Unser Buch Coding mit KI wird gerade übersetzt. Heute musste ich diverse Fragen zur Übersetzung beantworten und habe bei der Gelegenheit ein paar Beispiele aus unserem Buch mit aktuellen Versionen von ChatGPT und Claude noch einmal ausprobiert. Dabei ging es um die Frage, ob KI-Tools technische Diagramme (z.B. UML-Diagramme) zeichnen können. Die Ergebnisse sind niederschmetternd, aber durchaus unterhaltsam :-)
UML-Diagramme
Vor einem halben Jahr habe ich ChatGPT gebeten, zu zwei einfachen Java-Klassen ein UML-Diagram zu zeichnen. Das Ergebnis sah so aus (inklusive der falschen Einrückungen):
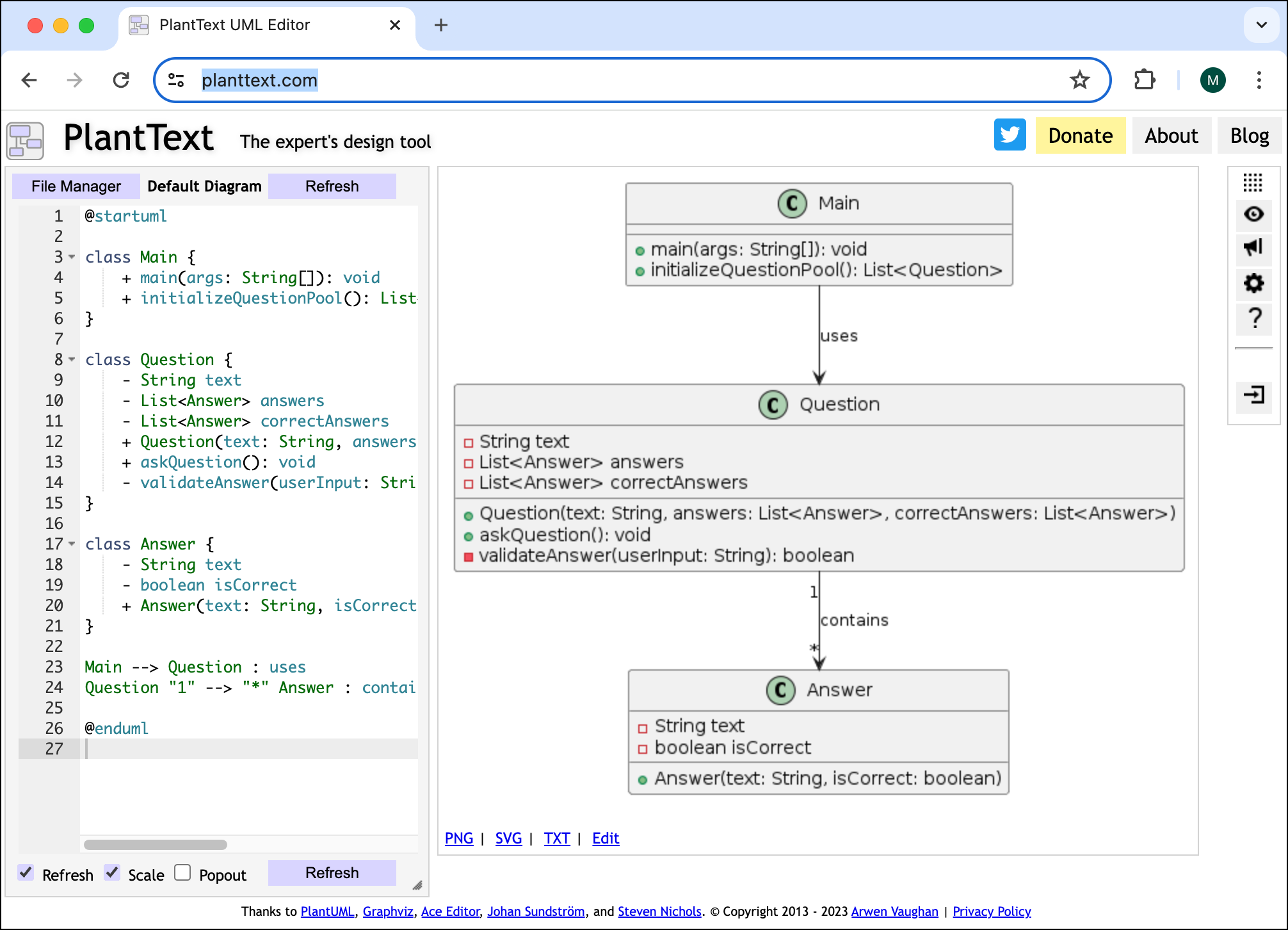
Dabei war ChatGPT schon damals in der Lage, PlantUML- oder Mermaid-Code zu liefern. Der Prompt Please generate PlantUML code instead liefert brauchbaren Code, der dann in https://www.planttext.com/ visualisiert werden kann. Das sieht dann so aus:
