Seit vielen Jahren verwende ich Let’s Encrypt-Zertifikate für meine Webserver. Zum Ausstellen der Zertifikate habe ich in den Anfangszeiten das Kommando certbot genutzt. Weil die Installation dieses Python-Scripts aber oft Probleme bereitete, bin ich schon vor vielen Jahren auf das Shell-Script acme.sh umgestiegen (siehe https://github.com/acmesh-official/acme.sh).
Kürzlich bin ich auf einen Sonderfall gestoßen, bei dem acme.sh nicht auf Anhieb funktioniert. Die Kurzfassung: Ich verwende Apache als Proxy für eine REST-API, die in einem Docker-Container läuft. Bei der Zertifikatausstellung/-erneuerung ist Apache (der auf dem Rechner auch als regulärer Webserver läuft) im Weg; die REST-API liefert wiederum keine statischen Dateien aus. Die Domain-Verifizierung scheitert. Abhilfe schafft eine etwas umständliche Apache-Konfiguration.
Ausgangspunkt
Ausgangspunkt ist also ein »gewöhnlicher« Apache-Webserver. Dieser soll nun zusätzlich eine REST-API ausliefern, die in einem Docker-Container läuft (localhost:8880). Die erste Konfiguration sah ziemlich simpel aus:
Das Problem besteht darin, dass acme.sh zwar diverse Domain-Verifizierungsverfahren kennt, aber keines so richtig zu meiner Konfiguration passt:
acme.sh ... --webroot scheitert, weil die API eine reine API ist und keine statischen Dateien ausliefert.
acme.sh ... --standalone scheitert, weil der bereits laufende Webserver Port 80 blockiert.
acme.sh ... --apache scheitert mit could not resolve api.example.com.well-known.
Die Lösung
Die Lösung besteht darin, die Apache-Proxy-Konfiguration dahingehend zu ändern, dass zusätzlich in einem Verzeichnis statische Dateien ausgeliefert werden dürfen. Dazu habe ich das neue Verzeichnis /var/www/acme-challenge eingerichtet:
Danach habe ich die Konfigurationsdatei für Apache umgebaut, so dass Anfragen an api.example.com/.well-known/acme-challenge mit statischen Dateien aus dem Verzeichnis /var/www/acme-challenge/.well-known/acme-challenge bedient werden:
# Apache-Konfiguration wie bisher
<VirtualHost *:443>
ServerName api.example.com
# SSL
SSLEngine on
SSLCertificateFile /etc/acme-letsencrypt/api.example.com.pem
SSLCertificateKeyFile /etc/acme-letsencrypt/api.example.com.key
# Proxy: localhost:8880 <-> api.example.com
ProxyPreserveHost On
ProxyPass / http://localhost:8880/
ProxyPassReverse / http://localhost:8880/
# Logging Konfiguration ...
</VirtualHost>
# geändert: HTTP auf HTTPS umleiten, aber nicht
# für well-known-Verzeichnis
<VirtualHost *:80>
ServerName api.example.com
# Handle ACME challenges locally
Alias /.well-known/acme-challenge /var/www/acme-challenge/.well-known/acme-challenge
<Directory /var/www/acme-challenge/.well-known/acme-challenge>
Require all granted
</Directory>
# Redirect everything EXCEPT ACME challenges to HTTPS
RewriteEngine On
RewriteCond %{REQUEST_URI} !^/.well-known/acme-challenge/
RewriteRule ^(.*)$ https://api.example.com$1 [R=301,L]
</VirtualHost>
Nach diesen Vorbereitungsarbeiten und mit systemctl reload apache2 gelingt nun endlich das Zertifikaterstellen und -erneuern mit dem --webroot-Verfahren. Dabei richtet acme.sh vorübergehend die Datei /var/www/acme-challenge/.well-known/acme-challenge/xxx ein und testet dann via HTTP (Port 80), ob die Datei gelesen werden kann.
Eine noch elegantere Lösung besteht darin, den Docker-Container mit Traefik zu kombinieren (siehe https://traefik.io/traefik/). Bei korrekter Konfiguration kümmert sich Traefik um alles, nicht nur um die Proxy-Funktionen sondern sogar um das Zertifikatsmanagment. Aber diese Lösung kommt nur in Frage, wenn auf dem Host nicht schon (wie in meinem Fall) ein Webserver läuft, der die Ports 80 und 443 blockiert.
Wir schreiben das Jahr 2025. Die Frage, ob man Linux-Server mit oder ohne Swap-Partition betreiben sollte, spaltet die Linux-Gemeinschaft in einer Weise, wie wir es seit dem Editor War nicht mehr gesehen haben…
So könnte ein spannender Film für Sysadmins anfangen, oder? Ich möchte aber keinen Streit vom Zaun brechen, sondern bin an euren Erfahrungen und Gedanken interessiert. Daher freue ich mich, wenn ihr euch die Zeit nehmt, folgende Fragen in den Kommentaren zu diesem Beitrag oder in einem eigenen Blogpost zu beantworten.
Stellt ihr Linux-Server mit Swap-Partition bereit und wie begründet ihr eure Entscheidung?
Hat euch die Swap-Partition bei sehr hoher Speicherlast schon mal die Haut bzw. Daten gerettet?
War der Server während des Swapping noch administrierbar? Falls ja, welche Hardware wurde für die Swap-Partition genutzt?
Eine kleine Mastodon-Umfrage lieferte bisher folgendes Bild:
Schaue ich mir meine eigenen Server an, so ergibt sich ein gemischtes Bild:
Debian mit LAMP-Stack und Containern: 16 GB RAM & kein Swap
RHEL-KVM-Hypervisor 1: 32 GB RAM & 4 GB Swap
RHEL-KVM-Hypervisor 2: 128 GB RAM & kein Swap
RHEL-Container-Host (VM): 4 GB RAM & 4 GB Swap
Bis auf den Container-Host handelt es sich um Bare-Metal-Server.
Ich kann mich nicht daran erinnern, dass jemals einem dieser Systeme der Hauptspeicher ausgegangen ist oder der Swapspeicher genutzt worden wäre. Ich erinnere mich, zweimal Swapping auf Kunden-Servern beobachtet zu haben. Die Auswirkungen waren wie folgt.
Im ersten Fall kamen noch SCSI-Festplatten im RAID zum Einsatz. Die Leistung des Gesamtsystems verschlechterte sich durch das Swapping so stark, dass bereitgestellten Dienste praktisch nicht mehr verfügbar waren. Nutzer erhielten Zeitüberschreitungen ihrer Anfragen, Sitzungen brachen ab und das System war nicht mehr administrierbar. Am Ende wurde der Reset-Schalter gedrückt. Das Problem wurde schlussendlich durch eine Vergrößerung des Hauptspeichers gelöst.
Im zweiten Fall, an den ich mich erinnere, führte ein für die Nacht geplanter Task zu einem erhöhten Speicherverbrauch. Hier hat Swapping zunächst geholfen. Tasks liefen zwar länger, wurden aber erfolgreich beendet und verwendeter Hauptspeicher wurde anschließend wieder freigegeben. Hier entstand erst ein Problem, als der Speicherbedarf größer wurde und die Swap-Partition zu klein war. So kam es zum Auftritt des Out-of-Memory-Killer, der mit einer faszinierenden Genauigkeit immer genau den Prozess abgeräumt hat, den man als Sysadmin gern behalten hätte. Auch hier wurde das Problem letztendlich durch eine Erweiterung des Hauptspeichers gelöst.
Ich erinnere mich auch noch an die ein oder andere Anwendung mit einem Speicherleck. Hier hat vorhandener Swap-Speicher das Leid jedoch lediglich kurz verzögert. Das Problem wurde entweder durch einen Bugfix oder den Wechsel der Anwendung behoben.
Nun bin ich auf eure Antworten und Erfahrungsberichte gespannt.
Der Name meines Blogs ist Programm. Es dient mir als digitales Gedächtnis für IT-Themen, die mich mich beschäftigt haben und die nochmal interessant werden können. Es ist eine Art Wissensdatenbank, auf die ich auch gerne zugreifen können möchte, wenn ich mal keine Internetverbindung habe.
Inspiriert durch den heutigen Beitrag von Dirk, möchte ich hier kurz beschreiben, was ich tue, um eine statische Version meines Blogs zu erstellen, welche ich einfach auf dem Laptop, Smartphone oder Tablet mitnehmen kann.
Ich verwende das Plugin Simply Static – The WordPress Static Site Generator, um eine statische Version meines Blogs zu erzeugen und als Zip-Archiv zu speichern. Möchte ich auf die statische Version meines Blogs zugreifen, entpacke ich das Zip-Archiv in ein Verzeichnis wie z.B. /tmp/simply-static/ und öffne anschließend in einem Webbrowser die Datei /tmp/simply-static/index.html.
Bildschirmfoto der statischen Version meines Blogs
So kann ich z.B. auch dann auf meine Artikel und Anleitungen zugreifen, wenn mein Webserver oder Internetzugriff nicht verfügbar ist. Die Suche auf der Seite funktioniert nur sehr eingeschränkt. Hier behelfe ich mir mit einer Dateisystemsuche im Terminal.
