Ubuntu Pro ist eine Updateerweiterung für bestimmte Pakete der bekannten Distribution.
Ubuntu LTS soll so 10 Jahre Abdeckung für über 25.000 Pakete erhalten. Zusätzlich erhältst du Kernel Livepatching, Telefonsupport und Pakete fürs Hardening (NIST-certified FIPS crypto-modules, USG hardening mit CIS and DISA-STIG Profilen und Common Criteria EAL2).
Leider wird für dieses kostenpflichtige Produkt Werbung gemacht, auf dem Terminal und im Ubuntu Update Manager.
Sollte dich das stören, kannst du diese Meldungen mit wenigen Befehlen abschalten.
Alternativ kannst du dich auch einfach für Ubuntu Pro anmelden, denn der Zugang ist für Privatanwender für bis zu fünf Installationen umsonst.
Ubuntu Pro Nachrichten abschalten
sudo pro config set apt_news=false
Das Abschalten der APT News reicht nicht ganz aus, um dir die Werbeeinblendung zu ersparen.
Du musst zusätzlich eine Datei editieren und deren Inhalt auskommentieren
nano /etc/apt/apt.conf.d/20apt-esm-hook.conf
Ubuntu Advantage deaktivieren oder deinstallieren
Optional kannst du das Ubuntu Advantage Paket entfernen, bzw. die Expanded SecurityMaintenance (ESM) abschalten, wenn du magst.
Ubuntu Advantage war der Vorgänger von Ubuntu Pro
Dieses beinhaltet wie die Pro-Variante Kernel Livepatching, Unterstützung für Landscape oder Zugriff auf eine Wissensdatenbank. Alles Dinge, die für Privatanwender nur bedingt interessant sind.
Solltest du nun maximal verwirrt sein, was zu welchem Supportmodell gehört und wie es unterstützt wird, hier ein Vergleich von endoflifedate. Ubuntu Pro (Infra-Only) steht in der Tabelle für das alte Ubuntu Advantage.
Mit einem Dualstack-Proxy Internet-Protokolle verbinden beschrieb eine Möglichkeit, um von Hosts, welche ausschließlich über IPv6-Adressen verfügen, auf Ziele zugreifen zu können, die ausschließlich über IPv4-Adressen verfügen. In diesem Beitrag betrachte ich die andere Richtung.
Zu diesem Beitrag motiviert hat mich der Kommentar von Matthias. Er schreibt, dass er für den bei einem Cloud-Provider gehosteten Jenkins Build Server IPv4 deaktivieren wollte, um Kosten zu sparen. Dies war jedoch nicht möglich, da Kollegen aus einem Co-Workingspace nur mit IPv4 angebunden sind und den Zugriff verloren hätten.
Doch wie kann man nun ein IPv6-Netzwerk für ausschließlich IPv4-fähige Clients erreichbar machen, ohne für jeden Host eine IPv4-Adresse zu buchen? Dazu möchte ich euch anhand eines einfachen Beispiels eine mögliche Lösung präsentieren.
Vorkenntnisse
Um diesem Text folgen zu können, ist ein grundsätzliches Verständnis von DNS, dessen Resource Records (RR) und des HTTP-Host-Header-Felds erforderlich. Die Kenntnis der verlinkten Wikipedia-Artikel sollte hierfür ausreichend sein.
Umgebung
Zu diesem Proof of Concept gehören:
Ein Dualstack-Reverse-Proxy-Server (HAProxy) mit den DNS-RR:
haproxy.example.com. IN A 203.0.113.1
haproxy.example.com IN AAAA 2001:DB8::1
Zwei HTTP-Backend-Server mit den DNS-RR:
www1.example.com IN AAAA 2001:DB8::2
www2.example.com IN AAAA 2001:DB8::3
Zwei DNS-RR:
www1.example.com IN A 203.0.113.1
www2.example.com IN A 203.0.113.1
Ein Client mit einer IPv4-Adresse
Ich habe mich für HAProxy als Reverse-Proxy-Server entschieden, da dieser in allen Linux- und BSD-Distributionen verfügbar sein sollte und mir die HAProxy Maps gefallen, welche ich hier ebenfalls vorstellen möchte.
Der Versuchsaufbau kann wie folgt skizziert werden:
Ein Dualstack-Reverse-Proxy-Server (B) verbindet IPv4-Clients mit IPv6-Backend-Servern
HAProxy-Konfiguration
Für dieses Minimal-Beispiel besteht die HAProxy-Konfiguration aus zwei Dateien, der HAProxy Map hosts.map und der Konfigurationsdatei poc.cfg.
Eine HAProxy Map besteht aus zwei Spalten. In der ersten Spalte stehen die FQDNs, welche vom HTTP-Client aufgerufen werden können. In der zweiten Spalte steht der Name des Backends aus der HAProxy-Konfiguration, welcher bestimmt, an welche Backend-Server eine eingehende Anfrage weitergeleitet wird. In obigem Beispiel werden Anfragen nach www1.example.com an das Backend serversa und Anfragen nach www2.example.com an das Backend serversb weitergeleitet.
Die HAProxy Maps lassen sich unabhängig von der HAProxy-Konfigurations-Datei pflegen und bereitstellen. Map-Dateien werden in ein Elastic Binary Tree-Format geladen, so dass ein Wert aus einer Map-Datei mit Millionen von Elementen ohne spürbare Leistungseinbußen nachgeschlagen werden kann.
Die HAProxy-Konfigurations-Datei poc.cfg für dieses Minimal-Beispiel ist ähnlich simpel:
~]$ cat /etc/haproxy/conf.d/poc.cfg
frontend fe_main
bind :80
use_backend %[req.hdr(host),lower,map(/etc/haproxy/conf.d/hosts.map)]
backend serversa
server server1 2001:DB8::1:80
backend serversb
server server1 2001:DB8::2:80
In der ersten Zeile wird ein Frontend mit Namen fe_main definiert. Zeile 2 bindet Port 80 für den entsprechenden Prozess und Zeile 3 bestimmt, welches Backend für eingehende HTTP-Anfragen zu nutzen ist. Dazu wird der HTTP-Host-Header ausgewertet, falls notwendig, in Kleinbuchstaben umgewandelt. Mithilfe der Datei hosts.map wird nun ermittelt, welches Backend zu verwenden ist.
Die weiteren Zeilen definieren zwei Backends bestehend aus jeweils einem Server, welcher auf Port 80 Anfragen entgegennimmt. In diesem Beispiel sind nur Server mit IPv6-Adressen eingetragen. IPv4-Adressen sind selbstverständlich auch zulässig und beide Versionen können in einem Backend auch gemischt auftreten.
Kann eine HTTP-Anfrage nicht über die hosts.map aufgelöst werden, läuft die Anfrage in diesem Beispiel in einen Fehler. Für diesen Fall kann ein Standard-Backend definiert werden. Siehe hierzu den englischsprachigen Artikel Introduction to HAProxy Maps von Chad Lavoie.
Der Kommunikationsablauf im Überblick und im Detail
Der Kommunikationsablauf im Überblick
Von einem IPv4-Client aus benutze ich curl, um die Seite www1.example.com abzurufen:
~]$ curl -4 -v http://www1.example.com
* processing: http://www1.example.com
* Trying 203.0.113.1:80...
* Connected to www1.example.com (203.0.113.1) port 80
> GET / HTTP/1.1
> Host: www1.example.com
> User-Agent: curl/8.2.1
> Accept: */*
>
< HTTP/1.1 200 OK
< server: nginx/1.20.1
< date: Sat, 06 Jan 2024 18:44:22 GMT
< content-type: text/html
< content-length: 5909
< last-modified: Mon, 09 Aug 2021 11:43:42 GMT
< etag: "611114ee-1715"
< accept-ranges: bytes
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<title>Test Page for the HTTP Server on Red Hat Enterprise Linux</title>
Der FQDN www1.example.com wird mit der IPv4-Adresse 203.0.113.1 aufgelöst, welche dem Host haproxy.example.com gehört. Bei der Zeile Host: www1.example.com handelt es sich um den HTTP-Host-Header, welchen der HAProxy benötigt, um das richtige Backend auszuwählen.
Es ist zu sehen, dass wir eine Antwort von einem NGINX-HTTP-Server erhalten. Der HTML-Quelltext wurde gekürzt.
Damit ist es gelungen, von einem IPv4-Client eine Ressource abzurufen, die von einem IPv6-Server bereitgestellt wird.
Im Access-Log des Backend-Servers mit der IPv6-Adresse 2001:DB8::2 sieht man:
Die Anfrage erreicht den Backend-Server von der IPv6-Adresse des haproxy.example.com (2001:DB8::1). Die am Ende der Zeile zu sehende IPv4-Adresse (192.0.2.1) gehört dem IPv4-Client, von dem ich die Anfrage gesendet habe.
Gedanken zur Skalierung
In diesem Beispiel sind die Server www1.example.com und www2.example.com über ihre IPv6-Adressen direkt erreichbar. Nur die Client-Anfragen von IPv4-Clients laufen über den Reverse-Proxy. Wenn man es wünscht, kann man selbstverständlich sämtliche Anfragen (von IPv4- und IPv6-Clients) über den Reverse-Proxy laufen lassen.
In kleinen Umgebungen kann man einen Reverse-Proxy wie HAProxy zusammen mit Squid (vgl. Artikel Mit einem Dualstack-Proxy Internet-Protokolle verbinden) auf einem Host laufen lassen. Selbstverständlich kann man sie auch auf separate Hosts verteilen.