ChatGPT lieferte den Code für das UML-Diagramm, planttext.com visualisiert ihn
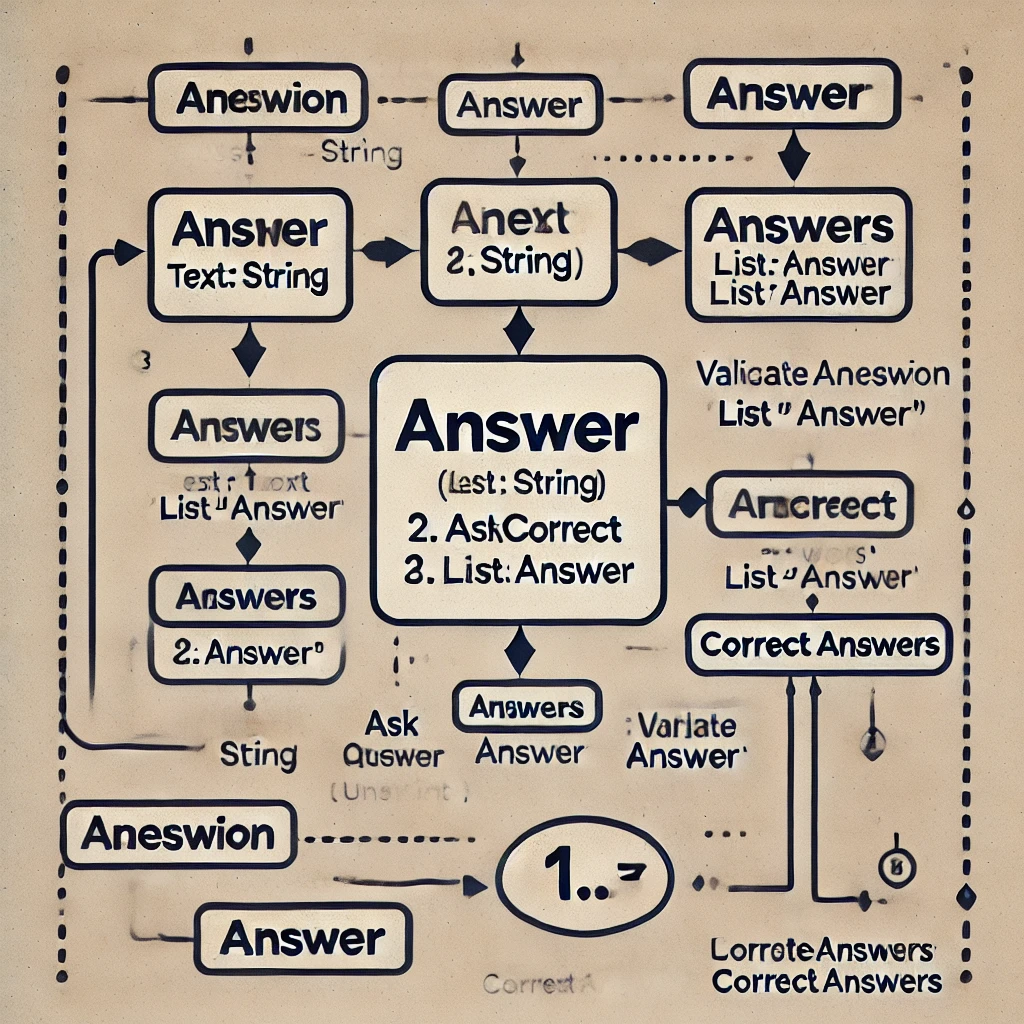
Heute habe ich das ganze Beispiel noch einmal ausprobiert. Ich habe also den Java-Code für zwei Klassen an ChatGPT übergeben und um ein UML-Diagramm gebeten. Vorbei sind die ASCII-Zeiten. Das Ergebnis sieht jetzt so aus:
ChatGPT nennt diesen von DALL-E produzierten Irrsinn ein »UML-Diagramm«Etwas mehr Kontext zum obigen Diagramm
Leider kann ich hier keinen Link zum ganzen Chat-Verlauf angeben, weil ChatGPT anscheinend nur reine Text-Chat-Verläufe teilen kann.
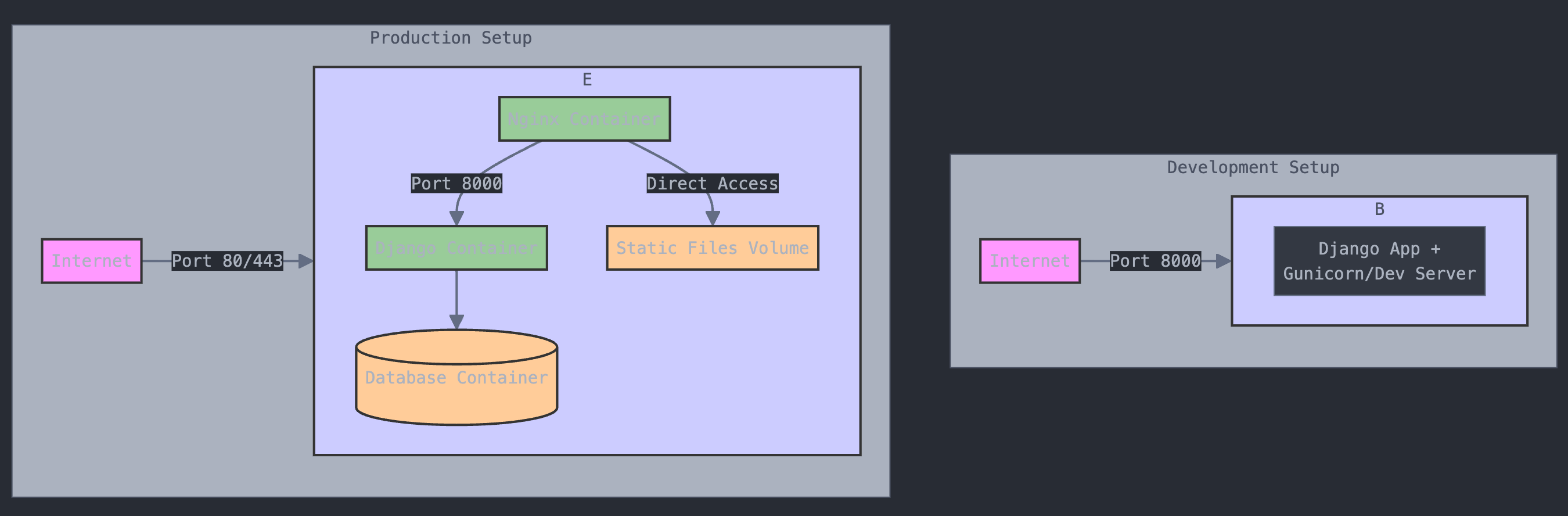
Visualisierung eines Docker-Setups
Beispiel zwei ergibt sich aus zwei Prompts:
Prompt: I want to build a REST application using Python and Django. The application will run in a Docker container. Do I need a proxy server in this case to make my application visible to the internet?
