Ab sofort ist KeePassXC 2.7.7 verfügbar. Die neueste Version bietet einige interessante Neuerungen sowie Verbesserungen. Die aktuelle Variante verbessert Deinen Arbeitsablauf sowie die Integration mit modernen Authentifizierungsdiensten. Zu den Highlights gehören Passkey-Unterstützung und ein Import-Assistent: Passkeys-Unterstützung in KeePassXC 2.7.7 Diese Version bietet die offizielle Implementierung von Passkeys für KeePassXC. Ein Jahr lang wurde die Funktion entwickelt. Sie nutzt den bestehenden Browser-Integrationsdienst, um Passkeys für die Authentifizierung zu speichern und zu verwenden. Passkeys sind eine Alternative zu Passwörtern, die sehr sicher […]
Am 29. Februar 2024 hat The Document Foundation LibreOffice 24.2.1 veröffentlicht. Jetzt hat es die neueste Version auch in das Fresh-PPA von Ubuntu geschafft. Bisher bekam ich weiterhin Versionen aus der 7.6.x-Reihe angeboten, die ebenfalls als stabil gilt. Als ich meinen Rechner heute Morgen hochgefahren habe, wurde mir allerdings erstmals das LibreOffice mit der neuen Versionierung angeboten. Es gibt zwar andere Optionen, LibreOffice zu installieren oder zu benutzen, aber mir ist die Option über den Paketmanager am liebsten. Damit bekomme […]
Es gibt unzählige Möglichkeiten, die Web-Werbung zu minimieren. Die c’t hat kürzlich ausführlich zum Thema berichtet, aber die entsprechenden Artikel befinden sich auf heise.de hinter einer Paywall. Und heise.de ist ja mittlerweile auch eine Seite, die gefühlt mindestens so viel Werbung in ihre Texte einbaut wie spiegel.de. Das ist schon eine Leistung … Entsprechend lahm ist der Seitenaufbau im Webbrowser.
Egal, alles, was Sie wissen müssen, um zuhause einigermaßen werbefrei zu surfen, erfahren Sie auch hier — kostenlos und werbefrei :-)
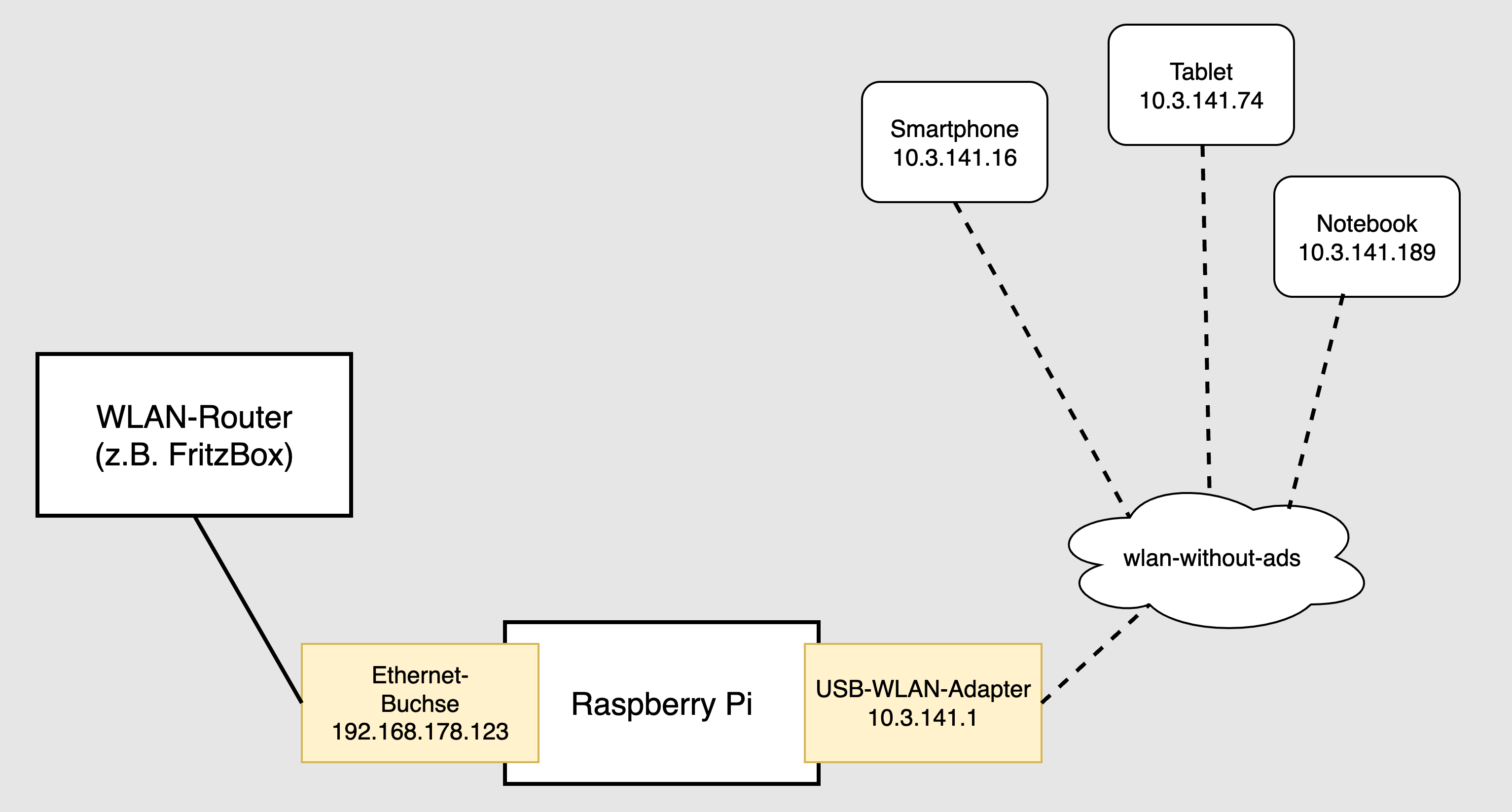
Raspberry Pi 3B+ mit USB-WLAN-Adapter
Konzept
Die Idee ist simpel: Parallel zum lokalen Netzwerk zuhause richten Sie mit einem Raspberry Pi ein zweites WLAN ein. Das zweite Netz verwendet nicht nur einen anderen IP-Adressbereich, sondern hat auch einen eigenen Domain Name Server, der alle bekannten Ad-Ausliefer-Sites blockiert. Jeder Zugriff auf eine derartige Seite liefert sofort eine Null-Antwort. Sie glauben gar nicht, wie schnell die Startseite von heise.de, spiegel.de etc. dann lädt!
Alle Geräte im Haushalt haben jetzt die Wahl: sie können im vorhandenen WLAN des Internet-Routers bleiben, oder in das WLAN des Raspberry Pis wechseln. (Bei mir zuhause hat dieses WLAN den eindeutigen Namen/SSID wlan-without-ads.)
RaspAP auf dem Raspberry Pi spannt ein eigenes (beinahe) werbefreies WLAN auf
Zur Realisierung dieser Idee brauchen Sie einen Raspberry Pi — am besten nicht das neueste Modell: dessen Rechenleistung und Stromverbrauch sind zu höher als notwendig! Ich habe einen Raspberry Pi 3B+ aus dem Keller geholt. Auf dem Pi installieren Sie zuerst Raspbian OS Lite und dann RaspAP. Sie schließen den Pi mit einem Kabel an das lokale Netzwerk an. Der WLAN-Adapter des Raspberry Pis realisiert den Hotspot und spannt das werbefreie lokale Zweit-Netzwerk auf. Die Installation dauert ca. 15 Minuten.
Raspberry Pi OS Lite installieren
Zur Installation der Lite-Version von Raspberry Pi OS laden Sie sich das Programm Raspberry Pi Imager von https://www.raspberrypi.com/software/ herunter und führen es aus. Damit übertragen Sie Raspberry Pi OS Lite auf eine SD-Karte. (Eine SD-Karte mit 8 GiB reicht.) Am besten führen Sie gleich im Imager eine Vorweg-Konfiguration durch und stellen einen Login-Namen, das Passwort und einen Hostnamen ein. Sie können auch gleich den SSH-Server aktivieren — dann können Sie alle weiteren Arbeiten ohne Tastatur und Monitor durchführen. Führen Sie aber keine WLAN-Konfiguration durch!
Mit der SD-Karten nehmen Sie den Raspberry Pi in Betrieb. Der Pi muss per Netzwerkkabel mit dem lokalen Netzwerk verbunden sein. Melden Sie sich an (wahlweise mit Monitor + Tastatur oder per SSH) und führen Sie ein Update durch (sudo apt update und sudo apt full-upgrade).
RaspAP installieren
RaspAP steht für Raspberry Pi Access Point. Sein Setup-Programm installiert eine Weboberfläche, in der Sie unzählige Details und Funktionen Ihres WLAN-Routers einstellen können. Dazu zählen:
Verwendung als WLAN-Router oder -Repeater
freie Auswahl des WLAN-Adapters
frei konfigurierbarer DHCP-Server
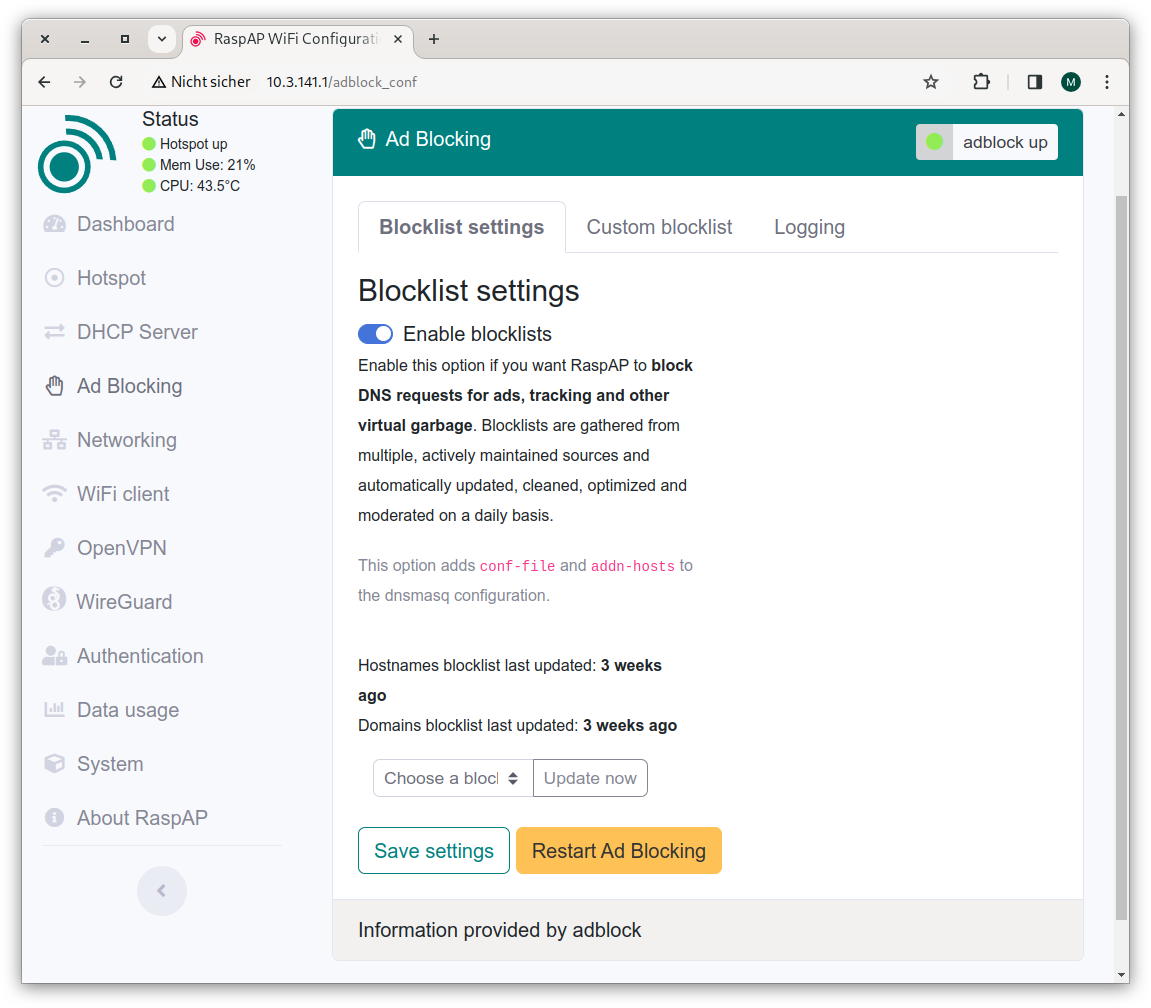
Ad-Blocking-Funktion
VPN-Server (OpenVPN, WireGuard)
VPN-Client (ExpressVPN, Mullvad VPN, NordVPN)
An dieser Stelle geht es nur um die Ad-Blocking-Funktionen, die standardmäßig aktiv sind. Zur Installation laden Sie das Setup-Script herunter, kontrollieren kurz mit less, dass das Script wirklich so aussieht, als würde es wie versprochen RaspAP installieren, und führen es schließlich aus.
