KaOS: erste Distribution mit KDE Plasma 6
Die Linux-Distribution KaOS hat sich vor über 10 Jahren dem KDE-Desktop verschrieben. Jetzt ist mit KaOS 2024.01 ein offizielles Abbild mit Plasma 6 erschienen.

Die Linux-Distribution KaOS hat sich vor über 10 Jahren dem KDE-Desktop verschrieben. Jetzt ist mit KaOS 2024.01 ein offizielles Abbild mit Plasma 6 erschienen.
Der neue Raspberry Pi 5 verfügt erstmals über eine PCIe-Schnittstelle. Leider hat man sich bei der Raspberry Pi Foundation nicht dazu aufraffen können, gleich auch einen Slot für eine PCIe-SSD vorzusehen. Gut möglich, dass es auch einfach an Platzgründen gescheitert ist. Oder wird dieser Slot das Kaufargument für den Raspberry Pi 6 sein? Egal.
Mittlerweile gibt es diverse Aufsteckplatinen für den Raspberry Pi, die den Anschluss einer PCIe-SSD ermöglichen. Sie unterscheiden sich darin, ob sie über oder unter der Hauptplatine des Raspberry Pis montiert werden, ob sie kompatibel zum Lüfter sind und in welchen Größen sie SSDs aufnehmen können. (Kleinere Aufsteckplatinen sind mit den langen 2280-er SSDs überfordert.)
Update: Im Mai 2024 stellte auch die Raspberry Pi Foundation einen SSD-Adapter vor. Vorteil: billig. Nachteil: nur für kleine SSDs geeignet (2230/2242). Siehe https://www.raspberrypi.com/news/m-2-hat-on-sale-now-for-12/
Für diesen Artikel habe ich die NVMe Base der britischen Firma Pimoroni ausprobiert (Link). Inklusive Versand kostet das Teil ca. 24 €, der Zoll kommt gegebenenfalls hinzu. Die Platine wird mit einem winzigen Kabel und einer Menge Schrauben geliefert.

Der Zusammenbau ist fummelig, aber nicht besonders schwierig. Auf YouTube gibt es eine ausgezeichnete Anleitung. Achten Sie darauf, dass Sie wirklich eine PCIe-SSD verwenden und nicht eine alte M2-SATA-SSD, die Sie vielleicht noch im Keller liegen haben!

Nachdem Sie alles zusammengeschraubt haben, starten Sie Ihren Raspberry Pi neu (immer noch von der SD-Karte). Vergewissern Sie sich mit lsblk im Terminal, dass die SSD erkannt wurde! Entscheidend ist, dass die Ausgabe eine oder mehrere Zeilen mit dem Devicenamen nmve0n1* enthält.
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
mmcblk0 179:0 0 29,7G 0 disk
├─mmcblk0p1 179:1 0 512M 0 part /boot/firmware
└─mmcblk0p2 179:2 0 29,2G 0 part
nvme0n1 259:0 0 476,9G 0 disk

Jetzt müssen Sie Ihre Raspberry-Pi-OS-Installation von der SD-Karte auf die SSD übertragen. Dazu starten Sie das Programm Zubehör/SD Card Copier, wählen als Datenquelle die SD-Karte und als Ziel die SSD aus.
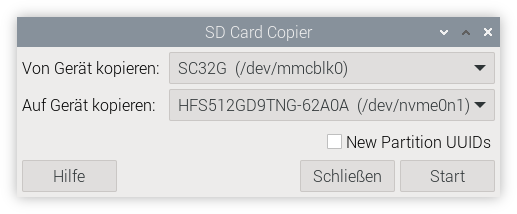
SD Card Copier kopiert das Dateisystem im laufenden Betrieb, was ein wenig heikel ist und im ungünstigen Fall zu Fehlern führen kann. Der Prozess dauert ein paar Minuten. Während dieser Zeit sollten Sie auf dem Raspberry Pi nicht arbeiten! Das Kopier-Tool passt die Größe der Partitionen und Dateisysteme automatisch an die Größe der SSD an.
Als letzten Schritt müssen Sie nun noch den Boot-Modus ändern, damit Ihr Raspberry Pi in Zukunft die SSD als Bootmedium verwendet, nicht mehr die SD-Karte. Dazu führen Sie im Terminal sudo raspi-config aus und wählen Advanced Options -> Boot Order -> NVMe/USB Boot.
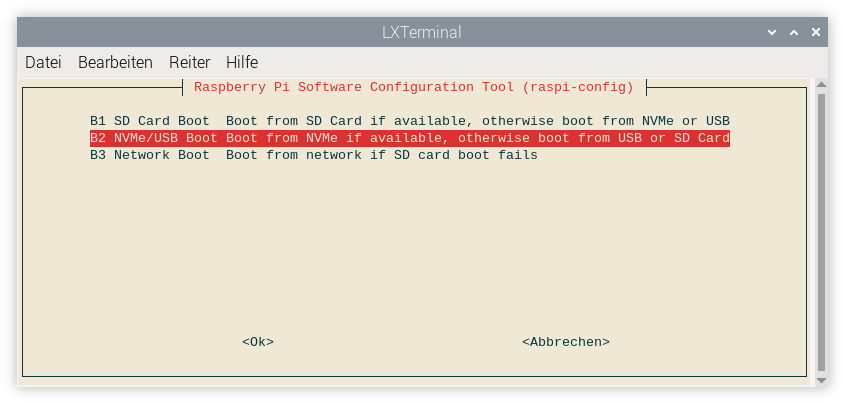
Selbst wenn alles klappt, verläuft der nächste Boot-Vorgang enttäuschend. Der Raspberry Pi lässt sich mit der Erkennung der SSD so viel Zeit, dass die Zeit bis zum Erscheinen des Desktops sich nicht verkürzt, sondern im Gegenteil ein paar Sekunden verlängert (bei meinen Tests ca. 26 Sekunden, mit SD-Karte nur 20 Sekunden). Falls Sie sich unsicher sind, ob die SSD überhaupt verwendet wird, führen Sie noch einmal lsblk aus. Der Mountpoint / muss jetzt bei einem nvme-Device stehen:
lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
nvme0n1 259:0 0 476,9G 0 disk
├─nvme0n1p1 259:1 0 512M 0 part /boot/firmware
└─nvme0n1p2 259:2 0 476,4G 0 part /
Wie viel die SSD an Geschwindigkeit bringt, merken Sie am ehesten beim Start großer Programme (Firefox, Chromium, Gimp, Mathematica usw.), der jetzt spürbar schneller erfolgt. Auch größere Update (sudo apt full-upgrade) gehen viel schneller vonstatten.
Ist die höhere Geschwindigkeit nur Einbildung, oder läuft der Raspberry Pi wirklich schneller? Diese Frage beantworten I/O-Benchmarktests. (I/O steht für Input/Output und bezeichnet den Transfer von Daten zu/von einem Datenträger.)
Ich habe den Pi Benchmark verwendet. Werfen Sie immer einen Blick in heruntergeladene Scripts, bevor Sie sie mit sudo ausführen!
wget https://raw.githubusercontent.com/TheRemote/ \
PiBenchmarks/master/Storage.sh
less Storage.sh
sudo bash Storage.sh
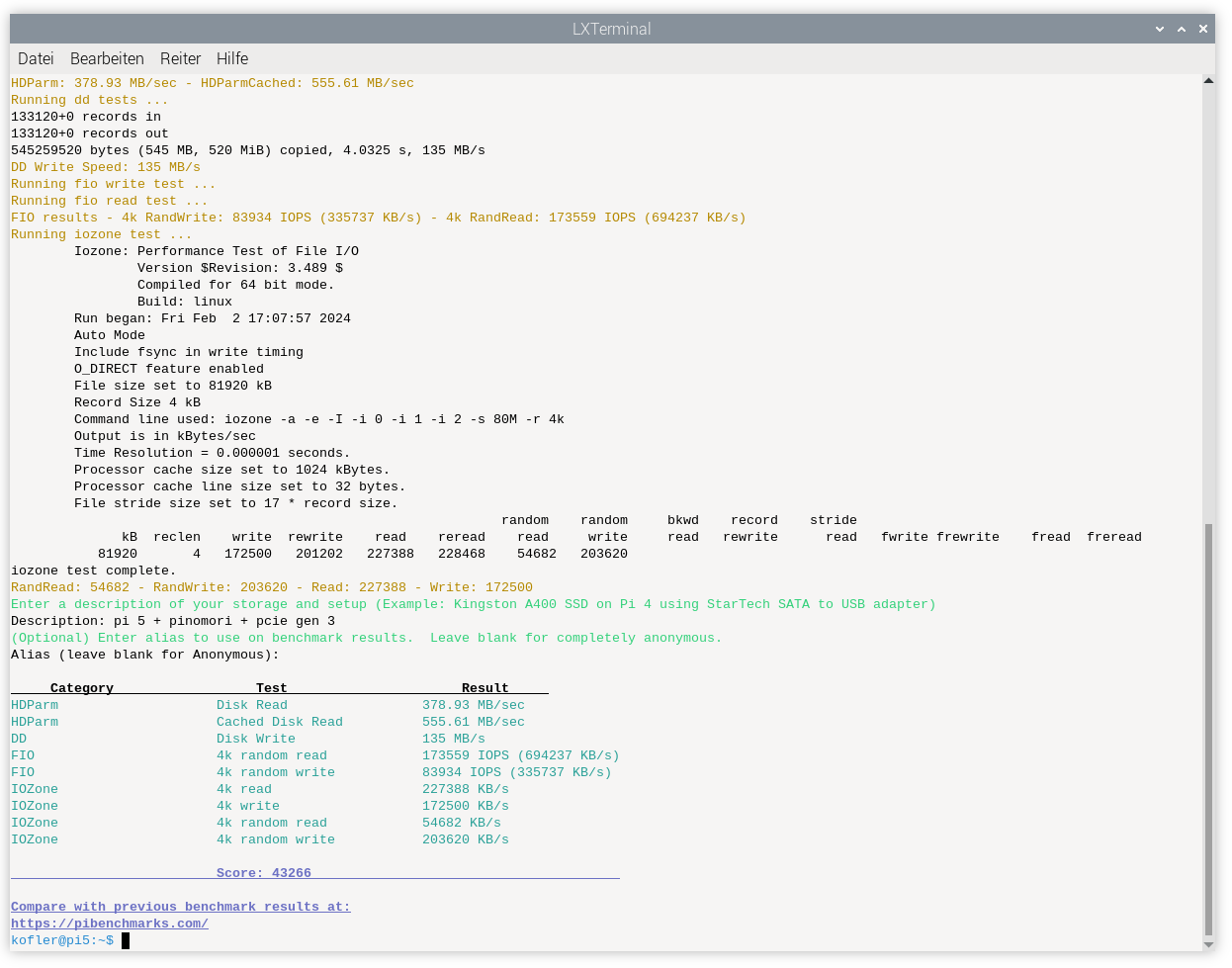
Ich habe den Test viermal ausgeführt:
Die Unterschiede sind wirklich dramatisch:
Modell Pi 5 + SD Pi 5 + USB Pi 5 + PCIe Pi 5 + PCIe 3
----------------- ----------- ------------- ------------- ---------------
Disk Read 73 MB/s 184 MB/s 348 MB/s 378 MB/s
Cached Disk Read 85 MB/s 186 MB/s 358 MB/s 556 MB/s
Disk Write 14 MB/s 121 MB/s 146 MB/s 135 MB/s
4k random read 3550 IOPS 32926 IOPS 96.150 IOPS 173.559 IOPS
4k random write 918 IOPS 27270 IOPS 81.920 IOPS 83.934 IOPS
4k read 15112 KB/s 28559 KB/s 175.220 KB/s 227.388 KB/s
4k write 4070 KB/s 28032 KB/s 140.384 KB/s 172.500 KB/s
4k random read 13213 KB/s 17153 KB/s 50.767 KB/s 54.682 KB/s
4k random write 2862 KB/s 27507 KB/s 160.041 KB/s 203.630 KB/s
Score 1385 9285 34.723 43.266
Beachten Sie aber, dass das synthetische Tests sind! Im realen Betrieb fühlt sich Ihr Raspberry Pi natürlich schneller an, aber keineswegs in dem Ausmaß, den die obigen Tests vermuten lassen.
Standardmäßig verwendet der Raspberry Pi PCI Gen 2. Mit dem Einbau von zwei Zeilen Code in /boot/firmware/config.txt können Sie den erheblich schnelleren Modus PCI Gen 3 aktivieren. (Der Tipp stammt vom PCIe-Experten Jeff Geerling.)
# in /boot/firmware/config.txt
dtparam=pciex1
dtparam=pciex1_gen=3
Die obigen Benchmarktests beweisen, dass die Einstellung tatsächlich einiges an Zusatz-Performance bringt. Ehrlicherweise muss ich sagen, dass Sie davon im normalen Betrieb aber wenig spüren.
Bleibt noch die Frage, ob die Einstellung gefährlich ist. Die Raspberry Pi Foundation muss ja einen Grund gehabt haben, warum sie PCI Gen 3 nicht standardmäßig aktiviert hat. Zumindest bei meinen Tests sind keine Probleme aufgetreten. Auch dmesg hat keine beunruhigenden Kernel-Messages geliefert.
Es ist natürlich cool, den Raspberry Pi mit einer schnellen SSD zu verwenden. Für Bastelprojekte ist dies nicht notwendig, aber wenn Sie vor haben, Ihren Pi als Server, NAS etc. einzusetzen, beschleunigt die SSD I/O-Vorgänge enorm.
Schön wäre, wenn der Raspberry Pi in Zukunft einen PCIe-Slot erhält, um (zumindest kurze) SSDs ohne Zusatzplatine zu nutzen. Bis dahin sind die Erweiterungsplatinen eine Übergangslösung.
In der Community ist zuletzt die Frage aufgetaucht, ob der Raspberry Pi überhaupt noch preiswert ist. Diese Frage ist nicht unberechtigt: Die Kosten für einen neuen Pi 5 + Netzteil + Lüfter + SSD-Platine + SSD + Gehäuse gehen in Richtung 150 €. Sofern Sie ein Gehäuse finden, in dem der Pi samt SSD-Platine Platz findet … Um dieses Geld bekommen Sie auch schon komplette Mini-PCs (z.B. die Chuwi Larkbox X). Je nach Anwendung muss man fairerweise zugeben, dass ein derartiger Mini-PC tatsächlich ein besserer Deal ist.
Zwei neue adminForge Services können ab sofort genutzt werden.
BookStack ist eine einfache Wiki-Software die leicht zu bedienen ist. Du kannst deine Informationen in Büchern mit Seiten ablegen und diese Bücher in Regale einordnen.
Mit Wallabag könnt ihr interessante Artikel ablegen und einfach später lesen.

BookStack ist eine einfache Wiki-Software die leicht zu bedienen ist. Du kannst deine Informationen in Büchern mit Seiten ablegen und diese Bücher in Regale einordnen.
https://bookstack.adminforge.de
Software: BookStack

Mit Wallabag könnt ihr interessante Artikel ablegen und einfach später lesen.
Apps:
Browser:
Geräte:
Software: Wallabag
Euer adminForge Team
 Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld. Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.Unterstütze unsere Arbeit mit einer Spende und diskutiere ins unserem Chat mit. |

by adminForge.
Es gibt wieder neue Sicherheitslücken in glibc. Dabei betrifft eine die syslog()-Funktion, die andere qsort(). Letztere Lücke existiert dabei seit glibc 1.04 und somit seit 1992. Entdeckt und beschrieben wurden die Lücken von der Threat Research Unit bei Qualys.
Die syslog-Lücke ist ab Version 2.37 seit 2022 enthalten und betrifft somit die eher die neuen Versionen von Linux-Distributionen wie Debian ab Version 12 oder Fedora ab Version 37. Hierbei handelt es sich um einen "heap-based buffer overflow" in Verbindung mit argv[0]. Somit ist zwar der Anwendungsvektor schwieriger auszunutzen, weil in wenigen Szenarien dieses Argument (der Programmname) dem Nutzer direkt überlassen wird, die Auswirkungen sind jedoch umso schwerwiegender. Mit der Lücke wird eine lokale Privilegienausweitung möglich. Die Lücke wird unter den CVE-Nummern 2023-6246, 2023-6779 und 2023-6780 geführt.
Bei der qsort-Lücke ist eine Memory Corruption möglich, da Speichergrenzen an einer Stelle nicht überprüft werden. Hierfür sind allerdings bestimmte Voraussetzungen nötig: die Anwendung muss qsort() mit einer nicht-transitiven Vergleichsfunktion nutzen (die allerdings auch nicht POSIX- und ISO-C-konform wären) und über eine große Menge an zu sortierenden Elementen verfügen, die vom Angreifer bestimmt werden. Dabei kann ein malloc-Aufruf gestört werden, der dann zu weiteren Angriffen führen kann. Das Besondere an dieser Lücke ist ihr Alter, da sie bereits im September 1992 ihren Weg in eine der ersten glibc-Versionen fand.
Bei der GNU C-Bibliothek (glibc) handelt es sich um eine freie Implementierung der C-Standard-Bibliothek. Sie wird seit 1987 entwickelt und ist aktuell in Version 2.38 verfügbar. Morgen, am 1. Februar, erscheint Version 2.39.
Ein Jahr mussten die Fans von Vanilla OS auf die zweite Veröffentlichung dieses Next-Gen-Betriebssystems warten. Jetzt liegt eine Beta zum Testen vor.