Prompt: Can you visualize the setup in a diagram?
In der Vergangenheit (Mitte 2024) lieferte ChatGPT das Diagramm als ASCII-Art.
Erst auf die explizite Bitte liefert es auch Mermaid-Code, der dann unter https://mermaid.live/ gezeichnet werden kann.
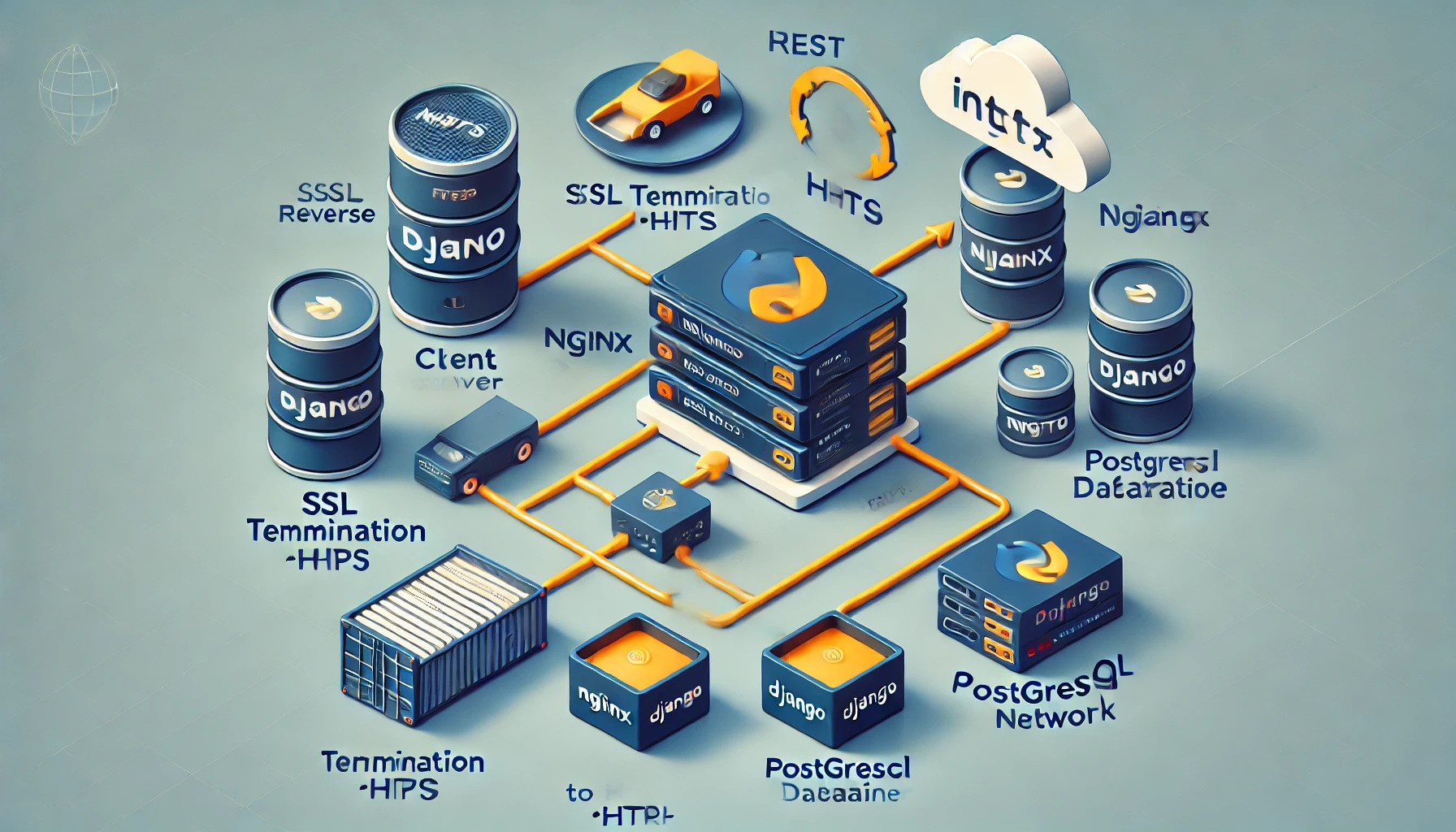
Heute (Dez. 2024) gibt sich ChatGPT nicht mehr mit ASCII-Art ab sondern leitet den Diagrammwunsch an DALL-E weiter. Das Ergebnis ist eine Katastrophe.
ChatGPT’s jämmerlicher Versuch, ein einfaches Docker-Setup zu visualisieren
Auch Claude.ai zeichnet selbstbewusst ein Diagramm des Docker-Setups. Dabei wird intern Mermaid verwendet.
Claude leidet offensichtlich unter bedrohlichen Farbstörungen, aber inhaltlich ist das Ergebnis besser als bei ChatGPTHier der relevante Teil des Chat-Verlaufs mit Claude
Fazit
Die Diagramme haben durchaus einen hohen Unterhaltungswert. Aber offensichtlich wird es noch ein wenig dauern, bis KI-Tools brauchbare technische Diagramme zeichnen können. Der Ansatz von Claude wirkt dabei erfolgsversprechender. Technische Diagramme mit DALL-E zu erstellen wollen ist doch eine sehr gewagte Idee von OpenAI.
Die besten Ergebnisse erzielen Sie weiterhin, wenn Sie ChatGPT, Claude oder das KI-Tool Ihrer Wahl explizit um Code in PlantUML oder Mermaid bitten. Den Code können Sie dann selbst visualisieren und bei Bedarf auch weiter optimieren.