Die Rückfragen, welche Features installiert werden sollen, können Sie grundsätzlich alle mit [Return] beantworten. Das VPN-Client-Feature ist nur zweckmäßig, wenn Sie über Zugangsdaten zu einem kommerziellen VPN-Dienst verfügen und Ihr Raspberry Pi diesen VPN-Service im WLAN weitergeben soll. (Das ist ein großartiger Weg, z.B. ein TV-Gerät via VPN zu nutzen.)
Welche Funktionen Sie wirklich verwenden, können Sie immer noch später entscheiden. Das folgende Listing ist stark gekürzt. Die Ausführung des Setup-Scripts dauert mehrere Minuten, weil eine Menge Pakete installiert werden.
wget https://install.raspap.com -O raspap-setup.sh
less raspap-setup.sh
bash raspap-setup.sh
The Quick Installer will guide you through a few easy steps
Using GitHub repository: RaspAP/raspap-webgui 3.0.7 branch
Configuration directory: /etc/raspap
lighttpd root: /var/www/html? [Y/n]:
Installing lighttpd directory: /var/www/html
Complete installation with these values? [Y/n]:
Enable HttpOnly for session cookies? [Y/n]:
Enable RaspAP control service (Recommended)? [Y/n]:
Install ad blocking and enable list management? [Y/n]:
Install OpenVPN and enable client configuration? [Y/n]:
Install WireGuard and enable VPN tunnel configuration? [Y/n]:
Enable VPN provider client configuration? [Y/n]: n
The system needs to be rebooted as a final step. Reboot now? [Y/n]
Wenn alles gut geht, gibt es nach dem Neustart des Raspberry Pi ein neues WLAN mit dem Namen raspi-webgui. Das Passwort lautet ChangeMe.
Sobald Sie Ihr Notebook (oder ein anderes Gerät) mit diesem WLAN verbunden haben, öffnen Sie in einem Webbrowser die Seite http://10.3.141.1 (mit http, nicht https!) und melden sich mit den folgenden Daten an:
Username: admin
Passwort: secret
In der Weboberfläche sollten Sie als Erstes zwei Dinge ändern: das Admin-Passwort und das WLAN-Passwort:
Zur Veränderung des Admin-Passworts klicken Sie auf das User-Icon rechts oben in der Weboberfläche, geben einmal das voreingestellte Passwort secret und dann zweimal Ihr eigenes Passwort an.
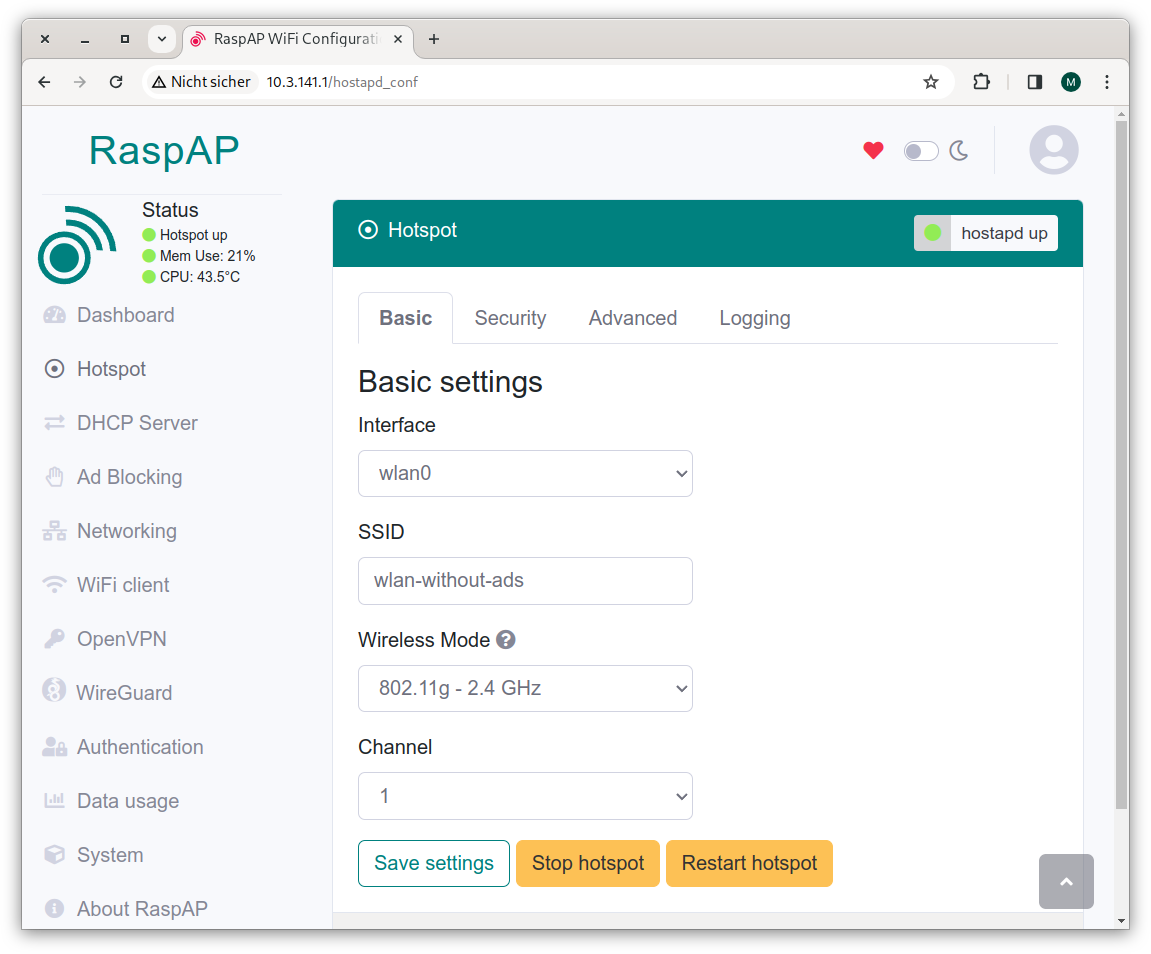
Die Eckdaten des WLANs finden Sie im Dialogblatt Hotspot. Das Passwort können Sie im Dialogblatt Security verändern.
Die Weboberfläche von RaspAP mit den Hotspot-EinstellungenBei den Ad-Block-Einstellungen sind keine Änderungen erforderlich. Es schadet aber nicht, hin und wieder die Ad-Blocking-Liste zu erneuern.
RaspAP verwendet automatisch den WLAN-Namen (den Service Set Identifier) raspi-webgui. Auf der Einstellungsseite Hotspot können Sie einen anderen Namen einstellen. Ich habe wie gesagt wlan-without-ads verwendet. Danach müssen sich alle Clients neu anmelden. Fertig!
USB-WLAN-Adapter
Leider hat der lokale WLAN-Adapter des Raspberry Pis keine großartige Reichweite. Für’s Wohnzimmer oder eine kleine Wohnung reicht es, für größere Wohnungen oder gar ein Einfamilienhaus aber nicht. Abhilfe schafft ein USB-WLAN-Antenne. Das Problem: Es ist nicht einfach, ein Modell zu finden, das vom Linux-Kernel auf Anhieb unterstützt wird. Ich habe zuhause drei USB-WLAN-Adapter. Zwei haben sich als zu alt erwiesen (kein WPA, inkompatibel mit manchen Client-Geräten etc.); der dritte Adapter (BrosTrend AC650) wird auf Amazon als Raspberry-Pi-kompatibel beworben, womit ich auch schon in die Falle getappt bin. Ja, es gibt einen Treiber, der ist aber nicht im Linux-Kernel inkludiert, sondern muss manuell installiert werden:
Immerhin gelang die Installation unter Raspberry Pi OS Lite auf Anhieb mit dem folgenden, auf GitHub dokumentierten Kommando:
sh -c 'busybox wget deb.trendtechcn.com/install \
-O /tmp/install && sh /tmp/install'
Mit dem nächsten Neustart erkennt Linux den WLAN-Adapter und kann ihn nutzen. Das ändert aber nichts daran, dass mich die Installation von Treibern von dubiosen Seiten unglücklich macht, dass die Treiberinstallation nach jedem Kernel-Update wiederholt werden muss und dass die manuelle Treiberinstallationen bei manchen Linux-Distributionen gar nicht möglich ist (LibreELEC, Home Assistant etc.).
Wenn Sie gute Erfahrungen mit einem USB-WLAN-Adapter gemacht haben, hinterlassen Sie bitte einen kurzen Kommentar!
Sobald RaspAP den WLAN-Adapter kennt, bedarf es nur weniger Mausklicks in der RaspAP-Weboberfläche, um diesen Adapter für den Hotspot zu verwenden.
Alternativ können Sie den internen WLAN-Adapter auch ganz deaktivieren. Dazu bauen Sie in config.txt die folgende Zeile ein und starten den Raspberry Pi dann neu.
Danach kennt Raspberry Pi OS nur noch den USB-WLAN-Adapter, eine Verwechslung ist ausgeschlossen.
Vorteile
Der größte Vorteil von RaspAP als Ad-Blocker ist aus meiner Sicht seine Einfachheit: Der Werbeblocker kann mit minimalem Konfigurationsaufwand von jedem Gerät im Haushalt genutzt werden (Opt-In-Modell). Sollte RaspAP für eine Website zu restriktiv sein, dauert es nur wenige Sekunden, um zurück in das normale WLAN zu wechseln. Bei mir zuhause waren alle Familienmitglieder schnell überzeugt.
Nachteile
Der Raspberry Pi muss per Ethernet-Kabel mit dem lokalen Netzwerk verbunden werden.
Manche Seiten sind so schlau, dass sie das Fehlen der Werbung bemerken und dann nicht funktionieren. Es ist prinzipbedingt unmöglich, für solche Seiten eine Ausnahmeregel zu definieren. Sie müssen in das normale WLAN wechseln, damit die Seite funktioniert.
youtube-Werbung kann nicht geblockt werden, weil Google so schlau ist, die Werbefilme vom eigenen Server und nicht von einem anderen Server zuzuspielen. youtube.com selbst zu blocken würde natürlich helfen und außerdem eine Menge Zeit sparen, schießt aber vielleicht doch über das Ziel hinaus.