Ein paar Zahlen:
Dauer zur Erstellung des Zip-Archivs: ca. 10 Minuten
Größe des Zip-Archivs: 274 MB
Entpackte Größe: 355 MB
Rythmus der Erstellung: Wenn mir danach ist; in der Regel einmal pro Quartal
Mir gefällt an dieser Lösung, dass ich auf meinem mobilen Gerät keinen Container, ja noch nichmal einen Webserver, sondern nur einen Browser benötige. Das ist einfach, sparsam und robust.
Was haltet ihr davon ein Blog auf diese Weise offline verfügbar zu machen? Tragt ihr eure Blogs auch mit euch herum? Welche Werkzeuge nutzt ihr, um sie stets bei euch zu haben? Teilt euch gerne in den Kommentaren oder einem eigenen Blog mit.
Dieser Artikel ist Teil der #BlogWochen2025. Von Mai bis Oktober schreiben (zumindest) Robert, Dirk und ich über unterschiedliche Themen rund ums Bloggen. Du kannst gerne jederzeit einsteigen und mitmachen – die gesammelten Posts aller Teilnehmer:innen findest du auf dieser Seite und kannst sie auch als Feed abonnieren.
Ich mag Retro-Konsolen und Retro-Spiele. Auf Dauer können sich, wenn man Retro-Konsolen sammelt, Netzteile stapeln und es wird schnell unübersichtlich. Als Maßnahme gegen Kabelsalat kann man die meisten Retro-Konsolen mit USB-C modden und so...
Anzeige – Ich habe für diesen Artikel Produkte der Firma Paulmann zur Verfügung gestellt bekommen. Wie man sein Smart Home mithilfe von Home Assistant und vielen kleinen Helferlein aufbaut, beschreibe ich nun schon seit geraumer Zeit hier im Blog. Dabei genieße ich es, dass die meisten Smart Home Anwendungen über den ein oder anderen Standard verfügen, mit dem sich Komponenten verbinden lassen. Bei Zigbee ist das generell zwar auch so, aber im Speziellen ist die Sache dann doch etwas komplizierter. Viele Anbieter von smarter Hardware haben auch eine Bridge, Gateway oder ähnliches im Portfolio, mit dem die Zigbee-Anbindung bewerkstelligt werden kann. So ist es auch bei meinen ersten Zigbee Produkten gewesen. Im Folgenden beschreibe ich, wie man die Zigbee Leuchten der Firma Paulmann aus der Serie „Plug & Shine“ einrichtet. Hierfür verwende ich deren Gateway namens Smik.
Bei der Sanierung unseres Außenbereichs haben wir viel Energie in die Auswahl der Materialien gelegt. Sowohl die Terrassenplatten, als auch die Mauersteine haben uns viel Kopfzerbrechen bereitet. Bei der Außenbeleuchtung war es glücklicherweise nicht ganz so schwierig, da die Auswahl an smarten Außenleuchten deutlich kleiner ist. So sind wir auf die Firma Paulmann aufmerksam geworden, die Zigbee-fähige Außenleuchten anbietet und noch dazu einen sehr einfachen Weg zu deren Einbindung bereithält.
Außenleuchten, welche Produkte habe ich verwendet?
Die Gartenmauer lassen wir uns mit der Leuchte „Plug & Shine Floor“ bescheinen. Sie leuchtet in weiß, die Farbtemperatur kann man hier einstellen. Außerdem hat sie alle RBG-Farben. Das ist ein tolles Feature, das man bei Gartenpartys verwenden kann. Über die Farbtemperatur vom weiß kann man die Lichtstimmung auf der Terrasse maßgeblich beeinflussen.
Den Treppenaufgang beleuchten wir mit der Pollerleuchte Ito. Diese ist von Haus aus leider nicht smart, lässt sich über den „Plug & Shine Controller“ aber smart machen. Mit diesem Controller kann man den gesamten Kabelstrang ein- bzw. ausschalten. Hier lassen sich weitere Paulmann-Produkte, die nicht von Haus aus smart sind, in die Steuerung einbinden und danach über das Smart Home steuern.
Die Einfassung der Terrasse beleuchten wir mit dem LED-Streifen „Plug & Shine Smooth Strip RGBW„, der Zigbee-fähig ist. Wie man dem Namen schon entnimmt, kann dieser in allen RGB-Farben leuchten. Für die Farbe weiß ist die Farbtemperatur wählbar.
Bäume und Sträucher setzen wir mit der smarten Leuchte „Plug & Shine Pike“ in Szene. Die Farben sind, ihr ahnt es schon, wieder in allen RBG-Farben möglich. Die Farbtemperatur von weiß ist wieder wählbar.
Elektrisch verkabelt werden die Leuchten mit Kabeln namens „Plug & Shine Connector„, die man in verschiedenen Längen und Anzahl von Abgängen erwerben kann. Das System ist einfach, aber genial: Eine 24 VDC-Spannungsquelle stellt die Spannung zur Verfügung. Die Kabel verfügen über Schraubverbinder, an die man wiederum die Leuchten verbinden kann. Auch Kabelabgänge als Verlängerungsleitung sind hiermit möglich. Die Kabel und die Verbinder sind dabei IP68 wasserfest – sogar für Pools geeignet. Die Anbindung der Leuchten ist somit werkzeuglos, verpolungssicher und sehr einfach möglich. Die Intelligenz der Leuchten steckt bereits in den Leuchten drin, sodass hier keine Bastel- oder Verkabelungsarbeit anfällt. Somit lässt sich das Projekt auch nach und nach erweitern.
Als Spannungsquelle verwende ich die „Plug & Shine Einspeisung 230/24V DC„. Diese sind mit IP67 ebenfalls für den Außenbereich geeignet. Ihre Größe kann man an der Gesamtleistung aller Leuchten berechnen. Es stehen mehrere Größen zur Verfügung. Durch die Kunststoff-Abdeckung „Plug and Shine Trafoabdeckung“ lässt sich das Netzteil sogar unauffällig verkleiden.
Zur Steuerung verwende ich die Fernbedienung „Plug & Shine Gent 2„. Mit ihr kann man die Leuchten gruppenweise an- bzw. ausschalten sowie die Farben vorgeben. Das ist sehr nett gelöst, da man über ein Farbfeld intuitiv die Farben auswählen kann. Großer Pluspunkt für die Fernbedienung! Dafür ist für die Einrichtung bzw. das Anlernen der Leuchten etwas Übung notwendig. Die Anleitung dazu liegt der Fernbedienung bei. Mit etwas Konzentration versteht man aber die Logik dahinter.
Einrichtung des Zigbee Gateways und der Leuchten
Dreh- und Angelpunkt für die Steuerung der Außenbeleuchtung ist das Gateway. Hier ist die Schnittstelle zwischen der Smartphone App und den Leuchten. Die Einrichtung ist denkbar einfach. Man schließt das Gateway mittels Ethernet-Kabel an das Netzwerk an (z.B. an eine Fritzbox) und stellt die Spannungsversorgung her. Die Schwierigkeit besteht in der sehr geringen Reichweite des Signals. Sie wird mit 100 m angegeben, berücksichtigt aber weder Wände noch Fensterscheiben. Folglich muss das Gerät sehr nahe an den Garten gebracht werden.
Auf dem Smartphone installiert man sich die App „Paulmann Smik“ und folgt den Anweisungen auf dem Bildschirm. Man muss im Laufe der Einrichtung den QR-Code auf der Rückseite des Gateways scannen. Hierdurch gelingt die Einrichtung sehr schnell und einfach.
Neue Leuchten fügt man hinzu, indem man sie auf Werkseinstellungen zurückstellt. Das ist etwas herausfordernd, da man die Leuchten hier schnell an- und ausschalten muss, insgesamt 5 mal hintereinander. Die Leuchte darf dabei nicht länger als 2 Sekunden an und nicht länger als 5 Sekunden aus sein. Ich habe das geschafft, indem ich die Spannungsversorgung an eine schaltbare Steckdose angeschlossen habe. Mit ihr kann ich über einen Schalter die Ein- und Ausschaltdauer sehr gut timen. Sobald sie zurückgesetzt wurden, können sie über die App gefunden werden.
Best Practises und Tipps
Gruppiert eure Leuchten am besten thematisch, um zusammengehörige Leuchten gemeinsam zu schalten. Ich habe beispielsweise die Mauerspots gruppiert. Sie liegen in der Fernbedienung auf der Schnellwahltaste 1. Ist die Gruppe gewählt, steuere ich alle Mauerspots gemeinsam. Die Fernbedienung erlaubt auch das Steuern von mehreren Gruppen gleichzeitig. Dadurch kann man die Farben von allen Leuchten gemeinsam verändern. Sehr nice!
Macht die Steckdose schaltbar. Wenn die Spannungsversorgung an einer schaltbaren Steckdose angeschlossen ist, könnt ihr die Leuchten sehr viel komfortabler zurücksetzen und für die Einrichtung vorbereiten.