Als ich vor 40 Jahren zu schreiben begann, war klar, was ein IT-Fachbuch liefern musste: Korrekte Information zu einem Thema, zu einer Programmiersprache, zu Linux etc. … Je mehr Information, desto besser. Ein dickes Buch war also im Regelfall wertvoller als ein dünnes.
Das IT-Buch war damals nahezu konkurrenzlos: Zu kommerziellen Software-Produkten gab es im Idealfall ein gedrucktes Handbuch (oft lieblos gestaltet und von dürftiger Qualität), dazu eventuell noch ein paar Readme-Dateien; ansonsten waren Administratorinnen und Programmierer weitgehend auf sich selbst gestellt. Mit etwas Glück veröffentlichte eine der damals noch viel zahlreicheren Zeitschriften einen Artikel mit Lösungsideen für ein spezifisches Problem. Aber ansonsten galt: Learning by doing.
Mit dem Siegeszug des Internets änderte sich der IT-Buchmarkt zum ersten Mal radikal: Der Vorteil des Buchs lag nun darin, dass die dort zusammengestellten Informationen (hoffentlich!) besser recherchiert und besser strukturiert waren als die über das Internet und in Videos verstreuten Informationsschnipsel, Tipps und Tricks. Ein gutes Buch konnte ganz einfach Zeit sparen.
Das IT-Buch stand plötzlich in Konkurrenz zur Informationsfülle des Internets. Es liegt in der Natur der Sache, dass ein Buch nie so aktuell sein kann wie das Internet, nie so allumfassend bei der Themenauswahl. Im Internet finden sich selbst für exotische Funktionen Anleitungen, selbst zu selten auftretenden Fehlern Tipps oder zumindest Leidensberichte anderer Personen. Es hilft ja schon zu wissen, dass ein Problem nicht nur auf dem eigenen Rechner oder Server auftritt.
Natürlich habe auch ich als Autor von der einfachen Zugänglichkeit der Informationen profitiert. Während früher Ausprobieren der einzige Weg war, um bestimmte Techniken verlässlich zu dokumentieren, konnte ich jetzt auf den Erfahrungsschatz der riesigen Internet-Community zurückgreifen. Gleichzeitig sank aber der Bedarf nach IT-Büchern — und zwar in einem dramatischen Ausmaß. Viele Verlage, für die ich im Laufe der letzten Jahrzehnte geschrieben habe, existieren heute nicht mehr.
Mit der freien Verfügbarkeit von KI-Tools wie ChatGPT stehen wir heute vor einem weiteren Umbruch: Wozu noch nach einem Buch, einem StackOverflow-Artikel oder einem Blog-Beitrag suchen, wenn KI-Werkzeuge in Sekunden den Code für scheinbar jedes Problem, eine strukturierte Anleitung für jede Aufgabe liefern?
Möglichkeiten und Grenzen von KI-Tools
Seit die erste Version von ChatGPT online war, habe ich mich intensiv mit diesem und vielen anderen KI-Tools auseinandergesetzt. Natürlich habe ich darüber auch geschrieben, sowohl in diesem Blog als auch in Buchform: In Coding mit KI fassen Bernd Öggl, Sebastian Springer und ich zusammen, wie weit KI-Tools heute beim Coding und bei Administrationsaufgaben helfen — und wo ihre Grenzen liegen. Kurz gefasst: Claude, Copilot, Ollama etc. bieten bereits heute eine großartige Unterstüzung bei vielen Aufgaben. Sie machen Coding und Administration effizienter, schneller.
Ja, die Tools machen Fehler, aber sie sind dennoch nützlich, und sie werden jedes Monat besser. Ja, es gibt Datenschutzbedenken, aber die lassen sich lösen (am einfachsten, indem Sprachmodelle lokal ausgeführt werden). Ja, KI-Tools stellen mit ihrem exorbitaten Stromverbrauch vor allem in der Trainings-Phase eine massive ökologische Belastung dar; aber ich glaube/hoffe, dass sich KI-Tools mit bessere Hard- und Software in naher Zukunft ohne ein allzugroßes schlechtes Öko-Gewissen nutzen lassen.
Es ist für mich offensichtlich, dass viele IT-Arbeiten in Zukunft ohne KI-Unterstützung undenkbar sein werden. KI-Tools können bei der Lösung vieler Probleme die Effizienz steigern. Keine Firma, kein Admin, keine Entwicklerin wird es sich auf Dauer leisten können, darauf zu verzichten.
Die Zukunft des IT-Buchs
Ist »Coding mit KI« also das letzte IT-Buch, das Sie lesen müssen/sollen? Vermutlich nicht. (Aus meiner Sicht als Autor: Hoffentlich nicht!)
Auf jeden Fall ändern KI-Tools die Erwartungshaltung an IT-Bücher. Aktuell arbeite ich an einer Neuauflage meines Swift-Buchs. Weil sich inhaltlich viel ändert und ich bei vielen Teilen sowieso quasi bei Null anfangen muss, ist es das erste Buch, das ich von Grund auf im Hinblick auf das KI-Zeitalter neu konzipiere. In der vorigen Auflage habe ich über 1300 Seiten geschrieben und versucht, Swift und die App-Programmierung so allumfassend wie möglich darzustellen.
Dieses Mal bemühe ich mich im Gegenteil, die Seitenanzahl grob auf die Hälfte zu reduzieren. Warum? Weil ich glaube, dass sich das IT-Buch der Zukunft auf die Vermittlung der Grundlagen konzentriert. Es richtet den Blick auf das Wesentliche. Es erklärt die Konzepte. Es gibt Beispiele (durchaus auch komplexe). Aber es verzichtet darauf, endlose Details aufzulisten.
Was sind Ihre Erwartungen?