Mit RaspAP sind Sie in einem eigenen privaten Netz, NICHT im lokalen Netz Ihres Internet-Routers. Sie können daher mit Geräten, die sich im wlan-without-ads befinden, nicht auf andere Geräte zugreifen, die mit Ihrem lokalen Router (FritzBox etc.) verbunden sind. Das betrifft NAS-Geräte, Raspberry Pis mit Home Assistant oder anderen Anwendungen etc.
Keine Werbeeinnahmen mehr für Seitenbetreiber?
Mir ist klar, dass sich viele Seiten zumindest teilweise über Werbung finanzieren. Das wäre aus meiner Sicht voll OK. Aber das Ausmaß ist unerträglich geworden: Mittlerweile blinkt beinahe zwischen jedem Absatz irgendein sinnloses Inserat. Werbefilme vervielfachen das Download-Volumen der Seiten, der Lüfter heult, ich kann mich nicht mehr auf den Text konzentrieren, den ich lese. Es geht einfach nicht mehr.
Viele Seiten bieten mir Pur-Abos an (also Werbeverzicht gegen Bezahlung). Diesbezüglich war https://derstandard.at ein Pionier, und tatsächlich habe ich genau dort schon vor vielen Jahren mein einziges Pur-Abo abgeschlossen. In diesem Fall ist es auch ein Ausdruck meiner Dankbarkeit für gute Berichterstattung. Früher habe ich für die gedruckte Zeitung bezahlt, jetzt eben für die Online-Nutzung.
Mein Budget reicht aber nicht aus, dass ich solche Abos für alle Seiten abschließen kann, die ich gelegentlich besuche: heise.de, golem.de, phoronix, zeit.de, theguardian.com usw. Ganz abgesehen davon, dass das nicht nur teuer wäre, sondern auch administrativ mühsam. Ich verwende diverse Geräte, alle paar Wochen muss ich mich neu anmelden, damit die Seiten wissen, dass ich zahlender Kunde bin. Das ist bei derstandard.at schon mühsam genug. Wenn ich zehn derartige Abos hätte, würde ich alleine an dieser Stelle schon verzweifeln.
Wenn sich Zeitungs- und Online-News-Herausgeber aber zu einem Site-übergreifenden Abrechnungsmodell zusammenschließen könnten (Aufteilung der monatlichen Abo-Gebühr nach Seitenzugriffen), würde ich mir das vielleicht überlegen. Das ist aber sowieso nur ein Wunschtraum.
Aber so, wie es aktuell aussieht, funktioniert nur alles oder nichts. Mit RaspAP kann ich die Werbung nicht für manche Seiten freischalten. Eine Reduktion des Werbeaufkommens auf ein vernünftiges Maß funktioniert auch nicht. Gut, dann schalte ich die Werbung — soweit technisch möglich — eben ganz ab.
Laut eigenen Angaben ist The Dark Mod 2.12 ist ein großer Schritt nach vorn für Leute, die Missionen designen! Das Culling-System wurde umfassend überarbeitet, um sicherzustellen, dass Deine CPU und Deine GPU keine Ressourcen für das Rendern unsichtbarer Geometrie, Lichter und Schatten verschwenden. Einige der besten Kartenoptimierungsexperten haben ähnliche Leistungssteigerungen erreicht, wie es beim neuen Culling-System zu finden ist. Allerdings ist das laut eigenen Angaben eine seltene Fähigkeit. Das Team hat es sogar geschafft, die Leistung von Missionen zu verbessern, […]
Nach einer langen Entwicklungsphase wurde openmediavault 7 mit Codenamen Sandworm veröffentlicht. Die größte Neuerung ist das Upgrade auf Debian 12 Bookworm. Wobei das Team in der offiziellen Ankündigung von einer Evolution und nicht einer Revolution spricht. Im Changelog findest Du neben dem Upgrade auf Debian 12 auch folgende Neuerungen und Änderungen: Du kannst das ISO-Image für AMD64-basierte Systeme hier herunterladen. Das Team rät, das System nach der Installation mit omv-upgrade zu aktualisieren. Zusätzlich zur ISO-Installation kannst Du OMV auf einem […]
Das Entwickler-Team von Ubuntu hat sich dafür entschieden, beim kommenden Ubuntu 24.04 LTS Noble Numbat per Standard keine Spiele mehr zu installieren. Bisher wurden bei Ubuntu vier Spiele vorinstalliert: Das Team ist auch der Meinung, dass selbst diese wenigen ausgewählten Spiele immer weniger repräsentativ für Ubuntu sind. Natürlich sind diese Games nicht aus den Repos verschwunden. Wer sie nach der Installation des Betriebssystems wieder haben möchte, kann sie selbstverständlich nachinstallieren. Werde ich die Games vermissen? Nein … ich habe sie […]
Mit Kali Linux 2024.1 hat das Team die erste Version dieses Jahres veröffentlicht. Es gibt einige Neuerungen und auch visuell wurde die Security-Distribution aufgefrischt. Neu ist auch, dass es neue Spiegel-Server gibt, auf denen das Image gehostet ist. 2024 Theme-Änderungen und Desktop-Verbesserungen Es ist schon ein bisschen Tradition geworden, dass die 20**.1-Versionen immer ein neues Theme mit sich bringen. Das Team hat sowohl das Boot-Menü als auch den Anmeldebildschirm sowie die Wallpaper geändert. Es gibt auch einige Verbesserungen beim Xfce-Desktop. […]
Ab sofort ist die finale Version von Tails 6.0 verfügbar. Es ist die erste Version, die auf Debian 12 Bookworm basiert und GNOME 43 als Desktop-Umgebung mit sich bringt. Bei Tails 6.0 wurde die meiste Software aktualisiert. Zudem gibt es diverse Verbesserungen bezüglich Sicherheit und Benutzerfreundlichkeit. Zu den neuen Funktionen gehört eine Fehlererkennung beim permanenten Speicher. Tails 6.0 warnt Dich, wenn beim Lesen von Daten oder Schreiben auf den USB-Stick Fehler auftrete. Damit kannst Du mögliche Hardware-Fehler auf dem USB-Stick […]
Mit einem Dualstack-Proxy Internet-Protokolle verbinden beschrieb eine Möglichkeit, um von Hosts, welche ausschließlich über IPv6-Adressen verfügen, auf Ziele zugreifen zu können, die ausschließlich über IPv4-Adressen verfügen. In diesem Beitrag betrachte ich die andere Richtung.
Zu diesem Beitrag motiviert hat mich der Kommentar von Matthias. Er schreibt, dass er für den bei einem Cloud-Provider gehosteten Jenkins Build Server IPv4 deaktivieren wollte, um Kosten zu sparen. Dies war jedoch nicht möglich, da Kollegen aus einem Co-Workingspace nur mit IPv4 angebunden sind und den Zugriff verloren hätten.
Doch wie kann man nun ein IPv6-Netzwerk für ausschließlich IPv4-fähige Clients erreichbar machen, ohne für jeden Host eine IPv4-Adresse zu buchen? Dazu möchte ich euch anhand eines einfachen Beispiels eine mögliche Lösung präsentieren.
Vorkenntnisse
Um diesem Text folgen zu können, ist ein grundsätzliches Verständnis von DNS, dessen Resource Records (RR) und des HTTP-Host-Header-Felds erforderlich. Die Kenntnis der verlinkten Wikipedia-Artikel sollte hierfür ausreichend sein.
Umgebung
Zu diesem Proof of Concept gehören:
Ein Dualstack-Reverse-Proxy-Server (HAProxy) mit den DNS-RR:
haproxy.example.com. IN A 203.0.113.1
haproxy.example.com IN AAAA 2001:DB8::1
Zwei HTTP-Backend-Server mit den DNS-RR:
www1.example.com IN AAAA 2001:DB8::2
www2.example.com IN AAAA 2001:DB8::3
Zwei DNS-RR:
www1.example.com IN A 203.0.113.1
www2.example.com IN A 203.0.113.1
Ein Client mit einer IPv4-Adresse
Ich habe mich für HAProxy als Reverse-Proxy-Server entschieden, da dieser in allen Linux- und BSD-Distributionen verfügbar sein sollte und mir die HAProxy Maps gefallen, welche ich hier ebenfalls vorstellen möchte.
Der Versuchsaufbau kann wie folgt skizziert werden:
Ein Dualstack-Reverse-Proxy-Server (B) verbindet IPv4-Clients mit IPv6-Backend-Servern
HAProxy-Konfiguration
Für dieses Minimal-Beispiel besteht die HAProxy-Konfiguration aus zwei Dateien, der HAProxy Map hosts.map und der Konfigurationsdatei poc.cfg.
Eine HAProxy Map besteht aus zwei Spalten. In der ersten Spalte stehen die FQDNs, welche vom HTTP-Client aufgerufen werden können. In der zweiten Spalte steht der Name des Backends aus der HAProxy-Konfiguration, welcher bestimmt, an welche Backend-Server eine eingehende Anfrage weitergeleitet wird. In obigem Beispiel werden Anfragen nach www1.example.com an das Backend serversa und Anfragen nach www2.example.com an das Backend serversb weitergeleitet.
Die HAProxy Maps lassen sich unabhängig von der HAProxy-Konfigurations-Datei pflegen und bereitstellen. Map-Dateien werden in ein Elastic Binary Tree-Format geladen, so dass ein Wert aus einer Map-Datei mit Millionen von Elementen ohne spürbare Leistungseinbußen nachgeschlagen werden kann.
Die HAProxy-Konfigurations-Datei poc.cfg für dieses Minimal-Beispiel ist ähnlich simpel:
~]$ cat /etc/haproxy/conf.d/poc.cfg
frontend fe_main
bind :80
use_backend %[req.hdr(host),lower,map(/etc/haproxy/conf.d/hosts.map)]
backend serversa
server server1 2001:DB8::1:80
backend serversb
server server1 2001:DB8::2:80
In der ersten Zeile wird ein Frontend mit Namen fe_main definiert. Zeile 2 bindet Port 80 für den entsprechenden Prozess und Zeile 3 bestimmt, welches Backend für eingehende HTTP-Anfragen zu nutzen ist. Dazu wird der HTTP-Host-Header ausgewertet, falls notwendig, in Kleinbuchstaben umgewandelt. Mithilfe der Datei hosts.map wird nun ermittelt, welches Backend zu verwenden ist.
Die weiteren Zeilen definieren zwei Backends bestehend aus jeweils einem Server, welcher auf Port 80 Anfragen entgegennimmt. In diesem Beispiel sind nur Server mit IPv6-Adressen eingetragen. IPv4-Adressen sind selbstverständlich auch zulässig und beide Versionen können in einem Backend auch gemischt auftreten.
Kann eine HTTP-Anfrage nicht über die hosts.map aufgelöst werden, läuft die Anfrage in diesem Beispiel in einen Fehler. Für diesen Fall kann ein Standard-Backend definiert werden. Siehe hierzu den englischsprachigen Artikel Introduction to HAProxy Maps von Chad Lavoie.
Der Kommunikationsablauf im Überblick und im Detail
Der Kommunikationsablauf im Überblick
Von einem IPv4-Client aus benutze ich curl, um die Seite www1.example.com abzurufen:
~]$ curl -4 -v http://www1.example.com
* processing: http://www1.example.com
* Trying 203.0.113.1:80...