Hochverfügbarkeit lässt sich auch hier mit keepalived nachrüsten:
Die Internet-Protokolle IPv4 und IPv6 werden wohl noch eine ganze Zeit gemeinsam das Internet bestimmen und parallel existieren. Ich bin mir sogar sicher, dass ich das Ende von IPv4 nicht mehr miterleben werde. Dualstack-(Reverse)-Proxy-Server stellen eine solide und robuste Lösung dar, um beide Welten miteinander zu verbinden.
Sicher bleiben noch ausreichend Herausforderungen übrig. Ich denke da nur an Firewalls, Loadbalancer, NAT und Routing. Und es werden sich auch Fälle finden lassen, in denen Proxyserver nicht infrage kommen. Doch mit diesen Herausforderungen beschäftige ich mich dann in anderen Artikeln.
In drei Wochen beginnen die Chemnitzer Linux-Tage 2024 mit dem diesjährigen Motto „Zeichen setzen“. Am 16. und 17. März erwartet euch im Hörsaalgebäude an der Richenhainer Straße 90 ein vielfältiges Programm an Vorträgen und Workshops. Hier finden sich Vorträge für interessierte Neueinsteiger wie für alte Hasen.
So geht es am Samstag im Einsteigerforum beispielsweise um die Digitalisierung analoger Fotos, das Erstellen von Urlaubsvideos mit der Software OpenShot oder die Verschlüsselung von E-Mails. In der Rubrik „Schule“ gibt Arto Teräs einen Einblick in den Einsatz der Open-Source-Lösung Puavo an finnischen und deutschen Schulen. Zusätzlich stehen Vorträge aus den Bereichen Finanzen, Medien, Datensicherheit, KI oder Netzwerk auf dem Programm. Am Sonntag gibt das Organisationsteam der Chemnitzer Linux-Tage mit „make CLT“ Einblicke in die Planung und Strukturen der Veranstaltung selbst. In der Rubrik „Soft Skills” wird es um die Schätzung von Aufwänden oder notwendige Fähigkeiten von Software-Entwicklern gehen.
Eintrittskarten können online im Vorverkauf und an der Tageskasse erworben werden. Kinder bis 12 Jahren haben freien Eintritt.
Während viele Besucher bereits Stammgäste sind, werden auch neue Gesichter herzlich willkommen. Lasst euch gern von der hier herrschenden Atmosphäre voller Begeisterung für freie Software und Technik anstecken und begeistern.
Ich selbst freue mich, am Samstag um 10:00 Uhr in V6 den Vortrag mit dem obskuren Namen ::1 beisteuern zu dürfen. Update: Unverhofft kommt oft. Uns so freue ich mich am Sonntag um 10:00 Uhr in Raum V7 noch in einem zweiten Vortrag vertreten zu sein. Zusammen mit Michael Decker von der ASPICON GmbH erfahrt ihr, wie man „Mit Ansible Collections & Workflows gegen das Playbook-Chaos“ angehen kann.
Darüber hinaus beteilige ich mich als Sessionleiter für die folgenden drei Vorträge an der Veranstaltung:
So habe ich auf jeden Fall einen Platz im Raum sicher. ;-)
Wer ebenfalls helfen möchte, kann sich unter Mitmachen! informieren und melden.
Für mich ist dieses Jahr einiges im Programm dabei. Doch freue ich mich ebenso sehr auf ein Wiedersehen mit alten Bekannten aus der Gemeinschaft und darauf, neue Gesichter (Namen kann ich mir meist erst Jahre später merken) kennenzulernen.
Im Frontend ändert sich mein Blog nur noch marginal. Jedoch musste ich mich aufgrund von Änderungen im Sourcecode von WordPress für ein anderes Theme entscheiden. Zuvor hatte ich ein Theme von einem deutschen bekannten Entwicklerpaar gekauft, aber leider endet hier der Support doch recht schnell. Auch Bugfixes, welche ich einmal auf Github eingereicht hatte, wurden ... Weiterlesen
Die letzten Wochen habe ich mich ziemlich intensiv mit Home Assistant auseinandergesetzt. Dabei handelt es sich um eine Open-Source-Software zur Smart-Home-Steuerung. Home Assistant (HA) ist eine spezielle Linux-Distribution, die häufig auf einem Raspberry Pi ausgeführt wird. Dieser Artikel zeigt die nicht ganz unkomplizierte Integration meines Fronius Wechselrichters in das Home-Assistant-Setup. (Die Basisinstallation von HA setze ich voraus.)
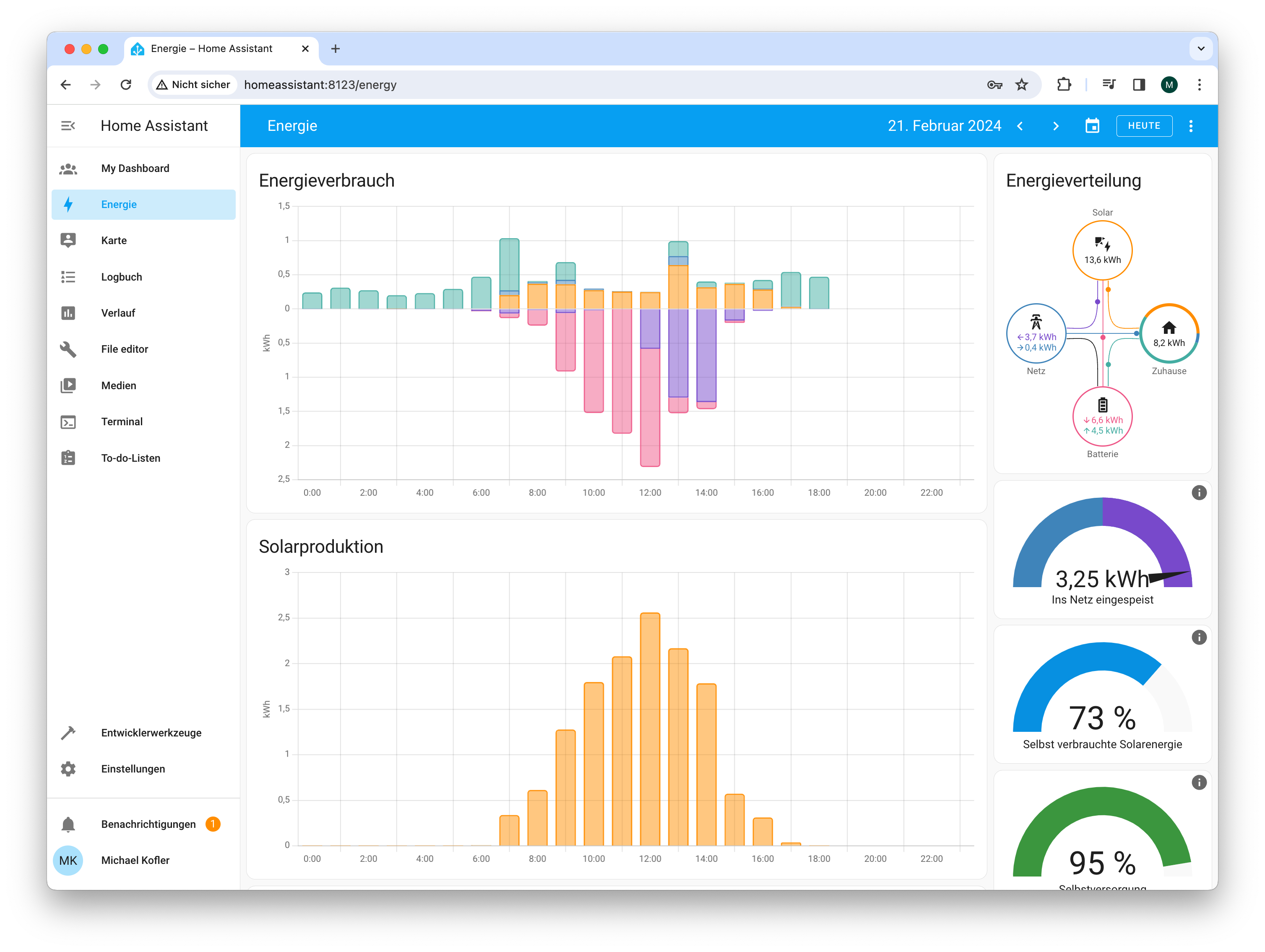
Die Energieansicht nach der erfolgreichen Integration des Fronius Wechselrichters.
Die Abbildung ist wie folgt zu interpretieren: Heute bis 19:00 wurden im Haushalt 8,2 kWh elektrische Energie verbraucht, aber 13,6 kWh el. Energie produziert (siehe die Kreise rechts). 3,7 kWh wurden in das Netz eingespeist, 0,4 kWh von dort bezogen.
Das Diagramm »Energieverbrauch« (also das Balkendiagramm oben): In den Morgen- und Abendstunden hat der Haushalt Strom aus der Batterie bezogen (grün); am Vormittag wurde der Speicher wieder komplett aufgeladen (rot). Am Nachmittag wurde Strom in das Netz eingespeist (violett). PV-Strom, der direkt verbraucht wird, ist gelb gekennzeichnet.
