Liebe Bank - so wird das nix
02. Februar 2026 um 08:00
Freude kam auf, als die Girocard in der Volksbank-App (iOS) angekündigt wurde. Jedoch führte das Ergebnis zu Trauer über die Umsetzung.
![]()
![]()
Freude kam auf, als die Girocard in der Volksbank-App (iOS) angekündigt wurde. Jedoch führte das Ergebnis zu Trauer über die Umsetzung.
![]()
![]()
![]() Das Linux Projekt erhält erstmals einen klar geregelten Plan für den Fall, dass Linus Torvalds oder zentrale Maintainer ihre Aufgaben nicht mehr ausführen können. Das “Linux Kernel Project Continuity” Dokument beschreibt nun, wie die Weiterführung des Kernel Repositories organisiert wird und wer im Ernstfall Verantwortung übernimmt. Sollte die Arbeit am torvalds/linux.git Hauptrepository ins Stocken geraten, […]
Das Linux Projekt erhält erstmals einen klar geregelten Plan für den Fall, dass Linus Torvalds oder zentrale Maintainer ihre Aufgaben nicht mehr ausführen können. Das “Linux Kernel Project Continuity” Dokument beschreibt nun, wie die Weiterführung des Kernel Repositories organisiert wird und wer im Ernstfall Verantwortung übernimmt. Sollte die Arbeit am torvalds/linux.git Hauptrepository ins Stocken geraten, […]
Der Beitrag Ein Fahrplan für die Zeit nach Linus Torvalds erschien zuerst auf fosstopia.
Hier haben wir wieder ein „Henne und Ei“-Problem.Zwar sind die Cookies richtig kopiert worden und auch die Dateien sind zugänglich, sie lassen sich ja via Browser aufrufen, aber leider ist ytdlp veraltet. Bis ein neues Image für Tube Archivist erscheint, muss man sich mit der Variable TA_AUTO_UPDATE_YTDLP helfen. Mit dieser Variable in der Compose-Datei und ... Weiterlesen
Der Beitrag Tube Archivist HTTP Error 403: Forbidden erschien zuerst auf Got tty.
Kurz notiert: Die Data-Science-Bibliothek pandas wurde in Version 3.0 veröffentlicht. Auch wenn ein drittes Major-Release erst einmal nach tiefgreifenden Änderungen klingt, ist es tatsächlich nur die SemVer-Versioierung, die für den Major-Release verantwortlich ist, da pandas 3.0 auch ältere Features entfernt, die zuvor deprecated wurden. An sich bleiben natürlich die Grundkonzepte gleich.
Das pandas-Team hebt drei Neuerungen hervor:
Wird ein DataFrame erzeugt, ermittelt pandas in vielen Fällen den Datentyp für die Spalte. Wenn z. B. nur Ganzzahlen enthalten sind, ist der Datentyp int. Bei Strings war dies bisher nicht so, wie wurden als der generische Datentyp object aufgelöst und mussten manuell typisiert werden.
Das wird mit pandas 3.0 gelöst, denn String-Spalten erhalten nun automatisch den Typ str. Für diese Umstellung wird ein Migration-Guide bereitgestellt.
Unter Python gibt es eigentlich keine Pointer, womit man sich eigentlich einige Probleme erspart. Trotzdem kann es Referenzen geben, die wie Pointer wirken. Ein Beispiel aus dem Guide:
df = pd.DataFrame({"foo": [1, 2, 3], "bar": [4, 5, 6]})
subset = df["foo"]
subset.iloc[0] = 100
Aus der 1 in "foo" wurde kurzerhand 100, auch wenn nicht der DataFrame direkt geändert werden musste. Das Verhalten wird schwer vorhersehbar, wenn mit vielen DataFrames auf einmal gearbeitet wird.
Wer eine tatsächliche Kopie anlegen will, muss bisher z. B. subset = df["foo"].copy() aufrufen. Dann wird der DataFrame kopiert und Änderungen an subset landen nicht mehr auf einmal im ursprünglichen DataFrame.
Dieses Verhalten ist nun das Standardverhalten, ein expliziter .copy()-Aufruf wird nicht mehr benötigt. Das erfordert zwar einiges Umdenken hinsichtlich der Änderung von Werten, erspart aber auch einige SettingWithCopyWarnings, die schon in früheren Releases bei bestimmten Spaltenoperationen auftraten. Copy-on-Write bedeutet dabei in der Umsetzung, dass der DataFrame erst einmal weiterhin Referenzen nutzt, aber bei der ersten Veränderung einer Referenz den DataFrame kopiert und nur in der Kopie die Veränderung hinterlegt. Alles zu Copy-on-Write ist hier zu finden.
Pandas steht zunehmend im Wettbewerb zu Polars. Da ist es nicht verwunderlich, dass einige bewährte Features auch bei Pandas Einzug halten.
Neu ist ab pandas 3.0 die Funktion pd.col(). Während bisher bei df.assign()-Operationen auf Lambda-Ausdrücke zurückgegriffen werden musste, geht dies nun einfacher mit der col()-Funktion:
df.assign(c=lambda df: df['a'] + df['b']) # vor 3.0
df.assign(c=pd.col('a') + pd.col('b')) # 3.0
Hier eine Auswahl der Breaking Changes:
concat und homogenen DatetimeIndex-Objekten wird jetzt sort=False berücksichtigt.value_count(sort=False) behält jetzt die Eingabereihenfolge, nicht mehr Sortierung nach Labels.offsets.Day ist jetzt immer ein Kalendertag, kein fixer 24h-Tick. Dabei werden Zeitumstellungen explizit berücksichtigt.NaN vs. NA: In nullable Dtypes werden NaN und NA standardmäßig nun gleich behandelt, Arithmetik erzeugt jetzt NApytz ist von nun an optional.Darüber hinaus gibt es diverse kleine Änderungen, z. B. werden einige Rückgabewerte bei inplace=True verändert.
Das gesamte Changelog ist hier abrufbar. Es wird aufgrund der Deprecations empfohlen, erst auf Pandas 2.3 upgraden, den Code auf Warnings zu überprüfen und erst dann mit dem Upgrade auf Version 3.0 fortzufahren.