Setzt das Gateway möglichst nahe an den Außenbereich. Die geringe Reichweite ist relativ nervig, daher muss das Gateway recht nahe an den ersten Teilnehmer. Das Signal wird vom ersten Teilnehmer verstärkt, sodass alle weiteren Leuchten dann gutes Signal haben sollten. In der Praxis muss man das ein bisschen ausprobieren, was gut funktioniert.
Ausblick: Einbindung in Home Assistant
Die Einbindung der Außenbeleuchtung in Home Assistant ist möglich. Hat man einen Zigbee-Stick, zum Beispiel den von Nabu Casa selbst, kann man die Lampen damit einbinden. Hierfür muss man eine Instanz von Zigbee2MQTT installiert haben. Bei vielen Home Assistant Anwendern geht das über den Addon Store oder über einen Docker Container, wie es bei mir der Fall ist. Aus zwei Gründen habe ich das bei mir allerdings nicht getan.
1) Die Steuerung über die Paulmann App bzw. über die Gent 2 Fernbedienung ist sehr komfortabel. Es sind viele Funktionen voreingestellt, die Wahl der Farbtemperatur zum Beispiel oder die sehr einfache Auswahl der Farbe über das Farbfeld ist sehr cool. In Home Assistant müsste man sich diese Funktionen erst selbst konfigurieren. Ich bin mir sicher, dass viele Leute das schaffen würden. Für mich steht der Aufwand in keinem Verhältnis.
2) Während er Zeit auf der Terrasse möchte ich weitestgehend auf das Smartphone verzichten. Für die Lichtsteuerung möchte ich deshalb nicht aufs Smartphone angewiesen sein. Im Gegenteil: ich möchte auch unseren Gästen die einfache Möglichkeit geben, unsere Beleuchtung zu kontrollieren. Die Fernbedienung ist hierfür ideal geeignet.
Für die Einbindung in Home Assistant gibt es jedoch ebenfalls gute Argumente
1) Das ganze Haus lässt sich über eine zentrale Steuereinheit kontrollieren. Hier wäre es nur konsequent, die Außenbeleuchtung mit einzubinden.
2) Logging und Kontrolle von den Lampen: Von unterwegs aus sehen, ob die Lampen noch an sind? Kann man mit Home Assistant.
3) Kombination mit anderen Systemen. Die Sensoren und Aktoren könnten auch von anderen Herstellern kommen. Dämmerungs- und Bewegungsmelder von Paulmann könnten dann auch andere smarte Aktoren schalten.
In diesem Video zeigt Jean OpenCloud, eine Open-Source Cloud Software, die möglicherweise als Alternative für Nextcloud in Frage kommt.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
- Zum Interview mit Peer Heinlein https://youtu.be/3XRErSQUyrs
- Interview mit Daniél Kerkmann von OpenTalk https://youtu.be/pxMGS9cD2bI
- OpenCloud Installationstutorial für Administratoren (auf Englisch) https://youtu.be/lVvSnYNpGIA
- Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
- Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
- Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
- Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
- Offizielle Webseite: https://www.linuxguides.de
- Forum: https://forum.linuxguides.de/
- Unterstützen: http://unterstuetzen.linuxguides.de
- Mastodon: https://mastodon.social/@LinuxGuides
- X: https://twitter.com/LinuxGuides
- Instagram: https://www.instagram.com/linuxguides/
- Kontakt: https://www.linuxguides.de/kontakt/
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Seit über zwölf Jahren beschäftige ich mich intensiv mit Linux-Servern. Der Einstieg gelang mir über den Einplatinencomputer Raspberry Pi. Erste Erfahrungen sammelte ich damals mit XBMC – heute besser bekannt als Kodi. Dabei handelt es sich um eine freie, plattformübergreifende Mediaplayer-Software, die dank ihrer Flexibilität und Erweiterbarkeit schnell mein Interesse an quelloffener Software weckte.
Schnell wurde mir klar, dass der Raspberry Pi weit mehr kann. So folgten bald weitere spannende Projekte, darunter auch die ownCloud. Das von Frank Karlitschek gegründete Unternehmen entwickelte eine Cloud-Software, die nicht nur quelloffen war, sondern sich auch problemlos auf Systemen wie Debian oder Ubuntu installieren ließ. Die Möglichkeit, eigene Dateien auf einem selbst betriebenen Server zu speichern und zu synchronisieren, war ein überzeugender Schritt in Richtung digitaler Eigenverantwortung.
Im Jahr 2016 verließ Karlitschek ownCloud, forkte das Projekt und gründete die Firma Nextcloud. Diese erfreut sich bis heute großer Beliebtheit in der Open-Source-Community. Nextcloud bietet neben der klassischen Dateisynchronisation auch zahlreiche Erweiterungen wie Kalender, Kontakte, Videokonferenzen und Aufgabenverwaltung. Damit positioniert sich die Lösung als vollwertige Alternative zu kommerziellen Diensten wie Google Workspace oder Microsoft 365 – mit dem entscheidenden Unterschied, dass die Datenhoheit beim Nutzer selbst bleibt.
Debian vs. Ubuntu
Nextcloud lässt sich auf Debian- und Ubuntu-Systemen relativ unkompliziert auf einem klassischen LAMP-Stack installieren. Doch welches System die bessere Wahl ist, lässt sich pauschal nicht sagen – beide bringen ihre jeweiligen Stärken und Schwächen mit. Debian gilt als besonders stabil und konservativ, was es ideal für Serverumgebungen macht. Ubuntu hingegen punktet mit einem häufig aktuelleren Softwareangebot und einem umfangreicheren Hardware-Support.
Da das Betriebssystem des Raspberry Pi stark an Debian angelehnt ist, läuft die Cloud-Software auch auf dieser Plattform nach wie vor sehr stabil – inzwischen sogar in einer 64-Bit-Variante. Häufiger Flaschenhals ist hier jedoch nicht die Software selbst, sondern die Internetanbindung. Insbesondere der Upstream kann bei vielen DSL-Verbindungen zur Herausforderung werden, wenn größere Datenmengen übertragen werden sollen. Ein Blick in Richtung Virtual Private Server kann sich lohnen.
Virtual Private Server
Wer eine Nextcloud im eigenen Zuhause betreiben möchte, ist mit einem Raspberry Pi gut beraten. Doch Mini-PCs mit Debian oder Ubuntu bieten aufgrund ihrer Bauform – etwa durch die Möglichkeit, mehrere SSDs aufzunehmen – oft eine noch bessere Alternative. Hinzu kommt der Vorteil, dass auch Dienste wie automatische Backups oder RAID-Systeme einfacher umzusetzen sind.
Will man jedoch weitere Dienste auf dem Server betreiben, wie etwa WordPress für die eigene Webseite oder einen Mailserver für den E-Mail-Verkehr, stößt man mit einem Mini-Computer schnell an Grenzen. In solchen Fällen ist ein Virtual Private Server, kurz VPS, die bessere Wahl. Leistungsfähige Angebote wie ein passendes VPS von IONOS, Hetzner oder Netcup machen ein solches Vorhaben inzwischen auch für Privatnutzer bezahlbar. VPS bieten dabei nicht nur mehr Leistung, sondern auch eine höhere Verfügbarkeit, da die Anbindung an das Internet in der Regel professionell realisiert ist.
Fazit
Wer eigene Dienste wie Cloud, Website oder E-Mail in Selbstverwaltung hosten möchte, kann dies mit überschaubarem Aufwand zu Hause mit Open-Source-Software umsetzen. Reicht die Leistung nicht aus, ist ein Virtual Private Server (VPS) eine sinnvolle Alternative.
Der administrative Aufwand sollte dabei nicht unterschätzt werden. Regelmäßige Updates, Backups und Sicherheitskonfigurationen gehören ebenso zum Betrieb wie ein grundlegendes Verständnis für die eingesetzten Komponenten. Doch der entscheidende Vorteil bleibt: Die Kontrolle über die eigenen Daten liegt vollständig in der eigenen Hand – ein wichtiger Schritt hin zur digitalen Souveränität. Open Source baut hier nicht nur funktionale, sondern auch ideelle Brücken.
Mozilla hat heute überraschend angekündigt, seine beiden Dienste Pocket und Fakespot einzustellen.
Mozilla hat heute die unerwartete Ankündigung gemacht, dass die beiden Dienste Pocket und Fakespot eingestellt werden. Offensichtlich hat dies finanzielle Gründe, denn Mozilla beginnt seine Ankündigung damit, dass man der einzige Browserhersteller ist, hinter dem kein Milliardär steht – eine Formulierung, die Mozilla genau so in den letzten Wochen sehr viel in seiner offiziellen Kommunikation verwendet, sowohl in Zusammenhang mit der aktuellen Kartell-Untersuchung gegen Google, welche im schlechtesten Fall Einfluss auf Mozillas Geschäftsbeziehung mit Google haben könnte, aber auch in der direkten Ansprache an die User über Social Media.
