Mozilla hat die Übernahme von Anonym bekannt gegeben. Anonym stellt Lösungen bereit, um den Erfolg digitaler Werbung in einer datenschutzfreundlichen Weise zu messen.
Mozilla hat das Unternehmen Anonym inklusive seiner 13 Mitarbeiter übernommen. Anonym wird von Mozilla als Vorreiter im Bereich der datenschutzfreundlichen digitalen Werbung beschrieben. Gegründet wurde Anonym vor etwas mehr als zwei Jahren von zwei ehemaligen hochrangigen Managern bei Meta.
Diese strategische Übernahme soll es Mozilla ermöglichen, die Messlatte für die Werbeindustrie höher zu legen, indem die Privatsphäre der Nutzer geschützt wird, während gleichzeitig trotzdem effektive Werbelösungen angeboten werden können.
Die Online-Werbebranche befindet sich in einem tiefgreifenden Wandel. Angesichts der wachsenden Bedenken der Verbraucher und der zunehmenden Kontrolle durch die Regulierungsbehörden ist es offensichtlich, dass die derzeitigen Datenpraktiken übertrieben und unhaltbar sind. Wir stehen an der Spitze eines entscheidenden Wandels in der Koexistenz von Datenschutz und Werbung, der die digitale Landschaft für Werbetreibende, Plattformen und Verbraucher umgestaltet.
In dieser Zeit des Wandels zeichnet sich Anonym durch seine einzigartige Technologie zur Wahrung der Privatsphäre aus. Durch die sichere Zusammenführung verschlüsselter Datensätze von Plattformen und Werbetreibenden ermöglicht Anonym eine skalierbare, datenschutzkonforme Messung und Optimierung von Werbekampagnen und führt damit einen Wandel hin zu einem nachhaltigeren Werbe-Ökosystem herbei.
Und so funktioniert es:
Sichere Umgebung: Die Datensätze werden in einer hochsicheren Umgebung abgeglichen, um sicherzustellen, dass Werbetreibende, Publisher und Anonym keinen Zugriff auf Daten auf Nutzerebene haben.
Anonymisierte Analysen: Der Prozess führt zu anonymisierten Erkenntnissen und Modellen, die Werbetreibenden helfen, die Kampagnenleistung zu messen und zu verbessern, während die Privatsphäre der Verbraucher geschützt wird.
Differenzielle Datenschutz-Algorithmen: Diese Algorithmen fügen den Daten ein „Rauschen“ hinzu, das verhindert, dass die Daten zu einzelnen Nutzern zurückverfolgt werden können.
Diese Übernahme ist ein wichtiger Schritt, um den dringenden Bedarf an datenschutzfreundlichen Werbelösungen zu decken. Durch die Kombination der Größe und des guten Rufs von Mozilla mit der Spitzentechnologie von Anonym können wir die Privatsphäre der Nutzer und die Effektivität der Werbung verbessern und so die Wettbewerbsbedingungen für alle Beteiligten angleichen.
Anonym wurde mit zwei Grundüberzeugungen gegründet: Erstens, dass Menschen ein grundlegendes Recht auf Privatsphäre bei Online-Interaktionen haben und zweitens, dass digitale Werbung für die Nachhaltigkeit von kostenlosen Inhalten, Diensten und Erlebnissen entscheidend ist. Mozilla und Anonym teilen die Überzeugung, dass fortschrittliche Technologien relevante und messbare Werbung ermöglichen können, ohne die Privatsphäre der Nutzer zu verletzen.
Mozilla
Anonym wird als eigene Einheit innerhalb der Mozilla Corporation operieren, um neue Lösungen für datenschutzfreundliche Messung, Targeting und Optimierung zu entwickeln. Das Hauptaugenmerk im nächsten Jahr wird aber zunächst auf der Markteinführungs-Strategie liegen, einschließlich der Einstellung von weiteren Mitarbeitern und der Erweiterung der bestehenden Produkte von Anonym.
Mozilla hat Firefox Klar 127 (internationaler Name: Firefox Focus 127) für Apple iOS veröffentlicht. Die neue Version steht im Apple App Store zum Download bereit.
Bei Firefox Klar 127 für Apple iOS handelt es sich um ein Wartungs-Update, welches ausschließlich Verbesserungen unter der Haube bringt.