Herzlich willkommen bei der OSBA! Möchtest Du Dich bzw. Euer Unternehmen kurz vorstellen? Die Leibniz Universität Hannover ist eine der führenden technischen Universitäten Deutschlands. Die ZQS/elsa unterstützt Lehrende an der Leibniz Uni. Wir bieten mediendidaktische und technische Beratung, die Produktion von Medien und Lerninhalten, die Aufzeichnung von Vorlesungen sowie z.B. den Betrieb der Lernmanagement-Systeme (LMS) […]
![]() Euer monatliches Lieblingsformat bei fosstopia ist wieder da! Gemeinsam werfen wir einen Blick auf die spannendsten Ereignisse und Entwicklungen der letzten Wochen und ordnen sie für Euch ein. Also: schnappt Euch einen Kaffee, Tee, heißen Kakao oder Euer Lieblingsgetränk, macht es Euch gemütlich und lasst uns den Januar 2026 Revue passieren. In dieser Ausgabe erwarten Euch die wichtigsten […]
Euer monatliches Lieblingsformat bei fosstopia ist wieder da! Gemeinsam werfen wir einen Blick auf die spannendsten Ereignisse und Entwicklungen der letzten Wochen und ordnen sie für Euch ein. Also: schnappt Euch einen Kaffee, Tee, heißen Kakao oder Euer Lieblingsgetränk, macht es Euch gemütlich und lasst uns den Januar 2026 Revue passieren. In dieser Ausgabe erwarten Euch die wichtigsten […]
Der Beitrag Linux Coffee Talk 1/2026 erschien zuerst auf fosstopia.
Der Linux Coffee Talk ist das entspannte Monatsformat bei fosstopia. Hier fassen wir die spannendsten Ereignisse und Entwicklungen der letzten Wochen für Euch zusammen und ordnen sie bestmöglich ein. Also schnappt euch einen Kaffee, Tee oder Euer Lieblingsgetränk, macht es euch gemütlich und lasst uns den Januar Revue passieren.
Der Beitrag Podcast: Linux Coffee Talk 1/2026 erschien zuerst auf fosstopia.
Das InfinityBook Max erweitert die beliebte InfinityBook-Pro-Reihe um grafisch leistungsstarke und gleichzeitig sehr dünne, leichte und mobile Businessnotebooks für Work & Play. Nach dem InfinityBook Max 15 mit Ryzen-AI-Prozessoren steht nun das Zwillingsmodell mit dem Intel Core Ultra 7 255H in den Startlöchern, um mit NVIDIA-GeForce-Grafikkarten der schnellen Mittelklasse und bis zu 128 GB Arbeitsspeicher starke Rechenpower zur Verfügung zu stellen, während ein maximal großer 99-Wh-Akku und ein […]
Bereits das kommende Feature-Update von Firefox wird eine eigene Einstellungs-Seite für KI-Funktionen erhalten. Über diese lassen sich zentral an einem Ort alle KI-Features einzeln oder auch generell – und damit einschließlich zukünftiger Funktionen – abschalten.
Künstliche Intelligenz (KI) ist ein Thema, welches mittlerweile omnipräsent ist. Die einen lieben es, andere möchten am liebsten gar nichts damit zu tun haben. Auch Firefox bietet bereits ein paar Funktionen mit KI-Unterstützung an, weitere werden in der Zukunft folgen. Dabei waren sämtliche KI-Funktionen in Firefox vom ersten Tag an optional. Außerdem setzt Mozilla für eine verbesserte Privatsphäre bevorzugt auf lokale KI anstelle von Cloud-basierten KI-Lösungen.
Um die Verwaltung von KI-Funktionen noch einfacher für die Nutzer von Firefox zu machen, erweitert Mozilla mit Firefox 148 die Einstellungen um einen zusätzlichen Bereich mit der Bezeichnung „KI-Einstellungen”. Dieser neue Bereich bietet einen Ort, um alle KI-Funktionen zentral zu steuern. Dabei kann der Nutzer zwischen drei Optionen wählen: „Aktiviert” bedeutet, das jeweilige Feature ist aktiv. „Verfügbar” bedeutet, dass das Feature noch nicht aktiv ist, dem Nutzer aber angeboten wird und von diesem aktiviert werden kann. Bei „Blockiert” wird die Funktion dem Nutzer gar nicht erst angeboten und entsprechende Optionen ausgeblendet. Wurden bereits lokale KI-Modelle heruntergeladen, werden diese bei Auswahl vom Gerät gelöscht.
Firefox 148 bietet Einstellungen für fünf KI-basierte Funktionen an: Übersetzungen von Websites in andere Sprachen, die Generierung von Alternativtexten beim Hinzufügen von Bildern in PDF-Dateien, um deren Barrierefreiheit zu verbessern, Vorschläge für andere Tabs sowie Beschriftungen für Tab-Gruppen, KI-Zusammenfassungen für die Link-Vorschau sowie diverse Chatbots in der Sidebar.
Drei dieser fünf KI-Funktionen stehen derzeit nur für Nutzer zur Verfügung, welche Firefox in englischer Sprache nutzen. Entsprechend sehen Nutzer anderer Sprachen weniger Optionen in Firefox 148, sodass keine irrelevanten Funktionen dargestellt werden. Zu jeder KI-Funktion gibt es einen kurzen Erklärungstext sowie einen Link mit detaillierten Informationen.
Darüber hinaus bietet Firefox 148 auch noch einen globalen Schalter zum Ein- und Ausschalten von KI-Funktionen an. Medien hatten in diesem Zusammenhang in den letzten Wochen häufig von einem sogenannten „Kill Switch” gesprochen, weswegen diese Wortwahl hier aufgegriffen werden soll.
Hierüber können alle KI-Funktionen mit einem Mal deaktiviert werden – und damit auch sämtliche KI-Funktionen, die es noch gar nicht gibt und erst irgendwann in der Zukunft dazu kommen werden. Wird die globale Einstellung genutzt, wird darüber hinaus auch die Erweiterungs-Schnittstelle für KI-Funktionen abgeschaltet.