Der »Fedora Asahi Remix« ist eine für moderne Macs (Apple Silicon) optimierte Version von Fedora 39. Ich habe mich mit Asahi Linux ja schon vor rund zwei Jahren beschäftigt. Seither hat sich viel getan. Zeit also für einen neuen Versuch! Dieser Beitrag beschreibt die Installation des Fedora Asahi Remix auf einem Mac Mini mit M1-CPU. In einem zweiten Artikel fasse ich die Konfiguration und meine praktischen Erfahrungen zusammen.
Die Projektseite von Asahi Linux empfiehlt, die Installation von Asahi Linux in einem Terminal wie folgt zu starten:
curl https://alx.sh | sh
Ich habe bei solchen Dingen immer etwas Bauchweh, zumal das Script sofort nach dem sudo-Passwort fragt. Was, wenn irgendjemand alx.sh gekapert hat und mir ein Script unterjubelt, das einen Trojaner installiert? Daher:
curl https://alx.sh -o alx.sh
less alx.sh
sh alx.sh
Die Kontrolle hilft auch nur bedingt. Das Script ist nur wenige Zeilen lang und lädt alle erdenklichen weiteren Tools herunter. Aber der Code sieht zumindest so aus, als würde er tatsächlich Asahi Linux installieren, keine Malware. Eine echte Garantie, dass das alles gefahrlos ist, gibt auch less nicht. Nun gut …
Auf meinem Mac fristet eine uralte Asahi-Installation schon seit Jahren ein Schattendasein. Ich wollte das neue Asahi Linux einfach darüber installieren — aber das Installationsprogramm bietet dazu keine Möglichkeit. Die richtige Vorgehensweise sieht so aus: Zuerst müssen die drei damals eingerichteten Partitionen gelöscht werden. Dann kann das Installationsprogramm den partitionsfreien Platz auf der SSD für eine Neuinstallation nutzen.
Dankenswerterweise hat Asahi-Chefentwickler Hector Martin auf einer eigenen Seite eine Menge Know-how zur macOS-Partitionierung zusammengefasst. Dort gibt es auch gleich ein Script, mit dem alte Asahi-Linux-Installationen entfernt werden können. Gesagt, getan!
curl -L https://github.com/AsahiLinux/asahi-installer/raw/main/tools/wipe-linux.sh -o wipe-linux.sh
less wipe-linux.sh
sh wipe-linux.sh
THIS SCRIPT IS DANGEROUS!
DO NOT BLINDLY RUN IT IF SOMEONE JUST SENT YOU HERE.
IT WILL INDISCRIMINATELY WIPE A BUNCH OF PARTITIONS
THAT MAY OR MAY NOT BE THE ONES YOU WANT TO WIPE.
You are much better off reading and understanding this guide:
https://github.com/AsahiLinux/docs/wiki/Partitioning-cheatsheet
Press enter twice if you really want to continue.
Press Control-C to exit.
Started APFS operation on disk1
Deleting APFS Container with all of its APFS Volumes
Unmounting Volumes
Unmounting Volume "Asahi Linux - Data" on disk1s1
Unmounting Volume "Asahi Linux" on disk1s2
Unmounting Volume "Preboot" on disk1s3
Unmounting Volume "Recovery" on disk1s4
Unmounting Volume "Update" on disk1s5
...
Bei meinem Test hat das Script exakt getan, was es soll. Ein kurzer Test mit diskutil zeigt, dass sich zwischen Partition 2 und 3 eine Lücke von rund 200 GiB befindet. Dort war vorher Asahi Linux, und dorthin soll das neue Asahi Linux wieder installiert werden.
Nach diesen Vorbereitungsarbeiten (natürlich habe ich vorher auch ein Backup aller wichtiger Daten erstellt, eh klar …) habe ich den zweiten Versuch gestartet.
sh alx.sh
Bootstrapping installer:
Checking version...
Version: v0.7.1
Downloading...
Extracting...
Initializing...
The installer needs to run as root.
Please enter your sudo password if prompted.
Password:*******
Welcome to the Asahi Linux installer!
This installer will guide you through the process of setting up
Asahi Linux on your Mac.
Please make sure you are familiar with our documentation at:
https://alx.sh/w
Press enter to continue.
Collecting system information...
Product name: Mac mini (M1, 2020)
SoC: Apple M1
Device class: j274ap
Product type: Macmini9,1
Board ID: 0x22
Chip ID: 0x8103
System firmware: iBoot-10151.81.1
Boot UUID: 284E...
Boot VGID: 284E...
Default boot VGID: 284E...
Boot mode: macOS
OS version: 14.3 (23D56)
OS restore version: 23.4.56.0.0,0
Main firmware version: 14.3 (23D56)
No Fallback System Firmware / rOS
SFR version: 23.4.56.0.0,0
SystemRecovery version: 22.7.74.0.0,0 (13.5 22G74)
Login user: kofler
Collecting partition information...
System disk: disk0
Collecting OS information...
Nach der Darstellung einiger Infos ermittelt das Script eine Partitionstabelle und bietet dann an, Asahi Linux im freien Bereich der Disk zu installieren (Option f).
Partitions in system disk (disk0):
1: APFS [Macintosh HD] (795.73 GB, 6 volumes)
OS: [B*] [Macintosh HD] macOS v14.3 [disk3s1s1, 284E...]
2: (free space: 198.93 GB)
3: APFS (System Recovery) (5.37 GB, 2 volumes)
OS: [ ] recoveryOS v14.3 [Primary recoveryOS]
[B ] = Booted OS, [R ] = Booted recovery, [? ] = Unknown
[ *] = Default boot volume
Using OS 'Macintosh HD' (disk3s1s1) for machine authentication.
Choose what to do:
f: Install an OS into free space
r: Resize an existing partition to make space for a new OS
q: Quit without doing anything
» Action (f): f
Im nächsten Schritt haben Sie die Wahl zwischen verschiedenen Fedora-Varianten. Ich habe mich für Gnome entschieden:
Choose an OS to install:
1: Fedora Asahi Remix 39 with KDE Plasma
2: Fedora Asahi Remix 39 with GNOME
3: Fedora Asahi Remix 39 Server
4: Fedora Asahi Remix 39 Minimal
5: UEFI environment only (m1n1 + U-Boot + ESP)
» OS: 2
Jetzt beginnt die eigentliche Installation. Leider haben Sie keine Möglichkeit, auf die Partitionierung oder Verschlüsselung Einfluss zu nehmen. Es werden zwei kleine Partitionen für /boot (500 MiB) und /boot/efi eingerichtet (1 GiB). Den restlichen Platz füllt ein btrfs-Dateisystem ohne Verschlüsselung. Immerhin können Sie bei Bedarf festlegen, dass nicht der gesamte partitionsfreie Platz von Fedora Asahi Linux genutzt wird.
Downloading OS package info...
-
Minimum required space for this OS: 14.94 GB
Available free space: 198.93 GB
How much space should be allocated to the new OS?
You can enter a size such as '1GB', a fraction such as '50%',
the word 'min' for the smallest allowable size, or
the word 'max' to use all available space.
» New OS size (max): max
The new OS will be allocated 198.93 GB of space,
leaving 167.94 KB of free space.
Enter a name for your OS
» OS name (Fedora Linux with GNOME): <return>
Using macOS 13.5 for OS firmware
Downloading macOS OS package info...
Creating new stub macOS named Fedora Linux with GNOME
Installing stub macOS into disk0s5 (Fedora Linux with GNOME)
Preparing target volumes...
Checking volumes...
Beginning stub OS install...
Setting up System volume...
Setting up Data volume...
Setting up Preboot volume...
Setting up Recovery volume...
Wrapping up...
Stub OS installation complete.
Adding partition EFI (524.29 MB)...
Formatting as FAT...
Adding partition Boot (1.07 GB)...
Adding partition Root (194.83 GB)...
Collecting firmware...
Installing OS...
Copying from esp into disk0s4 partition...
Copying firmware into disk0s4 partition...
Extracting boot.img into disk0s7 partition...
Extracting root.img into disk0s6 partition...
Downloading extra files...
Downloading gstreamer1-plugin-openh264-1.22.1-1.fc39.aarch64.rpm (1/3)...
Downloading mozilla-openh264-2.3.1-2.fc39.aarch64.rpm (2/3)...
Downloading openh264-2.3.1-2.fc39.aarch64.rpm (3/3)...
Preparing to finish installation...
Collecting installer data...
To continue the installation, you will need to enter your macOS
admin credentials.
Password for kofler: **********
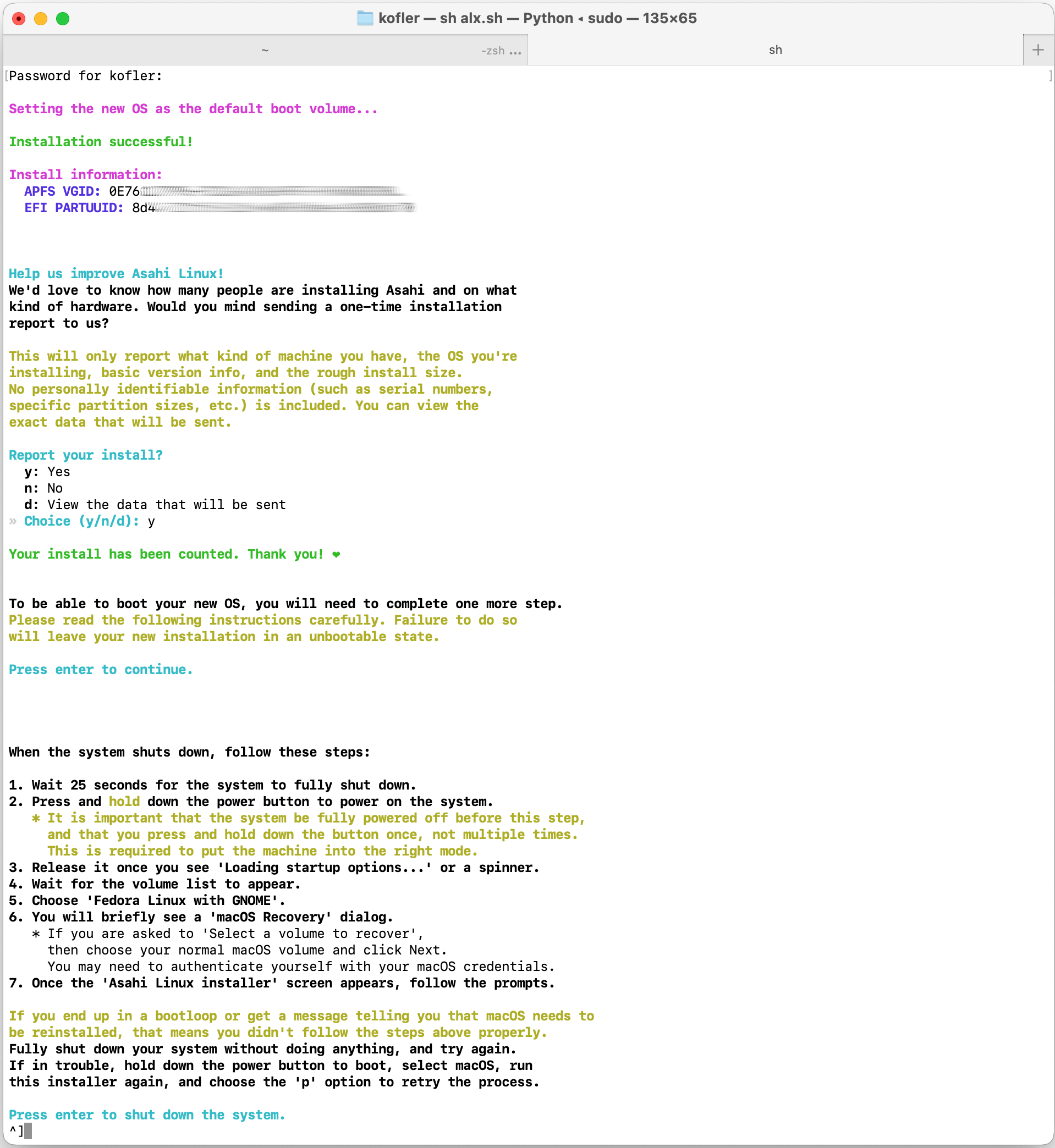
Setting the new OS as the default boot volume...
Installation successful!
Install information:
APFS VGID: 0E76...
EFI PARTUUID: 8d47...
Help us improve Asahi Linux!
We'd love to know how many people are installing Asahi and on what
kind of hardware. Would you mind sending a one-time installation
report to us?
This will only report what kind of machine you have, the OS you're
installing, basic version info, and the rough install size.
No personally identifiable information (such as serial numbers,
specific partition sizes, etc.) is included. You can view the
exact data that will be sent.
Report your install?
y: Yes
n: No
d: View the data that will be sent
» Choice (y/n/d): y
Your install has been counted. Thank you! ❤
Zuletzt zeigt das Installations-Script genaue Anweisungen für den ersten Start von Asahi Linux an:
To be able to boot your new OS, you will need to complete one more step.
Please read the following instructions carefully. Failure to do so
will leave your new installation in an unbootable state.
Press enter to continue.
When the system shuts down, follow these steps:
1. Wait 25 seconds for the system to fully shut down.
2. Press and hold down the power button to power on the system.
* It is important that the system be fully powered off before this step,
and that you press and hold down the button once, not multiple times.
This is required to put the machine into the right mode.
3. Release it once you see 'Loading startup options...' or a spinner.
4. Wait for the volume list to appear.
5. Choose 'Fedora Linux with GNOME'.
6. You will briefly see a 'macOS Recovery' dialog.
* If you are asked to 'Select a volume to recover',
then choose your normal macOS volume and click Next.
You may need to authenticate yourself with your macOS credentials.
7. Once the 'Asahi Linux installer' screen appears, follow the prompts.
If you end up in a bootloop or get a message telling you that macOS needs to
be reinstalled, that means you didn't follow the steps above properly.
Fully shut down your system without doing anything, and try again.
If in trouble, hold down the power button to boot, select macOS, run
this installer again, and choose the 'p' option to retry the process.
Press enter to shut down the system.
Ich habe den Installationsprozess auch in Screenshots dokumentiert:
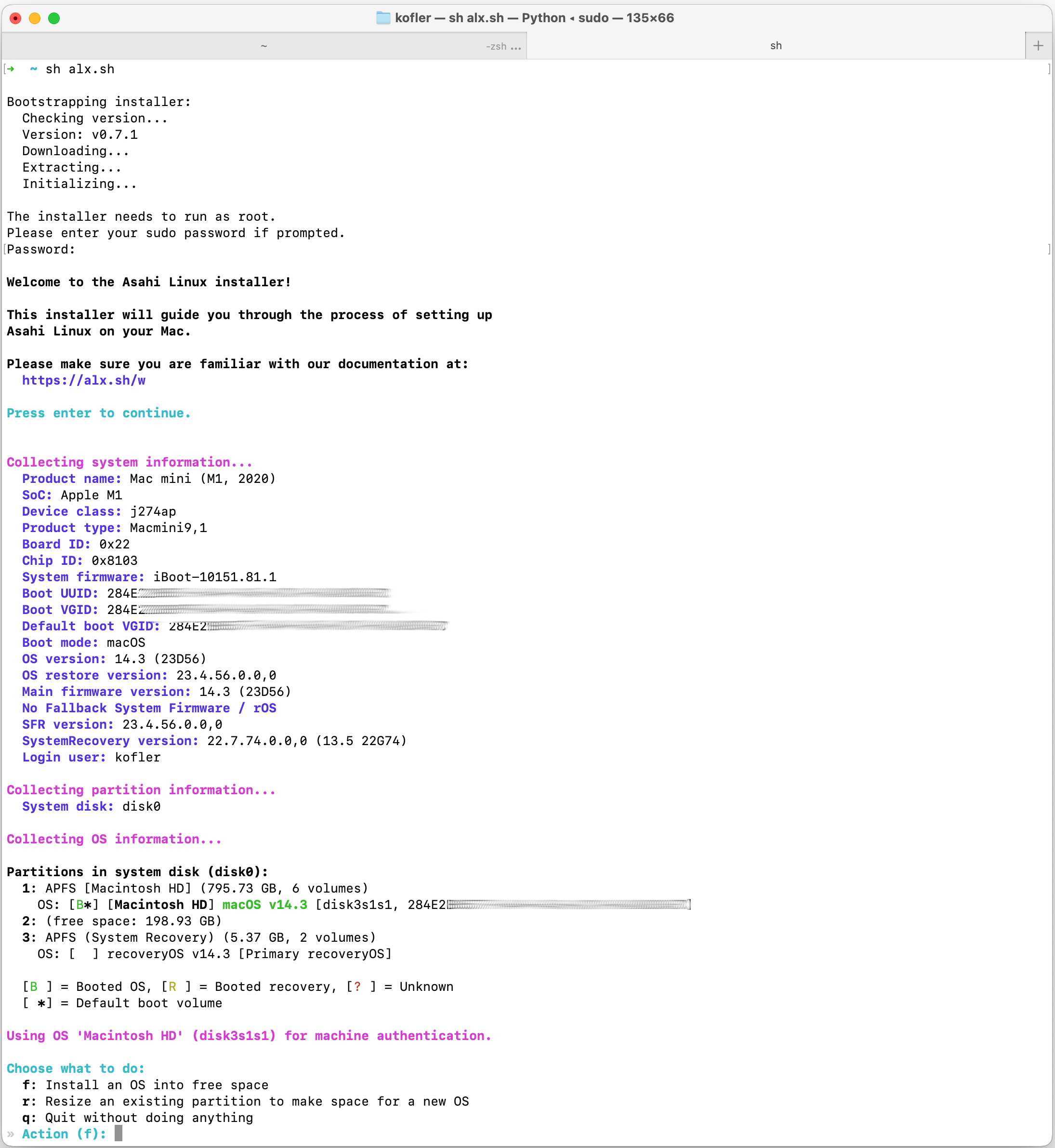
Das Script fährt nun macOS herunter. Zum Neustart drücken Sie die Power-Taste und halten diese ca. 15 Sekunden lang gedrückt, bis ein Auswahlmenü erscheint. Dort wählen Sie Asahi Linux. Dieses wird allerdings nicht gleich gestartet, vielmehr muss nun die Bootkonfiguration fertiggestellt werden. Ich habe die folgenden Schritte mit Fotos dokumentiert.
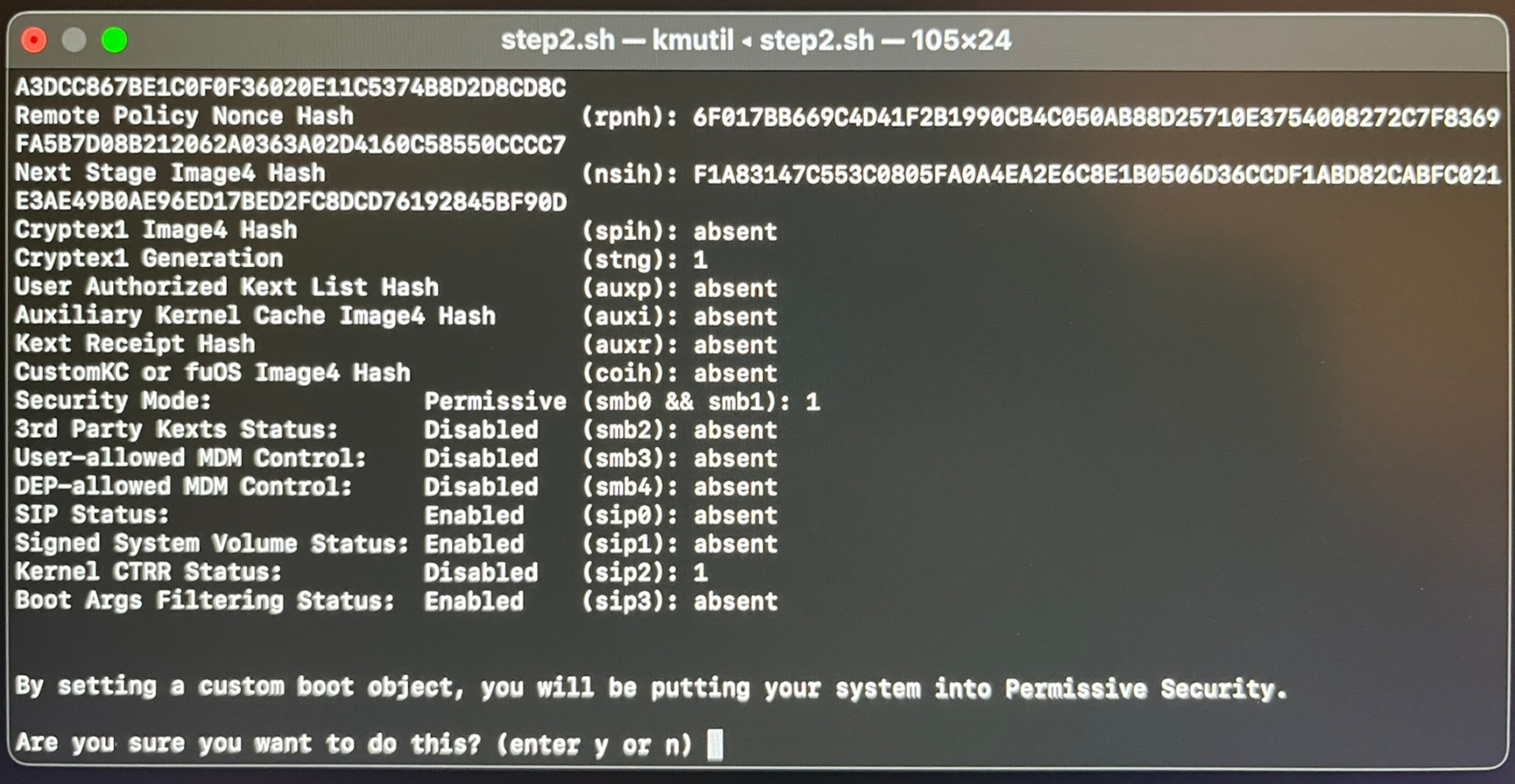
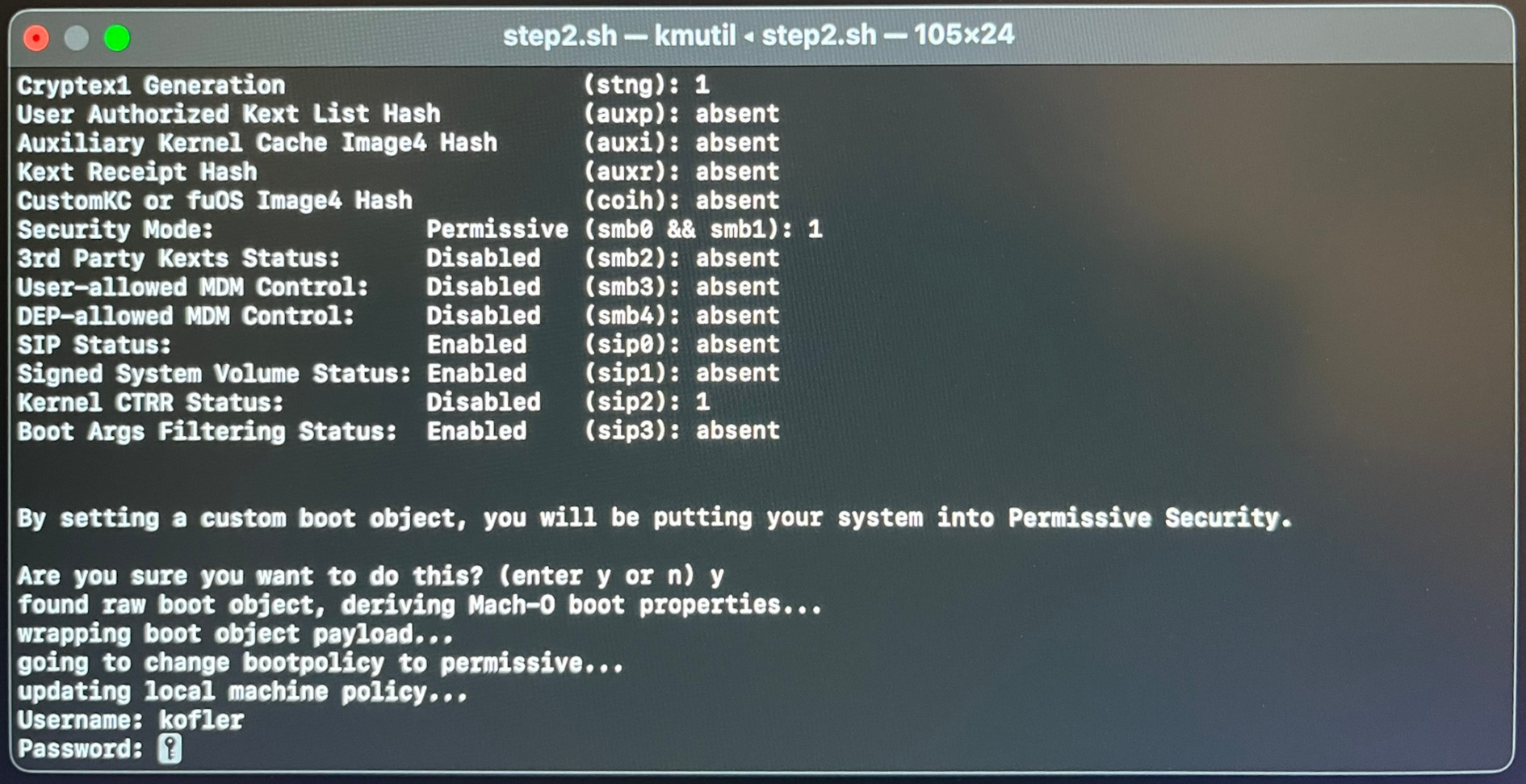
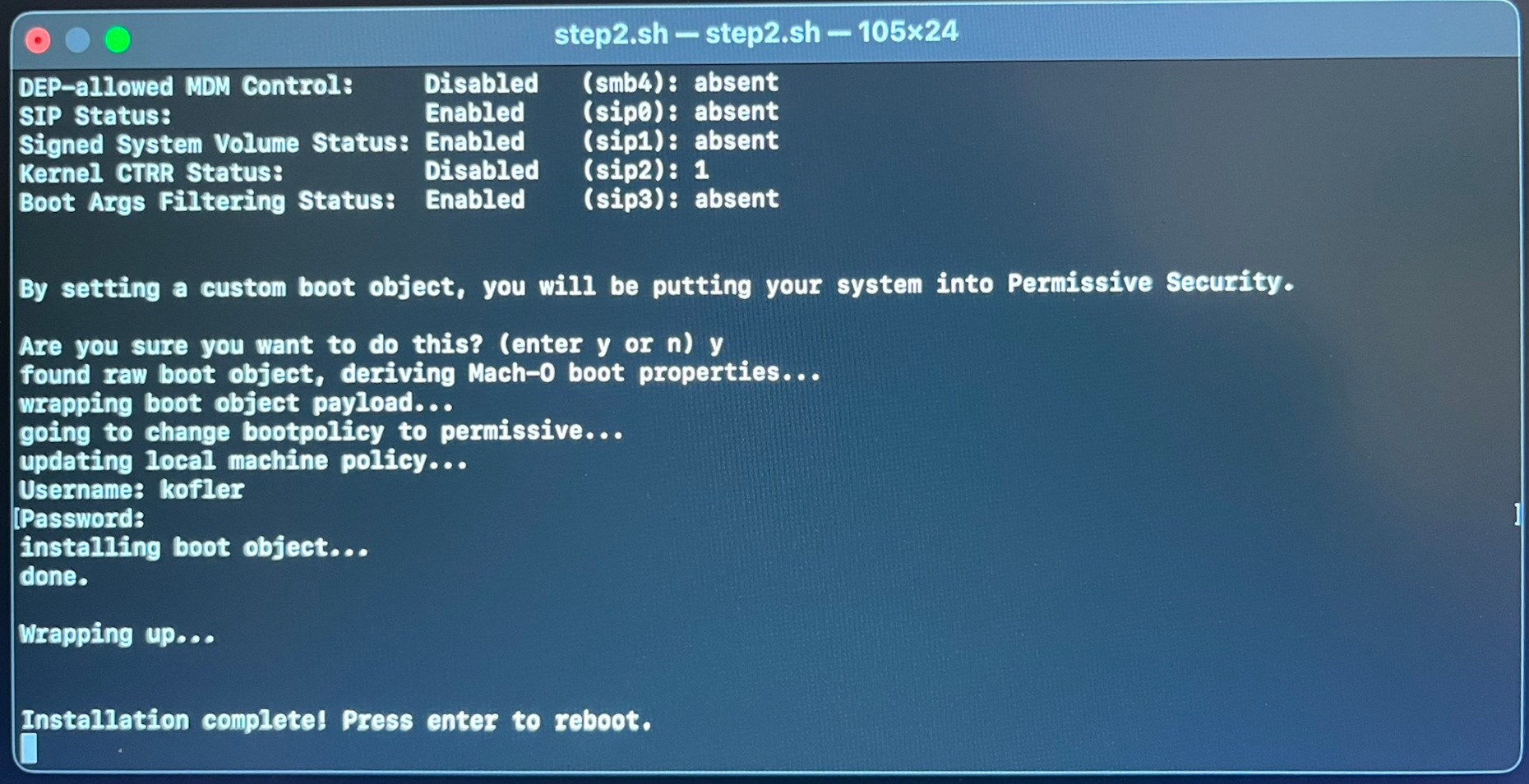
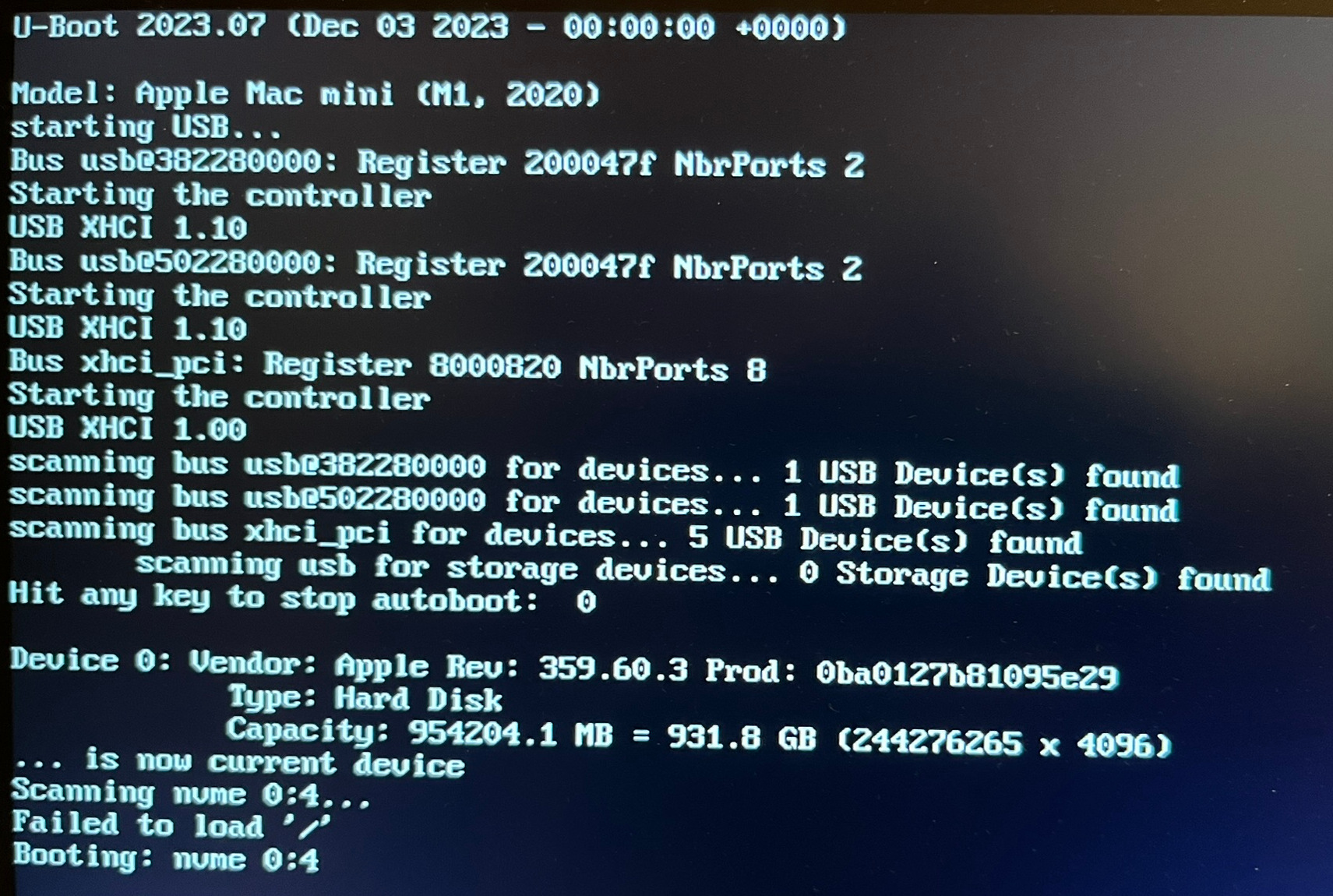
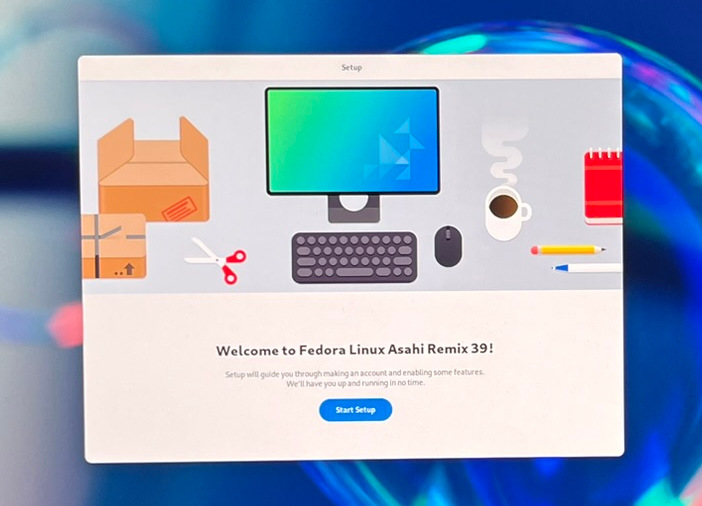
Fedora Linux läuft zum ersten Mal. Nun müssen Sie einige grundlegende Konfigurationsschritte erledigen (User-Name + Passwort, WLAN, Sprache, Tastaturlayout, Update).
Der Bootprozess ist jetzt so eingerichtet, dass bei jedem Neustart automatisch Fedora gestartet wird. Wenn Sie macOS verwenden möchten, müssen Sie den Rechner zuerst komplett herunterfahren. Dann drücken Sie wieder die Power-Taste, halten Sie ca. 15 Sekunden gedrückt, bis das OS-Menü erscheint, und wählen macOS.
Unter macOS können Sie das Default-OS voreinstellen. Es ist aber leider nicht möglich, den Mac so zu konfigurieren, dass bei jedem Bootprozess automatisch das Auswahlmenü erscheint. Sie müssen sich für eine Hauptvariante entscheiden. Jeder Bootprozess in ein anderes OS bleibt mühsam (Power-Taste 15 Sekunden drücken …).
Wie schnell ist Linux im Vergleich zu macOS? Ich habe auf meinem Mac Mini M1 Geekbench 6 jeweils unter macOS und unter Fedora Asahi ausgeführt. Das Ergebnis: im Rahmen der Messgenauigkeit etwa gleich schnell.
Single Multi Core
---------- ---------- ------------
macOS 2360 8050
Fedora 2357 7998
Das ist eine gute Frage. Hat man „IPv6… Kein Anschluss unter dieser Nummer“ gelesen, kann man mich sicher fragen, warum ich mir das antue, wo doch überall Stolpersteine und Probleme lauern. Und ich kenne einige Personen, die sich lieber eine Axt ins Bein schlagen, eine Nadel unter die Fingernägel schieben oder Broccoli essen würden, statt sich mit IPv6 zu beschäftigen.
Die Antwort ist ganz einfach. Ich tue dies, weil ich es kann, Spaß daran habe und IPv4-Adressen knapper und teurer werden.
Möchte man Dienste im Internet anbieten, benötigt man IP-Adressen. Üblicherweise bekommt man zu den gängigen Angeboten von Virtual Private Server, Dedicated Server, etc. eine IPv4-Adresse und ein /64-IPv6-Netzsegment kostenlos. Zusätzliche IPv4-Adressen kosten Stand heute zwischen 2,00 € und 5,00 € pro Monat, wobei häufig noch eine saftige Einrichtungsgebühr hinzukommt. Im Abschnitt Preisübersicht findet ihr das Ergebnis einer kurzen Internetrecherche.
Da ich einen Proxmox-Host und ein /64-IPv6-Netzsegment für Spiel-, Spaß- und Laborumgebungen besitze, möchte ich mich gern damit auseinandersetzen. Und sei es nur, um zu lernen, wo es noch überall klemmt und mit welchen Workarounds man die existierenden Klippen umschiffen kann. Wundert euch also nicht, wenn es in Zukunft noch den ein oder anderen Artikel zu diesem Thema gibt.
Heute möchte ich noch einmal ein Thema aus der Mottenkiste holen, welches ja eigentlich schon abgehakt sein sollte. Es geht um das Upgrade von Raspbian 10 auf das Raspberry Pi OS 11.
Anlass des Ganzen ist unsere Community-Cloud mit über 25 Nutzern. Diese Cloud wurde vor über fünfeinhalb Jahren zum Zwecke des Datenteilens ins Leben gerufen. Durch einen bedingten öfteren Standortwechsel verblieb das System auf einem Softwarestand von vor über zwei Jahren. Jetzt im neuen Zuhause stand dadurch ein gründlicher Tapetenwechsel an. D.h., dass im ersten Schritt das Betriebssystem auf Raspberry Pi OS 11 Bullsleye angehoben werden musste, bevor die Nextcloud von Version 22 auf 27 aktualisiert wurde. Weiterhin musste parallel PHP 7.3 auf Version 8.1 gezogen werden, um wieder in sicheres Fahrwasser zu gelangen. Bei der Hardware handelt es sich um einen Raspberry Pi 3 Model B. Auch dieses Gerät soll im laufe des Jahres noch ein Refresh erhalten.
Nun zum Upgrade auf das erwähnte Raspberry Pi OS 11.
Hilfreich bei der Installation war die Anleitung von linuxnews.de, die ich abschließend noch um zwei Punkte ergänzen musste. Hierbei konnte ich mich noch an mein erstes Upgrade dieser Art erinnern, dass es zu Unverträglichkeiten mit dem Desktop kam. Dieses Problem wird ganz am Ende des Artikels behandelt.
Zuerst wurde ein vollständiges Upgrade auf die aktuellste Version Raspbian 10 durchgeführt.
sudo apt update sudo apt full-upgrade sudo rpi-update
Danach wurden die Quellen auf Bullseye angepasst.
sudo sed -i 's/buster/bullseye/g' /etc/apt/sources.list sudo sed -i 's/buster/bullseye/g' /etc/apt/sources.list.d/raspi.list
Im Anschluss folgte ein Update der Quellen und die erforderliche Installation von gcc-8.
sudo apt update && sudo apt install libgcc-8-dev gcc-8-base sudo apt full-upgrade sudo apt -f install
Danach wurden unnötige Pakete und verbliebene heruntergeladene Pakete entfernt.
sudo apt autoremove sudo apt clean
Nun mussten noch die Kernelbased Mode-Setting (KMS) in der /boot/config.txt angepasst werden. Hierzu wurden folgende zwei Befehle ausgeführt:
sudo sed -i 's/dtoverlay=vc4-fkms-v3d/#dtoverlay=vc4-fkms-v3d/g' /boot/config.txt sudo sed -i 's/\[all\]/\[all\]\ndtoverlay=vc4-kms-v3d/' /boot/config.txt
Nach dem Reboot mit angeschlossenem Monitor fiel auf, dass sich das Programm Parcellite in der Menüleiste verewigt hatte. Parcellite war vor dem Systemupgrade auf Raspberry Pi OS 11 Bullseye nicht an Bord. Aus diesem Grund konnte es auch ohne Bedenken gelöscht werden.
sudo apt remove parcellite
Weiterhin fiel auf, dass die ganze Menüleiste des Desktops etwas vermurkst aussah. Diese wurde auf die Grundeinstellungen mit
cd ~/ sudo rm -rf .cache
zurückgesetzt.
Nach einem erneuten Reboot läuft Raspberry Pi OS 11 wie gewünscht.
sudo reboot