Ich weiß schon, immer mehr angehende und tatsächliche IT-Profis kommen ohne Bücher aus. Eigenes Ausprobieren in Kombination mit Videos, Blog-Artikeln und KI-Hilfe reichen aus, um neue Konzepte zu erlernen oder ganz pragmatisch ein Problem zu lösen (oft ohne es wirklich zu verstehen). Bleibt nur die Frage, warum Sie überhaupt auf meiner Website gelandet sind :-)
Persönlich lese ich mich in ein neues Thema aber weiterhin gerne ein, lasse mich von einem Autor oder einer Autorin von neuen Denkweisen überzeugen (zuletzt: Prometheus: Up & Running von Julien Pivotto und Brian Brazil). Bevorzugt mache ich das weit weg vom Computer. Wenn ich später ein Detail nochmals nachsehen will, ist mir ein E-Book willkommen. Aber beim ersten Lesen bevorzuge ich den analogen Zugang, ungestört und werbefrei.
Falls also auch Sie noch gelegentlich ein Buch zur Hand nehmen, dann interessiert mich Ihrer Meinung: Was erwarten Sie heute von einem IT-Buch? Was sind Ihre Wünsche an mich als Autor? Was ist aus Ihrer Sicht ein gutes IT-Buch, was ist ein schlechtes? Ich sage es sicherheitshalber gleich: Alle Wünsche kann ich nie erfüllen … Aber ich freue mich auf jeden Fall über Ihr Feedback!
Amazon, einer der größten IT-Konzerne der Welt, war bislang im Rennen um die Vorherrschaft bei generativen KI-Modellen vor allem durch seine finanzielle Untertützung für das Startup Anthropic…
Die Eclipse Foundation und die Open Source Initiative (OSI), die globale Non-Profit-Organisation für die Förderung von Open Source sowie Hüterin der Open-Source-Definition wollen beim Thema KI…
Aufgrund der Fortschritte im Quantencomputing und der Künstlichen Intelligenz (KI) sowie Machine Learning werden Cyberbedrohungen durch Ransomware und Infostealer im kommenden Jahr zunehmen, so…
Das Bundesministerium für Bildung und Forschung (BMBF) fördert zwei neue Verbundprojekte mit Beteiligung der Ludwig Maximilians Universität (LMU) München .
Mit der raschen Verbreitung von KI bauen Entwickler zunehmend KI-Modelle in Anwendungen ein und beteiligen sich in großer Zahl an KI-Projekten auf GitHub.
Google hat angekündigt, seine von einer KI erzeugte Übersicht der Suchergebnisse in mehr als hundert Ländern einzuführen. Die Europäische Union spart der Konzern aber aus.
Ein halbes Jahr lang haben wir zu dritt intensiv getestet:
Was ist möglich?
Was ist sinnvoll?
Welche Anwendungsfälle gibt es, die über das reine Erstellen von Code hinausgehen?
Wo liegen die Grenzen?
Was sind die Risken?
Ist der KI-Einsatz ethisch vertretbar?
Wir haben mit ChatGPT und Claude gearbeitet und deren Ergebnisse mit lokalen Sprachmodellen (via Ollama, GPT4All, Continue, Tabby) verglichen. Wir haben Llama, Mistral/Mixtral, CodeLlama, Starcoder, Gemma und andere »freie« Sprachmodelle ausprobiert. Wir haben nicht nur Pair Programming getestet, sondern haben die KI-Werkzeuge auch zum Debugging, Refactoring, Erstellen von Unit-Tests, Design von Datenbanken, Scripting sowie zur Administration eingesetzt. Dabei haben wir mit verschiedenen Prompt-Formulierungen experimentiert und geben dazu eine Menge Tipps.
Der nächste Schritt beim Coding mit KI sind semi-selbstständige Level-3-Tools. Also haben wir uns OpenHands und Aider angesehen und waren von letzterem ziemlich angetan. Wir haben die Grenzen aktueller Sprachmodelle mit Retrieval Augmented Generation (RAG) und Text-to-SQL verschoben. Wir haben Scripts entwickelt, die mit KI-APIs kommunizieren und automatisiert dutzende oder auch hunderte von Code-Dateien verarbeiten.
Kurz und gut: Wir haben uns das Thema »Coding mit KI« so gesamtheitlich wie möglich angesehen und teilen mit Ihnen unsere Erfahrungen. Die Quintessenz ist vielleicht ein wenig banal: Es kommt darauf an. In vielen Fällen haben wir sehr gute Ergebnisse erzielt. Oft sind wir aber auch an die Grenzen gestoßen — umso eher, je spezieller die Probleme, je exotischer die Programmiersprachen und je neuer die genutzten Sprach-Features/Frameworks/Bibliotheken sind.
Was bleibt, ist die Überzeugung, dass an KI-Tools in der Software-Entwicklung kein Weg vorbei geht. Wer KI-Tools richtig einsetzt, spart Zeit, kürzer lässt es sich nicht zusammenfassen. Aber wer sie falsch einsetzt, agiert unverantwortlich und produziert fehlerhaften und unwartbaren Code!
Mehr Details zum (Vorwort, Leseprobe) finden Sie hier.
Die Diskussion über einen KI-Assistenten für Linux wirft grundlegende Fragen zu den Werten und der Philosophie des Betriebssystems auf. Linux wird für seine Anpassungsfähigkeit und Benutzerkontrolle geschätzt, was im Widerspruch zu der Idee steht, einen KI-Assistenten einzuführen, der Aufgaben automatisiert und den Lernprozess von Nutzern potenziell beeinträchtigt. Dennoch könnte ein KI-Assistent in vielen Bereichen von […]
Die weltweiten Ausgaben für künstliche Intelligenz (KI), einschließlich KI-gestützter Anwendungen, Infrastruktur und damit verbundener IT- und Unternehmensdienstleistungen, werden sich bis 2028…
Was genau bedeutet meine Diagnose? Mit solchen Fragen wollen sich viele Deutsche nach einem Besuch in der Arztpraxis künftig an eine Künstliche Intelligenz wenden.