Fronius-Integration
Bevor Sie mit der Integration des Fronius-Wechselrichters in das HA-Setup beginnen, sollten Sie sicherstellen, dass der Wechselrichter, eine fixe IP-Adresse im lokalen Netzwerk hat. Die erforderliche Einstellung nehmen Sie in der Weboberfläche Ihres WLAN-Routers vor.
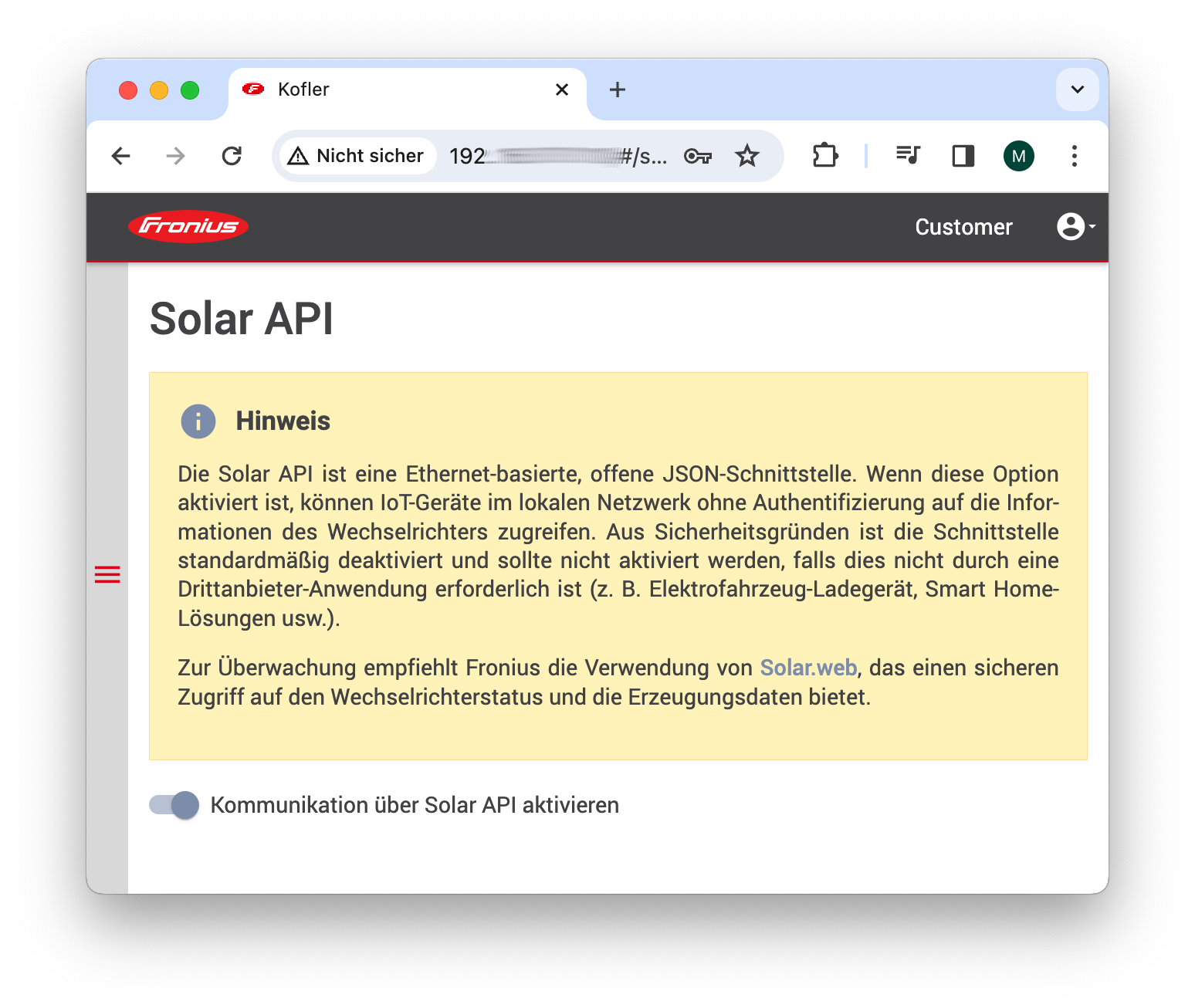
Außerdem müssen Sie beim Wechselrichter die sogenannte Solar API aktivieren. Über diese REST-API können diverse Daten des Wechselrichters gelesen werden. Zur Aktivierung müssen Sie sich im lokalen Netzwerk in der Weboberfläche des Wechselrichters anmelden. Die relevante Option finden Sie unter Kommunikation / Solar API. Der Dialog warnt vor der Aktivierung, weil die Schnittstelle nicht durch ein Passwort abgesichert ist. Allzugroß sollte die Gefahr nicht sein, weil der Zugang ohnedies nur im lokalen Netzwerk möglich ist und weil die Schnittstelle ausschließlich Lesezugriffe vorsieht. Sie können den Wechselrichter über die Solar API also nicht steuern.
Aktivierung der Solar API in der lokalen Weboberfläche des Fronius-Wechselrichters
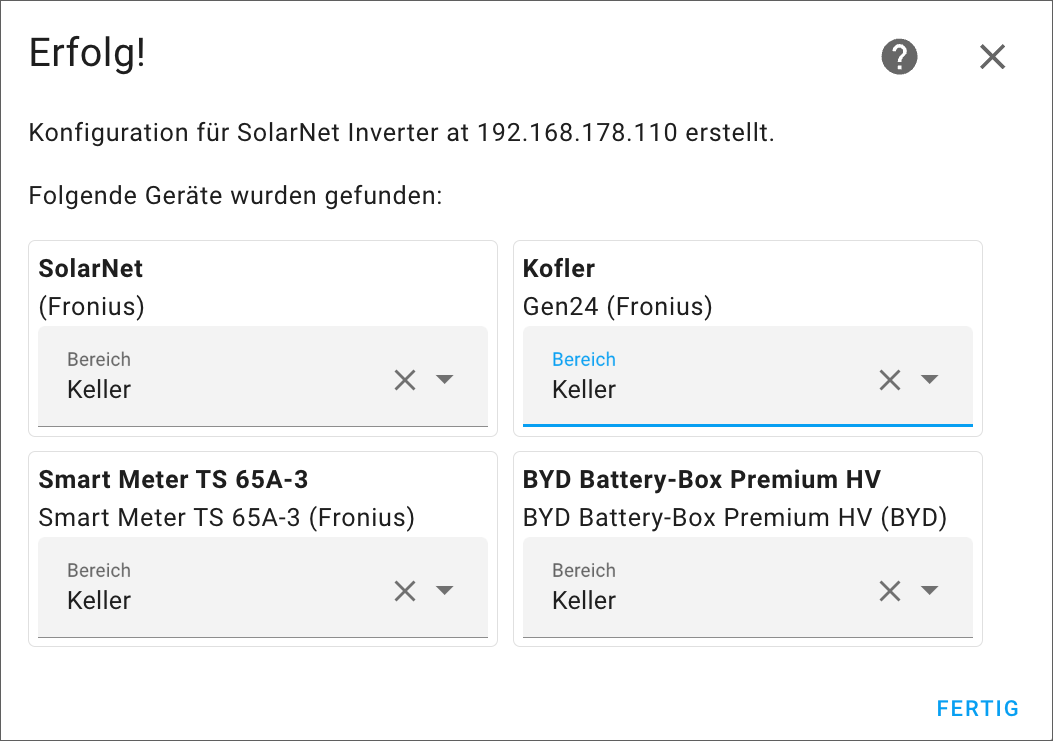
Als nächstes öffnen Sie in der HA-Weboberfläche die Seite Einstellungen / Geräte & Dienste und suchen dort nach der Integration Fronius (siehe auch hier). Im ersten Setup-Dialog müssen Sie lediglich die IP-Adresse des Wechselrichters angeben. Im zweiten Dialog werden alle erkannten Komponenten aufgelistet und Sie können diese einem Bereich zuordnen.
Setup der Fronius-Integration in der Weboberfläche von Home Assistant
Bei meinen Tests standen anschließend über 60 neue Entitäten (Sensoren) für alle erdenklichen Betriebswerte des Wechselrichters, des damit verbundenen Smartmeters sowie des Stromspeichers zur Auswahl. Viele davon werden automatisch im Default-Dashboard angezeigt und machen dieses vollkommen unübersichtlich.
Energieansicht
Der Zweck der Fronius-Integration ist weniger die Anzeige diverser einzelner Betriebswerte. Vielmehr sollen die Energieflüssen in einer eigenen Energieansicht dargestellt werden. Diese Ansicht wertet die Wechselrichterdaten aus und fasst zusammen, welche Energiemengen im Verlauf eines Tags, einer Woche oder eines Monats wohin fließen. Die Ansicht differenziert zwischen dem Energiebezug aus dem Netz bzw. aus den PV-Modulen und berücksichtigt bei richtiger Konfiguration auch den Stromfluss in den bzw. aus dem integrierten Stromspeicher. Sofern Sie eine Gasheizung mit Mengenmessung verfügen, können Sie auch diese in die Energieansicht integrieren.