Da man aus diesem Grund priorisieren müsse, wofür man seine Zeit und Ressourcen investiert, wurde diese Entscheidung getroffen. Demnach soll Mozillas Fokus noch stärker auf Firefox gelegt werden – eine Aussage, die sich ebenfalls mit der offiziellen Unternehmens-Kommunikation deckt, seit Laura Chambers CEO der Mozilla Corporation ist.
Einstellung von Pocket
Im Februar 2017 hatte Mozilla Read it Later, den damaligen Entwickler von Pocket, für 30 Millionen USD gekauft. In der Folge erhielt Firefox eine Funktion zum Speichern von Artikeln in der Pocket-Ablage und Content-Empfehlungen auf der Firefox-Startseite. Außerdem wurde der Quellcode von Pocket als Open Source freigegeben. Die Pocket-Community soll aus über 30 Millionen Nutzern bestehen.
Bereits seit heute ist es nicht länger möglich, ein neues Abo für die Bezahlversion Pocket Premium abzuschließen. Bestehende Abos werden automatisch beendet und Abonnenten des Jahres-Abos werden ab dem 8. Juli 2025 eine Erstattung erhalten. An dem Tag wird auch Pocket abgeschaltet werden.
Bis zum 8. Oktober 2025 haben Nutzer Zeit, ihre Daten zu exportieren. Anschließend werden diese unwiderruflich gelöscht. Mit dem Tag wird auch die Pocket API für Entwickler eingestellt.
Auf die Content-Empfehlungen auf der Firefox-Startseite muss dies im Übrigen nicht zwingend Auswirkungen haben. Dazu wurde nichts explizit kommuniziert und das Pocket-Branding wurde dafür bereits entfernt, ohne das Feature als Solches zu entfernen. Außerdem wird es auch den Newsletter „Pocket Hits“ weiterhin geben, in Zukunft unter dem neuen Namen „Ten Tabs“. Lediglich die Wochenend-Ausgaben werden entfallen. Es wird also weiterhin kuratierte Inhalte und damit potentiell auch eine Quelle für die Firefox-Startseite geben – welche ja gleichzeitig auch eine Fläche für gesponsorte Inhalte ist.
Einstellung von Fakespot
Fakespot wurde von Mozilla im Mai 2023 gekauft und die Funktionalität anschließend in Firefox integriert. Die Fakespot-KI half dabei, gefälschte Bewertungen auf den Shopping-Portalen Amazon, Walmart und Best Buy zu erkennen.
Ab dem 10. Juni 2025 wird die in Firefox integrierte Funktion abgeschaltet werden. Ab dem 1. Juli 2025 werden dann die Website, Browser-Erweiterungen und Smartphone-Apps nicht länger zur Verfügung stehen.
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Viele Anwender haben lange darauf gewartet – GIMP ist nach fast sechs Jahren Entwicklungszeit in Version 3 erschienen. Dieses Release bringt einen komplett überarbeiteten Kern mit sich und setzt nun auf das GTK3-Toolkit. Das Buch „GIMP 3: Das umfassende Handbuch“ bietet – wie der Name schon verrät – ein umfassendes Nachschlagewerk zum GNU Image Manipulation Program, kurz: GIMP.
Das Buch ist in sieben Teile gegliedert.
Teil I – Grundlagen widmet sich, wie der Titel schon sagt, den grundlegenden Funktionen von GIMP. Der Autor erläutert die Oberfläche des Grafikprogramms und stellt dabei heraus, dass sich Nutzer auch in der neuen Version schnell zurechtfinden – ein Hinweis, der mögliche Bedenken beim Umstieg zerstreuen dürfte. Die Aussage „GIMP ist nicht Photoshop“ von Jürgen Wolf ist prägnant und unterstreicht, dass es sich bei GIMP um ein eigenständiges, leistungsfähiges Programm handelt, das keinen direkten Vergleich mit kommerzieller Software scheuen muss – oder sollte. Zahlreiche Workshops mit umfangreichem Zusatzmaterial begleiten die einzelnen Kapitel. Neben der Benutzeroberfläche werden in Teil I auch Werkzeuge und Dialoge ausführlich erklärt. Darüber hinaus wird beschrieben, wie RAW-Aufnahmen in GIMP importiert und weiterverarbeitet werden können. Ebenso finden sich Anleitungen zum Speichern und Exportieren fertiger Ergebnisse sowie Erläuterungen zu den Unterschieden zwischen Pixel- und Vektorgrafiken (siehe Grafik). Auch Themen wie Farben, Farbmodelle und Farbräume werden behandelt – Letzteres wird im dritten Teil des Buches noch einmal vertieft.
Vektorgrafik vs. Pixelgrafik
Teil II – Die Bildkorrektur behandelt schwerpunktmäßig die Anpassung von Helligkeit, Kontrast und anderen grundlegenden Bildeigenschaften. Ein wesentlicher Abschnitt widmet sich der Verarbeitung von RAW-Aufnahmen, wobei das Zusammenspiel von GIMP mit Darktable im Mittelpunkt steht. Zahlreiche Beispiele und praxisnahe Bearbeitungshinweise unterstützen den Leser bei der Umsetzung am eigenen Bildmaterial.
Teil III – Rund um Farbe und Schwarzweiß beschreibt den Umgang mit Farben und erläutert grundlegende Konzepte dieses Themenbereichs. Dabei wird auch der Einsatz von Werkzeugen wie Pinsel, Stift und Sprühpistole behandelt. Darüber hinaus zeigt das Kapitel, wie Farben verfremdet und Schwarzweißbilder erstellt werden können.
Teil IV – Auswahlen und Ebenen führt den Leser in die Arbeit mit Auswahlen und Ebenen ein. Besonders faszinierend ist dabei das Freistellen von Objekten und die anschließende Bildmanipulation – eine Disziplin, die GIMP hervorragend beherrscht. Auch hierzu bietet das Buch eine Schritt-für-Schritt-Anleitung in Form eines Workshops.
Teil V – Kreative Bildgestaltung und Retusche erklärt, was sich hinter Bildgröße und Auflösung verbirgt und wie sich diese gezielt anpassen lassen. Techniken wie der „Goldene Schnitt“ werden vorgestellt und angewendet, um Motive wirkungsvoll in Szene zu setzen. Außerdem zeigt das Kapitel, wie sich Objektivfehler – etwa tonnen- oder kissenförmige Verzeichnungen – sowie schräg aufgenommene Horizonte korrigieren lassen. Die Bildverbesserung und Retusche werden ausführlich behandelt. Vorgestellte Techniken wie die Warptransformation sind unter anderem in der Nachbearbeitung von Werbefotografie unverzichtbar.
Retusche – Warptransformation
Teil VI – Pfade, Text, Filter und Effekte beschäftigt sich mit den vielfältigen Möglichkeiten, die GIMP für die Arbeit mit Pixel- und Vektorgrafiken bietet. So lassen sich beispielsweise Pixelgrafiken nachzeichnen, um daraus Vektoren bzw. Pfade für die weitere Bearbeitung zu erzeugen. Eine weitere Übung, die sich mit der im Handbuch beschriebenen Methode leicht umsetzen lässt, ist der sogenannte Andy-Warhol-Effekt.
Andy-Warhol-Effekt
Teil VII – Ausgabe und Organisation zeigt, wie der Leser kleine Animationen im WebP- oder GIF-Format erstellen kann. Auch worauf beim Drucken und Scannen zu achten ist, wird in diesem Kapitel ausführlich erläutert. Jürgen Wolf geht zudem noch einmal umfassend auf die verschiedenen Einstellungen in GIMP ein. Besonders hilfreich ist die Auflistung sämtlicher Tastaturkürzel, die die Arbeit mit dem Grafikprogramm spürbar erleichtern.
Das Buch umfasst insgesamt 28 Kapitel und deckt damit alle wichtigen Bereiche der Bildbearbeitung mit GIMP 3 ab.
„GIMP 3: Das umfassende Handbuch“ von Jürgen Wolf überzeugt durch eine klare Struktur, verständliche Erklärungen und praxisnahe Workshops. Sowohl Einsteiger als auch fortgeschrittene Anwender finden hier ein zuverlässiges Nachschlagewerk rund um die Bildbearbeitung mit GIMP. Besonders hervorzuheben sind die zahlreichen Beispiele sowie die umfassende Behandlung aller relevanten Themenbereiche. Wer ernsthaft mit GIMP arbeiten möchte, findet in diesem Buch eine uneingeschränkte Kaufempfehlung.
Die MZLA Technologies Corporation hat mit Thunderbird 138.0.2 ein Update für seinen Open Source E-Mail-Client veröffentlicht.
Neuerungen von Thunderbird 138.0.2
Mit Thunderbird 138.0.2 hat die MZLA Technologies Corporation ein Update für seinen Open Source E-Mail-Client veröffentlicht. Die neue Version bringt mehrere Fehlerkorrekturen, welche sich in den Release Notes (engl.) nachlesen lassen.
Heute Abend klären wieder Hauke und Jean Deine Fragen live!