* Connected to www1.example.com (203.0.113.1) port 80
> GET / HTTP/1.1
> Host: www1.example.com
> User-Agent: curl/8.2.1
> Accept: */*
>
< HTTP/1.1 200 OK
< server: nginx/1.20.1
< date: Sat, 06 Jan 2024 18:44:22 GMT
< content-type: text/html
< content-length: 5909
< last-modified: Mon, 09 Aug 2021 11:43:42 GMT
< etag: "611114ee-1715"
< accept-ranges: bytes
<
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<title>Test Page for the HTTP Server on Red Hat Enterprise Linux</title>
Der FQDN www1.example.com wird mit der IPv4-Adresse 203.0.113.1 aufgelöst, welche dem Host haproxy.example.com gehört. Bei der Zeile Host: www1.example.com handelt es sich um den HTTP-Host-Header, welchen der HAProxy benötigt, um das richtige Backend auszuwählen.
Es ist zu sehen, dass wir eine Antwort von einem NGINX-HTTP-Server erhalten. Der HTML-Quelltext wurde gekürzt.
Damit ist es gelungen, von einem IPv4-Client eine Ressource abzurufen, die von einem IPv6-Server bereitgestellt wird.
Im Access-Log des Backend-Servers mit der IPv6-Adresse 2001:DB8::2 sieht man:
Die Anfrage erreicht den Backend-Server von der IPv6-Adresse des haproxy.example.com (2001:DB8::1). Die am Ende der Zeile zu sehende IPv4-Adresse (192.0.2.1) gehört dem IPv4-Client, von dem ich die Anfrage gesendet habe.
Gedanken zur Skalierung
In diesem Beispiel sind die Server www1.example.com und www2.example.com über ihre IPv6-Adressen direkt erreichbar. Nur die Client-Anfragen von IPv4-Clients laufen über den Reverse-Proxy. Wenn man es wünscht, kann man selbstverständlich sämtliche Anfragen (von IPv4- und IPv6-Clients) über den Reverse-Proxy laufen lassen.
In kleinen Umgebungen kann man einen Reverse-Proxy wie HAProxy zusammen mit Squid (vgl. Artikel Mit einem Dualstack-Proxy Internet-Protokolle verbinden) auf einem Host laufen lassen. Selbstverständlich kann man sie auch auf separate Hosts verteilen.
Hochverfügbarkeit lässt sich auch hier mit keepalived nachrüsten:
Die Internet-Protokolle IPv4 und IPv6 werden wohl noch eine ganze Zeit gemeinsam das Internet bestimmen und parallel existieren. Ich bin mir sogar sicher, dass ich das Ende von IPv4 nicht mehr miterleben werde. Dualstack-(Reverse)-Proxy-Server stellen eine solide und robuste Lösung dar, um beide Welten miteinander zu verbinden.
Sicher bleiben noch ausreichend Herausforderungen übrig. Ich denke da nur an Firewalls, Loadbalancer, NAT und Routing. Und es werden sich auch Fälle finden lassen, in denen Proxyserver nicht infrage kommen. Doch mit diesen Herausforderungen beschäftige ich mich dann in anderen Artikeln.
Die letzten Wochen habe ich mich ziemlich intensiv mit Home Assistant auseinandergesetzt. Dabei handelt es sich um eine Open-Source-Software zur Smart-Home-Steuerung. Home Assistant (HA) ist eine spezielle Linux-Distribution, die häufig auf einem Raspberry Pi ausgeführt wird. Dieser Artikel zeigt die nicht ganz unkomplizierte Integration meines Fronius Wechselrichters in das Home-Assistant-Setup. (Die Basisinstallation von HA setze ich voraus.)
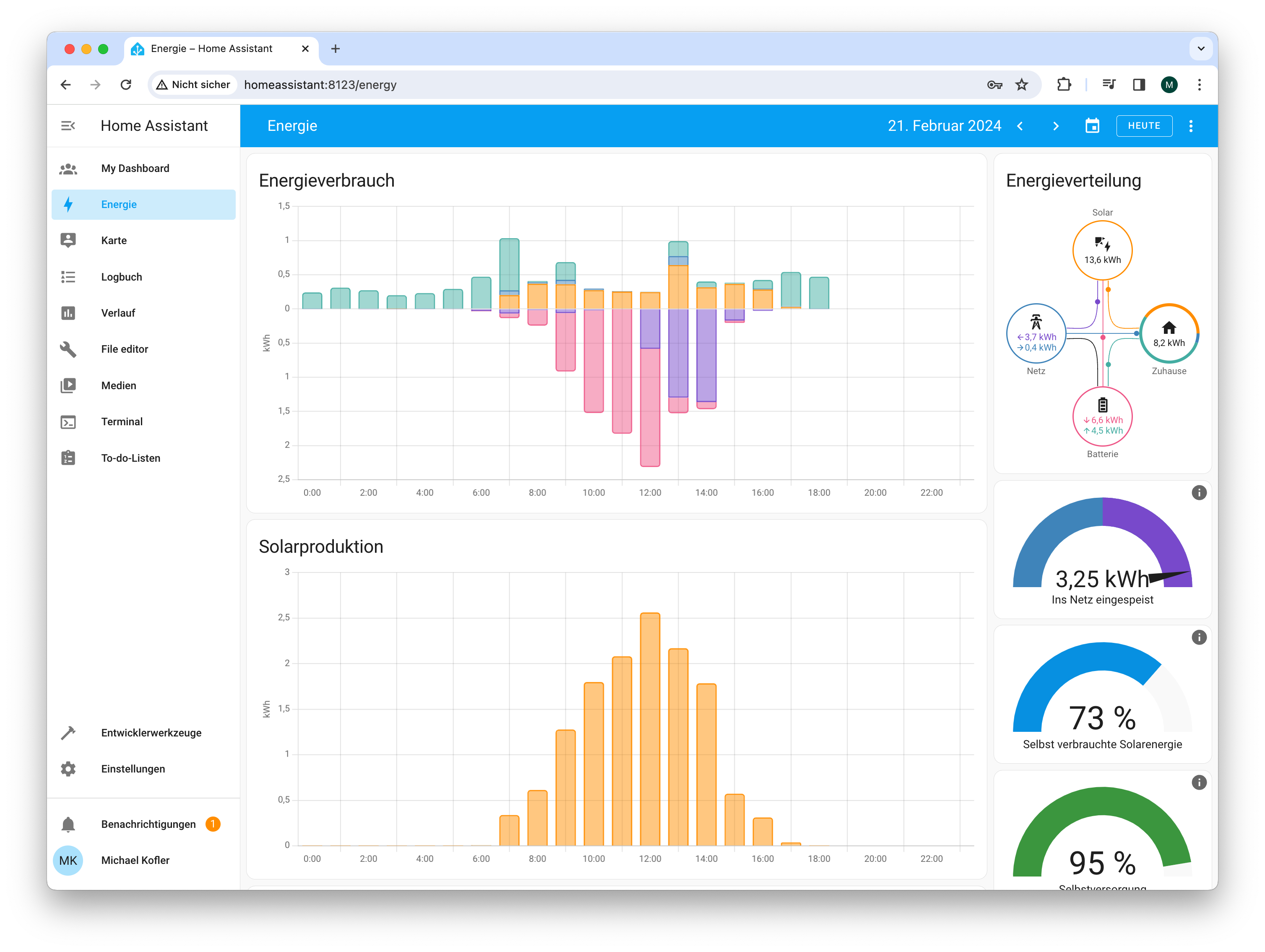
Die Energieansicht nach der erfolgreichen Integration des Fronius Wechselrichters.
Die Abbildung ist wie folgt zu interpretieren: Heute bis 19:00 wurden im Haushalt 8,2 kWh elektrische Energie verbraucht, aber 13,6 kWh el. Energie produziert (siehe die Kreise rechts). 3,7 kWh wurden in das Netz eingespeist, 0,4 kWh von dort bezogen.
Das Diagramm »Energieverbrauch« (also das Balkendiagramm oben): In den Morgen- und Abendstunden hat der Haushalt Strom aus der Batterie bezogen (grün); am Vormittag wurde der Speicher wieder komplett aufgeladen (rot). Am Nachmittag wurde Strom in das Netz eingespeist (violett). PV-Strom, der direkt verbraucht wird, ist gelb gekennzeichnet.
Fronius-Integration
Bevor Sie mit der Integration des Fronius-Wechselrichters in das HA-Setup beginnen, sollten Sie sicherstellen, dass der Wechselrichter, eine fixe IP-Adresse im lokalen Netzwerk hat. Die erforderliche Einstellung nehmen Sie in der Weboberfläche Ihres WLAN-Routers vor.
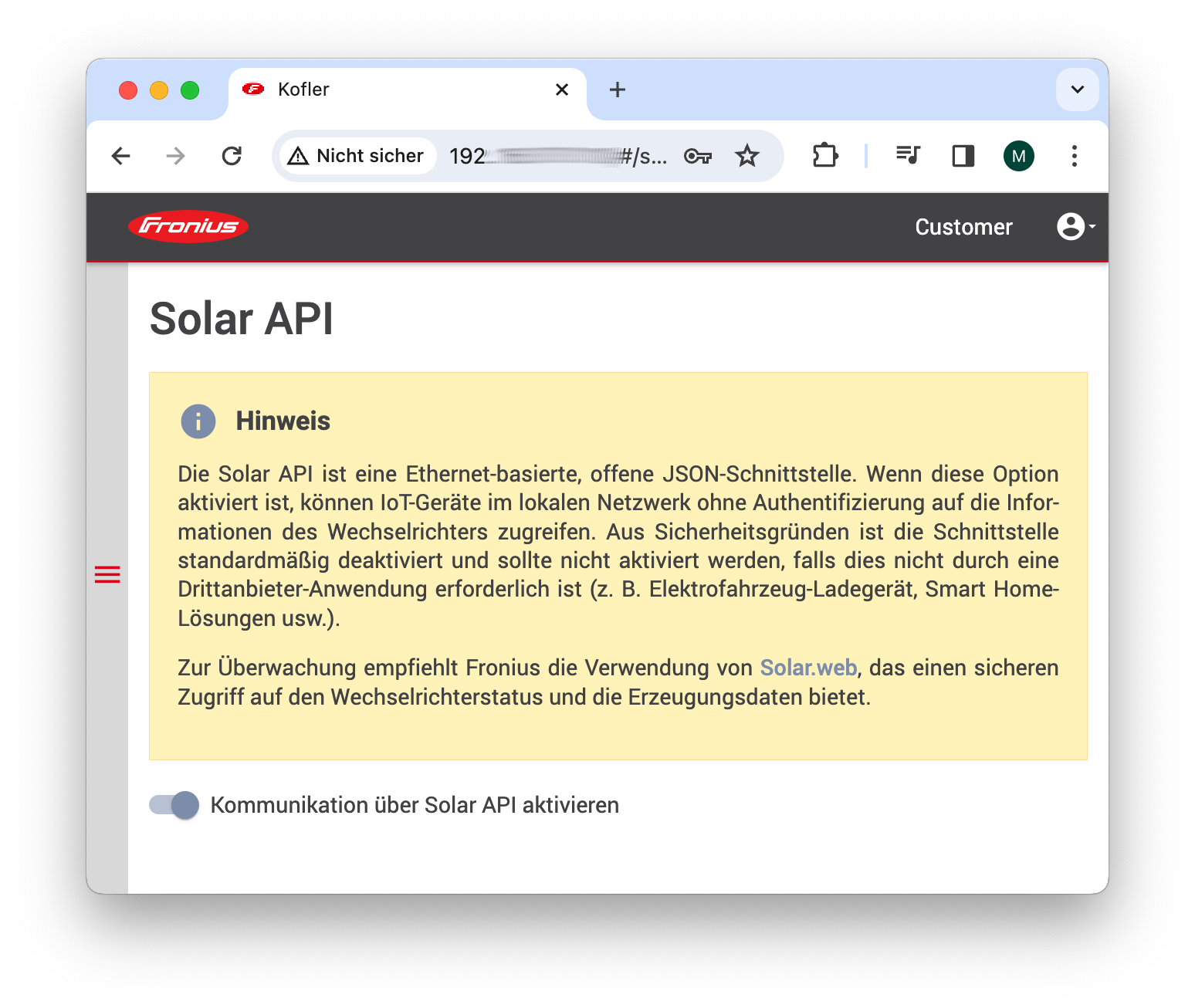
Außerdem müssen Sie beim Wechselrichter die sogenannte Solar API aktivieren. Über diese REST-API können diverse Daten des Wechselrichters gelesen werden. Zur Aktivierung müssen Sie sich im lokalen Netzwerk in der Weboberfläche des Wechselrichters anmelden. Die relevante Option finden Sie unter Kommunikation / Solar API. Der Dialog warnt vor der Aktivierung, weil die Schnittstelle nicht durch ein Passwort abgesichert ist. Allzugroß sollte die Gefahr nicht sein, weil der Zugang ohnedies nur im lokalen Netzwerk möglich ist und weil die Schnittstelle ausschließlich Lesezugriffe vorsieht. Sie können den Wechselrichter über die Solar API also nicht steuern.