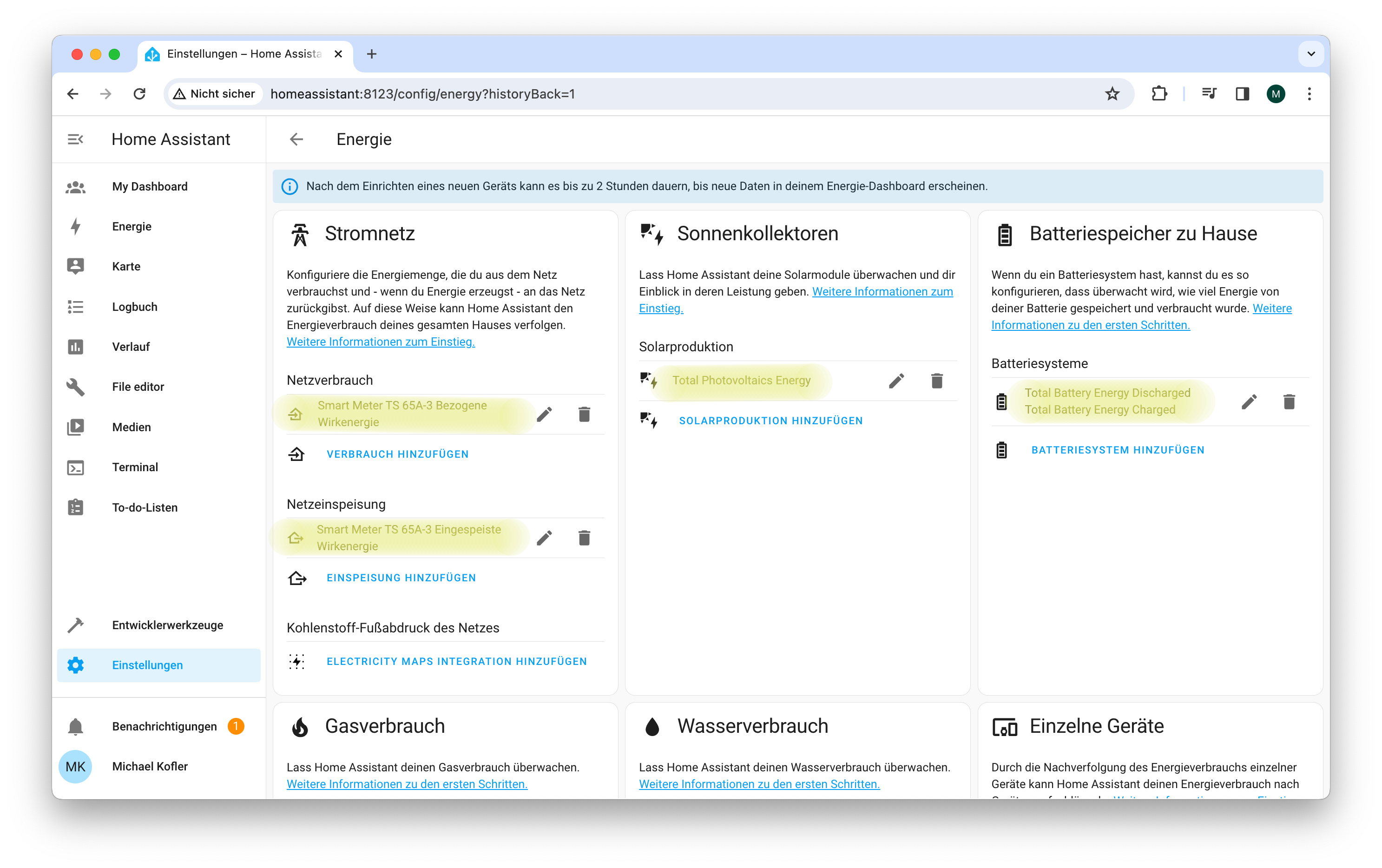
Die Konfiguration der Energieansicht hat sich aber als ausgesprochen schwierig erwiesen. Auf Anhieb gelang nur das Setup des Moduls Stromnetz. Damit zeigt die Energieansicht nur an, wie viel Strom Sie aus dem Netz beziehen bzw. welche Mengen Sie dort einspeisen. Die Fronius-Integration stellt die dafür Daten in Form zweier Sensoren direkt zur Verfügung:
Aus dem Netz bezogene Energie: sensor.smart_meter_ts_65a_3_bezogene_wirkenergie
In das Netz eingespeiste Energie: sensor.smart_meter_ts_65a_3_eingespeiste_wirkenergie
Je nachdem, welchen Wechselrichter und welche dazu passende Integration Sie verwenden, werden die Sensoren bei Ihnen andere Namen haben. In den Auswahllisten zur Stromnetz-Konfiguration können Sie nur Sensoren
auswählen, die Energie ausdrücken. Zulässige Einheiten für derartige Sensoren sind unter anderem Wh (Wattstunden), kWh oder MWh.
Konfiguration der Energie-Ansicht in Home Assistant
Code zur Bildung von drei Riemann-Integralen
Eine ebenso einfache Konfiguration der Module Sonnenkollektoren und Batteriespeicher zu Hause scheitert daran, dass die Fronius-Integration zwar aktuelle Leistungswerte für die Produktion durch die PV-Module und den Stromfluss in den bzw. aus dem Wechselrichter zur Verfügung stellt (Einheit jeweils Watt), dass es aber keine kumulierten Werte gibt, welche Energiemengen seit dem Einschalten der Anlage geflossen sind (Einheit Wattstunden oder Kilowattstunden). Im Internet gibt es eine Anleitung, wie dieses Problem behoben werden kann:
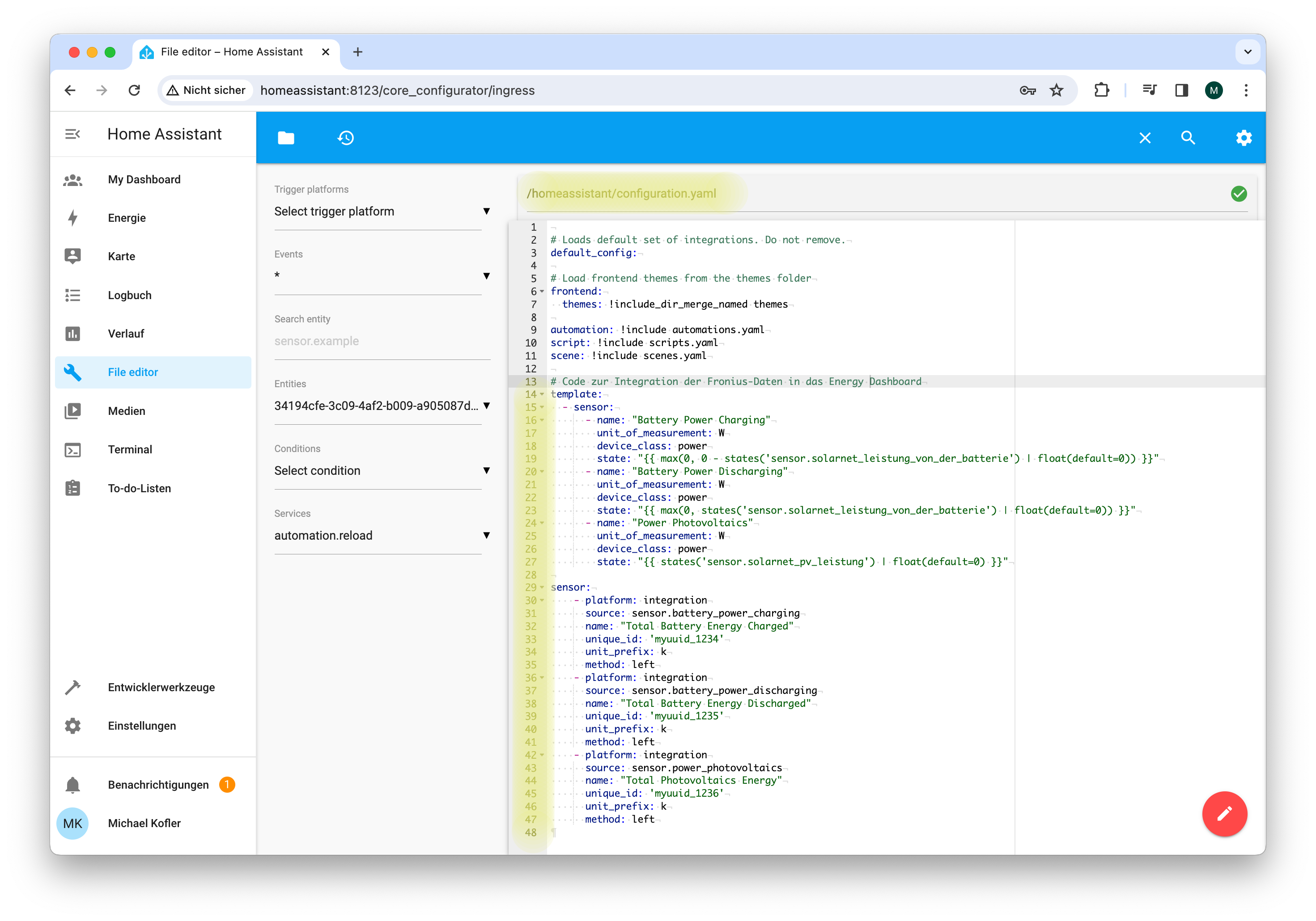
Die Grundidee besteht darin, dass Sie eigenen Code in eine YAML-Konfigurationsdatei von Home Assistant einbauen. Gemäß dieser Anweisungen werden mit einem sogenannten Riemann-Integral die Leistungsdaten in Energiemengen umrechnet. Dabei wird regelmäßig die gerade aktuelle Leistung mit der zuletzt vergangenen Zeitspanne multipliziert. Diese Produkte (Energiemengen) werden summiert (method: left). Das Ergebnis sind drei neue Sensoren (Entitäten), deren Name sich aus den title-Attributen im zweiten Teil des Listings ergeben:
Die Umsetzung der Anleitung hat sich insofern schwierig erwiesen, als die in der ersten Hälfte des Listungs verwendeten Sensoren aus der Fronius-Integration bei meiner Anlage ganz andere Namen hatten als in der Anleitung. Unter den ca. 60 Sensoren war es nicht ganz leicht, die richtigen Namen herauszufinden. Wichtig ist auch die Einstellung device_class: power! Die in einigen Internet-Anleitungen enthaltene Zeile device_class: energy ist falsch.