Um unsere Community-Cloud wieder sicher zu machen, war ein wenig Wochenendarbeit nötig. Die so investierte Zeit hat sich aber durchaus gelohnt. Im nächsten Schritt erfolgt dann der Tausch des Raspberry Pi und ein Wechsel der Daten-SSD gegen ein größeres Modell.
Ein MQTT-Broker ist die Schnittstelle zwischen vielen IoT-Sensoren und Geräten, die Sensordaten auswerten oder Aktoren steuern. Das MQTT-Protokoll ist offen und sehr weit verbreitet. Es findet in der Industrie Anwendungen, ist aber auch in Smart Homes ist MQTT weit verbreitet.
MQTT ist ein sehr schlankes und schnelles Protokoll. Es wird in Anwendungen mit niedriger Bandbreite gerne angewendet.
MQTT funktioniert, grob gesagt, folgendermaßen: IoT-Geräte können Nachrichten versenden, die von anderen IoT-Geräten empfangen werden. Die Vermittlungsstelle ist ein sogenannter MQTT-Broker. Dieser empfängt die Nachrichten von den Clients. Gleichzeitig können diese Nachrichten von anderen Clients abonniert werden. Die Nachrichten werden in sog. Topics eingestuft, die hierarchisch angeordnet sind, z.B. Wohnzimmer/Klima/Luftfeuchtigkeit.
Home Assistant, oder ein anderer Client, kann diesen Topic abonnieren und den Nachrichteninhalt („Payload„) auswerten (z.B. 65%).