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
--------------------
Links:
Frage stellen: https://ask.linuxguides.de
Forum: https://forum.linuxguides.de/
Haukes Webseite: https://goos-habermann.de/index.php
Nicht der Weisheit letzter Schluß: youtube.com/@nichtderweisheit
Linux Guides Admin: https://www.youtube.com/@LinuxGuidesAdmin
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Ubuntu Kurs für Anwender*: https://www.linuxguides.de/ubuntu-kurs-fuer-anwender/
Linux für Fortgeschrittene*: https://www.linuxguides.de/linux-kurs-fuer-fortgeschrittene/
Offizielle Webseite: https://www.linuxguides.de
Tux Tage: https://www.tux-tage.de/
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Twitter: https://twitter.com/LinuxGuides
Mastodon: https://mastodon.social/@LinuxGuides
Matrix: https://matrix.to/#/+linuxguides:matrix.org
Discord: https://www.linuxguides.de/discord/
Kontakt: https://www.linuxguides.de/kontakt/
BTC-Spende: 1Lg22tnM7j56cGEKB5AczR4V89sbSXqzwN
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Der SSH-Dienst ist ein natürliches Angriffsziel jedes Servers. Klassische Abwehrmaßnahmen zielen darauf aus, den root-Login zu sperren (das sollte eine Selbstverständlichkeit sein) und mit Fail2ban wiederholte Login-Versuche zu blockieren. Eine weitere Sicherheitsmaßnahme besteht darin, den Passwort-Login mit einer Zwei-Faktor-Authentifizierung (2FA) zu verbinden. Am einfachsten gelingt das server-seitig mit dem Programm google-authenticator. Zusätzlich zum Passwort muss nun ein One-time Password (OTP) angegeben werden, das mit einer entsprechenden App generiert wird. Es gibt mehrere geeignete Apps, unter anderem Google Authenticator und Authy (beide kostenlos und werbefrei).
Es gibt verschiedene Konfigurationsoptionen. Ziel dieser Anleitung ist es, parallel zwei Authentifizierungsvarianten anzubieten:
mit SSH-Schlüssel (ohne 2FA)
mit Passwort und One-time Password (also mit 2FA)
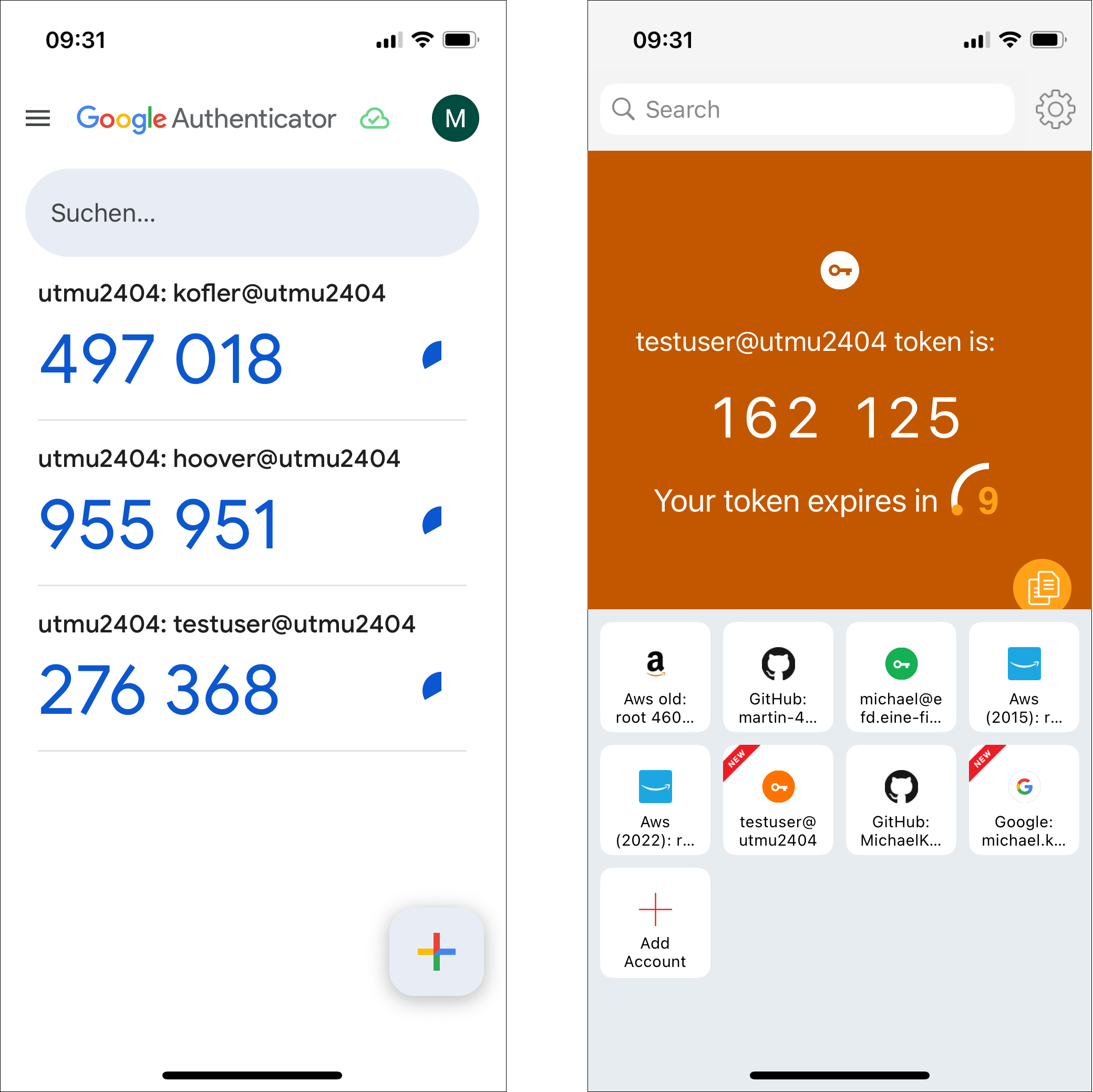
Links die App »Google Authenticator«, rechts »Authy«
Grundlagen: sshd-Konfiguration
Vorweg einige Worte zu Konfiguration des SSH-Servers. Diese erfolgt durch die folgenden Dateien:
Verwechseln Sie sshd_config nicht mit ssh_config (ohne d) für die Konfiguration des SSH-Clients, also für die Programme ssh und scp! opensshserver.config legt fest, welche Verschlüsselungsalgorithmen erlaubt sind.
Beachten Sie, dass bei Optionen, die in den sshd-Konfigurationsdateien mehrfach eingestellt sind, der erste Eintrag gilt (nicht der letzte)! Das gilt auch für Einstellungen, die am Beginn von sshd_config mit Include aus dem Unterverzeichnis /etc/ssh/sshd_config.d/ gelesen werden und die somit Vorrang gegenüber sshd_config haben.
Werfen Sie bei Konfigurationsproblemen unbedingt auch einen Blick in das oft übersehene sshd_config.d-Verzeichnis und vermeiden Sie Mehrfacheinträge für ein Schlüsselwort!
Weil die Dateien aus /etc/ssh/sshd_config.d/ Vorrang gegenüber sshd_config haben, besteht eine Konfigurationsstrategie darin, sshd_config gar nicht anzurühren und stattdessen alle eigenen Einstellungen in einer eigenen Datei (z.B. sshd_config.d/00-myown.conf) zu speichern. 00 am Beginn des Dateinamens stellt sicher, dass die Datei vor allen anderen Konfigurationsdateien gelesen wird.
Überprüfen Sie bei Konfigurationsproblemen mit sshd -T, ob die Konfiguration Fehler enthält. Wenn es keine Konflikte gibt, liefert sshd -T eine Auflistung aller aktuell gültigen Einstellungen. Die Optionen werden dabei in Kleinbuchstaben angezeigt. Mit grep -i können Sie die für Sie relevante Einstellung suchen:
sshd -T | grep -i permitro
permitrootlogin yes
Änderungen an sshd_config werden erst wirksam, wenn der SSH-Server die Konfiguration neu einliest. Dazu führen Sie das folgende Kommando aus:
Google Authenticator bezeichnet zwei unterschiedliche Programme: einerseits die App, die sowohl für iOS als auch für Android verfügbar ist, andererseits ein Linux-Kommando, um die 2FA auf einem Linux-Server einzurichten. Während der Code für die Smartphone-Apps nicht öffentlich ist, handelt es sich bei dem Linux-Kommando um Open-Source-Code. Das resultierende Paket steht für RHEL-Distributionen in der EPEL-Paketquelle zur Verfügung, bei Ubuntu in universe.