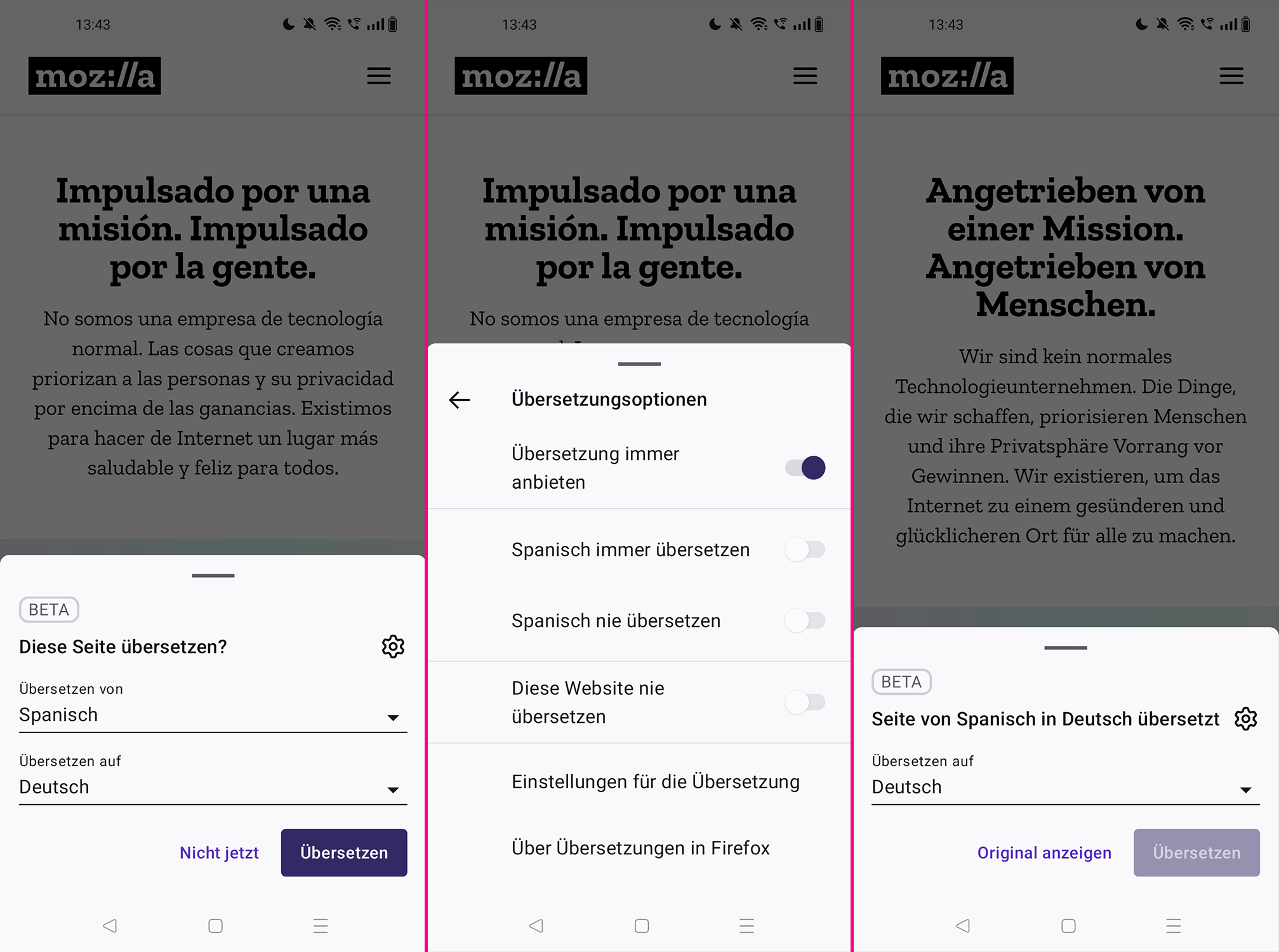
Mozilla hat Firefox 127 für Android veröffentlicht. Dieser Artikel beschreibt die Neuerungen von Firefox 127 für Android. Highlights sind eine lokale Übersetzungsfunktion, verbesserte Lesezeichen auf dem Startbildschirm, sortierbare private Tabs sowie Performance-Verbesserungen.
Firefox für Windows, Apple macOS und Linux wird bereits seit Version 118 mit einer lokalen Funktion zur maschinellen Übersetzung von Websites für den Browser ausgeliefert. Das bedeutet, dass die Übersetzung vollständig im Browser geschieht und keine zu übersetzenden Inhalte an einen Datenriesen wie Google oder Microsoft übermittelt werden müssen. Firefox 127 bringt die Funktion auch auf Android. Weitere Verbesserungen dieser Funktion sowie die Unterstützung zusätzlicher Sprachen sollen folgen.