In Home Assistant OS und Supervisor gibt es ein Addon, das einen MQTT-Broker installiert. Das ist sehr einfach, komfortabel und funktioniert wohl recht zurverlässig. In den Installationsarten Home Assistant Container und Core gibt es diese Möglichkeit nicht. Hier muss man manuell einen MQTT-Broker aufsetzen.
In diesem Artikel beschäftige ich mich damit, wie man den MQTT-Brocker Mosquitto über Docker installiert. Anschließend zeige ich, wie man die Konfigurationsdatei gestaltet und eine Verbindung zu Home Assistant herstellt. Das Ergebnis ist dann ungefähr so, als hätte man das Addon installiert. Los gehts!
Als MQTT-Broker verwende ich die weit verbreitete Software Mosquitto von Eclipse. Dieser wird auch von Home Assistant bevorzugt und ist derjenige Broker, den das Addon installieren würde.
Für diese Anleitung wird vorausgesetzt, dass Docker bereits installiert ist und eine SSH-Verbindung zum Server hergestellt werden kann.

Schritt 1: Zunächst erstellen wir ein paar Ordner, die wir später benötigen. Mosquitto wird später so konfiguriert, dass in diese Ordner alle wichtigen Dateien abgelegt werden. Dadurch kann man auf dem Filesystem des Servers Mosquitto konfigurieren und beobachten.
$ mkdir mosquitto $ mkdir mosquitto/config $ mkdir mosquitto/data $ mkdir mosquitto/log
Schritt 2: Nun wird die Konfigurationsdatei für Mosquitto erstellt. Über diese Datei kann man das Verhalten von Mosquitto steuern.
$ nano config/mosquitto.conf
persistence true persistence_location /mosquitto/data/ log_dest file /mosquitto/log/mosquitto.log log_dest stdout password_file /mosquitto/config/mosquitto.passwd allow_anonymous false listener 1883
Schritt 3: Mit dem folgenden Befehl lädt man sich das aktuelle Image von Eclipse Mosquitto auf den Server.
$ docker pull eclipse-mosquitto
Schritt 4: Mit dem folgenden Befehl wird der Docker-Container gestartet. Das ist der Schlüsselmoment, jetzt muss alles klappen.
$ docker run -it -p 1883:1883 -p 9001:9001 --name mosquitto -v /home/pi/mosquitto/config:/mosquitto/config -v /home/pi/mosquitto/data:/mosquitto/data -v /home/pi/mosquitto/log:/mosquitto/log eclipse-mosquitt
Die Flags bedeuten hierbei folgendes:
Wer lieber Docker Compose verwendet, trägt diesen Eintrag in seine *.yaml ein:
services:
eclipse-mosquitto:
stdin_open: true
tty: true
ports:
- 1883:1883
- 9001:9001
restart: unless-stopped
container_name: mosquitto
volumes:
- /home/pi/mosquitto/config:/mosquitto/config
- /home/pi/mosquitto/data:/mosquitto/data
- /home/pi/mosquitto/log:/mosquitto/log
image: eclipse-mosquittoSchritt 5: Checken, ob der Container ordnungsgemäß läuft. In der folgenden Liste sollte eine Zeile mit dem Mosquitto-Docker auftauchen. Dieser sollte außerdem „up“ sein. Falls nicht, nochmal versuchen den Container zu starten und kontrollieren, ob er läuft.
$ docker container ls -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES xxxxxxxxx eclipse-mosquitto "/init" 3 minutes ago Up 2 minutes [...] mosquitto
Schritt 6: Sehr gut, der Container läuft. Es wird dringend empfohlen, den MQTT-Broker so abzusichern, dass nur angemeldete User darauf zugreifen können. Das ist ja schon in Schritt 2 in die Konfigurationsdatei geschrieben worden. Mit dem folgenden Befehl melden wir uns in der Shell innerhalb des Containers an und erstellen einen Benutzer. In diesem Beispiel mosquitto. Im Anschluss an diesen Befehl wird man zweimal gebeten, das Passwort für den User festzulegen. Ist das geschafft, läuft der MQTT-Broker auf dem Server. Herzlichen Glückwunsch!
$ docker exec -it mosquitto sh // öffnet die Shell innerhalb des Dockers
mosquitto_passwd -c /mosquitto/config/mosquitto.passwd mosquitto
Optional Schritt 7: Den MQTT-Broker bindet man in Home Assistant ein, indem man auf Einstellungen → Geräte und Dienste → + Integration hinzufügen klickt. Im Suchfenster nach „MQTT“ suchen und die Zugangsdaten eingeben.
Die Server-Adresse findet man übrigens am schnellsten über ifconfig heraus.

The post MQTT-Broker Mosquitto als Docker Container installieren first appeared on bejonet - Linux | Smart Home | Technik.
Ein neuer adminForge Service kann ab sofort genutzt werden.
Mit der kostenlosen Open Source Lösung unbox.at schützt du deinen Posteingang mit E-Mail-Aliasnamen. Antworte anonym auf weitergeleitete E-Mails. Der Absender erhält die E-Mail so, als käme sie von deinem Alias. Oder starte eine Konversation direkt von deinem Alias aus.

Software: addy.io
Euer adminForge Team
| Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld. Unterstütze unsere Arbeit mit einer Spende und diskutiere ins unserem Chat mit. |

by adminForge.
Noch rund 40 Tage verbleiben bis zum geplanten Release von Plasma 6. Die Planung und Ausführung erscheinen fast generalstabsmäßig und lassen einen nahtlosen Übergang erwarten.

Das ist der dritte Teil einer Mini-Serie zur GPIO-Nutzung am Raspberry Pi 5:
Genau genommen hat die Kamera-Nutzung nicht unmittelbar etwas mit GPIOs zu tun. Allerdings ist für die Kommunikation mit der Kamera ebenfalls der neu im Pi 5 integrierte RP1-Chip verantwortlich. Der Chip ist der Grund, weswegen alte Kamera-Tools auf dem Raspberry Pi 5 nicht mehr funktionieren. Bevor Sie zu schimpfen beginnen: Der RP1 hat viele Vorteile. Unter anderem können Sie nun zwei Kameras gleichzeitig anschließen und nutzen und höhere Datenmengen übertragen (wichtig für Videos).
Beachten Sie, dass Sie beim Raspberry Pi 5 zum Kamera-Anschluss ein neues, schmaleres Kabel benötigen!