Aktivierung der Solar API in der lokalen Weboberfläche des Fronius-Wechselrichters
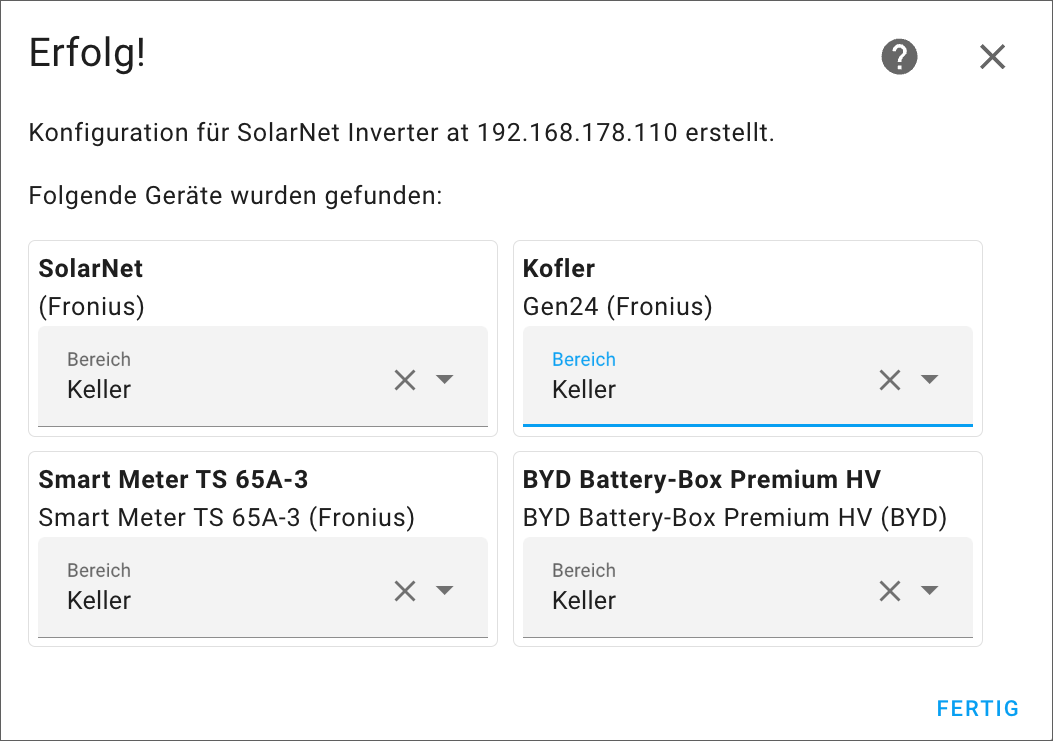
Als nächstes öffnen Sie in der HA-Weboberfläche die Seite Einstellungen / Geräte & Dienste und suchen dort nach der Integration Fronius (siehe auch hier). Im ersten Setup-Dialog müssen Sie lediglich die IP-Adresse des Wechselrichters angeben. Im zweiten Dialog werden alle erkannten Komponenten aufgelistet und Sie können diese einem Bereich zuordnen.
Setup der Fronius-Integration in der Weboberfläche von Home Assistant
Bei meinen Tests standen anschließend über 60 neue Entitäten (Sensoren) für alle erdenklichen Betriebswerte des Wechselrichters, des damit verbundenen Smartmeters sowie des Stromspeichers zur Auswahl. Viele davon werden automatisch im Default-Dashboard angezeigt und machen dieses vollkommen unübersichtlich.
Energieansicht
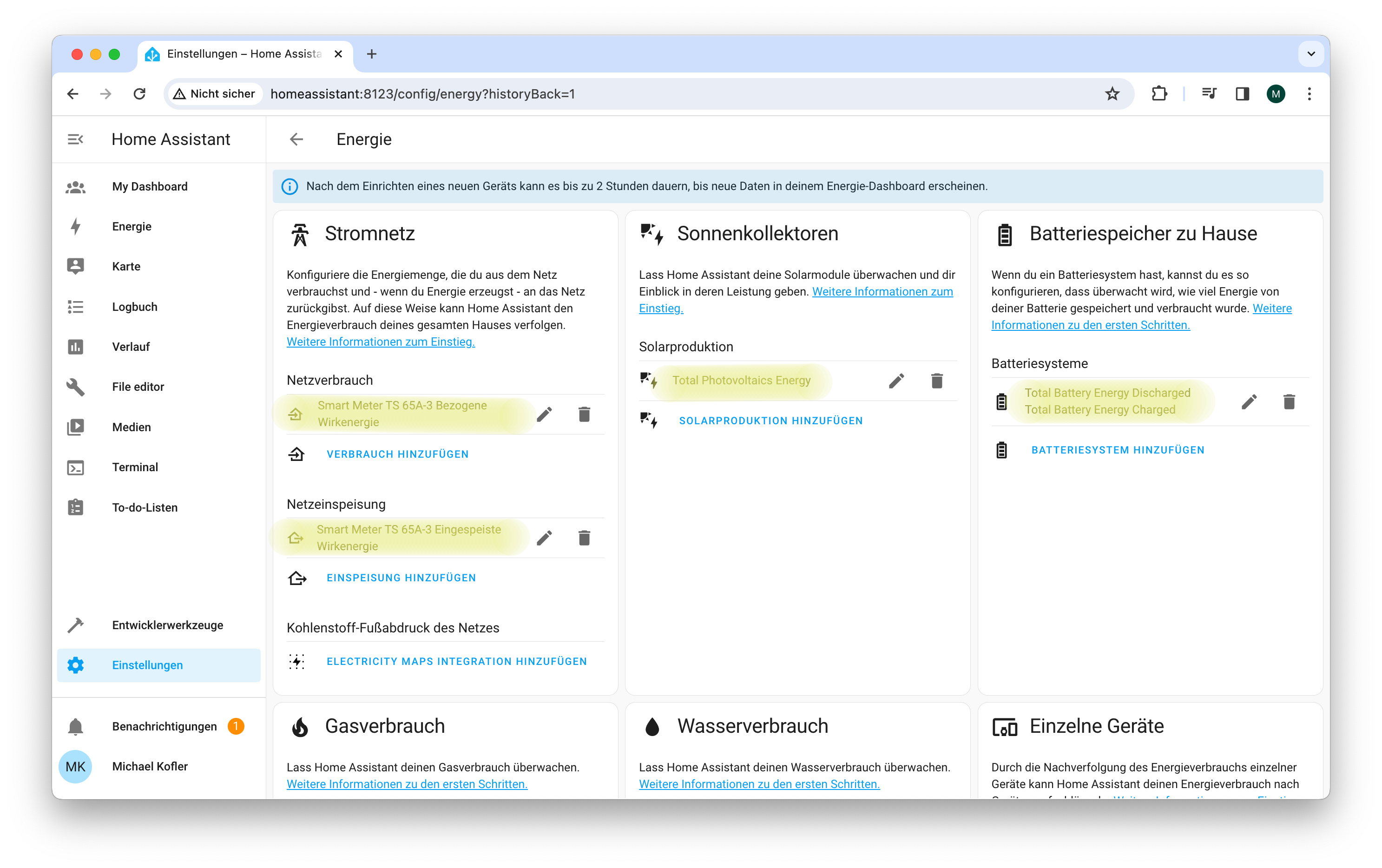
Der Zweck der Fronius-Integration ist weniger die Anzeige diverser einzelner Betriebswerte. Vielmehr sollen die Energieflüssen in einer eigenen Energieansicht dargestellt werden. Diese Ansicht wertet die Wechselrichterdaten aus und fasst zusammen, welche Energiemengen im Verlauf eines Tags, einer Woche oder eines Monats wohin fließen. Die Ansicht differenziert zwischen dem Energiebezug aus dem Netz bzw. aus den PV-Modulen und berücksichtigt bei richtiger Konfiguration auch den Stromfluss in den bzw. aus dem integrierten Stromspeicher. Sofern Sie eine Gasheizung mit Mengenmessung verfügen, können Sie auch diese in die Energieansicht integrieren.
Die Konfiguration der Energieansicht hat sich aber als ausgesprochen schwierig erwiesen. Auf Anhieb gelang nur das Setup des Moduls Stromnetz. Damit zeigt die Energieansicht nur an, wie viel Strom Sie aus dem Netz beziehen bzw. welche Mengen Sie dort einspeisen. Die Fronius-Integration stellt die dafür Daten in Form zweier Sensoren direkt zur Verfügung:
Aus dem Netz bezogene Energie: sensor.smart_meter_ts_65a_3_bezogene_wirkenergie
In das Netz eingespeiste Energie: sensor.smart_meter_ts_65a_3_eingespeiste_wirkenergie
Je nachdem, welchen Wechselrichter und welche dazu passende Integration Sie verwenden, werden die Sensoren bei Ihnen andere Namen haben. In den Auswahllisten zur Stromnetz-Konfiguration können Sie nur Sensoren
auswählen, die Energie ausdrücken. Zulässige Einheiten für derartige Sensoren sind unter anderem Wh (Wattstunden), kWh oder MWh.