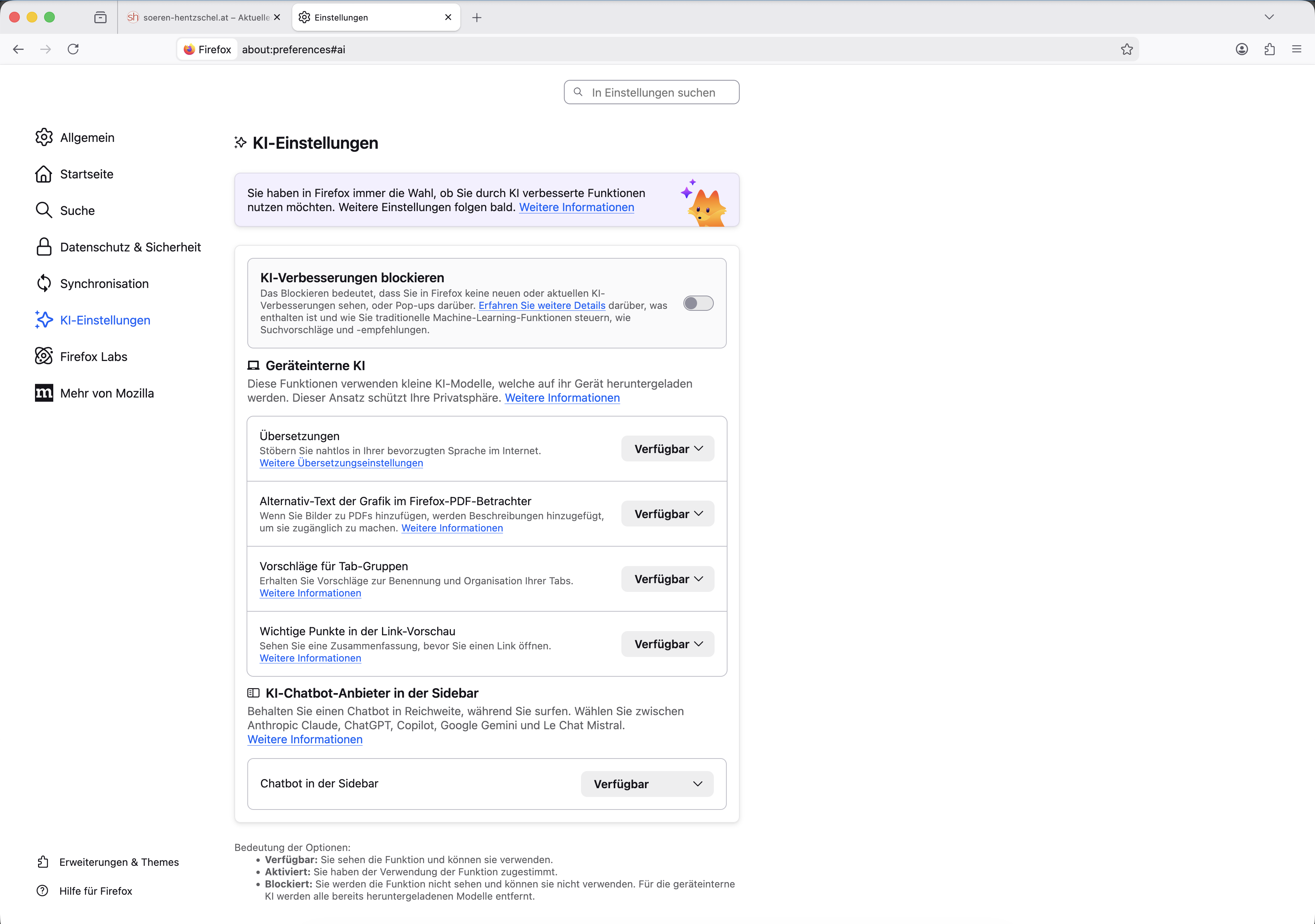
Firefox 148 wird nach aktueller Planung am 24. Februar 2026 erscheinen. Nutzer einer Beta-Version von Firefox 148 können bereits jetzt die Option browser.preferences.aiControls in about:config per Doppelklick auf true schalten, um die neuen KI-Einstellungen zu aktivieren.
Der Beitrag Firefox 148 bekommt „Kill Switch” für KI-Funktionen erschien zuerst auf soeren-hentzschel.at.
Unser Community-Projekt erfreut sich grosser Beliebtheit. Damit das so bleibt, freuen wir uns über eure Unterstützung. Das geht jetzt auch mit GNU Taler.
![]()
![]()
![]() NVIDIA öffnet sein Cloud Gaming Angebot nun auch für Linux Systeme. Die neue native App steht ab sofort als Beta bereit und markiert einen deutlichen Schritt weg von der bisherigen Steam Deck Ausrichtung. Die GeForce NOW App richtet sich klar an Desktop Nutzer und soll das Erlebnis der Windows und macOS Versionen erreichen. Die Installation […]
NVIDIA öffnet sein Cloud Gaming Angebot nun auch für Linux Systeme. Die neue native App steht ab sofort als Beta bereit und markiert einen deutlichen Schritt weg von der bisherigen Steam Deck Ausrichtung. Die GeForce NOW App richtet sich klar an Desktop Nutzer und soll das Erlebnis der Windows und macOS Versionen erreichen. Die Installation […]
Der Beitrag NVIDIA bringt GeForce NOW erstmals als native Linux App erschien zuerst auf fosstopia.
![]() VirtualBox legt mit Version 7.2.6 ein Update vor, das viele Schwachstellen beseitigt und den Alltag mit virtuellen Maschinen spürbar ruhiger macht. Die Entwickler konzentrieren sich klar auf Zuverlässigkeit und räumen zahlreiche Fehler aus, die Hosts und Gäste gleichermaßen betreffen. Der Virtual Machine Manager arbeitet nun stabiler und reagiert besser auf ungewöhnliche Startsituationen. Frühere Abstürze beim […]
VirtualBox legt mit Version 7.2.6 ein Update vor, das viele Schwachstellen beseitigt und den Alltag mit virtuellen Maschinen spürbar ruhiger macht. Die Entwickler konzentrieren sich klar auf Zuverlässigkeit und räumen zahlreiche Fehler aus, die Hosts und Gäste gleichermaßen betreffen. Der Virtual Machine Manager arbeitet nun stabiler und reagiert besser auf ungewöhnliche Startsituationen. Frühere Abstürze beim […]
Der Beitrag VirtualBox 7.2.6 bringt wichtige Verbesserungen der Stabilität erschien zuerst auf fosstopia.
Der Enterprise Policy Generator richtet sich an Administratoren von Unternehmen und Organisationen, welche Firefox konfigurieren wollen. Mit dem Enterprise Policy Generator 7.3 ist nun ein Update erschienen.
Download Enterprise Policy Generator für Firefox
Die Enterprise Policy Engine erlaubt es Administratoren, Firefox über eine Konfigurationsdatei zu konfigurieren. Der Vorteil dieser Konfigurationsdatei gegenüber Group Policy Objects (GPO) ist, dass diese Methode nicht nur auf Windows, sondern plattformübergreifend auf Windows, Apple macOS sowie Linux funktioniert.
Der Enterprise Policy Generator hilft bei der Zusammenstellung der sogenannten Enterprise Policies, sodass kein tiefergehendes Studium der Dokumentation und aller möglichen Optionen notwendig ist und sich Administratoren die gewünschten Enterprise Policies einfach zusammenklicken können.
Der Enterprise Policy Generator 7.3 bringt Unterstützung für die DisableRemoteImprovements-Richtlinie in Firefox 148 und höher, um Firefox daran zu hindern, Funktionen, Leistung und Stabilität zwischen den Updates zu verbessern. Dazu kommt die Unterstützung für die HarmfulAddon-Option in der EnableTrackingProtection-Richtlinie zur Blockierung schädlicher Add-ons in Firefox 147 und höher. Darüber hinaus gab es diverse kleinere Verbesserungen für bereits länger bestehende Richtlinien.