Im Terminal bzw. in Bash-Scripts funktionieren raspistill, raspivid usw. nicht mehr. Sie müssen stattdessen rpicam-still, rpicam-vid etc. einsetzen.
In Python-Scripts müssen Sie Abschied vom picamera-Modul nehmen. Stattdessen gibt es das vollkommen neue Modul Picamera2. Es bietet (viel) mehr Funktionen, ist aber in der Programmierung komplett inkompatibel. Vorhandene Scripts können nicht portiert werden, sondern müssen neu entwickelt werden.
Sowohl die rpicam-xxx-Kommandos als auch das Picamera2-Modul greifen auf die ebenfalls neue Bibliothek libcamera2 zurück.
Im einfachsten Anwendungsfall erzeugen Sie ein Picamera2-Objekt, machen mit der Methode start_and_capture_file ein Foto und speichern dieses in eine Datei. Dabei kommt die volle Auflösung der Kamera zur Anwendung, beim Camera Module 3 immerhin fast 4600×2600 Pixel.
#!/usr/bin/env python3
# Beispieldatei camera.py
from picamera2 import Picamera2
cam = Picamera2()
# ein Foto machen und speichern
cam.start_and_capture_file("test.jpg")
Anstelle von start_and_capture_file gibt es zwei weitere Methoden, um ebenso unkompliziert Bilderfolgen bzw. Videos aufzunehmen:
# 10 Bilder im Abstand von 0,5 Sekunden aufnehmen
# mit Dateinamen in der Form series-0003.jpg
cam.start_and_capture_files("series-{:0>4d}.jpg",
num_files=10,
delay=0.5)
# Video über 10 Sekunden aufnehmen (640x480 @ 30 Hz, H.264/AVC1)
cam.start_and_record_video("test.mp4", duration=10)
Zum Test der Kamera sowie zur Aufnahme von Bildern und Videos stehen die folgenden neuen Kommandos zur Auswahl:
rpicam-jpeg, Optionen etwas kompatibler zu raspistill)Die Kommandos sind mit all ihren Optionen großartig dokumentiert. Es gibt zwar keine man-Seiten, aber dafür liefern die Kommandos mit der Option -h eine lange Liste aller Optionen (z.B. rpicam-still -h). Ich beschränke mich hier auf einige einfache Anwendungsbeispiele.
# fünf Sekunden lang ein Vorschaufenster anzeigen, dann
# ein Foto aufnehmen und speichern
rpicam-jpeg -o image.jpg
# ohne Vorschau, Aufnahme nach einer Sekunde (1000 ms)
rpicam-jpeg -n -t 1000 -o image.jpg
# wie oben, aber Debugging-Ausgaben nicht anzeigen
rpicam-jpeg -n -t 1000 -v 0 -o image.jpg
# Bildgröße 1280x800
rpicam-jpeg --width 1280 --height 800 -o image.jpg
# heller/dunkler (EV Exposure Compensation)
rpicam-jpeg --ev 0.5 -o brighter.jpg
rpicam-jpeg --ev -0.5 -o darker.jpg
# erstellt ein 10 Sekunden langes Video (10.000 ms)
# 640x480@30Hz, H264-Codec
rpicam-vid -t 10000 -o test.mp4
# wie vorher, aber höhere Auflösung
rpicam-vid --width 1024 --height 768 -t 10000 -o test.mp4
Falls Sie mehr als eine Kamera angeschlossen haben, können Sie diese mit rpicam-hello --list-cameras auflisten. Die bei einer Aufnahme gewünschte Kamera können Sie mit der Option rpicam-xxx --camera <n> festlegen.
picamera2 ist ein relativ neues Python-Modul. Es ersetzt das früher gebräuchliche Modul picamera. Der Hauptvorteil von picamera2 besteht darin, dass das Modul zu aktuellen Raspberry-Pi-Modellen kompatibel ist. Beim Raspberry Pi 5 kommt picamera2 auch mit dem Fall zurecht, dass Sie zwei Kameras gleichzeitig an Ihren Minicomputer angeschlossen haben.
Eine umfassende Referenz aller Klassen und Methoden finden Sie in der exzellenten Dokumentation (nur im PDF-Format verfügbar), die allerdings weit mehr technische Details behandelt, als Sie jemals brauchen werden. Eine Menge Beispiel-Scripts finden Sie auf GitHub.
Mit create_still_configuration können Sie in diversen optionalen Parametern Einstellungen vornehmen. Das resultierende Konfigurationsobjekt übergeben Sie dann an die configure-Methode. Wichtig ist, dass Sie das Foto nicht mit start_and_capture_file aufnehmen, sondern dass Sie die Methoden start und capture_file getrennt ausführen. Die folgenden Zeilen zeigen, wie Sie ein Bild in einer Auflösung von 1024×768 Pixel aufnehmen. Die sleep-Aufforderung verbessert die Qualität des Bilds. Sie gibt der Kamera-Software etwas Zeit, um die Aufnahme zu fokussieren und richtig zu belichten.
#!/usr/bin/env python3
from picamera2 import Picamera2, Preview
import time
# ein Foto in reduzierter Auflösung aufnehmen
cam = Picamera2()
myconfig = cam.create_still_configuration(
main={"size": (1024, 768)} )
cam.configure(myconfig)
cam.start()
time.sleep(0.5)
cam.capture_file("1024x768.jpg")
Mit Transformationen können Sie das aufgenommene Bild vertikal und horizontal spiegeln. Falls Sie die Kamerakonfiguration während der Ausführung eines Scripts ändern möchten, müssen Sie die Kamera vorher stoppen und danach neu starten.
# (Fortsetzung des obigen Listings)
cam.stop()
from libcamera import Transform
mytrans = Transform(hflip=True)
myconfig = cam.create_still_configuration(
main={"size": (1024, 768)},
transform=mytrans)
cam.configure(myconfig)
cam.start()
time.sleep(0.5)
cam.capture_file("1024x768-hflip.jpg")
Bei der Aufnahme von Videos haben Sie die Wahl zwischen drei Encodern, die die aufgenommenen Bilder in Video-Dateien umzuwandeln:
H264Encoder (Hardware-Encoder für H.264, kommt per Default zum Einsatz, max. 1080p@30 Hz)MJPEGEncoder (Hardware-Encoder für Motion JPEG = MJPEG)JpegEncoder (Software-Encoder für MJPEG) Hardware-Encoding steht nur auf dem Raspberry Pi 4 (H.264 und MJPEG) und dem Raspberry Pi 5 (nur H.264) zur Verfügung. Beim Raspberry Pi 5 läuft der MJPEGEncoder also per Software.
Das folgenden Script soll ein Video im Format 720p aufnehmen und gleichzeitig ein Vorschaubild anzeigen. Dabei soll der H.264-Codec eingesetzt werden.
#!/usr/bin/env python3
from picamera2 import Picamera2, Preview
from picamera2.encoders import H264Encoder, Quality
import time
cam = Picamera2()
myconfig = cam.create_video_configuration(
main={"size": (1280, 720)}) # Auflösung 720p
myencoder = H264Encoder()
cam.configure(myconfig)
cam.start_preview(Preview.QTGL)
time.sleep(0.5)
cam.start_recording(myencoder,
"test-720p.mp4",
quality=Quality.MEDIUM)
time.sleep(10)
cam.stop_recording()
cam.stop_preview()
Das Script zeigt zwar keine Fehlermeldungen an, allerdings lässt sich die Video-Datei nicht abspielen, weder mit VLC am Raspberry Pi noch mit anderen Video-Playern auf anderen Rechnern. Ich habe tagelang mit den Video-Funktionen von Picamera2 experimentiert, aber die resultierenden Videos waren meist schwarz oder enthielten nur ein Bild, das am Beginn der Aufnahme entstanden ist. Auch die auf der folgenden Seite gesammelten Beispiel-Scripts zum Video-Recording funktionierten bei meinen Tests entweder gar nicht oder nur mit Einschränkungen:
https://github.com/raspberrypi/picamera2/tree/main/examples
Fazit: Die Video-Funktionen von Picamera2 sind aktuell (Anfang 2024) ebenso ambitioniert wie unausgereift. Es ist zu hoffen, dass neue Versionen von libcamera und Picamera2 und eine bessere Dokumentation der Grundfunktionen in Zukunft Abhilfe schaffen. Was nützen coole Spezial-Features, wenn es schon bei den einfachsten Grundfunktionen Probleme gibt?
Wine ist eine Laufzeitumgebung zur Ausführung von moderner Windows-Software und Games unter Linux, Chrome OS, macOS und anderen Plattformen. Einmal

Das Jahr 2024 ist nun schon zwei Wochen alt. Dennoch möchte ich noch einen Blick zurückwerfen und mich erinnern, wie das Jahr 2023 für meinen Blog verlaufen ist.
In 2023 wurden auf My-IT-Brain insgesamt 45 Artikel veröffentlicht. Dies sind 16 mehr als in 2022 und 14 mehr als in 2021. Jeden Monat sind mindestens zwei Artikel veröffentlicht worden.
Die Themen waren dabei wieder bunt gemischt. Allein Artikel über die Red Hat Enterprise Linux (RHEL) System Roles zogen sich wie ein roter Faden durch den Blog. Welche Artikel haben denn euch am besten gefallen? Lasst es mich gerne in den Kommentaren wissen.
Ich hoffe, es war für jeden von euch etwas Interessantes mit dabei und ihr folgt diesem Blog auch in 2024. Ihr könnt mir auch gerne Anregungen in die Kommentare schreiben, welche Themen ihr hier gerne behandelt sehen wollt. Vielleicht greife ich ja einige davon auf.
Und nun aber auf in ein spannendes Jahr 2024!

Ayaneo erweitert das zuletzt durch die Bank weg kostspielige Portfolio an Gaming-Handhelds um ein günstigeres Modell, das ab 299 USD zu haben ist. Das Ayaneo Next Lite setzt zu diesem Zweck auf eine vier Jahre alte Ryzen-Plattform und verzichtet auf Windows, stattdessen kommt wie beim Steam Deck Linux zum Zuge.
Wärmepumpen sind ökologisch umso sinnvoller, je größer der Anteil erneuerbarer Energie bei der Stromerzeugung ist. In unserem Wärmepumpenbuch gibt es eine Tabelle mit Zahlen von 2021/2022. In den letzten Tagen wurden aktualisierte Zahlen für das vergangene Jahr 2023 veröffentlicht — und die sind sehr erfreulich!
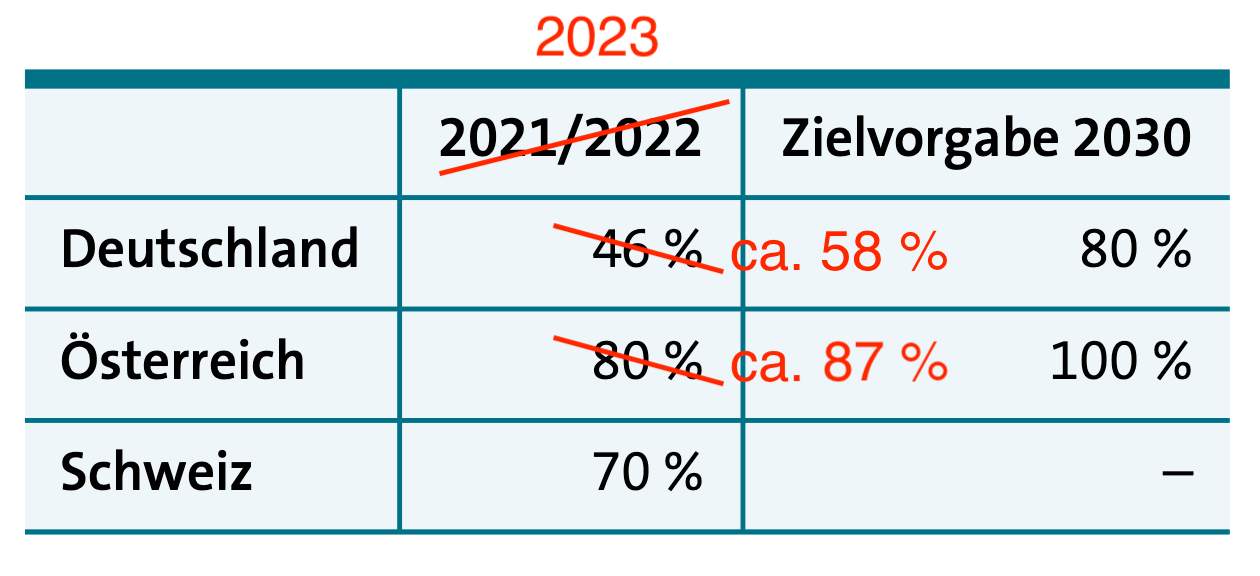
Anmerkung: Es gibt unterschiedliche Zahlen für den Anteil der erneuerbaren Energien (EE) am Strom, je nachdem, ob der Anteil relativ zur Erzeugung oder zur Nutzung des Stroms berechnet wird, ob Import/Export aus dem bzw. in das Ausland mit berücksichtigt wird und ob die betriebseigene Stromerzeugung durch eigene Kraftwerke in Bergbau, Industrie und Zugverkehr miteinberechnet wird oder nicht (dieser Strom zählt nicht zum offiziellen »Strommix«). Außerdem versorgen sich immer mehr Betriebe und Haushalte zumindest stundenweise selbst mit PV-Strom. Diese Strommengen können nicht genau erfasst werden, was eine korrekte Berechnung noch schwieriger macht. Dementsprechend variiert der EE-Anteil je nach Berechnungsmethode und Quelle ein wenig (ein bis zwei Prozent auf oder ab).
Für die Schweiz habe ich noch keine 2023er-Zahlen gefunden.
Ich habe mich entschlossen, die Kommentare in meinem Blog abzuschalten. Ursprung war wie immer der Frühjahrsputz in dem Blog. Hierzu habe ich eine Funktion genutzt, welche neben den Kommentaren auch die Trackbacks und Pings entfernt.Ein sehr großer Vorteil ist, dass ich die alten Kommentare hierdurch noch behalte. Früher übernahm das Plugin My Custom Functions von ... Weiterlesen
Der Beitrag PHP Code entfernt Kommentarfunktion in WordPress erschien zuerst auf Got tty.
Das ist der zweite Teil einer Mini-Serie zur GPIO-Nutzung am Raspberry Pi 5:
Zu den wichtigsten Neuerungen beim Raspberry Pi 5 zählt nicht nur der viel schnellere SoC (System-on-a-Chip), sondern auch ein eigener I/O-Controller, der als eigener Chip realisiert ist (RP1). Dieser I/O-Chip bringt mit sich, dass etablierte Mechanismen zur GPIO-Steuerung nicht mehr funktionieren. Besonders stark betroffen sind Kommandos, die im Terminal oder in Bash-Scripts aufgerufen werden.
Im Verlauf eines Jahrzehnts haben sich diverse Kommandos etabliert, die mittlerweile veraltet sind. Dazu zählt das Kommando gpio aus dem WiringPi-Projekt, das bereits 2019 eingestellt wurde. Ebenfalls verabschieden müssen Sie sich von dessen Nachfolger-Kommando raspi-gpio: Das Kommando ist nicht mit dem neuen I/O-Chip RP1 kompatibel. Glücklicherweise lässt sich das Kommando relativ einfach durch pinctrl ersetzen.
Deutlich ärgerlicher ist, dass auch der beliebte Dämon pigpiod und das dazugehörende Kommando pigs der Kompatibilität zu RP1 zum Opfer gefallen ist. Absurderweise kann der Dienst Anfang 2024 im Raspberry-Pi-Konfigurationsprogramm als GPIO-Fernzugriff scheinbar weiterhin aktiviert werden.
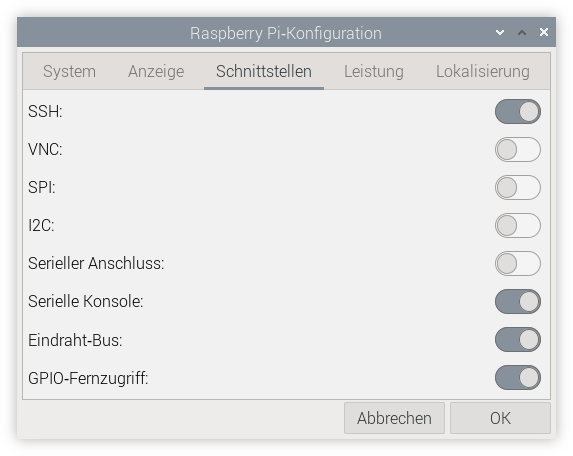
journalctl -u pigpiod beweist aber, dass der Dienst nicht funktioniert:
journalctl -u pigpiod
systemd[1]: Starting pigpiod.service - Daemon required to control GPIO pins via pigpio...
systemd[1]: Started pigpiod.service - Daemon required to control GPIO pins via pigpio.
pigpiod[88161]: 2023-12-29 11:02:24 gpioHardwareRevision: unknown rev code (d04170)
pigpiod[88161]: 2023-12-29 11:02:24 initCheckPermitted:
pigpiod[88161]: +---------------------------------------------------------+
pigpiod[88161]: |Sorry, this system does not appear to be a raspberry pi. |
pigpiod[88161]: |aborting. |
pigpiod[88161]: +---------------------------------------------------------+
pigpiod[88161]: Can't initialise pigpio library
systemd[1]: pigpiod.service: Main process exited, code=exited, status=1/FAILURE
systemd[1]: pigpiod.service: Failed with result 'exit-code'.
Das Problem ist bekannt, aber es sieht nicht so aus, als könnte es behoben werden: https://github.com/joan2937/pigpio/issues/589
Welche Kommandos funktionieren dann noch? Sie haben die Wahl zwischen den gpioxxx-Kommandos aus dem Paket gpiod sowie pinctrl (siehe den folgenden Abschnitt). Das Paket gpiod ist standardmäßig installiert. Die darin enthaltenen Kommandos nutzen zur Kommunikation mit dem Kernel die Device-Dateien /dev/gpiochip<n> und die Bibliothek libgpiod2.
Der größte Nachteil der Kommandos gpioget, gpioset usw. besteht darin, dass Sie als ersten Parameter die GPIO-Chip-Nummer angeben müssen. Diese variiert je nach Raspberry-Pi-Modell. Bei den Modellen der Serie 1 bis 4 müssen Sie die Nummer 0 angeben, ab Modell 5 die Nummer 4.
# LED ein- und ausschalten, die über den GPIO 7 gesteuert wird
# (= Pin 26 des J8-Headers)
# gpioset auf dem Raspberry Pi 5
gpioset 4 7=1; sleep 3; gpioset 4 7=0
# gpioset auf dem Raspberry Pi 1 bis 4
gpioset 0 7=1; sleep 3; gpioset 0 7=0
Warum variiert die GPIO-Chip-Nummer? Weil beim Raspberry Pi 4 die Kernel-Schnittstelle /dev/gpiochip0 für die GPIO-Steuerung verantwortlich ist (das sind in den BCM 2711 integrierte Funktionen), beim Pi 5 aber der RP1 (ein externer Chip) mit der Kernel-Schnittstelle /dev/gpiochip4. Informationen darüber, welche GPIO-Schnittstellen es gibt und welche GPIO-Funktion wie »verdrahtet« ist, geben die Kommandos gpiodetect und gpioinfo. Die folgenden Ausgaben gelten für den Raspberry Pi 5:
gpiodetect
gpiochip0 [gpio-brcmstb@107d508500] (32 lines)
gpiochip1 [gpio-brcmstb@107d508520] ( 4 lines)
gpiochip2 [gpio-brcmstb@107d517c00] (17 lines)
gpiochip3 [gpio-brcmstb@107d517c20] ( 6 lines)
gpiochip4 [pinctrl-rp1] (54 lines)
gpioinfo
gpiochip0 - 32 lines:
line 0: "-" unused input active-high
line 1: "2712_BOOT_CS_N" "spi10 CS0" output active-low
line 2: "2712_BOOT_MISO" unused input active-high
...
gpiochip1 - 4 lines:
line 0: "WIFI_SDIO_D0" unused input active-high
line 1: "WIFI_SDIO_D1" unused input active-high
...
gpiochip2 - 17 lines:
line 0: "RP1_SDA" unused input active-high
line 1: "RP1_SCL" unused input active-high
line 2: "RP1_RUN" "RP1 RUN pin" output active-high
...
gpiochip3 - 6 lines:
line 0: "HDMI0_SCL" unused input active-high
line 1: "HDMI0_SDA" unused input active-high
...
gpiochip4 - 54 lines:
line 0: "ID_SD" unused input active-high
line 1: "ID_SC" unused input active-high
line 2: "PIN3" unused input active-high
line 3: "PIN5" unused input active-high
line 4: "PIN7" "onewire@0" output active-high
line 5: "PIN29" "onewire@0" output active-low
line 6: "PIN31" unused input active-high
line 7: "PIN26" unused input active-high
line 8: "PIN24" unused input active-high
line 9: "PIN21" unused input active-high
line 10: "PIN19" unused input active-high
...
line 28: "PCIE_RP1_WAKE" unused input active-high
line 29: "FAN_TACH" unused input active-high
line 30: "HOST_SDA" unused input active-high
line 31: "HOST_SCL" unused input active-high
line 32: "ETH_RST_N" "phy-reset" output active-low
...
Um Scripts zu programmieren, die universell funktionieren, können Sie die folgenden Zeilen in den Code einbauen:
# chip=4 für RPi5, chip=0 für ältere Modelle
if gpiodetect | grep -q "pinctrl-rp"; then
chip=4
else
chip=0
fi
In der einfachsten Form schalten Sie mit gpioset einen GPIO-Ausgang auf High oder Low. In den folgenden Beispielen bezieht sich der erste Parameter auf die gpiochip-Nummer. 7 gibt die GPIO-Nummer in BCM-Nomenklatur an, 1 oder 0 den gewünschten Zustand:
gpioset $chip 7=1 # GPIO 7 (Pin 26) auf High stellen
gpioset $chip 7=0 # GPIO 7 (Pin 26) auf Low stellen
Sie können auch mehrere Ausgänge auf einmal steuern (hier GPIO 7, 8 und 25):
gpioset $chip 7=0 8=1 25=0
Durch diverse Optionen können Sie weitere Funktionen steuern (siehe auch man gpioset):
--bias=as-is|disable|pull-down|pull-up aktiviert die internen Pull-up- oder Pull-down-Widerstände.
--mode=exit|wait|time|signal gibt an, wie lange das Kommando laufen soll. Standardmäßig gilt exit, das Kommando wird also sofort beendet. Mit wait wartet das Programm, bis der Benutzer [Return] drückt. Bei der Einstellung time können Sie mit --sec=<n> oder --usec=<n> die gewünschte Wartezeit einstellen. signal bedeutet, dass das Programm weiterläuft, bis es mit [Strg]+[C] beendet wird.
--background führt das Kommando als Hintergrunddienst weiter.
gpioget funktioniert analog zu gpioset: Sie übergeben im ersten Parameter die gpiochip-Nummer (in aller Regel 0), im zweiten Parameter die BCM-Nummer des GPIOs, dessen Input Sie auswerten wollen. Das Ergebnis des Kommandos lautet 0 oder 1, je nachdem, welchen Zustand der Eingang hat.
gpioget $chip 9 # Zustand von GPIO 9 (Pin 21) auslesen
0
Auch mit pinctrl aus dem Paket raspi-utils können Sie GPIO-Funktionen steuern. Der Vorteil von pinctrl besteht darin, dass das Kommando zur Zeit mit allen Raspberry-Pi-Modellen kompatibel ist. Eine Fallunterscheidung, ob das Script auf einem alten oder neuen Modell mit RP1-Chip läuft, entfällt. Außerdem ist das Kommando syntaktisch weitestgehend zu raspi-gpio kompatibel.
Gegen den Einsatz des Kommandos spricht der Umstand, dass das Kommando laut pinctrl -h (der einzigen mir bekannten Dokumentation) nur für Debugging-Zwecke gedacht ist.
Die folgende Aufzählung fasst die wichtigsten Anwendungen des Kommandos zusammen:
pinctrl get [gpionr] ermittelt den aktuellen Status aller GPIOs bzw. des angegebenen GPIOs.
pinctrl funcs [gpionr] ermittelt, welche alternativen Funktionen der angegebene GPIO bzw. alle GPIOs erfüllen können.
pinctrl set gpionr options verändert den Status des angegeben GPIOs. Mögliche Optionen sind:
ip = Inputop = Outputdl = Zustand Low (Drive Low)dh = Zustand High (Drive High)pu = Pull-up-Widerstand aktivpd = Pull-down-Widerstand aktivpn = keine Pull-up/down-Funktiona0 bis a7 = alternative Funktion n aktivierenno = Deaktivieren (no function)Soweit sich sinnvolle Kombinationen ergeben, dürfen mehrere der obigen Optionen auf einmal übergeben werden, jeweils getrennt durch Leerzeichen. Welche alternative Funktionen ein GPIO unterstützt und wie sie nummeriert sind, geht aus pinctrl funcs hervor.
Das folgende Kommando ermittelt, welche Funktionen der GPIO mit der BCM-Nummer 23 unterstützt. Auf dem Raspberry Pi ist dieser GPIO mit Pin 16 des J8-Headers verbunden. GPIO23 kann diverse Funktionen übernehmen:
pinctrl funcs 23
23, PIN16/GPIO23, SD0_CMD, DPI_D19, I2S0_SDO1, SCL3,
I2S1_SDO1, SYS_RIO023, PROC_RIO023, PIO23
Wenn Sie über Pin 26 (BCM-Nummer 07) eine Leuchtdiode angeschlossen haben, dann können Sie die LED wie folgt ein- und ausschalten:
pinctrl set 7 op dh # LED an Pin 26 ein
pinctrl set 7 op dl # LED an Pin 26 aus
 Ihr findet ab sofort die adminForge Services auf der Startseite!
Ihr findet ab sofort die adminForge Services auf der Startseite!
Den Schritt fand ich sinnvoll, da die Webseite sich schon lange nicht mehr um Tutorials dreht, sondern um die Open Source Dienste.
Nun könnt ihr einfach https://adminforge.de aufrufen und die freien Services durchstöbern.
Euer adminForge Team
| Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld. Unterstütze unsere Arbeit mit einer Spende und diskutiere ins unserem Chat mit. |