Nach der Installation führen Sie für den Account, als der Sie sich später via SSH anmelden möchten (also nicht für root), das Programm google-authenticator aus. Nachdem Sie den im Terminal angezeigten QR-Code gescannt haben, sollten Sie zur Kontrolle sofort das erste OTP eingeben. Sämtliche Rückfragen können Sie mit y beantworten. Die Rückfragen entfallen, wenn Sie das Kommando mit den Optionen -t -d -f -r 3 -R 30 -W ausführen. Das Programm richtet die Datei .google-authenticator im Heimatverzeichnis ein.
user$ google-authenticator
Do you want authentication tokens to be time-based (y/n)
Enter code from app (-1 to skip): nnnnnn
Do you want me to update your .google_authenticator file? (y/n)
Do you want to disallow multiple uses of the same
authentication token? (y/n)
...
Zum Einrichten wird das Kommando »google-authenticator« im Terminal ausgeführt. Den QR-Code scannen Sie dann mit der OTP-App Ihrer Wahl ein. (Keine Angst, der hier sichtbare QR-Code stammt nicht von einem öffentlich zugänglichen Server. Er wurde vielmehr testweise in einer virtuellen Maschine erzeugt.)
SSH-Server-Konfiguration
Das nächste Listing zeigt die erforderlichen sshd-Einstellungen. Mit der Methode keyboard-interactive wird PAM für die Authentifizierung verwendet, wobei auch eine mehrstufige Kommunikation erlaubt ist. Die ebenfalls erforderliche Einstellung UsePAM yes gilt bei den meisten Linux-Distributionen standardmäßig. Am besten speichern Sie die folgenden Zeilen in der neuen Datei /etc/ssh/sshd_config.d/00-2fa.conf. Diese wird am Beginn der sshd-Konfiguration gelesen und hat damit Vorrang gegenüber anderen Einstellungen.
# Datei /etc/ssh/sshd_config.d/00-2fa.conf
UsePAM yes
PasswordAuthentication yes
PubkeyAuthentication yes
ChallengeResponseAuthentication yes
# Authentifizierung wahlweise nur per SSH-Key oder
# mit Passwort + OTP
AuthenticationMethods publickey keyboard-interactive
PAM-Konfiguration
Der zweite Teil der Konfiguration erfolgt in /etc/pam.d/sshd. Am Ende dieser Datei fügen Sie eine Zeile hinzu, die zusätzlich zu allen anderen Regeln, also zusätzlich zur korrekten Angabe des Account-Passworts, die erfolgreiche Authentifizierung durch das Google-Authenticator-Modul verlangt:
# am Ende von /etc/pam.d/sshd (Debian, Ubuntu)
...
# Authenticator-Zifferncode zwingend erforderlich
auth required pam_google_authenticator.so
Alternativ ist auch die folgende Einstellung mit dem zusätzlichen Schlüsselwort nullok denkbar. Damit akzeptieren Sie einen Login ohne 2FA für Accounts, bei denen Google Authenticator noch nicht eingerichtet wurde. Sicherheitstechnisch ist das natürlich nicht optimal — aber es vereinfacht das Einrichten neuer Accounts ganz wesentlich.
# am Ende von /etc/pam.d/sshd (Debian, Ubuntu)
...
# Authenticator-Zifferncode nur erforderlich, wenn
# Google Authenticator für den Account eingerichtet wurde
auth required pam_google_authenticator.so nullok
Wenn Sie RHEL oder einen Klon verwenden, sieht die PAM-Konfiguration ein wenig anders aus. SELinux verbietet dem SSH-Server Zugriff auf Dateien außerhalb des .ssh-Verzeichnisses. Deswegen müssen Sie die Datei .google-authenticator vom Home-Verzeichnis in das Unterverzeichnis .ssh verschieben. restorecon stellt sicher, dass der SELinux-Kontext für alle Dateien im .ssh-Verzeichnis korrekt ist.
user$ mv .google-authenticator .ssh/ (nur unter RHEL!)
user$ restorecon .ssh
In der Zeile auth required übergeben Sie nun als zusätzliche Option den geänderten Ort von .google-authenticator. Falls Sie die nullok-Option verwenden möchten, fügen Sie dieses Schlüsselwort ganz am Ende hinzu.
# am Ende von /etc/pam.d/sshd (RHEL & Co.)
...
auth required pam_google_authenticator.so secret=/home/${USER}/.ssh/.google_authenticator
Test und Fehlersuche
Passen Sie auf, dass Sie sich nicht aus Ihrem Server aussperren! Probieren Sie das Verfahren zuerst in einer virtuellen Maschine aus, nicht auf einem realen Server!
Vergessen Sie nicht, die durchgeführten Änderungen zu aktivieren. Vor ersten Tests ist es zweckmäßig, eine SSH-Verbindung offen zu lassen, damit Sie bei Problemen die Einstellungen korrigieren können.
Bei meinen Tests hat sich die Google-Authenticator-Konfiguration speziell unter RHEL als ziemlich zickig erwiesen. Beim Debugging können Sie client-seitig mit ssh -v, server-seitig mit journalctl -u sshd nach Fehlermeldungen suchen.
Die Anwendung von Google Authenticator setzt voraus, dass die Uhrzeit auf dem Server korrekt eingestellt ist. Die One-Time-Passwords gelten nur in einem 90-Sekunden-Fenster! Das sollten Sie insbesondere bei Tests in virtuellen Maschinen beachten, wo diese Bedingung mitunter nicht erfüllt ist (z.B. wenn die virtuelle Maschine pausiert wurde). Stellen Sie die Zeit anschließend neu ein, oder starten Sie die virtuelle Maschine neu!
Was ist, wenn das Smartphone verlorengeht?
Für den Fall, dass das Smartphone und damit die zweite Authentifizierungsquelle verlorengeht, zeigt das Kommando google-authenticator bei der Ausführung fünf Ziffernfolgen an, die Sie einmalig für einen Login verwendet können. Diese Codes müssen Sie notieren und an einem sicheren Ort aufbewahren — dann gibt es im Notfall einen »Plan B«. (Die Codes sind auch in der Datei .google_authenticator enthalten. Auf diese Datei können Sie aber natürlich nicht mehr zugreifen, wenn Sie keine Login-Möglichkeit mehr haben.)
Die App Google Authenticator synchronisiert die 2FA-Konfiguration automatisch mit Ihrem Google-Konto. Die 2FA-Konfiguration kann daher auf einem neuen Smartphone rasch wieder hergestellt werden. Schon eher bereitet Sorge, dass nur die Kenntnis der Google-Kontodaten ausreichen, um Zugang zur 2FA-Konfiguration zu erhalten. Die Cloud-Synchronisation kann in den Einstellungen gestoppt werden.
Auch Authy kann die 2FA-Konfiguration auf einem Server der Firma Twilio speichern und mit einem weiteren Gerät synchronisieren. Anders als bei Google werden Ihre 2FA-Daten immerhin mit einem von Ihnen zu wählenden Passwort verschlüsselt. Mangels Quellcode lässt sich aber nicht kontrollieren, wie sicher das Verfahren ist und ob es den Authy-Betreibern Zugriff auf Ihre Daten gewährt oder nicht. 2024 gab es eine Sicherheitspanne bei Twilio, bei der zwar anscheinend keine 2FA-Daten kompromittiert wurden, wohl aber die Telefonnummern von 35 Millionen Authy-Benutzern.
Sicherheits- und Privacy-Bedenken
Authenticator-Apps funktionieren prinzipiell rein lokal. Weder der beim Einrichten erforderliche Schlüssel bzw. QR-Code noch die ständig generierten Einmalcodes müssen auf einen Server übertragen werden. Die Apps implementieren den öffentlich standardisierten HMAC-based One-Time Password Algorithmus (OATH-HOTP).
Allerdings bieten einige OTP-Apps die Möglichkeit, die Account-Einträge über ein Cloud-Service zu sichern (siehe oben). Diese Cloud-Speicherung ist eine mögliche Sicherheitsschwachstelle.
Davon losgelöst gilt wie bei jeder App: Sie müssen der Firma vertrauen, die die App entwickelt hat. Der Code der App Google Authenticator war ursprünglich als Open-Source verfügbar, seit 2020 ist das leider nicht mehr der Fall. Wenn Sie weder Google Authenticator noch Authy vertrauen, finden Sie im Arch Linux Wiki Links zu Apps, deren Code frei verfügbar ist.
Mozilla hat Firefox 138.0.4 veröffentlicht und behebt damit zwei kritische Sicherheitslücken, welche im Rahmen des Hacking-Wettbewerbs Pwn2Own demonstriert worden sind.
Wie jedes Jahr fand auch in diesem Jahr wieder der Pwn2Own-Wettbewerb statt, dieses Mal in Berlin. Und wie bereits im Vorfeld erwartet, hat Mozilla in Form eines sehr schnellen Updates auf die Firefox betreffenden Ergebnisse reagiert. Firefox 138.0.4 behebt zwei Sicherheitslücken, welche Mozilla beide als kritisch einstuft. Ein Update ist für alle Nutzer dringend empfohlen.