Der template-Teil des Listings ist notwendig, weil der Sensor solarnet_leistung_von_der_batterie je nach Vorzeichen die Lade- bzw. Entladeleistung enthält und daher getrennt summiert werden muss. Außerdem kommt es vor, dass die Fronius-Integration einzelne Werte gar nicht übermittelt, wenn sie gerade 0 sind (daher die Angabe eines Default-Werts).
Der zweite Teil des Listungs führt die Summenberechnung durch (method: left) und skaliert die Ergebnisse um den Faktor 1000. Aus 1000 Wh wird mit unit_prefix: k also 1 kWh.
Bevor Sie den Code in configuration.yaml einbauen können, müssen Sie einen Editor als Add-on installieren (Einstellungen / Add-ons, Add-on-Store öffnen, dort den File editor auswählen).
# in die Datei /homeassistant/configuration.yaml einbauen
...
template:
- sensor:
- name: "Battery Power Charging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, 0 - states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Battery Power Discharging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Power Photovoltaics"
unit_of_measurement: W
device_class: power
state: "{{ states('sensor.solarnet_pv_leistung') | float(default=0) }}"
sensor:
- platform: integration
source: sensor.battery_power_charging
name: "Total Battery Energy Charged"
unique_id: 'myuuid_1234'
unit_prefix: k
method: left
- platform: integration
source: sensor.battery_power_discharging
name: "Total Battery Energy Discharged"
unique_id: 'myuuid_1235'
unit_prefix: k
method: left
- platform: integration
source: sensor.power_photovoltaics
name: "Total Photovoltaics Energy"
unique_id: 'myuuid_1236'
unit_prefix: k
method: left
In »configuration.yaml« müssen etliche Zeilen zusätzlicher Code eingebaut werden.
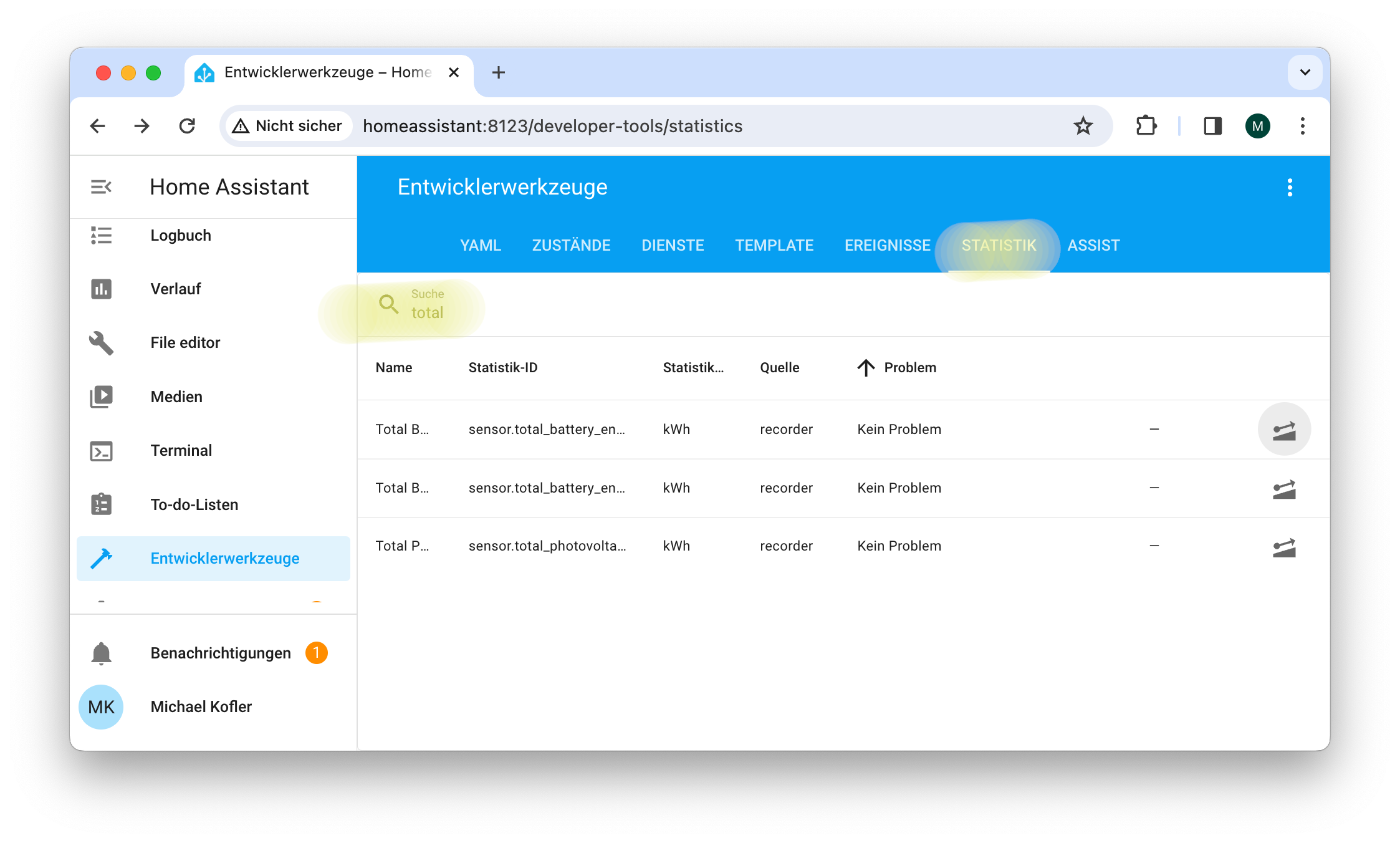
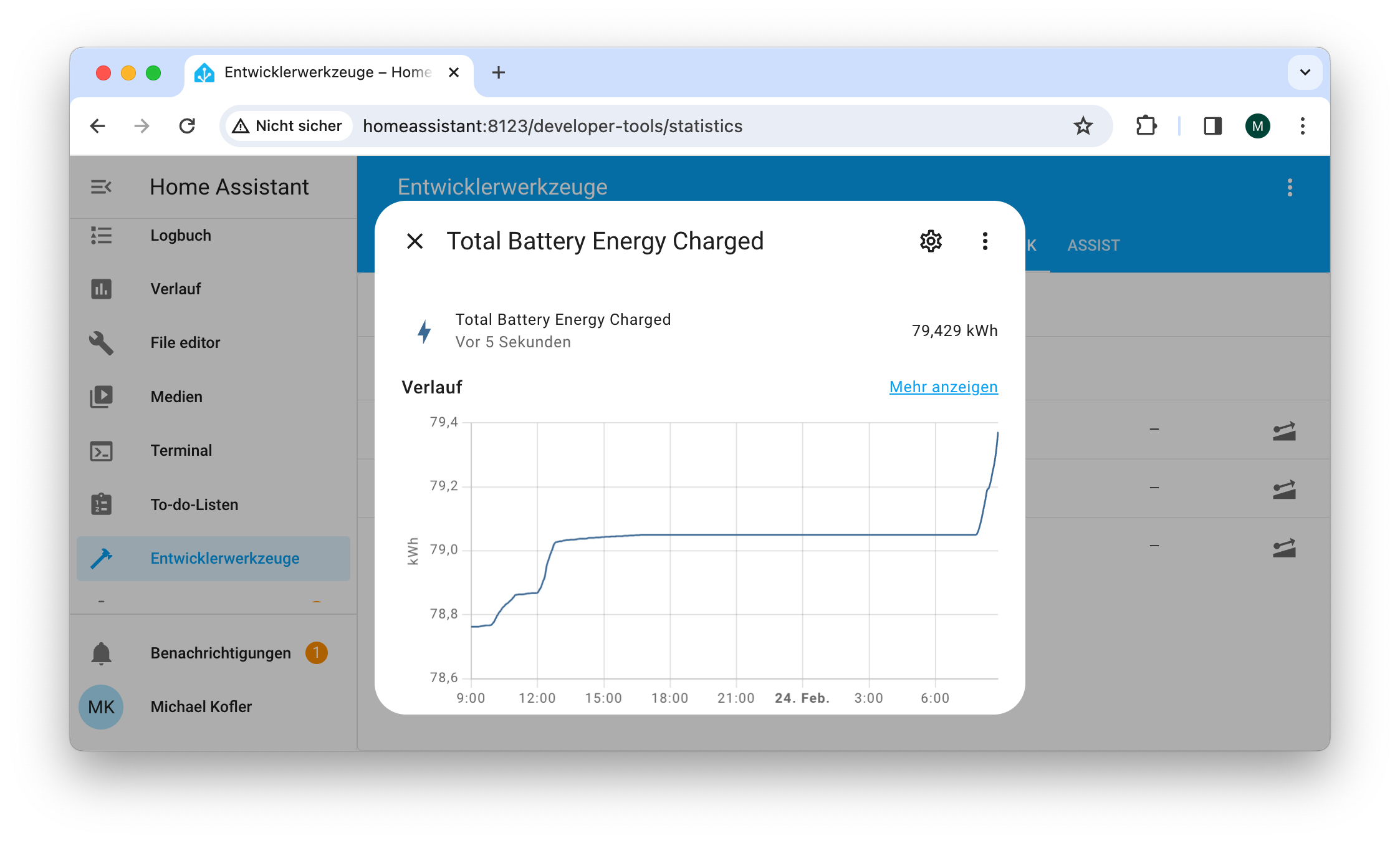
Damit die neuen Einstellungen wirksam werden, starten Sie den Home Assistant im Dialogblatt Einstellungen / System neu. Anschließend sollte es möglich sein, auch die Module Sonnenkollektoren und Batteriespeicher zu Hause richtig zu konfigurieren. (Bei meinen Experimenten hat es einen ganzen Tag gedauert hat, bis endlich alles zufriedenstellend funktionierte. Zwischenzeitlich habe ich zur Fehlersuche Einstellungen / System / Protokolle genutzt und musste unter Entwicklerwerkzeuge / Statistik zuvor aufgezeichnete Daten von falsch konfigurierten Sensoren wieder löschen.) Der Lohn dieser Art zeigt sich im Bild aus der Artikeleinleitung.