by adminForge.
Im März 2023 wechselte ich von Flex-Work in eine neue Rolle, in der ich 100 % remote arbeite. Heute möchte ich meine Erfahrungen mit euch teilen, die ich bisher damit gemacht habe.
Bevor es richtig losgeht, schreibe ich etwas zur Terminologie der Remote-Arbeit. Denn hier geht es mit den Begrifflichkeiten teilweise ganz schön durcheinander. Daher möchte ich sicherstellen, dass ihr versteht, was ich mit bestimmten Begriffen meine.
Von allen verwendeten Begriffen ist dies der Einzige, welcher in Deutschland in der Arbeitsstättenverordnung definiert ist:
Telearbeitsplätze sind vom Arbeitgeber fest eingerichtete Bildschirmarbeitsplätze im Privatbereich der Beschäftigten, für die der Arbeitgeber eine mit den Beschäftigten vereinbarte wöchentliche Arbeitszeit und die Dauer der Einrichtung festgelegt hat. Ein Telearbeitsplatz ist vom Arbeitgeber erst dann eingerichtet, wenn Arbeitgeber und Beschäftigte die Bedingungen der Telearbeit arbeitsvertraglich oder im Rahmen einer Vereinbarung festgelegt haben und die benötigte Ausstattung des Telearbeitsplatzes mit Mobiliar, Arbeitsmitteln einschließlich der Kommunikationseinrichtungen durch den Arbeitgeber oder eine von ihm beauftragte Person im Privatbereich des Beschäftigten bereitgestellt und installiert ist.
ArbStättV §2 Abs.7
Erbringen Arbeitnehmende die geschuldete Arbeitsleistung zum Teil am Telearbeitsplatz und zum Teil in einem Büro des Arbeitgebers, wird von alternierender Telearbeit gesprochen.
Bei dieser Form ist der Arbeitgebende für die vollständige Ausstattung des Arbeitsplatzes mit Mobiliar und Arbeitsmitteln sowie der Einhaltung arbeitsrechtlicher Vorschriften (z.B. Ergonomie, UVV, Prüfung ortsveränderlicher Elektrogeräte, etc.) verantwortlich.
Diese Begriffe werden häufig verwendet, wenn Arbeitnehmende die geschuldete Arbeitsleistung teilweise außerhalb der Büroräume des Arbeitgebers erbringen und es sich nicht um Telearbeit handelt.
Angestellte erhalten hierbei häufig keine komplette Büroeinrichtung für den Telearbeitsplatz im privaten Raum, sondern lediglich die notwendigen Arbeitsmittel, wie z.B. Laptop und Telefon. Dafür dürfen sie häufig auch außerhalb der eigenen vier Wände bzw. des Büros z.B. aus einer Ferienwohnung arbeiten.
In manchen Fällen werden voll ausgestattete Büroarbeitsplätze für die Angestellten vorgehalten. In anderen Fällen existiert eine Form von Desksharing.
Details werden in Arbeitsverträgen, Betriebsvereinbarungen und Tarifverträgen geregelt.
Der Duden definiert das Wort Homeoffice wie folgt:
[mit Kommunikationstechnik ausgestatteter] Arbeitsplatz im privaten Wohnraum
URL: https://www.duden.de/rechtschreibung/Homeoffice
Der Begriff wird jedoch nicht einheitlich verwendet. Betrachtet man die Quellen [1]-[5], so wird er sowohl als Synonym für Telearbeit als auch als Oberbegriff für alle Formen von Arbeit verwendet, die nicht in Büroräumen des Arbeitgebers ausgeführt werden.
Wenn ich in diesem Text den Begriff Homeoffice verwende, meine ich damit mobile Arbeit, wie sie im folgenden Abschnitt beschrieben wird.
Bei der mobilen Arbeit sind Angestellte keinem Büro zugeordnet und nicht an einen Teleheimarbeitsplatz gebunden. Die geschuldete Arbeitsleitung kann von einem beliebigen Ort wie z.B. dem Auto, Café, Hotel oder dem Strand erbracht werden. Dies schließt die eigenen vier Wände jedoch explizit mit ein.
Dem Arbeitnehmenden werden bei dieser Form häufig nur die zwingend benötigten Arbeitsmittel wie Laptop, Mobiltelefon und ggf. Headset gestellt. Bring you own device ist ebenso möglich. Häufig erhalten Angestellte eine Pauschale, mit der sie benötigte Arbeitsmittel selbst beschaffen können.
Details werden auch hierbei im Arbeitsvertrag, in Betriebsvereinbarungen oder Tarifverträgen geregelt.
Nicht jede Tätigkeit ist dazu geeignet, im Homeoffice ausgeführt zu werden. Pflegepersonal kann den Beruf meist ebensowenig aus den eigenen vier Wänden ausüben wie Bus-, LKW-, Zug-Fahrer und Kapitäne. Auch Berufe mit Laufkundschaft eignen sich in der Regel schlecht für Arbeit außerhalb eines festen Büros.
Ich gehöre hingegen zu den glücklichen Menschen, deren Job von einem fast beliebigen Ort aus erfüllt werden kann. Die einzige Bedingung ist eine gute Daten- und Kommunikations-Verbindung. Meine berufliche Tätigkeit lässt sich dabei mit folgenden Stichpunkten beschreiben:
Mit diesen Merkmalen habe ich die besten Voraussetzungen, um nicht auf einen festen Arbeitsplatz beschränkt bzw. angewiesen zu sein.
Zu Beginn meines Arbeitsverhältnisses wurde ich mit folgenden Arbeitsmitteln ausgestattet:
Ausgeliefert wurde das System mit einem RHEL 8 Corporate Standard Build (CSB). Die Installation wird also von unserer internen IT verwaltet. Ich selbst habe sudo-Rechte auf dem System und fühle mich in keinster Weise eingeschränkt. Ich bin fasziniert, wie gut die Inbetriebnahme ablief und es so gut wie keine Probleme gab, wegen denen ich den IT-Support bemühen musste.
Bei dem Laptop handelte es sich nicht um ein topaktuelles Modell, doch ist es für meine tägliche Arbeit sehr gut geeignet. Ich nutze es täglich für die Arbeit mit:
Im Vergleich mit meinem privaten ThinkPad T14s ist das Gerät nach einigen Videokonferenzen deutlich lauter. Die Effizienz der CPU und Lüftersteuerung sind beim P1 nicht so gut wie beim T14s.
Das Thunderbold-Dock hingegen ist das schlechteste Dock, das ich je selbst benutzen musste. Dass für diesen elektronischen Briefbeschwerer im Online-Versandhandel zwischen 250,- und 300,- EUR aufgerufen werden, macht mich fassungslos. Hier funktioniert nichts, wie es soll. Und auch nach einer Firmware-Update-Orgie ändern sich die Fehler, in Summe bleiben sie jedoch gleich. Ich musste mich jedoch nicht lange damit ärgern. Da die Probleme bekannt sind, konnte ich mir ein Dock meiner Wahl beschaffen und die Kosten dafür erstatten lassen.
Zusätzlich zu diesen Arbeitsmitteln bekam ich noch ein Budget, für das ich mir weitere notwendige Arbeitsmittel kaufen konnte, plus ein separates Budget für ein Mobiltelefon. Von diesen Mitteln habe ich beschafft:
Zum Telefon gehört ein Vertrag. Ich konnte beides aus einer Liste auswählen. Zur Auswahl standen auch diverse Geräte von Apple, Samsung und weiteren Herstellern.