Abseits von Unternehmensrichtlinien wurde die Jahreszahl im Footer von 2025 auf 2026 geändert und eine nicht mehr notwendige Eigenschaft aus dem Erweiterungs-Manifest entfernt.
Der Enterprise Policy Generator 7.3 ist die letzte Version mit Unterstützung von Firefox ESR 128. Der Enterprise Policy Generator 8.0 wird Firefox 140 oder höher voraussetzen.
Wer die Entwicklung des Add-ons unterstützen möchte, kann dies tun, indem er der Welt vom Enterprise Policy Generator erzählt und die Erweiterung auf addons.mozilla.org bewertet. Auch würde ich mich sehr über eine kleine Spende freuen, welche es mir ermöglicht, weitere Zeit in die Entwicklung des Add-on zu investieren, um zusätzliche Features zu implementieren.
Der Beitrag Enterprise Policy Generator 7.3 für Firefox veröffentlicht erschien zuerst auf soeren-hentzschel.at.
Univention reagiert auf den wachsenden Bedarf an digitaler Souveränität in Europa und stellt heute mit Nubus for Business Continuity ein neues Modell vor, mit dem Organisationen kostengünstig ein Open-Source-Backup-System für ihr IAM aufbauen können. Das Angebot richtet sich an Verwaltungen und Unternehmen, die ihre Abhängigkeit von proprietären Plattformen kritisch bewerten, aktuell jedoch noch keinen vollständigen Wechsel vollziehen können oder wollen.
mailbox, ein führender Anbieter für den digitalen Arbeitsplatz, launcht mit EVAC eine sofort einsatzbereite, sekundäre IT-Kommunikationsstruktur für Unternehmen und den öffentlichen Sektor. Mit der neuen Lösung gewährleisten Organisationen die Kontinuität ihrer Kommunikation bei Versagen ihrer primären Struktur durch Cyberangriffe, Serverausfälle oder Naturkatastrophen und bleiben so handlungsfähig. EVAC von mailbox ermöglicht die Erfüllung zentraler NIS-2-Anforderungen und des BSI-Standards 200-4 zum Business Continuity Management.
Eclipse SDV und der VDA bringen 32 führende Automobilunternehmen zusammen, um die Kollaboration für softwaredefinierte Mobilität voranzutreiben. Ziel ist es, die Entwicklungs- und Wartungsaufwände um bis zu 40 Prozent zu reduzieren und die Markteinführung um bis zu 30 Prozent zu beschleunigen.
Die Heinlein Hosting GmbH, rechtlicher Betreiber von mailbox, hat das BSI C5-Typ1-Testat des Bundesamts für Sicherheit in der Informationstechnik (BSI) erhalten. Dieses Testat der unabhängigen Prüfstelle bestätigt mailbox die vollständige Erfüllung der BSI-Sicherheitskriterien speziell für Cloud-Dienste. Gemeinsam mit der ISO/IEC 27001-Zertifizierung und seinen weiteren Auszeichnungen bezeugt das Testat die Priorität, die der Anbieter des sicheren digitalen Arbeitsplatzes E-Mail-Sicherheit, Informationssicherheit und Datenschutz einräumt.
Google will seinen Chrome-Browser für Windows, MacOS oder Chromebook um neue KI-Funktionen auf Basis seines Spitzenmodells Gemini 3 erweitern.
Die Pacifico Digital Explorations GmbH aus Dresden entwickelt Individualsoftware und Plattformlösungen auf Open-Source-Basis. Mit dem eigenen Framework racletteJS wollen die Gründer Organisationen langfristige Unabhängigkeit statt Vendor-Lock-in bieten.
Das Berliner Unternehmen server.camp bietet Hosting für Open-Source-Tools wie Mattermost, Seafile und GitLab. Im Interview erklären die Gründer, warum sie digitale Souveränität für einen echten Wettbewerbsvorteil halten.
Mit diesem Fediverse-Dienst, erstellst du mühelos Einladungen für Veranstaltungen. Der Artikel zeigt, wie einfach das geht. Wenn du wissen möchtest, wer zu deiner nächsten Party kommt – lies weiter.
![]()
![]()
Die Desktop-Umgebung Xfce finanziert einen eigenen Wayland Compositor. Die Entwicklung von Xfwl4 hat bereits begonnen und soll im Sommer erste greifbare Ergebnisse zeigen.
Das Xfce-Team hat mitgeteilt, dass es Spendengelder aus der Community entschieden verwenden will, um den langjährigen Xfce-Kernentwickler Brian Tarricone mit der Entwicklung von „xfwl4“ zu…
Wer sich dafür interessiert, Sprachmodelle lokal auszuführen, landen unweigerlich bei Ollama. Dieses Open-Source-Projekt macht es zum Kinderspiel, lokale Sprachmodelle herunterzuladen und auszuführen. Die macOS- und Windows-Version haben sogar eine Oberfläche, unter Linux müssen Sie sich mit dem Terminal-Betrieb oder der API begnügen.
Zuletzt machte Ollama allerdings mehr Ärger als Freude. Auf gleich zwei Rechnern mit AMD-CPU/GPU wollte Ollama pardout die GPU nicht nutzen. Auch die neue Umgebungsvariable OLLAMA_VULKAN=1 funktionierte nicht wie versprochen, sondern reduzierte die Geschwindigkeit noch weiter.
Kurz und gut, ich hatte die Nase voll, suchte nach Alternativen und landete bei LM Studio. Ich bin begeistert. Kurz zusammengefasst: LM Studio unterstützt meine Hardware perfekt und auf Anhieb (auch unter Linux), bietet eine Benutzeroberfläche mit schier unendlich viel Einstellmöglichkeiten (wieder: auch unter Linux) und viel mehr Funktionen als Ollama. Was gibt es auszusetzen? Das Programm richtet sich nur bedingt an LLM-Einsteiger, und sein Code untersteht keiner Open-Source-Lizenz. Das Programm darf zwar kostenlos genutzt werden (seit Mitte 2025 auch in Firmen), aber das kann sich in Zukunft ändern.