Bei der Arbeit für unser KI-Buch bin ich kürzlich über Aider gestolpert. Dabei handelt es sich um ein Konsolenwerkzeug zum Coding. Im Gegensatz zu anderen Tools (ChatGPT, GitHub Copilot etc.), die Sie beim Coding nur unterstützen, ist Aider viel selbstständiger: Sie sagen, was Ihr Programm machen soll. Aider erzeugt die notwendigen Dateien, implementiert die Funktion und macht gleich einen git-Commit. Sie testen den Code, optimieren vielleicht ein paar Details, dann geben Sie Aider weitere Aufträge. Den Großteil der Coding-Aufgaben übernimmt Aider. Sie sind im Prinzip nur noch für das Ausprobieren und Debugging zuständig.
Wie Sie gleich sehen werden, funktioniert das durchaus (noch) nicht perfekt. Aber das Konzept ist überzeugend, und es ist verblüffend, wie viel schon klappt. Aider kann auch auf ein bestehendes Projekt angewendet werden, das ist aber nicht Thema dieses Blog-Beitrags. Generell geht es mir hier nur darum, das Konzept vorzustellen. Viel mehr Details können Sie in der guten Dokumentation nachlesen. Es gibt auch diverse YouTube-Videos. Besonders überzeugend fand ich Claude 3.5 and Aider: Use AI Assistants to Build AI Apps.
Voraussetzungen
Damit Sie Aider ausprobieren können, brauchen Sie einen Rechner mit einer aktuellen Python-Installation, git sowie einen (kostenpflichtigen!) Key für ein KI-Sprachmodell. Ich habe meine Tests mit GPT-4o von OpenAI sowie mit Claude 3.5 Sonnet (Anthrophic) durchgeführt. Ein wenig überraschend hat Claude 3.5 Sonnet merklich besser funktioniert.
Damit Sie einen API-Key bekommen, müssen Sie bei OpenAI oder Anthrophic einen Account anlegen und Ihre Kontakt- und Kreditkartendaten hinterlegen. Sie kaufen dort vorab »Credits«, die dann durch API-Abfragen aufgebraucht werden. Für erste Tests reichen 10 EUR aus. Sie müssen also kein Vermögen investieren, um Aider auszuprobieren.
Installation von aider
aider ist ein Python-Programm. Die Installation führen Sie am besten in einem Virtual Environment aus, im Prinzip so:
Falls beide Variablen definiert sind, nutzt Aider das Modell Sonnet von Anthrophic. Mit den Optionen --4o oder --sonnet können Sie das Sprachmodell explizit auswählen. Aider unterstützt auch andere Sprachmodelle, empfiehlt aber explizit diese beiden Modell sowie DeepSeek Coder (siehe auch https://aider.chat/docs/leaderboards/).
»Hello World« mit GPT-4o von OpenAI
Um Aider kennenzulernen habe ich mir gedacht, ich beauftrage das Tool, ein ganz simples Webscraping-Tool in Python zu programmieren, das aus einer Wetterseite von orf.at die aktuelle Temperatur in Graz extrahiert. (Warnung: Das Script hat reinen Demonstrations-Charakter. Das regelmäßige Auslesen von Wetterseiten und die Nutzung der so gewonnen Daten — wofür auch immer — ist bei nahezu allen Websites verboten.)
Für den Test habe ich ein neues Verzeichnis eingerichtet, dieses aktiviert und (immer noch im Virtual-Environment) aider gestartet.
mkdir ~/my-projects/test1
cd ~/my-projects/test1
aider --4o
No git repo found, create one to track GPT's changes (recommended)? y
Models: gpt-4o with diff edit format, weak model gpt-4o-mini
Git repo: .git with 0 files
Repo-map: using 1024 tokens
Use /help <question> for help, run "aider --help" to see cmd line args
Die weitere Bedienung erfolgt durch Konsolenkommandos. Ich habe damit begonnen, mit /web die Wetterseite zu laden. Beim ersten /web-Kommando installiert Aider nach einer Rückfrage das Webscraping-Tool Playwright. Mit der folgenden Frage habe ich überprüft, dass Aider den Inhalt der gelesenen Seite versteht.
> /web https://wetter.orf.at/steiermark
I see that you've shared a webpage content. How can I assist you with this? Are
you looking to extract specific information, transform the data, or something
else? Please provide more details about what you need.
Tokens: 7,057 sent, 43 received. Cost: $0.04 request, $0.04 session.
> what is the temperature in Graz?
The temperature in Graz, according to the provided content, is 27.2°C.
Nach diesem einleitenden Test habe ich nun versucht, eine App zu entwickeln, die diese Aufgabe übernimmt. Aider erzeugt eine neue Datei und speichert die Datei dort. Von der Programmiersprache war nie die Rede, Aider hat sich für Python entschieden. In einem zweiten Prompt habe ich Aider darum gebeten, das Projekt mit einer requirement-Datei auszustatten.