Mein Arbeitsplatz sieht in der Regel sehr aufgeräumt und unaufgeregt aus.
Ich besaß bereits vor meinem Jobwechsel einen höhenverstellbaren Schreibtisch, den ich mir für meinen Rücken gegönnt habe. Aus privater Tasche habe ich mir dann noch Bürostuhl Tailwind 2 mit Pending-System und Ponso-Sitzfläche beim lokalen Händler https://www.fair-kauf.net/ gekauft.
Wenn während der Zeit etwas kaputtgeht oder ich feststelle, dass mir doch noch etwas fehlt, bespreche ich dies mit meinem Manager. Bisher war es kein Problem, die Ausgaben für Anschaffungen, die ich sinnvoll begründen konnte, erstattet zu bekommen.
Ich bin mit meinen Arbeitsmitteln sehr zufrieden und kann meine Arbeit damit gut erledigen. Neben der Technik betrachte ich es als unschlagbaren Vorteil, ein eigenes Arbeitszimmer zu besitzen, welches nur von mir zum Zweck der Arbeit genutzt wird. Dies hat für mich folgende unschlagbare Vorteile:
Hinsichtlich Raum und Arbeitsmittel kann ich aktuell nichts bemängeln und fühle mich gut ausgestattet.
Kommunikation ist wichtig und findet statt, sobald sich mindestens zwei Menschen eine Situation teilen, sich am gleichen Ort oder in der gleichen Videokonferenz befinden. Die Kommunikation findet dabei auf unterschiedlichen Ebenen statt, der Sach- und der Beziehungsebene, wobei die Beziehungsebene die Sachebene bestimmt.
Eine Nachricht, die von Mensch zu Mensch übertragen wird, hat mehrere Seiten und muss vom Empfänger nicht so verstanden werden, wie der Sender sie gemeint hat.
Bei diesen Aussagen handelt es sich um Erkenntnisse von Paul Watzlawick und Friedemann Schulz von Thun aus der Kommunikationswissenschaft (siehe [7]-[10] in den Quellen unten). Kommunikation stellt einen sehr wichtigen Faktor bei der Arbeit dar und beeinflusst in hohem Maße die Produktivität sowie die Motivation der Angestellten.
Viele Artikel und Blogs verkürzen dieses Thema auf Aussagen wie:
Mich stört, wenn so getan wird, als wäre die Realität schwarz oder weiß. Ist sie doch in Wirklichkeit grau (ein Blick aus dem Fenster bestätigt dies aktuell) und liegt die Wahrheit doch meist in der Mitte.
Ich möchte hier die Kommunikationskultur in der Firma und dem Team beschreiben, wo ich aktuell beruflich zu Hause bin. Da ich zu 100 % remote arbeite, finden für mich, von wenigen Kundenbesuchen im Jahr abgesehen, fast alle Meetings per Videokonferenz oder Telefon statt. Die einzige Bewertung, die ich dabei vornehme ist, dass es mir persönlich gut gefällt.
Wie in vermutlich jeder Firma gibt es auch bei uns regelmäßig wiederkehrende Meetings. Dazu gehören unter anderem:
Kurz gesagt, die 40-Stunden-Woche bietet nicht genug Zeit, um an allen möglichen Meetings teilzunehmen. Doch das erwartet auch niemand.
Was mir gut gefällt:
Benötigt man ein paar zusätzliche Augen bzw. Ideen beim Troubleshooting bzw. der Suche nach Informationen, öffnet man ein virtuelles Meeting und lädt Kolleg*innen via Chat ein. Entweder wählt man einen Kanal mit vielen Mitgliedern und hofft, dass jemand kommt oder man schreibt Teilnehmer gezielt an. Dabei gebietet die Etikette, dass man vorher prüft, ob die entsprechende Person auch frei ist. Möglich ist dies mithilfe unserer Kalender oder des Status im Chat.
Dabei ähneln diese Meetings den Störungen im Büro, wo die Tür aufgeht und Kollegen mit ihren Sorgen, Nöten und Anträgen plötzlich vor dem eigenen Schreibtisch stehen. Vorteil der Remote-Arbeit ist in meinen Augen, dass die Hemmschwelle sich diesen Störungen zu entziehen geringer ist. Eine Meetinganfrage lehnt man schneller ab oder verlässt ein Meeting schneller, als jemanden aus dem Büro hinauszubitten.
Für mich ist wichtig, vorher zu überlegen, ob der synchrone Austausch einen Vorteil über asynchrone Kommunikation bietet. Dies ist zum Beispiel der Fall, wenn sich ein Sachverhalt nur umständlich in einer E-Mail erklären lässt, oder das Risiko eines Missverständnisses hoch ist. Grundsätzlich gebe ich der asynchronen Kommunikation den Vorzug, da ich Kollegen so nicht in ihrer Arbeit störe, sie in ihrer eigenen Zeit antworten können und E-Mails Beweise generieren.
Obwohl ich ausschließlich aus dem Homeoffice arbeite, habe ich das Gefühl, weniger Zeit in Meetings zu verbringen als zuvor. Gemessen habe ich dies jedoch nicht.
Kaffeeküchengespräche, Gesabbel beim Mittagessen und Flurfunk sterben bei mobiler Arbeit aus. Das stimmt in meiner Erfahrung so nicht.
Wir treffen uns sporadisch zum Kaffeetrinken in einer Videokonferenz und sprechen darüber, wie unser Tag so läuft, was es Neues gibt. Dabei werden sowohl dienstliche wie private Themen diskutiert.
Manche Kollegen treffen sich sogar in einer Videokonferenz, ohne aktiv miteinander zu sprechen. Man könnte auch sagen: „Sie schweigen sich konstruktiv an.“ Dies kann das Gefühl reduzieren, allein zu sein. Es ist jemand in der Nähe, der zuhört und in aller Regel auf geräuschvolle Äußerungen reagiert.
„Vermisse ich regelmäßige persönliche Treffen in der realen Welt? Nein.“
„Weiß ich diese Treffen dennoch zu schätzen? Ja.“
In meinen Augen ist dies kein Widerspruch in sich. Ich habe mich schnell daran gewöhnt, dass mein Team verteilt sitzt und die meisten Kontakte durch Chat, E-Mail und Videokonferenz stattfinden. Dennoch freue ich mich, diese Menschen am Rande von Veranstaltungen auch mal persönlich zu treffen. Besonders gern, wenn dies ungezwungen außerhalb formal organisierter Teambildungsmaßnahmen passiert.
Dies sind definitiv zwei meiner Hauptarbeitsmittel. Beide sind Werkzeuge zur asynchronen Kommunikation. Chat ist dabei in der Regel schneller als E-Mail, wobei ich persönlich E-Mails besser strukturieren kann und Dinge leichter in E-Mails wiederfinde.
Aus Gesprächen mit Menschen aus verschiedenen Unternehmen weiß ich, dass Chat Fluch und Segen sein kann. Dies ist jedoch kein technisches Problem, sondern hängt von der Unternehmenskultur und der persönlichen Disziplin ab. Wird erwartet, dass jeder zu jederzeit erreichbar ist und prompt reagiert, kann das die Produktivität ziemlich in den Keller drücken.
Setzt man einen Status wie verfügbar, beschäftigt, im Termin u.ä. und wird dies respektiert, kann Chat die Kommunikation wunderbar unterstützen. Das klappt selbst dann, wenn es mehrere Chats-Werkzeuge gibt.
Zum Glück werde ich nur sehr selten angerufen und ich rufe auch nur selten jemanden an. Warum? Ich empfinde unangekündigte Anrufe als Störung, denn sie unterbrechen meine Arbeit. Und was ich selbst nicht will, das man mir tu, das füge ich niemand anderem zu.
Das Telefon ist für mich ein Kommunikationsmittel für den Fall, wenn es etwas sehr Dringendes zu bereden gibt. Oder wenn ich weiß, dass es das bevorzugte Kommunikationsmittel der Person ist, von der ich etwas möchte.
Es gibt Dinge, die kann man am Telefon oder in einer Videokonferenz schneller bzw. einfacher klären als in einer langen Chat- oder E-Mail-Diskussion. Ich empfinde es dann allerdings als höflich, wenn man für das Telefonat einen Termin vereinbart, statt ohne Vorwarnung durchzuklingeln.
Mich freut es sehr, dass ich nicht ständig von eingehenden Anrufen und Video-Calls gestört werde.
Aktuell passt die Form der mobilen Arbeit, wie sie in meinem Team bei Red Hat gelebt wird, sehr gut zu meinen persönlichen Vorlieben und meiner Lebenssituation.
Mir gefällt es, dass ich in Ruhe und allein arbeiten kann, gleichzeitig aber ein guter Kontakt zu Kolleg*innen existiert, mit denen ich mich austauschen kann. Ich bin sehr zufrieden und hoffe, dass es noch lange so weitergeht.
Herausforderungen in der Zusammenarbeit und Kommunikation liegen in meiner Erfahrung meist in der Unternehmenskultur begründet und nur selten in der Technik. Daher empfehle ich allen, bei denen es nicht optimal läuft, über Anforderungen zu sprechen und erst danach über mögliche Programme zur Lösung derselben.
Euch wünsche ich, dass ihr ein Arbeits(zeit)modell findet, das gut zu euch passt. Wenn ihr Lust habt, teilt doch gern eure Erfahrungen mit eurer Arbeit im Büro, hybrid oder remote hier. Ich freue mich zu erfahren, wie ihr heute arbeitet und wie zufrieden ihr damit seid.
Es ist der 31.12.2023 und somit wird es wieder Zeit für den traditionellen Jahresrückblick. Dieses Jahr dominierten zwei Buchstaben: KI. Die Veröffentlichung von ChatGPT erfolgte zwar kurz vor 2023, in diesem Jahr wurden allerdings die Auswirkungen sichtbar. Ich muss sagen, dass es lange kein Werkzeug gab, an dem ich so viel Experimentierfreude erleben konnte.
Dabei ist die Mensch-Maschine-Schnittstelle besonders spannend. Die natürlichsprachliche Interaktion verbessert nicht nur die Zugänglichkeit, sondern erhöht auch die Interoperabilität: Das Werkzeug kann nicht nur die Aufgabe verstehen, sondern die Ergebnisse in der gewünschten Form darstellen. Schreibe ich eine Software, erfüllt sie nur einen Zweck. ChatGPT kann besonders einfach an neue Aufgabenbereiche angepasst werden. Man muss nicht einmal im klassischen Sinne "programmieren". Somit wird die Arbeit mit dem Computer auf eine ganz neue Stufe gehoben.
Auf die technische Ebene möchte ich heute gar nicht direkt eingehen, das haben wir das Jahr schon im Detail in diesem Blog ergründet. Diskussionen über Technik und Innovationen stellen nur eine Augenblickaufnahme dar. Im Rückblick auf eine größere Zeitepisode wie ein mindestens Jahr werden allerdings gesellschaftliche Entwicklungen deutlich. Und hier gab es einiges zu beobachten.
ChatGPT hat eine große Nutzerbasis erreicht, die zumindest ein Mal das Werkzeug ausprobiert hat. Im deutschsprachigen Raum, der sonst sich so "datenschutzorientiert" und innovationskritisch gibt, ist das schon bemerkenswert. Diskussionen über Datenschutz waren zweitrangig, die Menschen waren von der Innovation durch das Werkzeug fasziniert. Natürlich kam über das Jahr die Erkenntnis, dass in der aktuellen Form die Technologie je nach Branche noch nicht weit genug ausgereift ist, trotzdem wollte jeder einmal schauen, was es damit auf sich hat und ob es den Alltag erleichtern kann.
Und doch hat OpenAIs Werkzeug in meinen Augen ein wenig den Blick verengt: Durch das schnelle Wachstum wurde ChatGPT zum Sinnbild von "KI" und hat Ängste geschürt. Denn einerseits will jeder, dass KI ihm das Leben einfacher macht, jedoch nicht, dass andere mit KI ihm seine Lebenssituation verschlechtern bzw. ihn zu einem Umdenken zwingen. Ein Zeitungsredakteur möchte gerne KI für die Verbesserung seiner Texte einsetzen, fürchtet jedoch um seine Jobzukunft, wenn andere ihn durch automatische Generierung ganzer Zeitungsbeiträge drohen, überflüssig zu machen.
Dieser Umstand hat die Diskussion rund um den europäischen AI Act noch einmal deutlich angeheizt. An Large Language Models wurden auf einmal hohe Anforderungen gestellt, um subjektiven Ängsten entgegenzutreten. Dann war man sich aufgrund der Innovationsgeschwindigkeit auf einmal nicht sicher, ob es jetzt schon Zeit für eine starre Regulierung ist. Und schlussendlich zeichnet sich eine politische Entwicklung ab, jetzt lieber irgendeinen Kompromiss als später eine gut ausgearbeitete Fassung präsentieren zu können. Wie der AI Act kommt, werden wir dann im nächsten Jahr sehen.
Das alles war aber nicht das, was dieses Jahr in meinen Augen besonders gemacht hat. Es ist etwas anderes: die neue Rolle von Open Source.
Anfang des Jahres sah es so aus, als setzt eine besondere Kommerzialisierung in der Technikwelt ein: die Kommerzialisierung von Basistechnologie. Über die verschiedenen Jahre haben wir gesehen, dass es für verschiedene Produkte in der IT proprietäre und freie Lösungen gibt. Zwar sind erstere gerne technologisch mitunter überlegen, da die Profitorientierung Anreize setzt, für bestimmte Anwendungszwecke besonders passende Lösungen zu entwickeln. Kostet eine Software Geld, kann der Hersteller Programmierer anstellen, die auch die Features entwickeln, die man ungern freiwillig programmiert. Auf diese Weise entstehen runde Produkte für einen Anwendungszweck.
Freie bzw. zumindest quelloffene Software ermöglicht zumindest aber der Öffentlichkeit, einen Blick in die Funktionsweise zu werfen, um zu sehen, wie etwas funktioniert. Das ist die Grundlage, um Technologie zu verbessern.
In der Welt des maschinellen Lernens entstand allerdings durch die benötigte Compute Power eine hohe Eintrittshürde. Es sah so aus, als wären die Large Language Models nur noch großen Konzernen bzw. gut finanzierten Start-ups vorbehalten, die sich die Trainingspower leisten können. Während die Vorgängersysteme wie GPT-2 noch öffentlich zugänglich waren, wurden gerade Systeme wie GPT-3 und GPT-4, bei denen das Produkt endlich richtig nutzbar wurde, zurückgehalten.
Im Laufe des Frühlings habe ich allerdings vermutet, dass freie Modelle die proprietären outperformen können, weil die öffentliche Zugänglichkeit die Chance eröffnet, dass Experten weltweit mit ihren eigenen Erfahrungen, Eindrücken und ihrem Domänenwissen eine Technologie entwickeln können, die verschlossenen Produkten überlegen ist.
Überraschend war, dass es gerade das AI-Team von Facebook war, das den Stein mit LLaMA ins Rollen gebracht hat. Es folgten zahlreiche weitere Abkömmlinge, Weiterentwicklungen oder gänzliche Alternativansätze, die eines gemein hatten: ihr Kern mit den Gewichten war zugänglich.
Wie es aussieht, könnte die Dominanz proprietärer Systeme gebrochen werden, sodass auch die Möglichkeit gewahrt bleibt, einen wissenschaftlichen Diskurs zu führen. Technische Berichte proprietärer Modelle sind zwar nett, aber die Forschungsarbeiten, in denen reproduzierbare Fortschritte aufgezeigt werden, bringen uns tatsächlich eher voran.
Um die rasante Entwicklung im Frühling, als scheinbar jedes KI-Team großer Konzerne und Forschungseinrichtungen alle in der Schublade angesammelten LLM-Projekte zu veröffentlichen versuchte, im Auge zu behalten, habe ich die LLM-Timeline entwickelt. Sie wurde vor einigen Tagen wieder aktualisiert und zeigt besonders, wie sehr LLaMA als eines der ersten praktisch verwertbaren Modelle mit offenen Gewichten die Entwicklung beeinflusst hat.
Ein weiteres Projekt, das ich in der Zusammenarbeit mit der Fachhochschule Kiel realisiert habe, war der Podcast KI & Kultur, der generative Modelle aus der Perspektive Kulturschaffender beleuchtet hat.
Das Jahr hat den 70 Jahre alten Begriff der KI wieder mal in die Massen gebracht. Dabei wird ChatGPT dem Begriff eigentlich gar nicht gerecht, weil es streng genommen relativ dumm ist. Insbesondere beschränkt es die Zustandsfähigkeit nur auf eine Prompt und lernt nicht, während es denkt. Training und Inferenz sind entkoppelt.
Und trotzdem ist es diese natürlichsprachliche Schnittstelle, die es so faszinierend macht. Allerdings ist auch diese Erkenntnis nicht neu und wurde schon vor 55 Jahren mit ELIZA diskutiert.
Erfreulich ist es, dass "Open Source" nicht mehr nur bei Software, sondern in neuen Technologien Anwendung findet. Der Gedanke, dass Technologie zugänglich sein muss, kann so erhalten werden. Und dass es hilft, wenn Wissenschaftler auf der ganzen Welt mit ihrem Wissen beitragen können, sehen wir weiterhin auch in dieser Thematik.
LLMs ermöglichen es, dass wir uns endlich wieder der Mensch-Maschine-Schnittstelle widmen können, die Technologie nutzbar macht. Menschen wollen, dass Technik das Leben einfacher macht. Die bisher begrenzte Rechenleistung hat uns zu Hilfsmitteln wie Displays, Touchscreens oder Tastaturen gezwungen. In den nächsten Jahren können wir schauen, wie wir das überwinden können, um endlich nutzbare Computer zu erhalten, die wirklich was bringen.
Und so ist es schon fast ironisch, dass die naheliegendste Technologie, die in den 2010er-Jahre euphorisch gefeiert wurde, von den LLMs noch wenig profitiert hat: Sprachassistenten. Sie sind überwiegend noch genau so begrenzt und unflexibel wie früher. Hier gibt es einiges zu tun.
Abschließend möchte ich meinen Lesern des Blogs und Zuhörern des Podcasts Risikozone sowie KI & Kultur danken, dass ihr den Blog lest, den Podcast hört und regelmäßig Feedback gebt. Ich wünsche euch einen guten Rutsch in das neue Jahr 2024.
Im nächsten Jahr werden wir wieder gemeinsam neue Technologien ergründen und die aktuellen Nachrichten diskutieren. Es wird auch mehr um Grundlagen und Visualisierungen gehen, hierauf freue ich mich schon besonders!
Viel Glück, Gesundheit und Erfolg!
Dieser Artikel ist der Auftakt einer Mini-Serie, die sich mit der Script-Programmierung des Raspberry Pi 5 beschäftigt. Geplant sind drei Artikel:
Hinter den Kulissen hat sich mit der Vorstellung des Raspberry Pi 5 mehr geändert, als es in den ersten Testberichten den Anschein hatte. Schuld daran ist der neue I/O-Chip RP1, der unter anderem für die Kommunikation mit der GPIO-Leiste und der Kamera zuständig ist. Der RP1 bringt natürlich viele Vorteile mit sich (u.a. die Möglichkeit, zwei Kameras anzuschließen und größere Bild- bzw. Videomengen zu verarbeiten); er führt aber auch dazu, dass über Jahre etablierte Module und Kommandos nicht mehr funktionieren. Ja, die Raspberry Pi Foundation hat vorgearbeitet und empfiehlt schon eine Weile alternative Werkzeuge. Aber aus Bequemlichkeit blieben viele Programmierer bei langjährig bewährten Tools. Damit ist jetzt Schluss. Wer den Pi 5 als Maker-Tool nutzen will, muss umlernen.
In der Vergangenheit gab es mehrere GPIO-Kommuniktionsmechanismen, z.B. das Lesen/Schreiben von sysfs-Dateien (sys/class/gpio) bzw. das direkte Verändern von Speicherbereichen. Diese Verfahren haben schon in der Vergangenheit oft Probleme bereitet. Beim Raspberry Pi 5 funktionieren sie schlicht nicht mehr. Neue Verfahren verwenden die lgpio-Bibliothek, die wiederum auf eine neue Kernel-Schnittstelle zurückgreift. Diese ist nach außen hin durch die Device-Dateien /dev/gpiochip* sichtbar.
Aus Python-Sicht ist insbesondere das Modul rpi.gpio betroffen. Es ist inkompatibel zum Pi 5 und es gibt anscheinend auch keine Pläne, den Code RP1-kompatibel zu reorganisieren.
Schon seit einiger Zeit empfiehlt die Raspberry Pi Foundation, das gpiozero-Modul zu verwenden. Es stellt für den Einstieg gut geeignete Klassen wie LED oder Button zur Verfügung, eignet sich aber auch für anspruchsvollere Maker-Aufgaben.
Wenn Sie sich partout nicht mit gpiozero anfreunden wollen, gibt es drei Alternativen: lgpio, gpiod und rpi-lgpio.
Das Python-Modul gpiozero macht die Steuerung von Hardware-Komponenten durch GPIOs besonders einfach. Für häufig benötigte Hardware-Komponenten gibt es eigene Klassen. Dazu zählen unter anderem:
LED (Leuchtdiode ein-/ausschalten)PWMLED (Helligkeit einer Leuchtdiode mit Software Pulse Width Modulation steuern)RGBLED (dreifarbige LED, die über drei GPIO-Ausgänge gesteuert wird) TrafficLights (Kombination aus einer roten, gelben und grünen Leuchtdiode)MotionSensor (für PIR-Bewegungssensoren)LightSensor (Lichtdetektor)Button (Taster) Buzzer (Summer)Motor (zur Steuerung von zwei GPIOs für Vorwärts- und Rückwärts-Signale)Robot (zur Steuerung mehrerer Motoren)MCP3008 (für den gleichnamigen A/D-Converter) Das Modul gpiozero ist umfassend dokumentiert:
https://gpiozero.readthedocs.io/en/latest
Ein Hello-World-Beispiel sieht so aus:
#!/usr/bin/env python3
from gpiozero import LED
import time
myled = LED(7) # BCM-Nummer 7 = Pin 26 des J8-Headers
print("LED ein")
myled.on()
time.sleep(1)
print("LED aus und Programmende")
myled.off()
Dieses Script setzt voraus, dass Pin 26 der GPIO-Leiste (intern BCM/GPIO 7) über einen Vorwiderstand mit einer Leuchtdiode verbunden ist. Anstelle der GPIO-Nummer gibt es einige alternative Adressierungsverfahren, wobei Sie den gewünschente GPIO-Kontakt als Zeichenkette angeben:
# alternative, gleichwertige Schreibweisen
myled = LED(7) # GPIO 7 = BCM-Nummer 7
myled = LED("GPIO7") # GPIO 7 (Achtung, nicht "GPIO07")
myled = LED("BCM7") # BCM 7 (nicht "BCM07")
myled = LED("BOARD26") # Pin 26 auf der GPIO-Leiste des Boards
myled = LED("J8:26") # Pin 26 des J8-Headers (= GPIO-Leiste)
lgpio (der Projektname lautet noch kürzer lg) ist eine C-Bibliothek zur lokalen Steuerung der GPIOs. Das gerade erwähnte Modul gpiozero verwendet intern seit Version 2.0 die lgpio-Bibliothek. Alternativ stellt das gleichnamige lgpio-Modul eine direkte Python-Schnittstelle zur lgpio-Bibliothek her. Deren Funktionen sind Hardware-näher implementiert. Der GPIO-Zugriff verbirgt sich also nicht hinter Klassen wie LED oder Button, vielmehr werden die GPIO-Schnittstellen direkt angesprochen.
Ein Hello-World-Beispiel mit lgpio sieht so aus:
#!/usr/bin/env python3
import lgpio, time
# Zugriff auf /dev/gpiochip4 für RP1-Chip
handle = lgpio.gpiochip_open(4)
# Raspberry Pi 4 und früher:
# handle = lgpio.gpiochip_open(0)
# GPIO 7 = Pin 26 als Output verwenden
led = 7
lgpio.gpio_claim_output(handle, led)
# LED zehnmal ein- und ausschalten
for i in range(10):
print("LED ein")
lgpio.gpio_write(handle, led, 1)
time.sleep(1)
print("LED aus")
lgpio.gpio_write(handle, led, 0)
time.sleep(1)
# nichts blockieren
lgpio.gpiochip_close(handle)
Beachten Sie, dass die Initialisierung des Handles für den GPIO-Zugriff je nach Modell variiert! Bei den älteren Raspberry-Pi-Modellen bis einschließlich 4B/400 müssen Sie handle = lgpio.gpiochip_open(0) ausführen. Beim Raspberry Pi 5 ist für die GPIO-Steuerung dagegen der neue RP1-Chip zuständig, den Sie mit gpiochip_open(4) ansprechen. (Die richtige Chip-Nummer stellen Sie am einfachsten mit dem Kommando gpioinfo aus dem Paket gpiod fest. Der hier benötigte Kontakt GPIO7 heißt in gpioinfo ein wenig verwirrend PIN7.)
Wenn Sie mit Python ein lgpio-Script schreiben wollen, das auf allen Pi-Modellen funktioniert, müssen Sie Code zur Erkennung des Pi-Modells integrieren.
Weiterer Codebeispiele finden Sie hier:
Was tun, wenn Sie Code für ältere Modelle entwickelt haben, den Sie nun für den Raspberry Pi 5 portieren möchten? Am schnellsten wird dies oft mit dem neuen Modul rpi-lgpio gelingen, das weitgehende Kompatibilität zu rpi.gpio verspricht.
Vor der Installation müssen Sie das in Raspberry Pi OS standardmäßig installierte Modul rpi.gpio installieren. Eine Parallelinstallation beider Module ist ausgeschlossen, weil rpi.gpio und rpi-lgpio den gleichen Modulnamen verwenden (import RPi.GPIO).
sudo apt remove python3-rpi.gpio
Da es in Raspberry Pi OS für rpi-lgpio kein fertiges Paket, installieren Sie dieses am einfachsten mit pip. Da es kein passendes Systempaket gibt, sind keine Konflikte zu erwarten. Wenn Sie die Option --break-system-packages dennoch vermeiden möchten, müssen Sie eine virtuelle Python-Umgebung einrichten.
pip install --break-system-packages rpi-lgpio
Das obige pip-Kommando installiert das Modul lokal, also nur für Ihren Account. Wenn Sie Ihr Script in einem anderen Account ausführen möchten (z.B. als Cron-Job), stellen Sie dem Kommando sudo voran und installieren so rpi-lgpio systemweit.
Nach diesen Vorbereitungsarbeiten sollten viele Ihre alten Scripts ohne Änderungen laufen. Einige Sonderfälle sind hier dokumentiert:
https://rpi-lgpio.readthedocs.io/en/release-0.4/differences.html
Die folgenden Zeilen zeigen einmal mehr eine Schleife zum Ein- und Ausschalten einer Leuchtdiode:
#!/usr/bin/env python3
# Das Script setzt voraus, dass vorher
# rpi-lgpio installiert wurde!
import RPi.GPIO as gpio
import time
# BCM-GPIO-Nummern verwenden
gpio.setmode(gpio.BCM)
# LED an Pin 26 = GPIO 7
gpio.setup(7, gpio.OUT)
# LED über Pin 26 fünf Mal ein- und ausschalten
for _ in range(5):
print("LED ein")
gpio.output(7, gpio.HIGH)
time.sleep(1)
print("LED aus")
gpio.output(7, gpio.LOW)
time.sleep(1)
# alle vom Script benutzten GPIOs/Pins wieder freigeben
gpio.cleanup()
Das Python-Modul gpiod wird durch das Paket python3-libgpiod zur Verfügung gestellt, das unter Raspberry Pi OS standardmäßig installiert ist. Das Modul stellt eine Python-Schnittstelle zur Bibliothek libgpiod her. Diese Bibliothek ist wiederum eine Alternative zu der schon erwähnten lgpio-Bibliothek. Da es zum Python-Modul kaum Dokumentation gibt, ist gpiod nur für Entwickler von Interesse, die mit libgpiod bereits C-Programme entwickelt haben. Als Ausgangspunkt für eine eigene Recherche eignen sich die beiden folgenden Seiten:
Das folgende Minibeispiel zeigt, wie Sie eine LED an Pin 26 (GPIO 7) fünf mal ein- und ausschalten:
#!/usr/bin/env python3
import gpiod, time
chip = gpiod.Chip('gpiochip4') # RP1 (Raspberry Pi 5)
led = chip.get_line(7) # GPIO 7 = Pin 26 des J8-Headers
led.request(consumer="example", type=gpiod.LINE_REQ_DIR_OUT)
for _ in range(5): # 5x ein- und ausschalten
led.set_value(1)
time.sleep(1)
led.set_value(0)
time.sleep(1)
Dieser Beitrag baut auf dem Artikel „PHP7.4-fpm auf PHP8.1-fpm für Nextcloud“ auf.
Im Januar 2023 hatte ich erklärt, wie ich mein Raspberry Pi OS 11 (basierend auf Debian 11 Bullseye), durch Einbinden einer Fremdquelle, von PHP7.4-fpm auf PHP8.1-fpm aktualisiert habe. Warum ich zu diesem Zeitpunkt die Version 8.1 installiert habe, ist recht einfach zu beantworten. Die aktuelle Version Nextcloud 25 war noch nicht kompatibel zu PHP 8.2. Erst mit Nextcloud 26 war ein Upgrade möglich.
Nun habe ich mich nach der Aktualisierung auf Nextcloud 28 entschieden auf PHP 8.2 zu wechseln. Da ich den FastCGI-Prozessmanager FPM bevorzuge, unterscheidet sich das Upgrade etwas von einer herkömmlichen PHP-Installation.