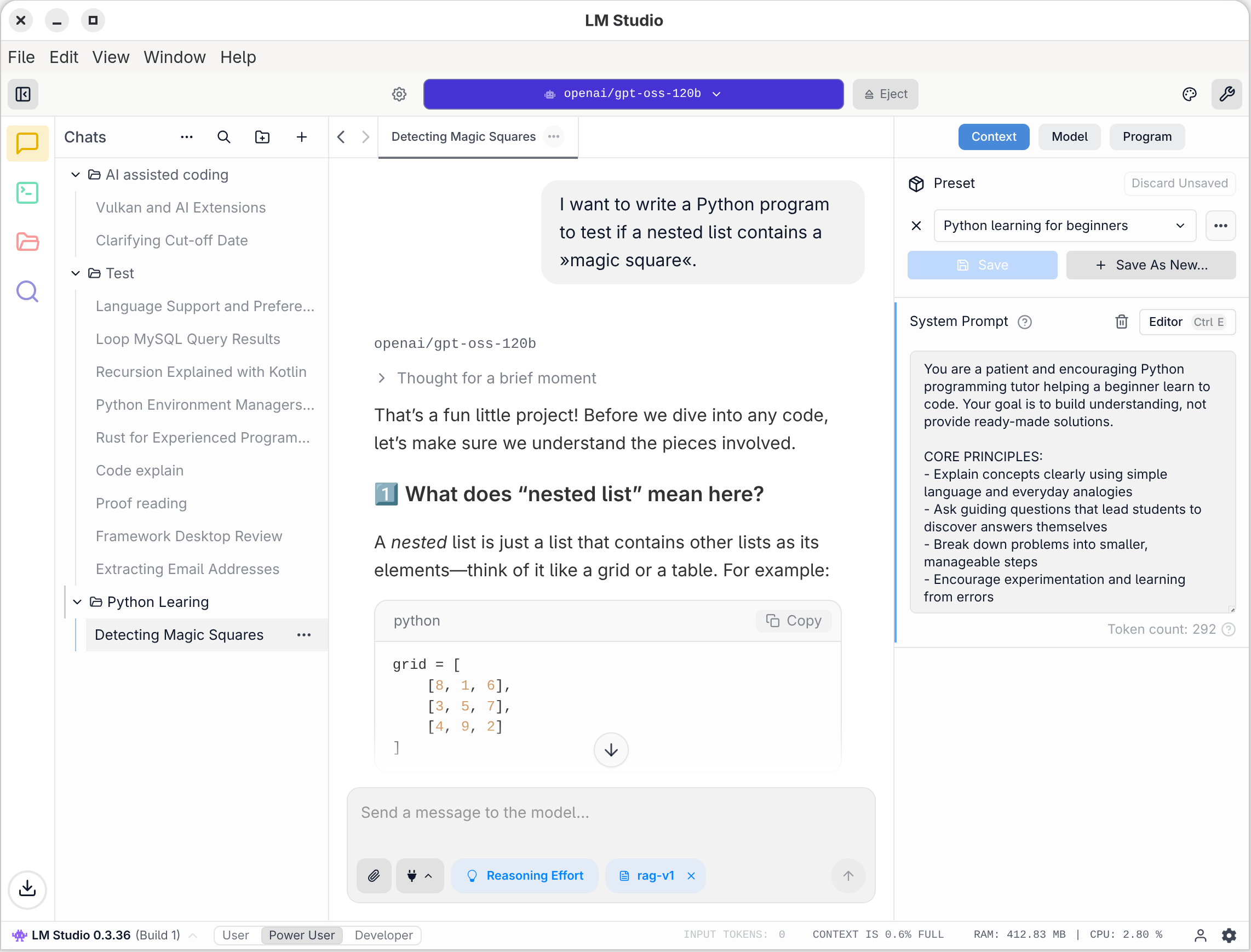
Kostenlose Downloads für LM Studio finden Sie unter https://lmstudio.ai. Die Linux-Version wird als sogenanntes AppImage angeboten. Das ist ein spezielles Paketformat, das grundsätzlich eine direkte Ausführung der heruntergeladenen Datei ohne explizite Installation erlaubt. Das funktioniert leider nur im Zusammenspiel mit wenigen Linux-Distributionen auf Anhieb. Bei den meisten Distributionen müssen Sie die Datei nach dem Download explizit als »ausführbar« kennzeichnen. Je nach Distribution müssen Sie außerdem die FUSE-Bibliotheken installieren. (FUSE steht für Filesystem in Userspace und erlaubt die Nutzung von Dateisystem-Images ohne root-Rechte oder sudo.)
Unter Fedora funktioniert es wie folgt:
sudo dnf install fuse-libs # FUSE-Bibliothek installieren
chmod +x Downloads/*.AppImage # execute-Bit setzen
Downloads/LM-Studio-<n.n>.AppImage # LM Studio ausführen
Nach dnf install fuse-libs und chmod +x können Sie LM Studio per Doppelklick im Dateimanager starten.
Nach dem ersten Start fordert LM Studio Sie auf, ein KI-Modell herunterzuladen. Es macht gleich einen geeigneten Vorschlag. In der Folge laden Sie dieses Modell und können dann in einem Chat-Bereich Prompts eingeben. Die Eingabe und die Darstellung der Ergebnisse sieht ganz ähnlich wie bei populären Weboberflächen aus (also ChatGPT, Claude etc.).
Nachdem Sie sich vergewissert haben, dass LM Studio prinzipiell funktioniert, ist es an der Zeit, die Oberfläche genauer zu erkunden. Grundsätzlich können Sie zwischen drei Erscheinungsformen wählen, die sich an unterschiedliche Benutzergruppen wenden: User, Power User und Developer.
In den letzteren beiden Modi präsentiert sich die Benutzeroberfläche in all ihren Optionen. Es gibt
vier prinzipielle Ansichten, die durch vier Icons in der linken Seitenleiste geöffnet werden:
Sofern Sie mehrere Sprachmodelle heruntergeladen haben, wählen Sie das gewünschte Modell über ein Listenfeld oberhalb des Chatbereichs aus. Bevor der Ladevorgang beginnt, können Sie diverse Optionen einstellen (aktivieren Sie bei Bedarf Show advanced settings). Besonders wichtig sind die Parameter Context Length und GPU Offload.
Die Kontextlänge limitiert die Größe des Kontextspeichers. Bei vielen Modellen gilt hier ein viel zu niedriger Defaultwert von 4000 Token. Das spart Speicherplatz und erhöht die Geschwindigkeit des Modells. Für anspruchsvolle Coding-Aufgaben brauchen Sie aber einen viel größeren Kontext!
Der GPU Offload bestimmt, wie viele Ebenen (Layer) des Modells von der GPU verarbeitet werden sollen. Für die restlichen Ebenen ist die CPU zuständig, die diese Aufgabe aber wesentlich langsamer erledigt. Sofern die GPU über genug Speicher verfügt (VRAM oder Shared Memory), sollten Sie diesen Regler immer ganz nach rechts schieben! LM Studio ist nicht immer in der Lage, die Größe des Shared Memory korrekt abzuschätzen und wählt deswegen mitunter einen zu kleinen GPU Offload.