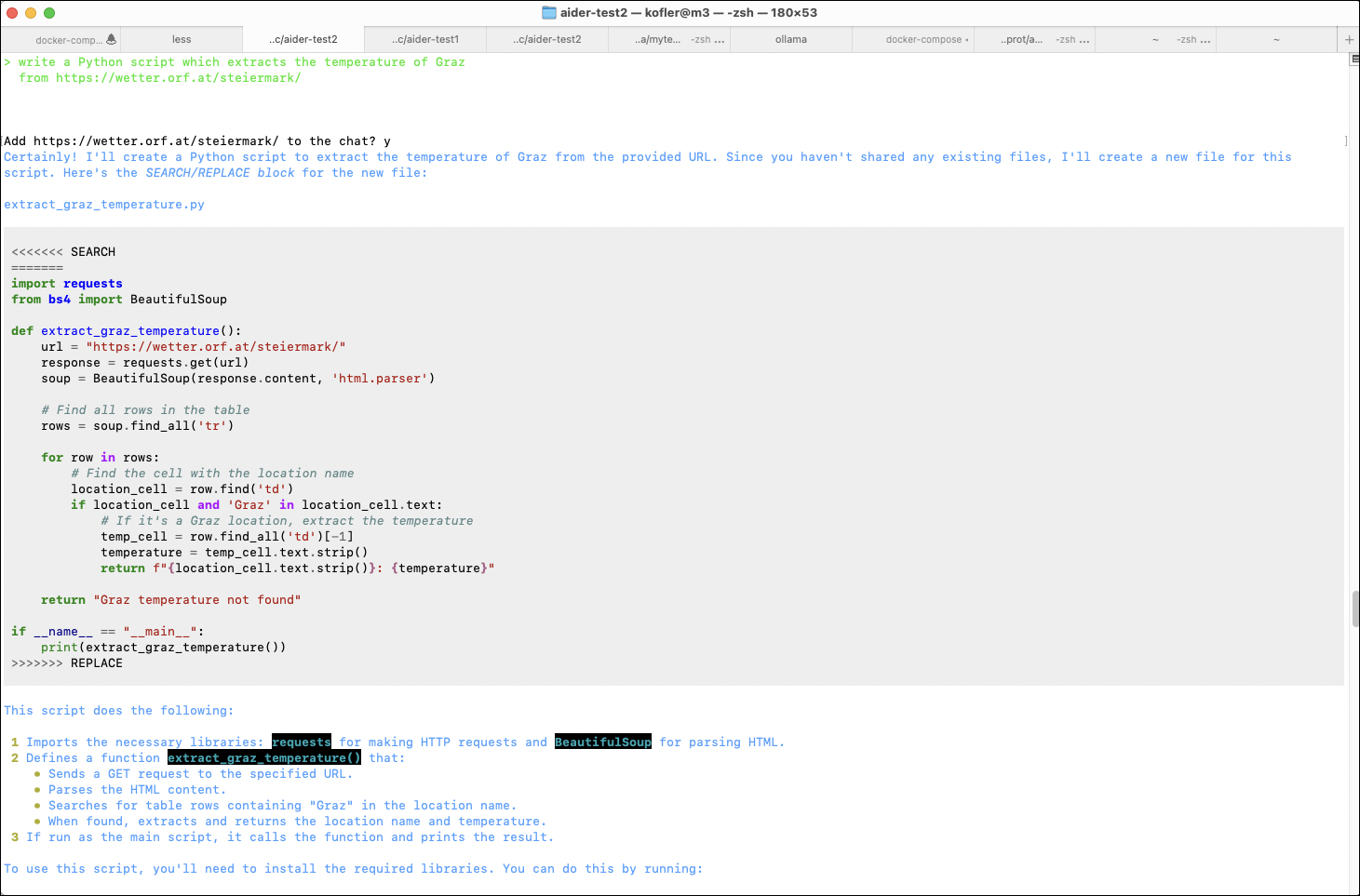
> write a Python script which extracts the temperature of Graz
from https://wetter.orf.at/steiermark/
Add https://wetter.orf.at/steiermark/ to the chat? y
Let's create a Python script that extracts the temperature of Graz from the
given URL. We'll use the requests library to fetch the webpage content and
BeautifulSoup from the bs4 library to parse the HTML.
Here is the script:
import requests
from bs4 import BeautifulSoup
def get_graz_temperature():
url = "https://wetter.orf.at/steiermark/"
response = requests.get(url)
response.raise_for_status() # Ensure we notice bad responses
soup = BeautifulSoup(response.text, 'html.parser')
graz_section = soup.find('a', href="https://wetter.ORF.at/steiermark/grazuniversitaet/")
if graz_section:
temperature_text = graz_section.find_next_sibling(text=True)
if temperature_text:
temperature = temperature_text.strip().split(' ')[0]
return temperature
return None
if __name__ == "__main__":
temperature = get_graz_temperature()
if temperature:
print(f"The temperature in Graz is {temperature}°C.")
else:
print("Could not find the temperature for Graz.")
This script will:
1 Fetch the webpage content from the given URL.
2 Parse the HTML content to find the section related to Graz.
3 Extract and print the temperature for Graz.
You can run this script in your Python environment to get the current
temperature in Graz.
Tokens: 7,196 sent, 314 received. Cost: $0.04 request, $0.11 session.
Allow creation of new file new_file_path: extract_graz_temperature.py? y
Applied edit to new_file_path: extract_graz_temperature.py
Commit beb001f feat: add script to extract temperature of Graz from weather website
You can use /undo to revert and discard commit beb001f.
> add a requirement file to the project
To add a requirements file to the project, we need to create a new file named
requirements.txt and list the necessary dependencies.
requests
beautifulsoup4
Tokens: 2,372 sent, 66 received. Cost: $0.01 request, $0.13 session.
In einem zweiten Terminal-Fenster oder -Tab habe ich nun ein weiteres Virtual Environment eingerichtet, um alle erforderlichen Module zu installieren und das neue Script zu testen.
Dabei habe ich auch schon den ersten Fehler entdeckt. Aider hat das neue Python-Script nicht extract_graz_temperature.py genannt, sondern new_file_path: extract_graz_temperature.py. Diesen Fehler habe ich mit git behoben.
python3 extract_graz_temperature.py
extract_graz_temperature.py:13: DeprecationWarning: The
'text' argument to find()-type methods is deprecated.
Use 'string' instead.
Could not find the temperature for Graz.
Der Code enthält offensichtlich einen veralteten Parameter. Zurück im ersten Terminal/Tab bitte ich Aider, das Problem zu beheben. Aider sieht den Fehler ein und korrigiert den Code.