Unter Entwicklerwerkzeuge/Statistik können Sie sich vergewissern, dass die neuen Sensoren korrekt eingerichtet sind.Wenn ein Sensor angeklickt wird, erscheint eine Verlaufskurve.
Ich habe nun das nächste Plugin aus WordPress entfernt. Auch habe ich mir nochmals Gedanken über dieses Plugin gemacht und es ist definitiv nicht Datenschutz konform, wenn ich Daten aus Github nachgeladen habe. Ich hatte zwar somit immer die neueste Version des Codes eingebunden, aber es war eigentlich eine Faulheit auf Kosten der Lesenden. Im ... Weiterlesen
Am 16. und 17. März 2024 werde ich euch auf den Chemnitzer Linux-Tagen um 10:00 Uhr in Raum V6 mit einem Vortrag über IPv6 unterhalten.
Dazu bin ich noch auf der Suche nach ein paar Beispielen aus dem echten Leben. Falls ihr mögt, teilt mir doch eure schönsten und schlimmsten Momente im Zusammenhang mit IPv6 mit und ich prüfe, ob ich sie in meinen Vortrag mit einbauen kann.
Wann und wie hat IPv6 euren Tag gerettet?
Wieso hat euch das Protokoll Alpträume beschehrt?
Was funktioniert wider Erwarten immer noch nicht mit IPv6?
Habt ihr lustige Geschichten, die ihr (anonym) mit der Welt teilen möchtet?
Ich freue mich über Einsendungen, Beiträge und Rückmeldungen:
Bitte schreibt dazu, ob ihr eine Namensnennung wünscht oder euer Beispiel anonym einfließen soll.
Um einen runden Vortrag zu erstellen, wird evtl. nicht jeder Beitrag einfließen können. Bitte habt Verständnis dafür und verzeiht, wenn ihr euch nicht im Vortrag wiederfindet. Ich werde eure Geschichten ggf. im Nachgang hier im Blog veröffentlichen.
Nachdem unsere Community-Cloud das vorab letzte Software-Upgrade und eine neue SSD erhalten hatte, wurde es nun Zeit auch die Hardware auf eine neue Stufe zu heben. Da wir der Meinung waren, dass hierzu ein Raspberry P4 4 Modell B mit 8GB völlig ausreicht, haben wir uns bewusst für dieses Gerät entschieden. Eingepackt in ein passiv gekühltes Metallgehäuse wird uns diese Kombination, so hoffe ich, die nächste Zeit zuverlässig begleiten.
Da ein Upgrade der installierten Software vom Raspberry Pi 3 auf den Raspberry Pi 4 wenig sinnvoll und auch fast unmöglich umzusetzen ist, war die Idee, die Datenbank und das Datenverzeichnis der Nextcloud in eine Neuinstallation (64-Bit) einzubinden.
Für den Wechsel auf 64-Bit hätte eigentlich parallel zum bestehenden System eine Neuinstallation auf dem erwähnten Raspberry Pi durchgeführt werden müssen. Hier konnte ich mir die Arbeit aber ein wenig erleichtern, indem ich die MicroSD meiner eigenen Cloud klonen konnte. Auf dem geklonten System waren so nur einige Anpassungen vorzunehmen, bevor das neue Gerät an Stelle des 32-Bit-Systems in Betrieb genommen werden konnte.
Aufnahme mit Wärmebildkamera (Raspberry Pi 4 – passive Kühlung)
Die aus dem Raspberry Pi 3 gesicherte Datenbank wurde in den Raspberry Pi 4 eingelesen und die Daten-SSD in die /etc/fstab eingebunden. Danach wurde der ddclient mit der DynDNS neu konfiguriert. Ein neues Zertifikat wurde erstellt und die automatische Upgrade-Routine hierzu angepasst. Zum Schluss mussten nur noch die Ports im Speedport-Router für die neue Hardware freigegeben werden.
Fazit
Der Aufwand hat sich in dem Sinne gelohnt, da dieses nun mittlerweile über fünfeinhalb Jahre existierende Projekt, zukunftssicher weiterbetrieben werden kann.
Nachdem nun unsere Community-Cloud endlich wieder lief, habe ich versucht innerhalb der Gemeinschaft unseren Cloud-Speicher etwas zu bewerben. Bei einigen Nutzern war dieser inzwischen etwas in Vergessenheit geraten, samt den nötigen Passwörtern.
Es kommt natürlich immer wieder vor, dass Zugangsdaten nicht richtig verwahrt werden oder gar ganze Passwörter nicht mehr auffindbar sind. Mehrfache fehlerhafte Eingaben können jedoch, wie im Fall der Nextcloud, dazu führen, dass Nutzer-IPs ausgesperrt bzw. blockiert werden. Diesen Schutz nennt man Bruteforce-Schutz.
Bruteforce-Schutz
Nextcloud bietet einen eingebauten Schutzmechanismus gegen Bruteforce-Angriffe, der dazu dient, das System vor potenziellen Angreifern zu sichern, die wiederholt verschiedene Passwörter ausprobieren. Diese Sicherheitsvorkehrung ist standardmäßig in Nextcloud aktiviert und trägt dazu bei, die Integrität der Daten zu wahren und unautorisierten Zugriff auf das System zu verhindern.
Wie es funktioniert
Die Funktionsweise des Bruteforce-Schutzes wird besonders deutlich, wenn man versucht, sich auf der Anmeldeseite mit einem ungültigen Benutzernamen und/oder Passwort anzumelden. Bei den ersten Versuchen mag es unauffällig erscheinen, doch nach mehreren wiederholten Fehlversuchen wird man feststellen, dass die Überprüfung des Logins mit zunehmender Häufigkeit länger dauert. An dieser Stelle tritt der Bruteforce-Schutz in Kraft, der eine maximale Verzögerung von 25 Sekunden für jeden Anmeldeversuch einführt. Nach erfolgreicher Anmeldung werden sämtliche fehlgeschlagenen Versuche automatisch gelöscht. Wichtig zu erwähnen ist, dass ein ordnungsgemäß authentifizierter Benutzer von dieser Verzögerung nicht mehr beeinträchtigt wird, was die Sicherheit des Systems und die Benutzerfreundlichkeit gleichermaßen gewährleistet.
Bruteforce-Schutz kurzzeitig aushebeln
Hat nun einmal die Falle zugeschnappt und ein Anwender wurde aus der Nextcloud ausgesperrt, so kann sich das Problem über die Zeit von selbst lösen. Es gibt aber auch die Möglichkeit die Datenbank entsprechend zurückzusetzen.
Zuerst wechselt man in das Nextcloud-Verzeichnis. Danach werden über den folgenden OCC-Befehl die Bruteforce-Einträge der Datenbank resetet.
cd /var/www/html/nextcloud/
sudo -u www-data php occ security:bruteforce:reset 0.0.0.0
Neue Bruteforce-Attacken werden natürlich danach wieder geloggt und verdächtige IPs ausgesperrt.