Konfiguration der Energie-Ansicht in Home Assistant
Code zur Bildung von drei Riemann-Integralen
Eine ebenso einfache Konfiguration der Module Sonnenkollektoren und Batteriespeicher zu Hause scheitert daran, dass die Fronius-Integration zwar aktuelle Leistungswerte für die Produktion durch die PV-Module und den Stromfluss in den bzw. aus dem Wechselrichter zur Verfügung stellt (Einheit jeweils Watt), dass es aber keine kumulierten Werte gibt, welche Energiemengen seit dem Einschalten der Anlage geflossen sind (Einheit Wattstunden oder Kilowattstunden). Im Internet gibt es eine Anleitung, wie dieses Problem behoben werden kann:
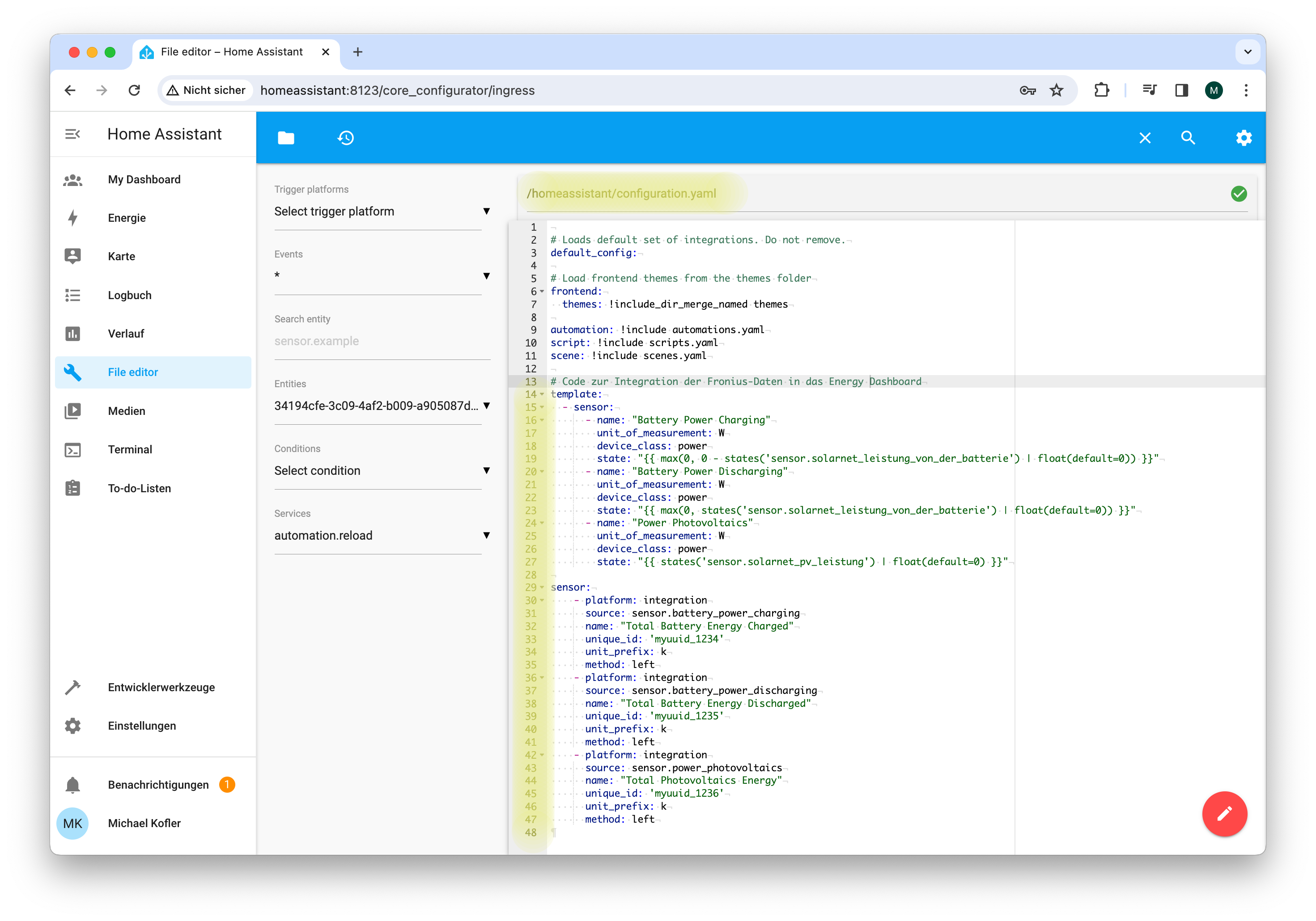
Die Grundidee besteht darin, dass Sie eigenen Code in eine YAML-Konfigurationsdatei von Home Assistant einbauen. Gemäß dieser Anweisungen werden mit einem sogenannten Riemann-Integral die Leistungsdaten in Energiemengen umrechnet. Dabei wird regelmäßig die gerade aktuelle Leistung mit der zuletzt vergangenen Zeitspanne multipliziert. Diese Produkte (Energiemengen) werden summiert (method: left). Das Ergebnis sind drei neue Sensoren (Entitäten), deren Name sich aus den title-Attributen im zweiten Teil des Listings ergeben:
Die Umsetzung der Anleitung hat sich insofern schwierig erwiesen, als die in der ersten Hälfte des Listungs verwendeten Sensoren aus der Fronius-Integration bei meiner Anlage ganz andere Namen hatten als in der Anleitung. Unter den ca. 60 Sensoren war es nicht ganz leicht, die richtigen Namen herauszufinden. Wichtig ist auch die Einstellung device_class: power! Die in einigen Internet-Anleitungen enthaltene Zeile device_class: energy ist falsch.
Der template-Teil des Listings ist notwendig, weil der Sensor solarnet_leistung_von_der_batterie je nach Vorzeichen die Lade- bzw. Entladeleistung enthält und daher getrennt summiert werden muss. Außerdem kommt es vor, dass die Fronius-Integration einzelne Werte gar nicht übermittelt, wenn sie gerade 0 sind (daher die Angabe eines Default-Werts).
Der zweite Teil des Listungs führt die Summenberechnung durch (method: left) und skaliert die Ergebnisse um den Faktor 1000. Aus 1000 Wh wird mit unit_prefix: k also 1 kWh.
Bevor Sie den Code in configuration.yaml einbauen können, müssen Sie einen Editor als Add-on installieren (Einstellungen / Add-ons, Add-on-Store öffnen, dort den File editor auswählen).
# in die Datei /homeassistant/configuration.yaml einbauen
...
template:
- sensor:
- name: "Battery Power Charging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, 0 - states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Battery Power Discharging"
unit_of_measurement: W
device_class: power
state: "{{ max(0, states('sensor.solarnet_leistung_von_der_batterie') | float(default=0)) }}"
- name: "Power Photovoltaics"
unit_of_measurement: W
device_class: power
state: "{{ states('sensor.solarnet_pv_leistung') | float(default=0) }}"
sensor:
- platform: integration
source: sensor.battery_power_charging
name: "Total Battery Energy Charged"
unique_id: 'myuuid_1234'
unit_prefix: k
method: left
- platform: integration
source: sensor.battery_power_discharging
name: "Total Battery Energy Discharged"
unique_id: 'myuuid_1235'
unit_prefix: k
method: left
- platform: integration
source: sensor.power_photovoltaics
name: "Total Photovoltaics Energy"
unique_id: 'myuuid_1236'
unit_prefix: k
method: left
In »configuration.yaml« müssen etliche Zeilen zusätzlicher Code eingebaut werden.
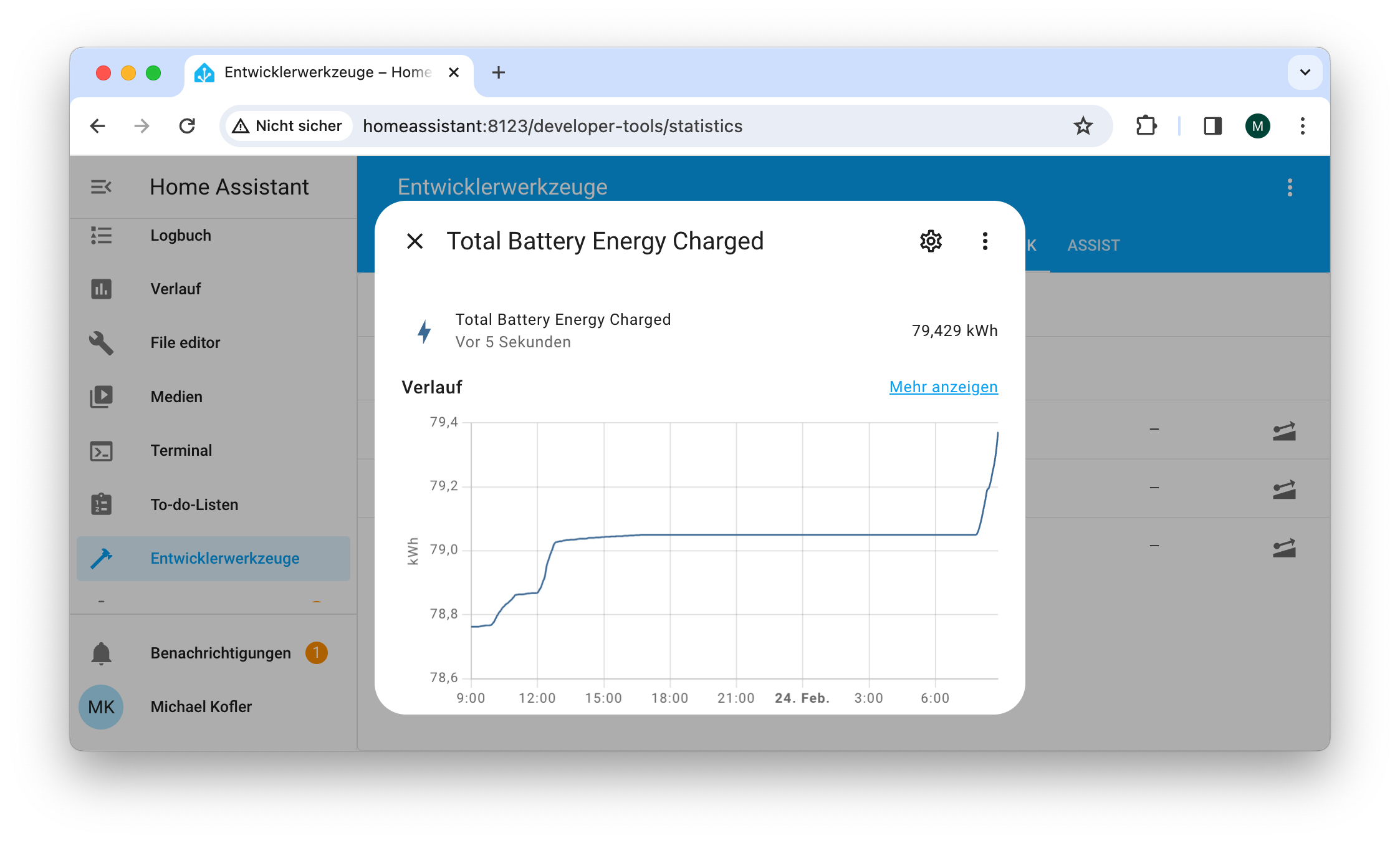
Damit die neuen Einstellungen wirksam werden, starten Sie den Home Assistant im Dialogblatt Einstellungen / System neu. Anschließend sollte es möglich sein, auch die Module Sonnenkollektoren und Batteriespeicher zu Hause richtig zu konfigurieren. (Bei meinen Experimenten hat es einen ganzen Tag gedauert hat, bis endlich alles zufriedenstellend funktionierte. Zwischenzeitlich habe ich zur Fehlersuche Einstellungen / System / Protokolle genutzt und musste unter Entwicklerwerkzeuge / Statistik zuvor aufgezeichnete Daten von falsch konfigurierten Sensoren wieder löschen.) Der Lohn dieser Art zeigt sich im Bild aus der Artikeleinleitung.
Unter Entwicklerwerkzeuge/Statistik können Sie sich vergewissern, dass die neuen Sensoren korrekt eingerichtet sind.Wenn ein Sensor angeklickt wird, erscheint eine Verlaufskurve.
Nachdem unsere Community-Cloud das vorab letzte Software-Upgrade und eine neue SSD erhalten hatte, wurde es nun Zeit auch die Hardware auf eine neue Stufe zu heben. Da wir der Meinung waren, dass hierzu ein Raspberry P4 4 Modell B mit 8GB völlig ausreicht, haben wir uns bewusst für dieses Gerät entschieden. Eingepackt in ein passiv gekühltes Metallgehäuse wird uns diese Kombination, so hoffe ich, die nächste Zeit zuverlässig begleiten.
Da ein Upgrade der installierten Software vom Raspberry Pi 3 auf den Raspberry Pi 4 wenig sinnvoll und auch fast unmöglich umzusetzen ist, war die Idee, die Datenbank und das Datenverzeichnis der Nextcloud in eine Neuinstallation (64-Bit) einzubinden.