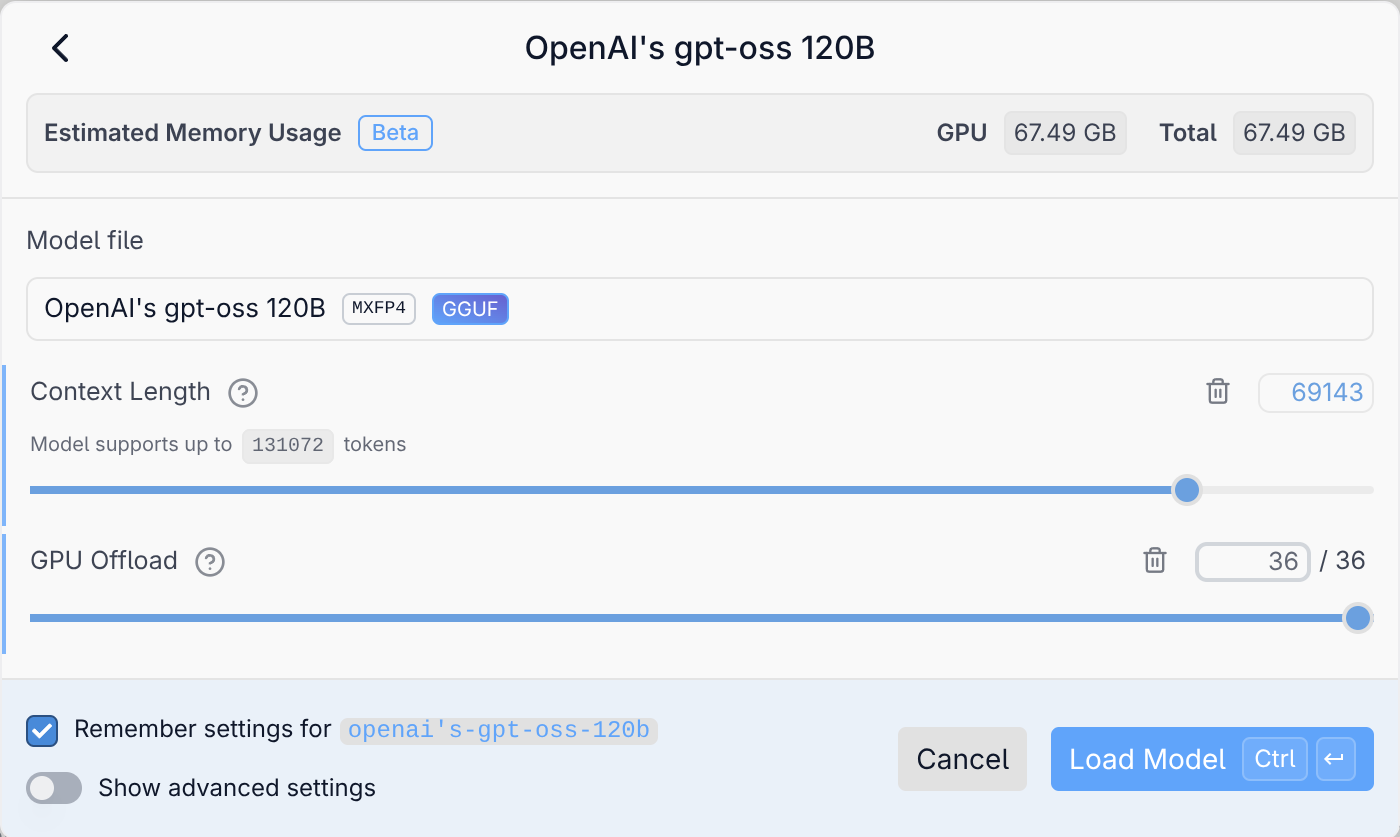
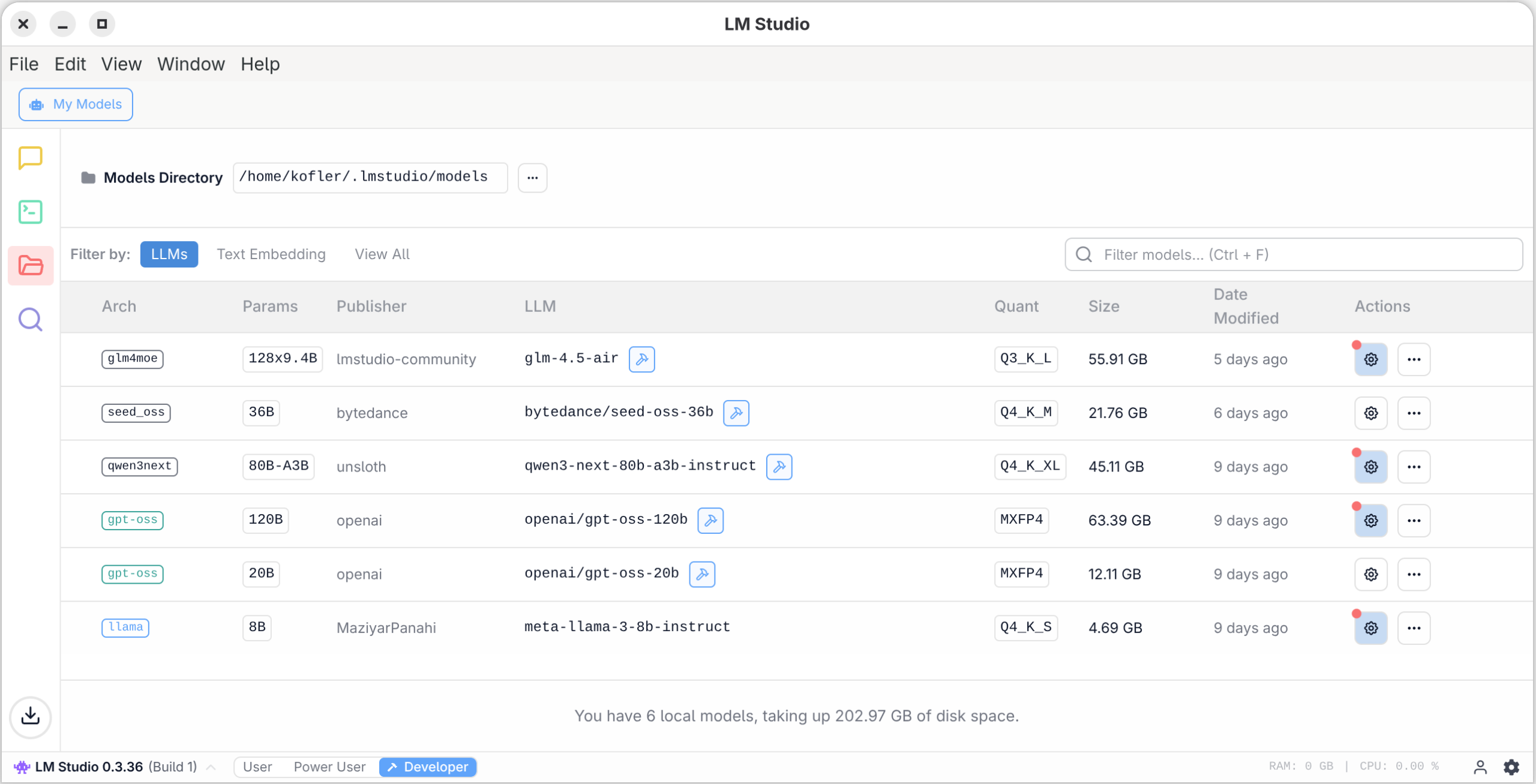
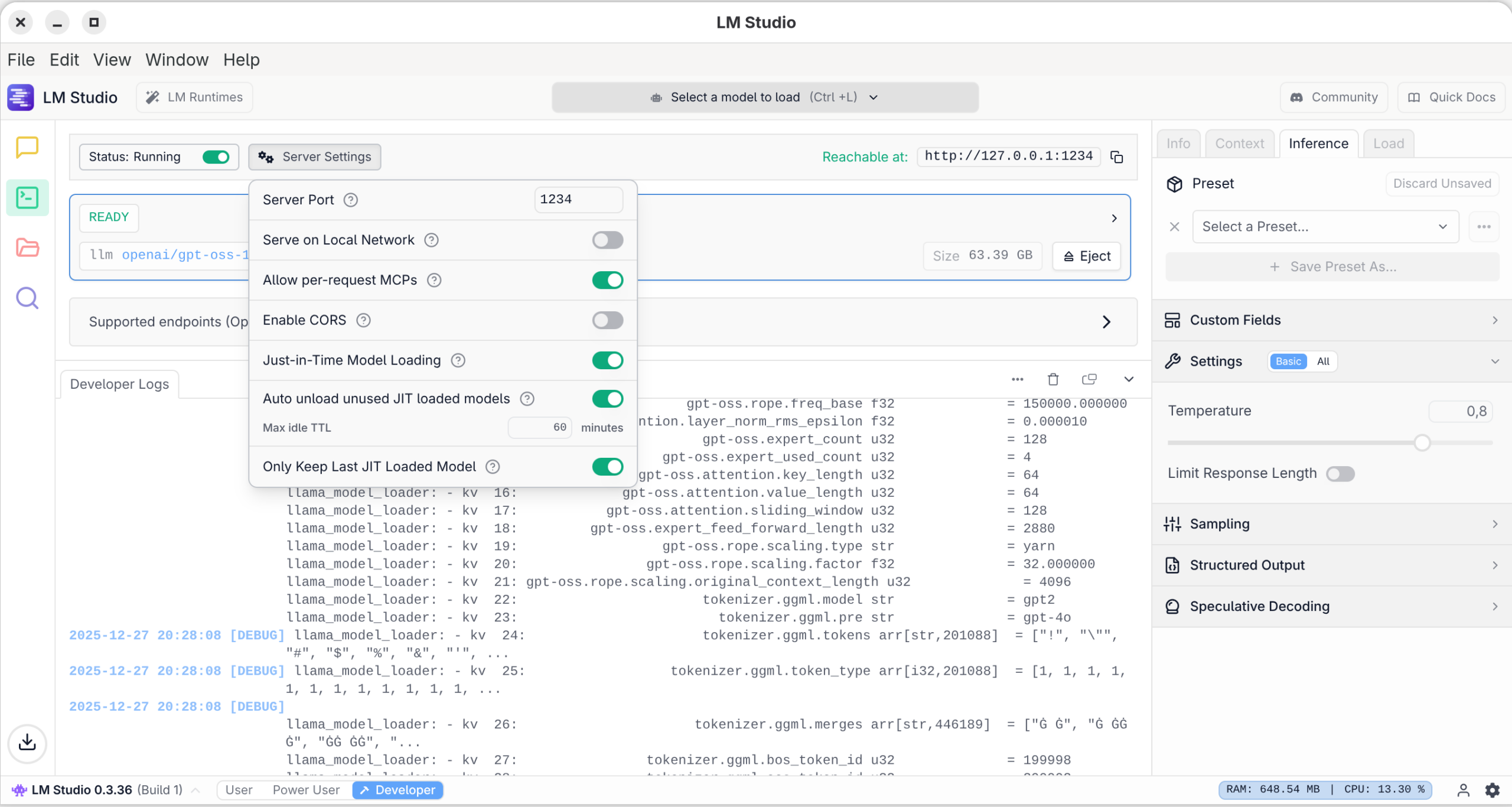
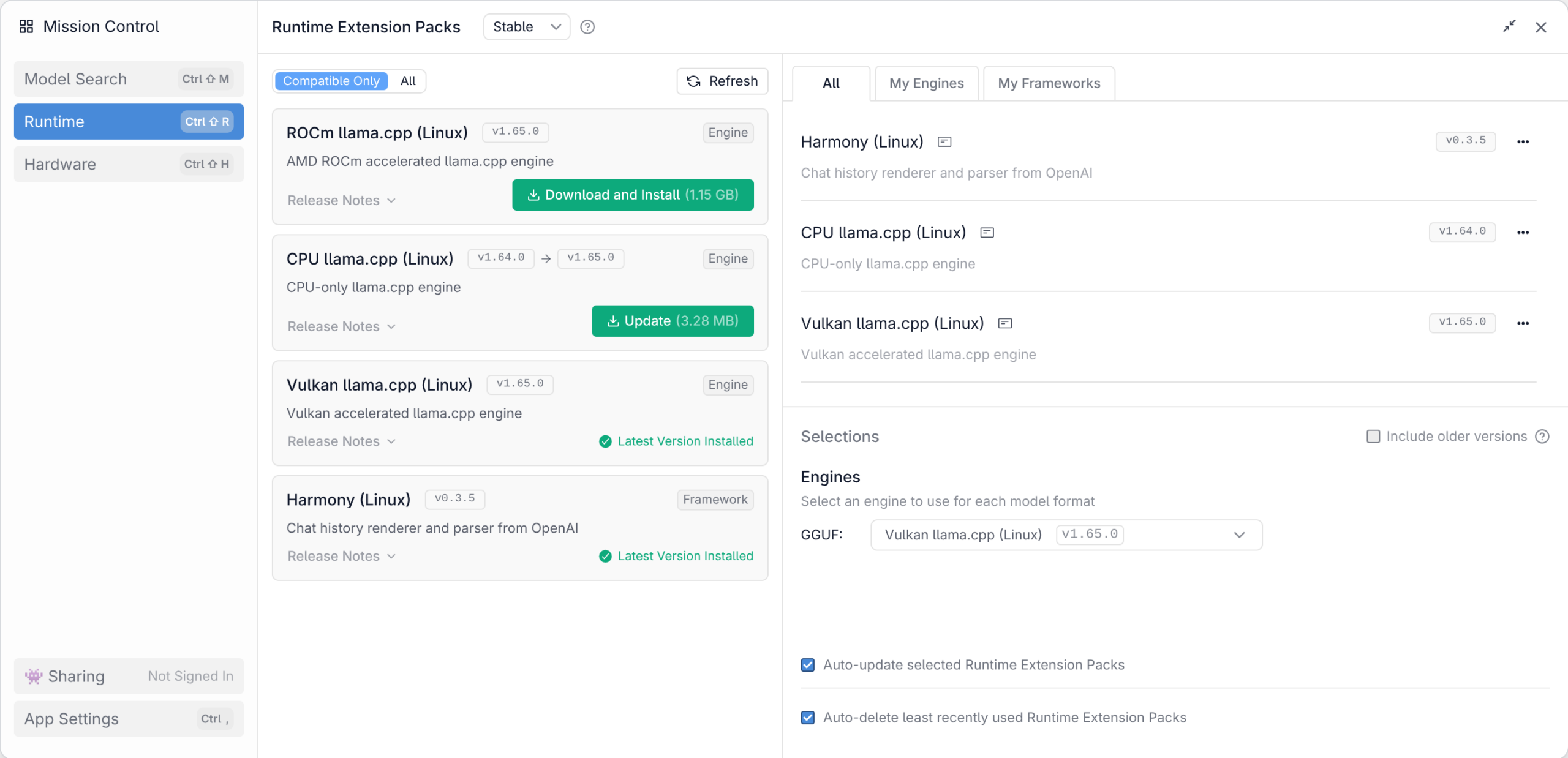
In der Ansicht Developer können Sie Logging-Ausgaben lesen. LM Studio verwendet wie Ollama und die meisten anderen KI-Oberflächen das Programm llama.cpp zur Ausführung der lokalen Modelle. Allerdings gibt es von diesem Programm unterschiedliche Versionen für den CPU-Betrieb (langsam) sowie für diverse GPU-Bibliotheken.
In dieser Ansicht können Sie den in LM Studio integrierten REST-Server aktivieren. Damit können Sie z.B. mit eigenen Python-Programmen oder mit dem VS-Code-Plugin Continue Prompts an LM Studio senden und dessen Antwort verarbeiten. Standardmäßig kommt dabei der Port 1234 um Einsatz, wobei der Zugriff auf den lokalen Rechner limitiert ist. In den Server Settings können Sie davon abweichende Einstellungen vornehmen.
Auf meinem neuen Framework Desktop mit 128 GiB RAM habe ich nun diverse Modelle ausprobiert. Die folgende Tabelle zeigt die erzielte Output-Geschwindigkeit in Token/s. Beachten Sie, dass die Geschwindigkeit spürbar sinkt wenn viel Kontext im Spiel ist (größere Code-Dateien, längerer Chat-Verlauf).