Des Öfteren erinnere ich Kollegen daran, doch bitte bei Upgrades in einer Remoteshell mit einem terminal mutliplexer zu arbeiten. Falls doch einmal die Verbindung abbricht, nicht ein halb installiertes, oder konfiguriertes Paket vorliegt. Das kann viel und sehr unangenehme Arbeit auslösen. Man glaubt es kaum, den Fakt habe ich bei meiner Firewall in meinem Homeoffice ... Weiterlesen
Das soziale Netzwerk Mastodon hat mit seinem web- und mobilen Anwendungen für mich einen wunderbaren Standard in das Leben gerufen und sogleich in dem Netzwerk etabliert. Die ausführliche Bildbeschreibung. Die Beschreibung wird, unterstützt durch künstliche Intelligenz, per Knopfdruck als ein Text generiert. Der Text wird nun noch an die eigenen Wünsche angepasst. Damit beschreibt der ... Weiterlesen
WP-Appbox ist ein wunderbares Plugin, welches vielfältige Darstellungsmöglichkeiten für die Verlinkung verschiedener Apps bietet. Das Plugin war bei mir seit 2013 in Benutzung. Ich habe es erstmals bei dem Blogbeitrag Ownstagram ein eigenes Instagram verwendet. Das Plugin bindet verschiedene Stores anhand eines Shortcodes ein und zieht sich hier die gewünschten Daten aus dem Shop. Ein ... Weiterlesen
Ich habe nun meine Bannermeldung nach dem Telekommunikation-Telemedien-Datenschutz-Gesetz (TTDSG) abgeschaltet. Siehe hierzu auch das Urteil des Bundesgerichtshofs vom 28. Mai 2020, Aktenzeichen I ZR 7/16.Ich betrieb meine Installation von Matomo schon so, dass seitens Matomo keine Cookies gesetzt wurden. Durch das Abschalten der Kommentarefunktion in WordPress konnten auch hier auf Cookies verzichtet werden. Den letzten Teil ... Weiterlesen
Nach über 14 Jahren Gebrauch ist WordPress eine Art von Hassliebe. Es ist nicht so, dass ich nicht andere Plattform für das Schreiben im Netz ausprobiert hatte. Ich startete mit WordPress, besuchte Drupal,Octopress und Serendpity, um am Ende doch wieder bei WordPress zu landen. Somit sitze ich im Moment vor meinem, doch in die Jahre ... Weiterlesen
Ich habe mich nach einer kleinen Testphase gegen GitKraken und für Fork als grafischen Client für Git unter macOS entschieden.Gitkraken mag ein hervorragendes Werkzeug sein, aber das Abomodell hat mich abgeschreckt. Ich möchte noch erwähnen, dass GitKraken ein Studenten- und Universitätspaket anbietet. Ich werde vielleicht GitKraken Kollegen:innen an meinem Arbeitsplatz für einen Test vorschlagen. Dann ... Weiterlesen
Linux und Open Source Anwendungen für Autoren - Schriftsteller benutzen für die Erstellung von Romanen Autorenpgrogramme. Autorenprogramme sind spezielle Schreibprogramme für Autoren und Schriftsteller. Für Linux ist die Auswahl derartiger Anwendungen leider begrenzt. Manuskript ist Open Source und läuft unter Linux (Debian, Ubunrtu, Fedora, Snap, Flatpak), Windows und auch MacOS. Da es zudem kostenfrei ist, stellt es eine Alternative für angehende Autoren dar , die auch einmal ein Autorenpgrogramm ausprobierten möchten und keine herkömmliche Textverarbeitung wie Libre Office oder Word nutzen wollen.
Im Video zeige ich die wesentlichen Unterschiede zu einer reinen Textverarbeitung und die wesentlichen Funktionsmerkmale von Manuskript.
🖋️ Entdecke mit mir das leistungsstarke Autorenprogramm Manuskript und erfahre, wie du in Linux deine Schreibprojekte optimal umsetzen kannst! In diesem umfassenden YouTube-Video nehme ich das Manuskript Autorenprogramm genau unter die Lupe und biete dir wertvolle Anwendungstipps für Linux-Nutzer, die aber in Windows und MacOS umgesetzt werden können.
📘 Mit Manuskript hast du nicht nur ein einfaches Schreibwerkzeug, sondern auch ein vielseitiges Programm, das speziell für Autoren entwickelt wurde. Tauche ein in die Funktionen, die das Programm bietet, und lerne, wie du es effektiv in deinem Linux-Betriebssystem nutzen kannst.
🚀 In diesem Tutorial erfährst du:
Die grundlegenden Funktionen von Manuskript und warum es ein Must-Have für Autoren ist
Spezifische Anwendungsmöglichkeiten von Manuskript in Linux
Tipps und Tricks für die effiziente Nutzung des Autorenprogramms
Integration von Manuskript in deinen Schreibworkflow unter Linux
Fortschrittliche Funktionen und individuelle Anpassungsmöglichkeiten
🔍 Verbessere deine Schreiberfahrung und suche nach "Manuskript Autorenprogramm Linux Tutorial", "Effektives Schreiben in Linux", oder "Autorensoftware für Linux" – und entdecke unser informatives Video, das dir dabei hilft, das Beste aus Manuskript herauszuholen. Vergiss nicht, unseren Kanal zu abonnieren, um über weitere Tipps und Tutorials auf dem Laufenden zu bleiben!
Link zur Webseite von Manuskript: https://www.theologeek.ch/manuskript/download/
Linux Bücher für Einsteiger von mir (Ebook und Taschenbuch):
▶️ https://www.amazon.de/~/e/B001K73R84
Brandneu: Linux Mint 21 - Schnellanleitung für Einsteiger
▶️ https://www.amazon.de/dp/B0BB9LGMPG
Weitere Videos zu Linux Distributionen findet Ihr in dieser Playlist:
▶️ https://www.youtube.com/watch?v=sdYcdG4mn98&list=PLl0zRfPkQ7Xu86XQgKbUhVRSBbHpUzxxM
Andere Kanäle von mir:
Joe loves Linux ▶️ https://www.youtube.com/channel/UCdI8plWGpNHwN1oswHi3iWA
Raketenheftleser ▶️ https://www.youtube.com/channel/UCyPNZr7yK8278QXQDMFnQag
Joe's Musik Check ▶️ https://www.youtube.com/channel/UCuB7gdAs73msDRUnlRRKv5Q
JJ Fotoshow ▶️ https://www.youtube.com/c/JoeTravels
BookStack ist eine einfache Wiki-Software die leicht zu bedienen ist. Du kannst deine Informationen in Büchern mit Seiten ablegen und diese Bücher in Regale einordnen.
Mit Wallabag könnt ihr interessante Artikel ablegen und einfach später lesen.
BookStack ist eine einfache Wiki-Software die leicht zu bedienen ist. Du kannst deine Informationen in Büchern mit Seiten ablegen und diese Bücher in Regale einordnen.
Bequemes Lesen: Wallabag extrahiert den Inhalt des Artikels (und nur den Inhalt!) und zeigt ihn in einer komfortablen Ansicht an
Migriere von anderen Diensten: Wenn bereits ein Konto bei Pocket, Readability, Instapaper oder Pinboard existiert, können die Daten in Wallabag importiert werden
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere ins unserem Chat mit.
Es gibt wieder neue Sicherheitslücken in glibc. Dabei betrifft eine die syslog()-Funktion, die andere qsort(). Letztere Lücke existiert dabei seit glibc 1.04 und somit seit 1992. Entdeckt und beschrieben wurden die Lücken von der Threat Research Unit bei Qualys.
Die syslog-Lücke ist ab Version 2.37 seit 2022 enthalten und betrifft somit die eher die neuen Versionen von Linux-Distributionen wie Debian ab Version 12 oder Fedora ab Version 37. Hierbei handelt es sich um einen "heap-based buffer overflow" in Verbindung mit argv[0]. Somit ist zwar der Anwendungsvektor schwieriger auszunutzen, weil in wenigen Szenarien dieses Argument (der Programmname) dem Nutzer direkt überlassen wird, die Auswirkungen sind jedoch umso schwerwiegender. Mit der Lücke wird eine lokale Privilegienausweitung möglich. Die Lücke wird unter den CVE-Nummern 2023-6246, 2023-6779 und 2023-6780 geführt.
Bei der qsort-Lücke ist eine Memory Corruption möglich, da Speichergrenzen an einer Stelle nicht überprüft werden. Hierfür sind allerdings bestimmte Voraussetzungen nötig: die Anwendung muss qsort() mit einer nicht-transitiven Vergleichsfunktion nutzen (die allerdings auch nicht POSIX- und ISO-C-konform wären) und über eine große Menge an zu sortierenden Elementen verfügen, die vom Angreifer bestimmt werden. Dabei kann ein malloc-Aufruf gestört werden, der dann zu weiteren Angriffen führen kann. Das Besondere an dieser Lücke ist ihr Alter, da sie bereits im September 1992 ihren Weg in eine der ersten glibc-Versionen fand.
Bei der GNU C-Bibliothek (glibc) handelt es sich um eine freie Implementierung der C-Standard-Bibliothek. Sie wird seit 1987 entwickelt und ist aktuell in Version 2.38 verfügbar. Morgen, am 1. Februar, erscheint Version 2.39.
Heute möchte ich noch einmal ein Thema aus der Mottenkiste holen, welches ja eigentlich schon abgehakt sein sollte. Es geht um das Upgrade von Raspbian 10 auf das Raspberry Pi OS 11.
Anlass des Ganzen ist unsere Community-Cloud mit über 25 Nutzern. Diese Cloud wurde vor über fünfeinhalb Jahren zum Zwecke des Datenteilens ins Leben gerufen. Durch einen bedingten öfteren Standortwechsel verblieb das System auf einem Softwarestand von vor über zwei Jahren. Jetzt im neuen Zuhause stand dadurch ein gründlicher Tapetenwechsel an. D.h., dass im ersten Schritt das Betriebssystem auf Raspberry Pi OS 11 Bullsleye angehoben werden musste, bevor die Nextcloud von Version 22 auf 27 aktualisiert wurde. Weiterhin musste parallel PHP 7.3 auf Version 8.1 gezogen werden, um wieder in sicheres Fahrwasser zu gelangen. Bei der Hardware handelt es sich um einen Raspberry Pi 3 Model B. Auch dieses Gerät soll im laufe des Jahres noch ein Refresh erhalten.