Diese Neuerung wird schrittweise im Laufe der kommenden Wochen für alle Nutzer ausgerollt werden.
Verbesserte Lesezeichen auf Startbildschirm
Aus dem optionalen Bereich „Neueste Lesezeichen“ für den Firefox-Startbildschirm wurde der Bereich „Lesezeichen“. Aber hinter dieser subtilen Änderung der Bezeichnung steckt mehr: Es werden nicht länger nur aktuelle Lesezeichen angezeigt. Bislang waren die Lesezeichen zehn Tage nach dem Hinzufügen nicht mehr in diesem Bereich angezeigt worden. Außerdem wurde die maximale Anzahl an Lesezeichen in diesem Bereich von vier auf acht verdoppelt.
Sortierbare private Tabs
Die Tabübersicht wurde komplett neu auf Basis neuester Android-Standards implementiert. Während diese Änderung für den Nutzer komplett transparent sein sollte, also im Vergleich zu vorher gleich aussieht und funktioniert, hat sich daraus doch auch eine funktionale Neuerung ergeben: Bereits bisher war es möglich, die Reihenfolge von Tabs durch Halten und Schieben zu verändern. Dies hatte allerdings nur für nicht private Tabs funktioniert. Jetzt funktioniert dies sowohl für nicht private als auch für private Tabs.
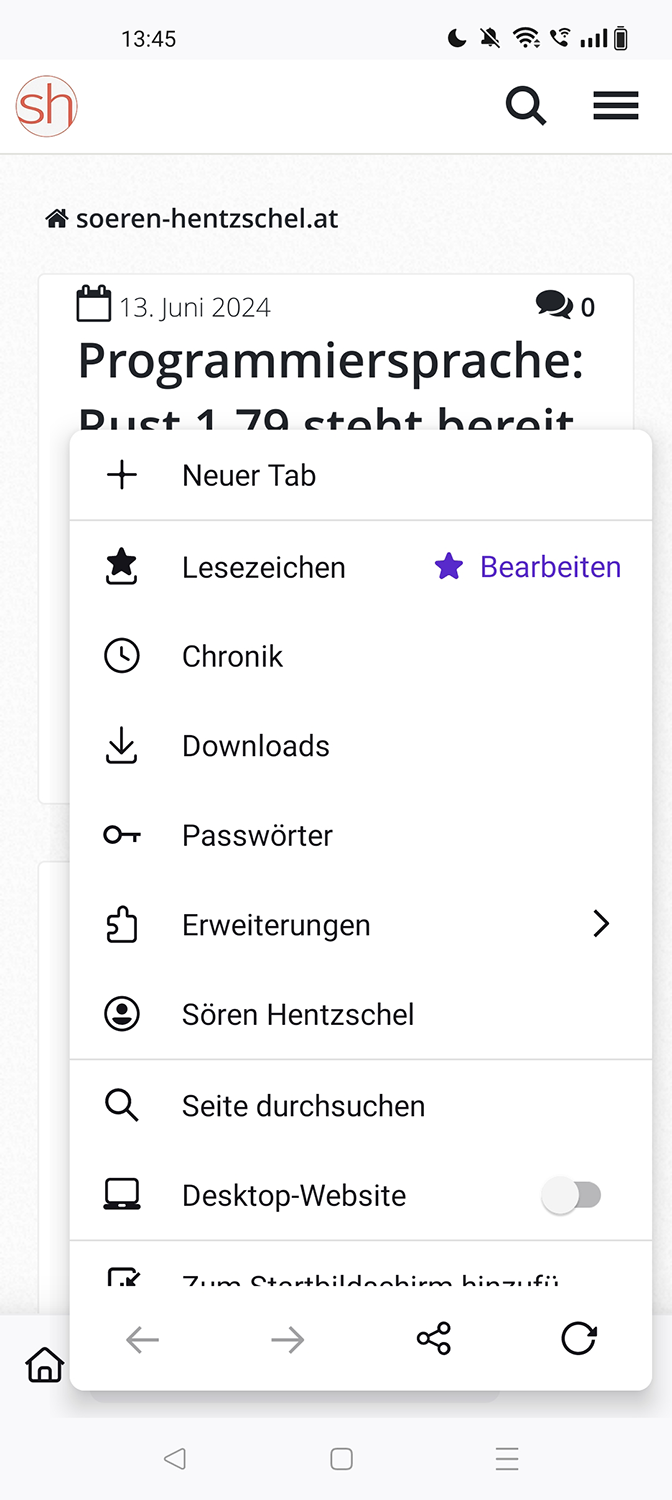
Zugriff auf gespeicherte Passwörter
Auf gespeicherte Zugangsdaten kann nun schneller zugegriffen werden, weil ein neuer Menüpunkt „Passwörter“ direkt in das Hauptmenü integriert worden ist.