Für den Wechsel auf 64-Bit hätte eigentlich parallel zum bestehenden System eine Neuinstallation auf dem erwähnten Raspberry Pi durchgeführt werden müssen. Hier konnte ich mir die Arbeit aber ein wenig erleichtern, indem ich die MicroSD meiner eigenen Cloud klonen konnte. Auf dem geklonten System waren so nur einige Anpassungen vorzunehmen, bevor das neue Gerät an Stelle des 32-Bit-Systems in Betrieb genommen werden konnte.
Aufnahme mit Wärmebildkamera (Raspberry Pi 4 – passive Kühlung)
Die aus dem Raspberry Pi 3 gesicherte Datenbank wurde in den Raspberry Pi 4 eingelesen und die Daten-SSD in die /etc/fstab eingebunden. Danach wurde der ddclient mit der DynDNS neu konfiguriert. Ein neues Zertifikat wurde erstellt und die automatische Upgrade-Routine hierzu angepasst. Zum Schluss mussten nur noch die Ports im Speedport-Router für die neue Hardware freigegeben werden.
Fazit
Der Aufwand hat sich in dem Sinne gelohnt, da dieses nun mittlerweile über fünfeinhalb Jahre existierende Projekt, zukunftssicher weiterbetrieben werden kann.
Nachdem nun unsere Community-Cloud endlich wieder lief, habe ich versucht innerhalb der Gemeinschaft unseren Cloud-Speicher etwas zu bewerben. Bei einigen Nutzern war dieser inzwischen etwas in Vergessenheit geraten, samt den nötigen Passwörtern.
Es kommt natürlich immer wieder vor, dass Zugangsdaten nicht richtig verwahrt werden oder gar ganze Passwörter nicht mehr auffindbar sind. Mehrfache fehlerhafte Eingaben können jedoch, wie im Fall der Nextcloud, dazu führen, dass Nutzer-IPs ausgesperrt bzw. blockiert werden. Diesen Schutz nennt man Bruteforce-Schutz.
Bruteforce-Schutz
Nextcloud bietet einen eingebauten Schutzmechanismus gegen Bruteforce-Angriffe, der dazu dient, das System vor potenziellen Angreifern zu sichern, die wiederholt verschiedene Passwörter ausprobieren. Diese Sicherheitsvorkehrung ist standardmäßig in Nextcloud aktiviert und trägt dazu bei, die Integrität der Daten zu wahren und unautorisierten Zugriff auf das System zu verhindern.
Wie es funktioniert
Die Funktionsweise des Bruteforce-Schutzes wird besonders deutlich, wenn man versucht, sich auf der Anmeldeseite mit einem ungültigen Benutzernamen und/oder Passwort anzumelden. Bei den ersten Versuchen mag es unauffällig erscheinen, doch nach mehreren wiederholten Fehlversuchen wird man feststellen, dass die Überprüfung des Logins mit zunehmender Häufigkeit länger dauert. An dieser Stelle tritt der Bruteforce-Schutz in Kraft, der eine maximale Verzögerung von 25 Sekunden für jeden Anmeldeversuch einführt. Nach erfolgreicher Anmeldung werden sämtliche fehlgeschlagenen Versuche automatisch gelöscht. Wichtig zu erwähnen ist, dass ein ordnungsgemäß authentifizierter Benutzer von dieser Verzögerung nicht mehr beeinträchtigt wird, was die Sicherheit des Systems und die Benutzerfreundlichkeit gleichermaßen gewährleistet.
Bruteforce-Schutz kurzzeitig aushebeln
Hat nun einmal die Falle zugeschnappt und ein Anwender wurde aus der Nextcloud ausgesperrt, so kann sich das Problem über die Zeit von selbst lösen. Es gibt aber auch die Möglichkeit die Datenbank entsprechend zurückzusetzen.
Zuerst wechselt man in das Nextcloud-Verzeichnis. Danach werden über den folgenden OCC-Befehl die Bruteforce-Einträge der Datenbank resetet.
cd /var/www/html/nextcloud/
sudo -u www-data php occ security:bruteforce:reset 0.0.0.0
Neue Bruteforce-Attacken werden natürlich danach wieder geloggt und verdächtige IPs ausgesperrt.
Des Öfteren erinnere ich Kollegen daran, doch bitte bei Upgrades in einer Remoteshell mit einem terminal mutliplexer zu arbeiten. Falls doch einmal die Verbindung abbricht, nicht ein halb installiertes, oder konfiguriertes Paket vorliegt. Das kann viel und sehr unangenehme Arbeit auslösen. Man glaubt es kaum, den Fakt habe ich bei meiner Firewall in meinem Homeoffice ... Weiterlesen
Ein MQTT-Broker ist die Schnittstelle zwischen vielen IoT-Sensoren und Geräten, die Sensordaten auswerten oder Aktoren steuern. Das MQTT-Protokoll ist offen und sehr weit verbreitet. Es findet in der Industrie Anwendungen, ist aber auch in Smart Homes ist MQTT weit verbreitet. MQTT ist ein sehr schlankes und schnelles Protokoll. Es wird in Anwendungen mit niedriger Bandbreite gerne angewendet.
MQTT funktioniert, grob gesagt, folgendermaßen: IoT-Geräte können Nachrichten versenden, die von anderen IoT-Geräten empfangen werden. Die Vermittlungsstelle ist ein sogenannter MQTT-Broker. Dieser empfängt die Nachrichten von den Clients. Gleichzeitig können diese Nachrichten von anderen Clients abonniert werden. Die Nachrichten werden in sog. Topics eingestuft, die hierarchisch angeordnet sind, z.B. Wohnzimmer/Klima/Luftfeuchtigkeit.
Home Assistant, oder ein anderer Client, kann diesen Topic abonnieren und den Nachrichteninhalt („Payload„) auswerten (z.B. 65%).
Home Assistant OS vs. Home Assistant Container
In Home Assistant OS und Supervisor gibt es ein Addon, das einen MQTT-Broker installiert. Das ist sehr einfach, komfortabel und funktioniert wohl recht zurverlässig. In den Installationsarten Home Assistant Container und Core gibt es diese Möglichkeit nicht. Hier muss man manuell einen MQTT-Broker aufsetzen.
In diesem Artikel beschäftige ich mich damit, wie man den MQTT-Brocker Mosquitto über Docker installiert. Anschließend zeige ich, wie man die Konfigurationsdatei gestaltet und eine Verbindung zu Home Assistant herstellt. Das Ergebnis ist dann ungefähr so, als hätte man das Addon installiert. Los gehts!
Schritt für Schritt: MQTT-Broker Mosquitto mit Docker installieren
Als MQTT-Broker verwende ich die weit verbreitete Software Mosquitto von Eclipse. Dieser wird auch von Home Assistant bevorzugt und ist derjenige Broker, den das Addon installieren würde. Für diese Anleitung wird vorausgesetzt, dass Docker bereits installiert ist und eine SSH-Verbindung zum Server hergestellt werden kann.
Schritt 1: Zunächst erstellen wir ein paar Ordner, die wir später benötigen. Mosquitto wird später so konfiguriert, dass in diese Ordner alle wichtigen Dateien abgelegt werden. Dadurch kann man auf dem Filesystem des Servers Mosquitto konfigurieren und beobachten.
-p 1883:1883 Der genannte Port ist die Standardeinstellung für MQTT. Alles was auf diesen Port am Server ankommt, wird in den Mosquitto-Container geleitet.
-p 9001:9001 Über diesen Port laufen die Websocket-Anwendungen. Falls das nicht benötigt wird, kann man das weg lassen
name mosquitto Über diesen kurzen Namen können wir den Docker-Container steuern
-v <filesystem-Pfad>:<Container-Pfad> Die in Schritt 1 erstellten Ordner werden in den Container eingebunden
Wer lieber Docker Compose verwendet, trägt diesen Eintrag in seine *.yaml ein:
Schritt 5: Checken, ob der Container ordnungsgemäß läuft. In der folgenden Liste sollte eine Zeile mit dem Mosquitto-Docker auftauchen. Dieser sollte außerdem „up“ sein. Falls nicht, nochmal versuchen den Container zu starten und kontrollieren, ob er läuft.
$ docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
xxxxxxxxx eclipse-mosquitto "/init" 3 minutes ago Up 2 minutes [...] mosquitto
Schritt 6: Sehr gut, der Container läuft. Es wird dringend empfohlen, den MQTT-Broker so abzusichern, dass nur angemeldete User darauf zugreifen können. Das ist ja schon in Schritt 2 in die Konfigurationsdatei geschrieben worden. Mit dem folgenden Befehl melden wir uns in der Shell innerhalb des Containers an und erstellen einen Benutzer. In diesem Beispiel mosquitto. Im Anschluss an diesen Befehl wird man zweimal gebeten, das Passwort für den User festzulegen. Ist das geschafft, läuft der MQTT-Broker auf dem Server. Herzlichen Glückwunsch!
$ docker exec -it mosquitto sh // öffnet die Shell innerhalb des Dockers mosquitto_passwd -c /mosquitto/config/mosquitto.passwd mosquitto
Optional Schritt 7: Den MQTT-Broker bindet man in Home Assistant ein, indem man auf Einstellungen → Geräte und Dienste → + Integration hinzufügen klickt. Im Suchfenster nach „MQTT“ suchen und die Zugangsdaten eingeben. Die Server-Adresse findet man übrigens am schnellsten über ifconfig heraus.
Unter dem Motto „Zeichen setzen“ finden am 16. und 17. März 2024 wieder die Chemnitzer Linux-Tage statt. Die Veranstalter hoffen wieder auf einen großen Zuspruch im Hörsaalgebäude der TU Chemnitz an der Reichenhainer Straße.
Eintrittskarten zur Veranstaltung wird es im Vorverkauf geben. Da die Anzahl der Tickets aber begrenzt ist, wird es an der Tageskasse nur Restkarten geben.
Auch 2024 haben sich die Chemnitzer Linux-Tage einen Platz an einem März-Wochenende gesucht. Also Kalender gezückt und den 16. und 17. März 2024 dick einkreisen! Es lohnt sich bestimmt.
Wir freuen uns sehr, euch im März vor Ort in Chemnitz in gewohnter Umgebung wiederzusehen. Über unsere Pressemitteilungen, Social Media könnt ihr euch diesbezüglich auf dem Laufenden halten.
Im Januar 2023 hatte ich erklärt, wie ich mein Raspberry Pi OS 11 (basierend auf Debian 11 Bullseye), durch Einbinden einer Fremdquelle, von PHP7.4-fpm auf PHP8.1-fpm aktualisiert habe. Warum ich zu diesem Zeitpunkt die Version 8.1 installiert habe, ist recht einfach zu beantworten. Die aktuelle Version Nextcloud 25 war noch nicht kompatibel zu PHP 8.2. Erst mit Nextcloud 26 war ein Upgrade möglich.
Nun habe ich mich nach der Aktualisierung auf Nextcloud 28 entschieden auf PHP 8.2 zu wechseln. Da ich den FastCGI-Prozessmanager FPM bevorzuge, unterscheidet sich das Upgrade etwas von einer herkömmlichen PHP-Installation.
Nun wird via CLI die PHP-Version von 8.1 auf 8.2 mit
sudo update-alternatives --config php
umgestellt.
sudo update-alternatives --config php
Es gibt 5 Auswahlmöglichkeiten für die Alternative php (welche /usr/bin/php bereitstellen).