> tried to run the code, got this error:
extract_graz_temperature.py:13: DeprecationWarning: The 'text'
argument to find()-type methods is deprecated. Use 'string'
instead. Can you fix the code? I renamed the code file to
extract_graz_temperature.py.
extract_graz_temperature.py
Add these files to the chat? y
<<<<<<< SEARCH
temperature_text = graz_section.find_next_sibling(text=True)
=======
temperature_text = graz_section.find_next_sibling(string=True)
>>>>>>> REPLACE
...
Tokens: 2,585 sent, 86 received. Cost: $0.01 request, $0.14 session.
Aber auch nach diesem Fix funktioniert das Script nicht. Das Problem ist, dass das Script die Struktur der Wetter-Website nicht korrekt analysiert hat und Beautiful Soup (eine HTML-Parser-Bibliothek für Python) falsch anwendet. Etwas enttäuscht habe ich an dieser Stelle den ersten Versuch abgebrochen. Die bis dahin angefallenen Kosten von 14 US Cent sind immerhin verschmerzbar.
»Hello World« mit Sonnet 3.5 von Anthrophic
Anstatt mich mit der Fehlersuche zu ärgern, habe ich das ganze Experiment mit dem Sprachmodell Sonnet wiederholt. Die folgenden Ausgaben sind stark gekürzt.
mkdir ~/my-projects/test2
cd ~/my-projects/test2
aider --sonnet
> /web https://wetter.orf.at/steiermark
> what is the temperature in Graz?
Based on the information provided in the weather report for Steiermark, there
are multiple temperature readings for Graz:
1 Graz Heinrichstrasse: 30.3°C
2 Graz-Straßgang: 29.8°C
3 Graz-Thalerhof: 29.2°C
4 Graz-Universität: 30.3°C
The temperatures in Graz range from 29.2°C to 30.3°C, with most locations
reporting around 30°C. The warmest spots in Graz appear to be Heinrichstrasse
and the University area, both at 30.3°C.
Tokens: 7,323 sent, 129 received. Cost: $0.02 request, $0.05 session.
> write a Python script which extracts the temperature of Graz
from https://wetter.orf.at/steiermark/
...
> add a requirement file to the project
...
In einem weiteren Terminal habe ich nun auch für dieses Projekt ein Python Environment eingerichtet und das Script ausprobiert:
(Virtual Environment einrichten, Requirements mit pip installieren ...)
python3 extract_graz_temperature.py
Graz Heinrichstrasse: 30,3 °C
Aider in einem Terminal-Fenster
Bingo! Das Script wählt eine der vier Messstellen von Graz aus und zeigt die Temperatur dort an. Wunderbar.
Dementsprechend ermutigt habe ich mein Glück weiter strapaziert. Das Script soll die Durchschnittstemperatur aller vier Messstellen ausrechnen. Zurück in Terminal 1 mit Aider. Wie die folgenden Prompts zeigen, sind fünf Versuche notwendig, bis Aider endlich funktionierenden Code zusammenbringt. (Die ursprüngliche Fassung versucht aus Zeichenketten wie ‚30,3 C‘ in Fließkommazahlen umzuwandeln. Es ignoriert sowohl das deutsche Dezimalformat als auch die Zeichenkette ‚ C‘ am Ende. Die ganze Prozedur dauert inklusive meiner Tests eine Viertelstunde.
> please change extract_graz_temperature.py to calculate the average temperature for Graz
> does not work because of german number format (1,3 instead of 1.3); please fix
> still fails, probably because temperature string contains ' C' at the end; please fix once more
> still fails, the space in ' C' is a fixed space; try again
> it's the unicode fixed blank; just drop the last two characters
Tokens: 3,153 sent, 211 received. Cost: $0.01 request, $0.16 session.
Immerhin, das Script funktioniert jetzt:
python3 extract_graz_temperature.py
Average temperature for Graz: 29.9°C
Die API-Kosten für die Entwicklung des Scripts betrugen 13 US Cents. Meine Arbeitszeit habe ich nicht gerechnet ;-)
Fazit
Im Internet finden Sie diverse Videos, wo Aider scheinbar auf Anhieb perfekt funktioniert. Meine Tests haben gezeigt, dass das durchaus nicht immer der Fall ist.
Was mich trotz aller Fehler begeistert, ist das Konzept: Am besten führen Sie Aider in einem VSCode-Terminal aus, während in VSCode das Projektverzeichnis geöffnet ist. (Das Ganze funktioniert natürlich auch mit jedem anderen Editor.) Dann haben Sie eine grandiose Umgebung zum Testen des Codes sowie für dessen Weiterentwickung mit Aider.
Ja, weder Aider noch die von Aider genutzten Sprachmodelle sind zum jetzigen Zeitpunkt perfekt. Aber das Potenzial, das hier schlummert, ist enorm. Sie sind damit quasi eine Abstraktionsebene über dem Code. Sie geben Aider Kommandos, wie es den Code weiterentwickeln oder verbessern soll, ohne sich im Detail mit Funktionen, Schleifen oder Variablen zu beschäftigen. (Dieses Wissen brauchen Sie zum Debugging aber weiterhin!)


 Die Diskussion über einen KI-Assistenten für Linux wirft grundlegende Fragen zu den Werten und der Philosophie des Betriebssystems auf. Linux wird für seine Anpassungsfähigkeit und Benutzerkontrolle geschätzt, was im Widerspruch zu der Idee steht, einen KI-Assistenten einzuführen, der Aufgaben automatisiert und den Lernprozess von Nutzern potenziell beeinträchtigt. Dennoch könnte ein KI-Assistent in vielen Bereichen von […]
Die Diskussion über einen KI-Assistenten für Linux wirft grundlegende Fragen zu den Werten und der Philosophie des Betriebssystems auf. Linux wird für seine Anpassungsfähigkeit und Benutzerkontrolle geschätzt, was im Widerspruch zu der Idee steht, einen KI-Assistenten einzuführen, der Aufgaben automatisiert und den Lernprozess von Nutzern potenziell beeinträchtigt. Dennoch könnte ein KI-Assistent in vielen Bereichen von […]