Nun zum Upgrade auf das erwähnte Raspberry Pi OS 11.
Installation
Hilfreich bei der Installation war die Anleitung von linuxnews.de, die ich abschließend noch um zwei Punkte ergänzen musste. Hierbei konnte ich mich noch an mein erstes Upgrade dieser Art erinnern, dass es zu Unverträglichkeiten mit dem Desktop kam. Dieses Problem wird ganz am Ende des Artikels behandelt.
Zuerst wurde ein vollständiges Upgrade auf die aktuellste Version Raspbian 10 durchgeführt.
Danach wurden unnötige Pakete und verbliebene heruntergeladene Pakete entfernt.
sudo apt autoremove
sudo apt clean
Nun mussten noch die Kernelbased Mode-Setting (KMS) in der /boot/config.txt angepasst werden. Hierzu wurden folgende zwei Befehle ausgeführt:
sudo sed -i 's/dtoverlay=vc4-fkms-v3d/#dtoverlay=vc4-fkms-v3d/g' /boot/config.txt
sudo sed -i 's/\[all\]/\[all\]\ndtoverlay=vc4-kms-v3d/' /boot/config.txt
Desktop aufräumen
Nach dem Reboot mit angeschlossenem Monitor fiel auf, dass sich das Programm Parcellite in der Menüleiste verewigt hatte. Parcellite war vor dem Systemupgrade auf Raspberry Pi OS 11 Bullseye nicht an Bord. Aus diesem Grund konnte es auch ohne Bedenken gelöscht werden.
sudo apt remove parcellite
Weiterhin fiel auf, dass die ganze Menüleiste des Desktops etwas vermurkst aussah. Diese wurde auf die Grundeinstellungen mit
cd ~/
sudo rm -rf .cache
zurückgesetzt.
Nach einem erneuten Reboot läuft Raspberry Pi OS 11 wie gewünscht.
sudo reboot
Nextcloud 27 – Raspberry Pi Modell B Rev 1.2Nextcloud 27 – PHP 8.1
Fazit
Um unsere Community-Cloud wieder sicher zu machen, war ein wenig Wochenendarbeit nötig. Die so investierte Zeit hat sich aber durchaus gelohnt. Im nächsten Schritt erfolgt dann der Tausch des Raspberry Pi und ein Wechsel der Daten-SSD gegen ein größeres Modell.
Ein MQTT-Broker ist die Schnittstelle zwischen vielen IoT-Sensoren und Geräten, die Sensordaten auswerten oder Aktoren steuern. Das MQTT-Protokoll ist offen und sehr weit verbreitet. Es findet in der Industrie Anwendungen, ist aber auch in Smart Homes ist MQTT weit verbreitet. MQTT ist ein sehr schlankes und schnelles Protokoll. Es wird in Anwendungen mit niedriger Bandbreite gerne angewendet.
MQTT funktioniert, grob gesagt, folgendermaßen: IoT-Geräte können Nachrichten versenden, die von anderen IoT-Geräten empfangen werden. Die Vermittlungsstelle ist ein sogenannter MQTT-Broker. Dieser empfängt die Nachrichten von den Clients. Gleichzeitig können diese Nachrichten von anderen Clients abonniert werden. Die Nachrichten werden in sog. Topics eingestuft, die hierarchisch angeordnet sind, z.B. Wohnzimmer/Klima/Luftfeuchtigkeit.
Home Assistant, oder ein anderer Client, kann diesen Topic abonnieren und den Nachrichteninhalt („Payload„) auswerten (z.B. 65%).
Home Assistant OS vs. Home Assistant Container
In Home Assistant OS und Supervisor gibt es ein Addon, das einen MQTT-Broker installiert. Das ist sehr einfach, komfortabel und funktioniert wohl recht zurverlässig. In den Installationsarten Home Assistant Container und Core gibt es diese Möglichkeit nicht. Hier muss man manuell einen MQTT-Broker aufsetzen.
In diesem Artikel beschäftige ich mich damit, wie man den MQTT-Brocker Mosquitto über Docker installiert. Anschließend zeige ich, wie man die Konfigurationsdatei gestaltet und eine Verbindung zu Home Assistant herstellt. Das Ergebnis ist dann ungefähr so, als hätte man das Addon installiert. Los gehts!
Schritt für Schritt: MQTT-Broker Mosquitto mit Docker installieren
Als MQTT-Broker verwende ich die weit verbreitete Software Mosquitto von Eclipse. Dieser wird auch von Home Assistant bevorzugt und ist derjenige Broker, den das Addon installieren würde. Für diese Anleitung wird vorausgesetzt, dass Docker bereits installiert ist und eine SSH-Verbindung zum Server hergestellt werden kann.
Schritt 1: Zunächst erstellen wir ein paar Ordner, die wir später benötigen. Mosquitto wird später so konfiguriert, dass in diese Ordner alle wichtigen Dateien abgelegt werden. Dadurch kann man auf dem Filesystem des Servers Mosquitto konfigurieren und beobachten.
-p 1883:1883 Der genannte Port ist die Standardeinstellung für MQTT. Alles was auf diesen Port am Server ankommt, wird in den Mosquitto-Container geleitet.
-p 9001:9001 Über diesen Port laufen die Websocket-Anwendungen. Falls das nicht benötigt wird, kann man das weg lassen
name mosquitto Über diesen kurzen Namen können wir den Docker-Container steuern
-v <filesystem-Pfad>:<Container-Pfad> Die in Schritt 1 erstellten Ordner werden in den Container eingebunden
Wer lieber Docker Compose verwendet, trägt diesen Eintrag in seine *.yaml ein:
Schritt 5: Checken, ob der Container ordnungsgemäß läuft. In der folgenden Liste sollte eine Zeile mit dem Mosquitto-Docker auftauchen. Dieser sollte außerdem „up“ sein. Falls nicht, nochmal versuchen den Container zu starten und kontrollieren, ob er läuft.
$ docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
xxxxxxxxx eclipse-mosquitto "/init" 3 minutes ago Up 2 minutes [...] mosquitto
Schritt 6: Sehr gut, der Container läuft. Es wird dringend empfohlen, den MQTT-Broker so abzusichern, dass nur angemeldete User darauf zugreifen können. Das ist ja schon in Schritt 2 in die Konfigurationsdatei geschrieben worden. Mit dem folgenden Befehl melden wir uns in der Shell innerhalb des Containers an und erstellen einen Benutzer. In diesem Beispiel mosquitto. Im Anschluss an diesen Befehl wird man zweimal gebeten, das Passwort für den User festzulegen. Ist das geschafft, läuft der MQTT-Broker auf dem Server. Herzlichen Glückwunsch!
$ docker exec -it mosquitto sh // öffnet die Shell innerhalb des Dockers mosquitto_passwd -c /mosquitto/config/mosquitto.passwd mosquitto
Optional Schritt 7: Den MQTT-Broker bindet man in Home Assistant ein, indem man auf Einstellungen → Geräte und Dienste → + Integration hinzufügen klickt. Im Suchfenster nach „MQTT“ suchen und die Zugangsdaten eingeben. Die Server-Adresse findet man übrigens am schnellsten über ifconfig heraus.
Mit der kostenlosen Open Source Lösung unbox.at schützt du deinen Posteingang mit E-Mail-Aliasnamen. Antworte anonym auf weitergeleitete E-Mails. Der Absender erhält die E-Mail so, als käme sie von deinem Alias. Oder starte eine Konversation direkt von deinem Alias aus.
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere ins unserem Chat mit.
Linux Umsteiger ist wieder da. Hier geht es zu den im Video angesprochenen Links:
Perry Rhodan Kanal Raketenheftleser : https://www.youtube.com/@raketenheftleser
Besucht mich auf Facebook: https://www.facebook.com/josef.moser.589/
Meine Autorenseite auf Amazon: https://www.amazon.de/stores/Josef-Moser/author/B001K73R84?ref=ap_rdr&isDramIntegrated=true&shoppingPortalEnabled=true
Weitere Kanäle:
Joe's Musik Check: https://www.youtube.com/@joesmusikcheck
Unter dem Motto „Zeichen setzen“ finden am 16. und 17. März 2024 wieder die Chemnitzer Linux-Tage statt. Die Veranstalter hoffen wieder auf einen großen Zuspruch im Hörsaalgebäude der TU Chemnitz an der Reichenhainer Straße.
Eintrittskarten zur Veranstaltung wird es im Vorverkauf geben. Da die Anzahl der Tickets aber begrenzt ist, wird es an der Tageskasse nur Restkarten geben.
Auch 2024 haben sich die Chemnitzer Linux-Tage einen Platz an einem März-Wochenende gesucht. Also Kalender gezückt und den 16. und 17. März 2024 dick einkreisen! Es lohnt sich bestimmt.
Wir freuen uns sehr, euch im März vor Ort in Chemnitz in gewohnter Umgebung wiederzusehen. Über unsere Pressemitteilungen, Social Media könnt ihr euch diesbezüglich auf dem Laufenden halten.
Eigentlich ist es eine kaum genutzte Funktion und irgendwie waren sie schon immer ein wenig, hmmm. Vielleicht empfinde ich es auch nur so. Aber nun sind einige soziale Netzwerke aus der Funktion Teilen aus den Blogartikeln genommen worden. Natürlich an erster Stelle das ehemalige Twitter und der Firma Meta inklusive alle Ihren Diensten. Ich glaube ... Weiterlesen