Sprachmodell MoE Parameter Quant. Token/s
------------- ----- ---------- --------- --------
deepseek-r1-distill-qwen-14b nein 14 Mrd. Q4_K_S 22
devstral-small-2-2512 nein 25 Mrd. Q4_K_M 13
glm-4.5-air ja 110 Mrd. Q3_K_L 25
gpt-oss-20b ja 20 Mrd. MXFP4 65
gpt-oss-120b ja 120 Mrd. MXFP4 48
nouscoder-14b nein 14 Mrd. Q4_K_S 22
qwen3-30b-a3b ja 30 Mrd. Q4_K_M 70
qwen3-next-80b-83b ja 80 Mrd. Q4_K_XL 40
seed-oss-36b nein 36 Mrd. Q4_K_M 10
Normalerweise gilt: je größer das Sprachmodell, desto besser die Qualität, aber desto kleiner die Geschwindigkeit. Ein neuer Ansatz durchbricht dieses Muster. Bei Mixture of Expert-Modellen (MoE-LLMs) gibt es Parameterblöcke für bestimmte Aufgaben. Bei der Berechnung der Ergebnis-Token entscheidet das Modell, welche »Experten« für den jeweiligen Denkschritt am besten geeignet sind, und berücksichtigt nur deren Parameter.
Ein populäres Beispiel ist das freie Modell GPT-OSS-120B. Es umfasst 117 Milliarden Parameter, die in 36 Ebenen (Layer) zu je 128 Experten organisiert sind. Bei der Berechnung jedes Output Tokens sind in jeder Ebene immer nur vier Experten aktiv. Laut der Modelldokumentation sind bei der Token Generation immer nur maximal 5,1 Milliarden Parameter aktiv. Das beschleunigt die Token Generation um mehr als das zwanzigfache:
Welches ist nun das beste Modell? Auf meinem Rechner habe ich mit dem gerade erwähnten Modell GPT-OSS-120B sehr gute Erfahrungen gemacht. Für Coding-Aufgaben funktionieren auch qwen3-next-80b-83b und glm-4.5-air gut, wobei letzteres für den praktischen Einsatz schon ziemlich langsam ist.
Mozilla hat Firefox 147.0.2 veröffentlicht und behebt damit mehrere Probleme der Vorgängerversion. Auch Sicherheitslücken wurden behoben.
Download Mozilla Firefox 147.0.2
Mozilla hat Firefox 147.0.2 für Windows, macOS und Linux veröffentlicht und behebt damit mehrere Sicherheitslücken, diverse potenzielle Absturzursachen sowie mehrere Webkompatibilitätsprobleme, darunter eines, welches unerwartete WebAuthn-Anfragen verursachen konnte.
Websites konnten vom Safe Browsing-Schutz unter Umständen fälschlicherweise als schädlich erkannt werden.
Mehrere Probleme wurden auch in Zusammenhang mit der Unterstützung für die XDG Base Directory-Spezifikation unter Linux behoben.
Außerdem zeigten Zertifikats-Fehlerseiten in manchen Fällen den Port doppelt an.
Der Beitrag Mozilla veröffentlicht Sicherheits-Update Firefox 147.0.2 erschien zuerst auf soeren-hentzschel.at.