In diesem Video zeigt Jean zwei einfache Anwendungen, mit denen man Text aus Dokumenten oder Bildern erkennen und extrahieren kann, in denen man eigentlich keinen Text markieren kann.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
- Zur Website von NAPS2: https://www.naps2.com/
- Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
- Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
- Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
- Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
- Offizielle Webseite: https://www.linuxguides.de
- Forum: https://forum.linuxguides.de/
- Unterstützen: http://unterstuetzen.linuxguides.de
- Mastodon: https://mastodon.social/@LinuxGuides
- X: https://twitter.com/LinuxGuides
- Instagram: https://www.instagram.com/linuxguides/
- Kontakt: https://www.linuxguides.de/kontakt/
Inhaltsverzeichnis:
-------------------------------------
00:00 Intro
00:15 NAPS2: Dokumente einscannen mit Texterkennung
05:08 Frog: Text vom Bildschirm erkennen
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
*) Werbung
00:00 Intro
00:15 NAPS2: Dokumente einscannen mit Texterkennung
05:08 Frog: Text vom Bildschirm erkennen
Kurz notiert: Die Programmiersprache Rust steht ab sofort in Version 1.87 bereit.
Die Programmiersprache Rust wurde planmäßig in Version 1.87 veröffentlicht. Wer sich für alle Highlights der neuen Version interessiert, findet wie immer in der offiziellen Release-Ankündigung weitere Informationen.
Die MZLA Technologies Corporation hat mit Thunderbird 138.0.1 ein Sicherheits-Update für seinen Open Source E-Mail-Client veröffentlicht.
Neuerungen von Thunderbird 138.0.1
Mit Thunderbird 138.0.1 hat die MZLA Technologies Corporation ein Update für seinen Open Source E-Mail-Client veröffentlicht. Die neue Version behebt mehrere Sicherheitslücken und Fehler.
Inhaltsverzeichnis:
-------------------------------------
0:00 Einführung
1:00 Zentrale Anmeldung mit 2 Faktor Authentifizierung
4:15 Weitere Profileinstellungen
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Mozilla hat Firefox 138.0.3 für Windows, macOS und Linux veröffentlicht. Firefox 138.0.2 wurde für diese Plattformen übersprungen, da Firefox 138.0.2 ein Update war, welches ausschließlich für Android erschienen war.
Die seit Firefox 137 schrittweise ausgerollte Unterstützung für Tab-Gruppen ist ab sofort für alle Nutzer standardmäßig aktiviert.
25 Prozent der neuen Nutzer auf Windows und macOS sehen beim ersten Start von Firefox einen Dialog zur Zustimmung der Nutzungsbedingungen und des Datenschutzhinweises von Firefox.
Die Links zur Mozilla-Dokumentation im Abschnitt „Surfen“ in den Firefox-Einstellungen funktionierten nicht mehr.
Die Tastenkombination Alt + C hatte bei Verwendung der Funktion „Seite durchsuchen“ nicht länger die Checkbox „Groß-/Kleinschreibung“ aktiviert respektive deaktiviert.
Unter Linux wurde ein Problem behoben, bei dem die Videowiedergabe unter Wayland verwaschen erschien, wenn keine HDR-Unterstützung verfügbar war.
Eine mögliche Absturzursache in Zusammenhang mit WebGL sowie eine weitere mögliche Absturzursache in Zusammenhang mit bestimmten SVG-Filtern wurde behoben.
Darüber hinaus wurden mehrere Webkompatibilitätsprobleme behoben.
In diesem Artikel halte ich fest, was es mit den genannten Begriffen auf sich hat und was ich in den vergangenen Tagen mit ihnen angestellt habe. Dabei gehe ich auch auf das Warum ein, während Fragen nach dem Wie vorwiegend in den Verweisen im Text beantwortet werden.
Der Artikel dient mir als Dokumentation und meinen Leser:innen zur Unterhaltung und zum Wissenstransfer.
Auf Codeberg könnt ihr eure eigenen Freie Software-Projekte entwickeln, zu anderen Projekten beitragen, inspirierende und nützliche Freie Software durchstöbern, euer Wissen teilen oder euren Projekten mit Codeberg Pages ein Zuhause im Web geben, um nur einige Beispiele zu nennen.
Die beiden vorstehenden Abschnitte wurden übersetzt mit DeepL.com (kostenlose Version) und anschließend leicht angepasst und mit Links angereichert.
Mit Codeberg.org werden keine kommerziellen Interessen verfolgt. Man ist hier (nur) Nutzer und/oder Unterstützer, jedoch nicht selbst ein Produkt. Mir gefällt die Mission des Projekts. Daher bin ich dazu übergegangen, einen Teil meiner Repositories hier zu verwalten. Zwar bin ich kein Mitglied des Vereins, unterstütze diesen jedoch durch gelegentliche Spenden.
Actions, Runner und Workflows
Plattformen wie Codeberg.org, GitHub und GitLab unterstützen Softwareentwicklungsprozesse durch CI/CD-Funktionalität.
Ein Forgejo-Runner ist ein Dienst, der Workflows von einer Forgejo-Instanz abruft, sie ausführt, mit den Protokollen zurücksendet und schließlich den Erfolg oder Misserfolg meldet.
Dabei ist ein Workflow in der Forgejo-Terminologie eine YAML-Datei im Verzeichnis .forgejo/workflows eines Repositories. Workflows umfassen einen oder mehrere Jobs, die wiederum aus einem oder mehreren Steps bestehen. Eine Action ist eine Funktion zur Erfüllung häufig benötigter Aufgaben, bspw. Quelltext auschecken, oder sich bei einer Container-Registry einloggen etc. Siehe für weitere Informationen Abschnitt Hierarchy ff. im Forgejo Actions user guide.
Motiviert, meinen eigenen Forgejo-Runner zu installieren, haben mich zwei Blog-Artikel von meinem Arbeitskollegen Jan Wildeboer:
Durch den Betrieb eigener Forgejo-Runner kann ich bereits vorhandene Rechenkapazität nutzen. Es fallen für mich und den Verein Codeberg e.V. dadurch keine zusätzlichen Kosten an. Für die Installation auf RHEL 9 bin ich dem Forgejo Runner installation guide gefolgt, da das in Jans Artikel erwähnte Repository ne0l/forgejo offensichtlich nicht mehr gepflegt wird und nur eine veraltete Version des Runner enthält.
Ein Dankeschön geht raus an Jan für unseren kurzen und produktiven Austausch dazu auf Mastodon.
Wozu das Ganze?
Ich beschäftige mich beruflich seit einiger Zeit mit dem RHEL image mode und möchte demnächst einen meiner KVM-Hypervisor damit betreiben. Bis es soweit ist, arbeite ich eine Weile im „Jugend forscht“-Modus und baue immer wieder neue Versionen meiner Container-Images. Der Ablauf ist dabei stets derselbe:
Um vorstehender Anforderung gerecht zu werden, speichere ich das erzeugte Container-Image in einem privaten Repository auf Quay.io. Sowohl für registry.redhat.io als auch für quay.io ist ein Login erforderlich, bevor es losgehen kann.
Für mich bot sich hier die Gelegenheit, die Nutzung von Forgejo Workflows zu lernen und damit den Ablauf zur Erstellung meines RHEL Bootc Images zu automatisieren.
Forgejo Workflow und Runner-Konfiguration
Im folgenden Codeblock findet ihr meinen Forgejo Workflow aus der Datei .forgejo/workflows/build_image.yaml, gefolgt von einer Beschreibung der einzelnen Schritte. Zur Erklärung der Begriffe name, on, env, jobs, steps, run, etc. siehe Workflow reference guide.
Der Workflow wird jedes Mal ausgeführt, wenn ich einen Commit in den Branch main pushe
Ich definiere einige Umgebungsvariablen, um bei Änderungen nicht alle Schritte im Workflow einzeln auf notwendige Änderungen prüfen zu müssen
Mit `runs-on: podman` bestimme ich, dass der Workflow auf einem Runner mit dem Label podman ausgeführt wird; der entsprechende Runner started dann einen rootless Podman-Container, in dem die folgenden Schritte innerhalb von rootful Podman ausgeführt werden (nested Podman bzw. Podman in Podman)
Git wird installiert
Anmeldung an registry.redhat.io erfolgt
Anmeldung an quay.io erfolgt
Das Git-Repository wird geklont, um es auf dem Runner verfügbar zu haben
Der Runner baut ein Container-Image (Erinnerung an mich selbst: Ersetze den hardcodierten Pfad durch eine Variable)
Das erstellte Image wird in die Registry gepusht
Damit mein Runner den obigen Workflow ausführen kann, existiert auf diesem die Konfigurationsdatei /etc/forgejo-runner/config.yml, welche ich mit dem Kommando forgejo-runner generate-config > config.yml erstellt und anschließend angepasst habe. Der folgende Codeblock zeigt nur die Abschnitte, die ich manuell angepasst habe.
Ich greife mal die Zeile podman:docker://registry.access.redhat.com/ubi9/podman heraus:
podman: am Beginn der Zeile beinhaltet das Label, welches im Worflow mit runs-on verwendet wird
Mit dem Rest der Zeile wird bestimmt, in welchem Container-Image der Workflow ausgeführt wird
Ich habe mich für ubi9/podman entschieden, weil
ich bei Red Hat arbeite und daher
mit den Prozessen zur Erstellung unserer Images vertraut bin,
wodurch sich ein gewisses Vertrauen gebildet hat.