Auswahl Pfad Priorität Status
------------------------------------------------------------
0 /usr/bin/php.default 100 automatischer Modus
1 /usr/bin/php.default 100 manueller Modus
2 /usr/bin/php7.4 74 manueller Modus
* 3 /usr/bin/php8.1 81 manueller Modus
4 /usr/bin/php8.2 82 manueller Modus
5 /usr/bin/php8.3 83 manueller Modus
sudo update-alternatives --config php
Es gibt 5 Auswahlmöglichkeiten für die Alternative php (welche /usr/bin/php bereitstellen).
Auswahl Pfad Priorität Status
------------------------------------------------------------
0 /usr/bin/php.default 100 automatischer Modus
1 /usr/bin/php.default 100 manueller Modus
2 /usr/bin/php7.4 74 manueller Modus
3 /usr/bin/php8.1 81 manueller Modus
* 4 /usr/bin/php8.2 82 manueller Modus
5 /usr/bin/php8.3 83 manueller Modus
Ein abschließender Check zeigt die aktuelle Version.
php -v
PHP 8.2.14 (cli) (built: Dec 21 2023 20:18:00) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.2.14, Copyright (c) Zend Technologies
with Zend OPcache v8.2.14, Copyright (c), by Zend Technologies
Ist die Ausgabe korrekt, kann PHP8.1-fpm deaktiviert, PHP8.2-fpm installiert und aktiviert werden.
Der Restart des Webservers führt nun die Änderungen aus.
sudo service apache2 restart
Nextcloud-Konfiguration
Da in der Nextcloud nun wieder die bekannten Fehlermeldungen auftauchen, heißt es, diese schrittweise abzuarbeiten. Dazu wird die neue php.ini geöffnet
sudo nano /etc/php/8.2/fpm/php.ini
und die Werte für memory_limit sowie session_lifetime wie empfohlen angepasst.
Danach muss in der apcu.ini das Command Line Interface des PHP Cache noch aktiviert werden, indem
sudo nano /etc/php/8.2/mods-available/apcu.ini
folgende Zeile am Ende eingetragen wird.
apc.enable_cli=1
Ist dies geschehen, wird der Webserver ein letztes Mal neu gestartet.
sudo service apache2 restart
Fazit
Die Umstellung bringt zwar im Moment keine erkennbaren Vorteile, jedoch verschafft es wieder ein wenig Zeit und senkt den Druck das eigentliche Raspberry Pi OS 11 Bullseye durch die aktuelle Version 12 Bookworm zu ersetzen.
Die gestrige Veröffentlichung von Linux 6.6 bedeutet, dass das Merge-Window wieder geöffnet ist. Ein erster Kandidat wurde bereits gemerged mit einem Vorhaben, das in den vergangenen Wochen zu vielen Diskussionen geführt hat: bcachefs.
Um bcachefs zu erklären, muss ich kurz ein wenig weiter ausholen. bcachefs geht - wie der Name schon vermuten lässt - auf bcache zurück. Hierbei handelt es sich um ein Kernelmodul, das Einzug in Linux 3.10 in 2013 fand und einen Caching-Layer für Block-Devices einführte.
Daten können somit hybrid zwischen ganz schnellem Speicher (RAM), schnellem Speicher (SSDs) und langsamem Speicher (HDD) aufgeteilt werden. Werden bestimmte Blöcke häufiger abgerufen, werden sie in den schnelleren Speicher verschoben und anders herum ebenso. Dabei handelte es sich aber immer um eine Zwischenschicht, auf der ein echtes Dateisystem aufbauen musste. Während der Entwicklung fiel dem Hauptentwickler Kent Overstreet jedoch schnell auf, dass zu einem "full-fledged" Filesystem nicht mehr viel fehlte.
Ein erster Prototyp entstand bereits im Jahre 2015 und hat somit die Ära der Dateisysteme der neusten Generation eingeläutet. Auch btrfs gehört zu diesen moderneren Dateisystemen und setzt auch auf das Copy-on-Write-Prinzip. Da die Blöcke einer Datei nicht bei einer Kopie dupliziert werden, spart dies Speicherplatz und ermöglicht verzögerungsfreie Snapshots.
bcachefs mit seinen über 90.000 Zeilen Code konnte zwar - wie für ein neues Dateisystem üblich und nötig - ausgiebig getestet werden, war allerdings bisher nicht im Mainline Linux vorhanden. Mitte des Jahres ging es dann an die Einarbeitung des Codes.
Eigentlich sollte bcachefs schon in Linux 6.5 Einzug halten. Aber aufgrund andauernder Spannungen wurde auch bei Linux 6.6 aus dem Vorhaben nichts. Eines der Probleme sind die teils umfangreichen Änderungen in fremden Modulen, die den Unmut der Maintainer auf sich gezogen haben. Wer sich dafür interessiert, kann sich den großen E-Mail-Thread ansehen. Linus Torvalds stand grundsätzlich einer Übernahme positiv gegenüber, wollte aber noch einen Test in linux-next abwarten. Dies ist zwischenzeitlich geschehen.
Nun also der Merge in den Kernel. Sollten sich die Änderungen bis zum Release halten, steht somit dem Einsatz des neuen Dateisystems ab der Veröffentlichung von Linux 6.7 nicht mehr viel im Wege. Die Aufnahme in Mainline vereinfacht aber auch die Entwicklung, da diese nun nicht mehr Out-of-Tree stattfindet, was aufgrund der hohen Änderungsgeschwindigkeit im Linux-Source-Tree schnell zu aufwändigen Anpassungsarbeiten führen kann.
Weitere Informationen zu bcachefs sind auf der eigenen Homepage abrufbar. Hier ist auch eine Schnellstartanleitung für den eigenen Einsatz zu finden.
Wer sich schon einmal mit MTAs (Mail Transfer Agent) auseinandergesetzt hat, dem wird Postfix sicherlich ein Begriff sein. Postfix zählt zu den bekanntesten Mailservern im Linuxbereich, ist schnell und recht einfach zu konfigurieren, eine gewisse Grundkenntnis vorausgesetzt. Für einen sicheren Mailverkehr möchte ich hier noch einmal auf das Crypto Handbuch verweisen.
Letzte Woche war ja ein wenig Exchange Server im Programm, heute soll es aber um eine Auswertung des Mailverkehrs, welcher täglich über einen Postfix Server rauscht, gehen.
Postfix Log Entry Summarizer
Hierfür gibt es sicherlich einige Monitoring Tools, eines davon ist Pflogsumm (Postfix Log Entry Summarizer), welches eine ausführliche Auswertung bietet, ohne, dass der Anwender viel konfigurieren muss.
Unter Ubuntu ist dieses Tool recht schnell konfiguriert und im Optimalfall erhaltet ihr am Ende eine Übersicht aller Nachrichten, egal ob gesendet, empfangen oder geblockt. Auch der Traffic, die Menge oder die Mailadressen werden ausgewertet. Bis zu dieser Statistik ist aber noch ein wenig Vorarbeit zu leisten.
Pflogsumm installieren (Ubuntu)
sudo apt-get install pflogsumm
Postfix Log Entry Summarizer konfigurieren
Ihr habt nun die Möglichkeit das Tool direkt aufzurufen und euch eine Liveauswertung geben zu lassen, um zu sehen was gerade auf dem Mailserver passiert. Pflogsumm macht nichts anderes, als auf die Logfiles des Postfix Server zurückzugreifen und diese auszuwerten. Mit einem Einzeiler lässt sich so eine Statistik in eine Datei schreiben oder per Mail versenden.
sudo pflogsumm -u 5 -h 5 --problems_first -d today /var/log/mail.log >> test oder
sudo pflogsumm -u 5 -h 5 --problems_first -d today /var/log/mail.log | mail -s "Postfix Mail Report" info@example.com
Vorarbeit zur regelmäßigen Postfix Analyse
Eine IST Auswertung mag zwar interessant sein, die regelmäßige Auswertung der letzten Tage ist jedoch um einiges interessanter. Realisierbar ist dies mit den Logs des Vortages, diese werden Mittels logrotate gepackt und können danach ausgewertet werden. Zunächst muss logrotate angepasst werden, damit täglich neue Logs geschrieben werden.
Wenn gewünscht ist, dass die Logrotation pünktlich zu einer gewissen Uhrzeit laufen soll, sagen wir um 2 Uhr Nachts , ist es nötig crontab zu editieren und dort die Laufzeit anzupassen.
Nun können wir unser eigenes Script zusammen stellen, welches am Schluss eine Auswertung versendet.
sudo nano mailstatistiken.sh
#!/bin/bash
#
###############
# mailstats #
###############
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
# Log Archive entpacken
gunzip /var/log/mail.log.1.gz
#Temporaere Datei anlegen
MAIL=/tmp/mailstats
#Etwas Text zum Anfang
echo "Taeglicher Mail Stats Report, erstellt am $(date "+%H:%M %d.%m.%y")" > $MAIL
echo "Mail Server Aktivitaeten der letzten 24h" >> $MAIL
#Pflogsumm aufrufen
/usr/sbin/pflogsumm --problems_first /var/log/mail.log.1 >> $MAIL
# Versenden der Auswertung
cat /tmp/mailstats | mail -s "Postfix Report $(date --date='yesterday')" stats@example.com
#Archiv wieder packen, damit alles seine Ordnung hat
gzip /var/log/mail.log.1
Insgesamt eine leichte Übung. Das fertige Skript noch mit "chmod +x" ausführbar machen und am besten via "crontab -e" zu einem gewünschten Zeitpunkt ausführen.
Am Ende solltet ihr jeden Tag per Mail eine ausführliche Zusammenfassung der E-Mails Statistiken erhalten.
Vor kurzem gab es das „WinRAR | 9GAG Special Offer!“ und ich bin einer von 5449 Personen, die bei diesem Angebot zugeschlagen haben. Der Key gilt nicht nur für WinRAR, sondern auch für die...
Zwei neue adminForge Services können ab sofort genutzt werden. 1) Hat.sh ist eine Webanwendung, die eine sichere lokale Dateiverschlüsselung im Browser ermöglicht. Sie ist schnell, sicher und verwendet moderne kryptografische Algorithmen mit Chunked-AEAD-Stream-Verschlüsselung/Entschlüsselung. 2)...
Der Pinecil v2 kann, wie der Pinecil v1 und andere IronOS-kompatible Lötkolben, mit einem eigenen Bootlogo versehen werden. Hierfür müssen folgende Voraussetzungen erfüllt sein: Pinecil v2 mit IronOS 2.22-rc (oder neuer) Ich für diese...
Ich habe mir mit einem Odroid HC1 ein zusätzliches NAS aufgebaut, auf welchen mein Proxmox VE Server täglich sichern soll. Sofern ihr noch keinen freigegebenen Ordner, auf welchen der Proxmox VE Server am Ende...
Heute ist die erste Beta der neuen Ubuntu Version 10.10 "Maverick Meerkat" erschienen.
Das System wurde nicht nur beim Bootvorgang optimiert, sondern hat auch Updates bei GNOME (2.31), KDE(4.5.0), Xfce(4.6.2) und MythTV(0.23.1) erfahren.
Zusätzlich wurde das Softwarecenter überarbeitet, es soll schneller geworden sein und bietet eine History an. Das ganze läuft auf dem Linux Kernel 2.6.35-19.28.
Bei LinuxTrends ist eine schöne Anleitung zu finden, wie man seiner aktuellen Ubuntu Installation, dass Look & Feel eines Windows 7 aufzwingt.
Dabei wird quasi ein Gnome Theme installiert, welches alle nötigen Grafiken mit sich bringt. Wer dann mit seinem Windows Look auch noch Windows Programme nutzen will, der ist mit Wine gut bedient, welches ich letzten Monat mal kurz vorgestellt hatte.