Zuerst wird das System auf den aktuellen Stand gebracht.
sudo apt update && sudo apt upgrade -y
Ein Check zeigt, welche PHP-Version momentan aktiv ist.
php -v
Hier die Ausgabe:
PHP 8.1.27 (cli) (built: Dec 21 2023 20:17:59) (NTS) Copyright (c) The PHP Group Zend Engine v4.1.27, Copyright (c) Zend Technologies with Zend OPcache v8.1.27, Copyright (c), by Zend Technologies
Jetzt werden alle benötigten Pakete nachinstalliert (auch das von Nextcloud 28 verlangte bz2 und der von mir eingesetzte Redis-Server).
sudo apt install php8.2 php8.2-mbstring php8.2-gd php8.2-curl php8.2-imagick php8.2-intl php8.2-bcmath php8.2-gmp php8.2-mysql php8.2-zip php8.2-xml php8.2-apcu libapache2-mod-php8.2 php8.2-bz2 php8.2-redis
Nun wird via CLI die PHP-Version von 8.1 auf 8.2 mit
sudo update-alternatives --config php
umgestellt.
sudo update-alternatives --config php Es gibt 5 Auswahlmöglichkeiten für die Alternative php (welche /usr/bin/php bereitstellen). Auswahl Pfad Priorität Status ------------------------------------------------------------ 0 /usr/bin/php.default 100 automatischer Modus 1 /usr/bin/php.default 100 manueller Modus 2 /usr/bin/php7.4 74 manueller Modus * 3 /usr/bin/php8.1 81 manueller Modus 4 /usr/bin/php8.2 82 manueller Modus 5 /usr/bin/php8.3 83 manueller Modus
sudo update-alternatives --config php Es gibt 5 Auswahlmöglichkeiten für die Alternative php (welche /usr/bin/php bereitstellen). Auswahl Pfad Priorität Status ------------------------------------------------------------ 0 /usr/bin/php.default 100 automatischer Modus 1 /usr/bin/php.default 100 manueller Modus 2 /usr/bin/php7.4 74 manueller Modus 3 /usr/bin/php8.1 81 manueller Modus * 4 /usr/bin/php8.2 82 manueller Modus 5 /usr/bin/php8.3 83 manueller Modus
Ein abschließender Check zeigt die aktuelle Version.
php -v
PHP 8.2.14 (cli) (built: Dec 21 2023 20:18:00) (NTS) Copyright (c) The PHP Group Zend Engine v4.2.14, Copyright (c) Zend Technologies with Zend OPcache v8.2.14, Copyright (c), by Zend Technologies
Ist die Ausgabe korrekt, kann PHP8.1-fpm deaktiviert, PHP8.2-fpm installiert und aktiviert werden.
sudo a2disconf php8.1-fpm sudo apt install php8.2-fpm sudo a2enconf php8.2-fpm
Der Restart des Webservers führt nun die Änderungen aus.
sudo service apache2 restart
Da in der Nextcloud nun wieder die bekannten Fehlermeldungen auftauchen, heißt es, diese schrittweise abzuarbeiten. Dazu wird die neue php.ini geöffnet
sudo nano /etc/php/8.2/fpm/php.ini
und die Werte für memory_limit sowie session_lifetime wie empfohlen angepasst.
memory_limit = 512M session.gc_maxlifetime = 3600
Der Block
opcache.enable=1 opcache.interned_strings_buffer=64 opcache.max_accelerated_files=10000 opcache.memory_consumption=256 opcache.save_comments=1 opcache.revalidate_freq=1
für den Zwischenspeicher OPchache wird ans Ende der php.ini gesetzt.
Zur Optimierung von PHP8.2-fpm werden speziell für das Modell Raspberry Pi 4 mit 4GB RAM in der Datei www.conf mit
sudo nano /etc/php/8.2/fpm/pool.d/www.conf
folgende Werte von
pm = dynamic pm.max_children = 5 pm.start_servers = 2 pm.min_spare_servers = 1 pm.max_spare_servers = 3
auf
pm = dynamic pm.max_children = 120 pm.start_servers = 12 pm.min_spare_servers = 6 pm.max_spare_servers = 18
angepasst und der Dienst neu gestartet.
sudo service php8.2-fpm restart
Danach muss in der apcu.ini das Command Line Interface des PHP Cache noch aktiviert werden, indem
sudo nano /etc/php/8.2/mods-available/apcu.ini
folgende Zeile am Ende eingetragen wird.
apc.enable_cli=1
Ist dies geschehen, wird der Webserver ein letztes Mal neu gestartet.
sudo service apache2 restart
Die Umstellung bringt zwar im Moment keine erkennbaren Vorteile, jedoch verschafft es wieder ein wenig Zeit und senkt den Druck das eigentliche Raspberry Pi OS 11 Bullseye durch die aktuelle Version 12 Bookworm zu ersetzen.
PHP-FPM (FastCGI Process Manager) ist eine leistungsstarke Erweiterung für den PHP-Interpreter, die die Ausführung von PHP-Skripten optimiert und verbessert. Entwickelt, um die Skalierbarkeit von PHP-basierten Webanwendungen zu erhöhen, spielt PHP-FPM eine entscheidende Rolle in modernen Webserver-Umgebungen.
Traditionell wurde PHP als Modul für Webserver wie Apache bereitgestellt. Dieser Ansatz hatte jedoch seine Einschränkungen, insbesondere wenn es um die Verwaltung von Ressourcen und die Skalierung von Webanwendungen ging. PHP-FPM wurde als Lösung für diese Herausforderungen entwickelt, indem es die FastCGI-Protokollspezifikation implementiert und PHP-Skripte als separate Prozesse ausführt.
PHP-FPM ermöglicht eine effiziente Verwaltung von Ressourcen, indem es separate Prozesse für jede Anforderung erstellt. Dadurch wird der Arbeitsspeicher besser genutzt und die Gesamtleistung der Webanwendung verbessert.
Durch die Nutzung von PHP-FPM können Webentwickler ihre Anwendungen leichter skalieren, da sie die Anzahl der gleichzeitig ausgeführten PHP-Prozesse steuern können. Dies ist besonders wichtig in Umgebungen mit starkem Datenverkehr.
Jede PHP-Anwendung wird in ihrem eigenen Prozess isoliert, wodurch Konflikte zwischen verschiedenen Anwendungen vermieden werden. Dies trägt zur Stabilität des Gesamtsystems bei.
PHP-FPM bietet eine umfangreiche Konfiguration, die es Administratoren ermöglicht, Parameter wie Prozessprioritäten, Anzahl der Kinderprozesse und andere Einstellungen zu optimieren.
Die Konfiguration von PHP-FPM erfolgt über die php-fpm.conf-Datei und optionale Pool-Konfigurationsdateien. Administratoren können Parameter anpassen, um die Leistung und Ressourcennutzung nach den Anforderungen ihrer Anwendung zu optimieren.
Die Integration von PHP-FPM in Webserver wie Nginx oder Apache erfolgt durch die Konfiguration von FastCGI-Servern. Dies ermöglicht eine reibungslose Kommunikation zwischen dem Webserver und PHP-FPM.
PHP-FPM hat sich als wesentliches Werkzeug für die Verwaltung von PHP-Anwendungen in produktiven Umgebungen etabliert. Durch die Bereitstellung von effizienter Ressourcennutzung, Skalierbarkeit und Anwendungsisolierung spielt PHP-FPM eine Schlüsselrolle bei der Gewährleistung der Leistungsfähigkeit von PHP-Webanwendungen. Bei der Entwicklung und Verwaltung von Webanwendungen ist es wichtig, die Vorteile von PHP-FPM zu verstehen und richtig zu konfigurieren, um eine optimale Leistung zu gewährleisten.
Aktuell sollte beim Updaten des Linux-Kernels Vorsicht walten gelassen werden. Bestimmte Kernel-Releases weisen ein Problem mit ext4 auf, das theoretisch im schlimmsten Fall zu einer Datenbeschädigung führen kann.
Es gibt eine Konstellation, in der in einem Release nur der erste ohne den zweiten Commit enthalten ist und somit der Code nicht wie gewünscht arbeitet. Konkret geht es um
Jan Karas E-Mail auf der LKML zufolge geht es darum, dass der erste Commit nur dann im Code vorhanden sein darf, wenn der zweite Commit bereits enthalten ist. Eigentlich ist das logisch, weil das ja mit der Reihenfolge dann auch so passt.
Jetzt kommen allerdings noch die Backports und Distributionen ins Spiel. Für den Kontext: da nicht jeder immer auf die neuste Linux-Version aktualisieren kann, gibt es ein Team, was alte Versionen nachpflegt und kleine, unkritische Fixes neuerer Versionen auf die älteren Versionen "rückportiert", also backported. Allerdings kann es nun passieren, dass etwas ganz neues rückportiert wird, ohne, dass eine ältere Voraussetzung rückportiert wurde. Die Fehler, die dann auftreten, nennt man klassicherweise eine Regression. Die einzelnen Codeänderungen sind da nicht an sich das Problem, sondern eher die Konstellation, in der sie zusammengesetzt wurden.
Linux 6.1.64 und 6.1.65 sind betroffen, 6.1.66 enthält den Fix. Debian 12, das auf die Kernels setzt, ist dabei besonders in Aufruhe, da eine problematische Kernel-Version verteilt wird. Aus diesem Grund wurde auch die Veröffentlichung von Debian 12.3 verzögert.