Ich vertraue unseren Images mehr, als jenen, die irgendein Unbekannter gebaut hat und deren Inhalt ich nicht kenne (man kann den Inhalt aber selbstverständlich überprüfen)
und ich so prüfen konnte, ob sich ein Image mit „unseren“ Werkzeugen bauen läst (nicht, dass ich daran gezweifelt hätte).
Die Angabe von privileged: true ist erforderlich, wenn man innerhalb des Containers ebenfalls mit podman oder docker arbeiten möchte.
Entscheidungen
Meinem weiter oben abgebildeten Workflow ist zu entnehmen, dass ich auf die Verwendung von Forgejo Actions verzichtet habe. Das hat folgende Gründe:
Für die Verwendung ist node auf dem Runner erforderlich
node ist im Image ubi9/podman standardmäßig nicht installiert
Node.js ist für mich das Tor zur Hölle und ich vermeide dessen Nutzung wenn möglich
Die Nutzung ist keine Voraussetzung, da ich mein Ziel auch so ohne Mehraufwand erreicht habe
Sobald die Workflows länger und komplexer werden, mag sich meine Einstellung zu Actions ändern.
Zusammenfassung
Ich habe gelernt:
Forgejo Runner zu installieren und zu konfigurieren
Wie Forgejo Workflows funktionieren und auf Codeberg.org genutzt werden können
Wie ich mir damit zukünftig die Arbeit in anderen Projekten erleichtern kann
Suchmaschinen gibt es einige. Google, Bing und DuckDuckGo dürften die bekanntesten sein. Laut statcounter.com führt Google mit 87 Prozent Marktanteil den Suchmaschinenmarkt an. Auf Platz 2 befindet sich Bing mit knapp 6 Prozent Marktanteil....
In diesem Video geht es unter anderem um den Cosmic Desktop von den Pop!_OS Entwicklern, Sicherheitsprobleme mit dem Deepin Desktop und um Neuigkeiten über Fedora. Außerdem spreche ich über den Streit zwischen LibreOffice und OpenOffice sowie den Wechsel zu sudo auf Rust-Basis.
Kennst du jemanden, der Unterstützung bei Linux braucht? Hier findest du lokale Ansprechpartner: https://www.linuxguides.de/ansprechpartner-2/
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
Zu den gezeigten Seiten:
- Ubuntu wechselt zu Rust basiertem sudo: https://news.itsfoss.com/ubuntu-25-10-sudo-rs/
- Der Pop!OS Desktop Cosmic in der Version Alpha 7: https://blog.system76.com/post/cosmic-alpha-7-never-been-beta
- openSUSE entfernt den Deepin Desktop aus Sicherheitsgründen: https://security.opensuse.org/2025/05/07/deepin-desktop-removal.html
- der LibreOffice Post auf Mastodon: https://fosstodon.org/@libreoffice/114457065586781781
- Fedora ist eine offizielle WSL-Distro: https://devblogs.microsoft.com/commandline/fedora-linux-is-now-an-official-wsl-distro/
- Fedora 43 Änderungsvorschlag (nur noch Wayland für Gnome): https://discussion.fedoraproject.org/t/f43-change-proposal-wayland-only-gnome-self-contained/150261
- Werde jetzt zum Linux-Helden: https://www.linuxguides.de/netzwerk-linux-helden/
- Ubuntu 25.04, alle Neuerungen: https://youtu.be/ukfkM_V4SyE
- Tuxflash-Podcast: https://youtube.com/playlist?list=PLPK5iNo_kpNe0dtNukSwl02w64dKSYBlJ&si=-W4AdACQYDveMZIl
- Interview mit Libre Office (bei den Chemnitzer Linux Tagen) https://youtu.be/izgcMPrRSdU?si=HDcZS07UvCOiylgJ&t=12
- Werde jetzt zum Linux-Helden: https://www.linuxguides.de/netzwerk-linux-helden/
- Zum Libre Workspace Kurs: https://www.youtube.com/playlist?list=PLhvaM7uJr1PB4dC5QA660htfw-BGKMBmM
- Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
- Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
- Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
- Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
- Offizielle Webseite: https://www.linuxguides.de
- Forum: https://forum.linuxguides.de/
- Unterstützen: http://unterstuetzen.linuxguides.de
- Mastodon: https://mastodon.social/@LinuxGuides
- X: https://twitter.com/LinuxGuides
- Instagram: https://www.instagram.com/linuxguides/
- Kontakt: https://www.linuxguides.de/kontakt/
Inhaltsverzeichnis:
-------------------------------------
00:00 Begrüßung
00:53 sudo auf Rust-Basis
04:45 Neuer Cosmic-Desktop von Pop!OS
09:58 openSUSE entfernt Deepin Desktop
12:44 Sicherheitslücken in OpenOffice
15:11 Fedora ist WSL-Distro
16:58 Fedora 43 nur noch Wayland
20:25 Linux Ansprechpartner
23:22 Neuer Libre Workspace Kurs
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
In diesem Video zeigt Jean, wie man jedes Windows-Programm auf seinem Linux-Rechner zum Laufen bringen kann und zwar ohne eine Windows-Lizenz oder ein Microsoft-Konto
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
- Windows 11 Download (runterscrollen bis zum ISO-Image): https://www.microsoft.com/de-de/software-download/windows11
- VirtualBox Download: https://www.virtualbox.org/wiki/Linux_Downloads
- VirtualBox Crashkurs https://youtu.be/rFTNxS5Jd-Y
- Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
- Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
- Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
- Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
- Offizielle Webseite: https://www.linuxguides.de
- Forum: https://forum.linuxguides.de/
- Unterstützen: http://unterstuetzen.linuxguides.de
- Mastodon: https://mastodon.social/@LinuxGuides
- X: https://twitter.com/LinuxGuides
- Instagram: https://www.instagram.com/linuxguides/
- Kontakt: https://www.linuxguides.de/kontakt/
Inhaltsverzeichnis:
-------------------------------------
00:00 Begrüßung
01:08 Downloads
05:31 Vorbereitung von VirtualBox
09:43 Windows installieren und einrichten
15:20 Microsoft-Account umgehen
18:49 Bildschirmauflösung anpassen
22:14 Tipps für VirtualBox
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Die Blogs von Benedikt, Dirk und Robert feiern dieses Jahr Geburtstag. Zu diesem Anlass haben die Drei die #BlogWochen2025 ausgerufen. Jede Bloggerin und jeder Blogger ist eingeladen, dabei mitzumachen. Details könnt ihr in den Blogs der drei nachlesen:
Zum Thema des heutigen Tages steuere ich gerne einen Beitrag bei.
Was mich zum Bloggen antreibt
Ich verfolge mit meinem Blog drei Ziele:
Dinge aufschreiben, die mir hilfreich waren bzw. die ich nützlich finde und die ich in Zukunft noch einmal gebrauchen kann – Mein Blog ist mein Gedächtnis für IT-Dinge
Mein Wissen mit der Welt teilen, damit andere davon profitieren können
Meine Meinung mit der Welt teilen, um mit anderen ins Gespräch zu kommen und andere Meinungen kennenzulernen
Da es im IT-Bereich bereits sehr viele gute Blogs in englischer Sprache gibt, habe ich mich zu Beginn entschieden, in Deutsch zu bloggen, um zur deutschsprachigen Gemeinschaft beizutragen. Meine Idee war und ist, damit denen zu helfen, für die Englisch gegebenenfalls noch eine Hürde darstellt. Diesen Grundsatz behalte ich bis auf ganz wenige Ausnahmen bis heute bei. Meine Artikel in englischer Sprache veröffentliche ich an anderer Stelle.
Ich freue mich, wenn ich Rückmeldungen erhalte, dass jemand meine Texte hilfreich und nützlich fand und meine Leser Gefallen daran finden. Besonders freue ich mich, wenn darunter Perlen aus der Vergangenheit sind. Dies zeigt mir, dass selbst Artikel von vor über 10 Jahren noch eine gewisse Relevanz besitzen.
Diese Rückmeldungen sind es, die mich motivieren, nach immer neuen Themen zu suchen und diese für den Blog zu verschriftlichen.
Zudem muss ich jedes Mal schmunzeln, wenn ich im Internet die Antwort auf eine Frage suche und diese dann in meinem eigenen Blog finde. So stellt mein Blog inzwischen für mich eine wertvolle Wissensdatenbank dar, auf die ich regelmäßig und gerne zurückgreife.
Wie ist das bei euch? Lest und stöbert ihr gerne in Blogs? Favorisiert ihr andere Formate? Bloggt ihr selbst? Ich freue mich über eure Kommentare oder Blogposts zu diesem Thema.
Inhaltsverzeichnis:
-------------------------------------
0:00 Einführung
2:00 Benutzer und Gruppenadministration
8:00 Daten-Import & Export
10:00 Systemverwaltung: Alles auf einen Blick
11:00 Backup wiederherstellen
16:00 Portal anpassen
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.