Der Dialog, der nach dem Absenden eines Formulars das Speichern eines Passworts vorschlägt, verschwindet jetzt erst von alleine, wenn man in diesem Tab auf eine andere Domain navigiert. Durch Weiterleitungen seitens Websites konnte es bisher passieren, dass Nutzer damit nicht mit dieser Funktion interagieren konnten.
Performance-Verbesserungen
Mozilla hat die Compiler-Einstellungen optimiert. Für den Preis einer erhöhten Dateigröße von mehreren Megabytes wurden dadurch die Startgeschwindigkeit von Firefox, die Ladezeiten von Websites wie auch die Akkulaufzeit spürbar verbessert.
Sonstige Neuerungen
Der Zahlenblock einer physischen Tastatur kann jetzt auch verwendet werden, um in der Adressleiste eingegebene URLs zu bestätigen. Außerdem wird die „Vorwärts“-Taste von physischen Mäusen jetzt für die Navigation unterstützt.
Ansonsten gibt es wie immer neue Plattform-Features der aktuellen GeckoView-Engine, diverse Fehlerbehebungen, geschlossene Sicherheitslücken sowie Verbesserungen unter der Haube.
In diesem Video zeigt Jean Dir Alternativen zu Whatsapp, Teams, Zoom und co. Kommuniziere sicher und schütze dabei deine Daten mit diesen sicheren Messengern und Kommunikationsplattformen.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
Video zu Element: https://www.youtube.com/watch?v=qz85QdBlu9g&t=394s
Microsoft Alternativen: https://www.youtube.com/watch?v=baDiksxu-f8
Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Offizielle Webseite: https://www.linuxguides.de
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Mastodon: https://mastodon.social/@LinuxGuides
X: https://twitter.com/LinuxGuides
Instagram: https://www.instagram.com/linuxguides/
Kontakt: https://www.linuxguides.de/kontakt/
0:00 Begrüßung
0:52 Warum wechseln?
2:29 Alternativen zu Whatsapp
2:32 Signal
3:54 Element
6:54 Threema
7:47 Tipps zum Umstieg
10:33 Meinung zu Telegram
11:32 Alternativen zu Teams, slack, Zoom
12:04 Element im Unternehmen
13:31 Jitsi (Videokonferenzen)
14:09 Big blue button
14:49 Nextcloud (Datei-Sharing)
15:24 Mattermost und Rocketchat
16:36 Kommunikation per E-Mail
17:21 E-Mail Verschlüsselung
17:59 Verabschiedung
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Kurz notiert: Die Programmiersprache Rust steht ab sofort in Version 1.79 bereit.
Die Programmiersprache Rust wurde planmäßig in Version 1.79 veröffentlicht. Wer sich für alle Highlights der neuen Version interessiert, findet wie immer in der offiziellen Release-Ankündigung weitere Informationen.
Mozilla hat Firefox Klar 127 (internationaler Name: Firefox Focus 127) für Android veröffentlicht.
Die Neuerungen von Firefox Klar 127 für Android
Bei Firefox Klar 127 handelt es sich um ein Wartungs-Update, bei welchem der Fokus auf Fehlerbehebungen und Verbesserungen unter der Haube lag. Dazu kommen wie immer neue Plattform-Features der aktuellen GeckoView-Engine sowie geschlossene Sicherheitslücken.
Linux und Open Source Anwendungen für Autoren - Schriftsteller benutzen für die Erstellung von Romanen Autorenpgrogramme. Autorenprogramme sind spezielle Schreibprogramme für Autoren und Schriftsteller. Für Linux ist die Auswahl derartiger Anwendungen leider begrenzt. Bibisco läuft unter Linux (Debian, Ubunrtu, Fedora, Snap, Flatpak), Windows und auch MacOS. Da es zudem eine kostenfreie Version gibt, stellt es eine Alternative für angehende Autoren dar , die auch einmal ein Autorenpgrogramm ausprobierten möchten und keine herkömmliche Textverarbeitung wie Libre Office oder Word nutzen wollen.
Im Video zeige ich die wesentlichen Funktionsmerkmale von Bibisco.
🖋️ Zu meinem Gruselroman "Die Rache des Legionärs"
▶️ https://www.amazon.de/dp/B0CWTPBKW2?asin=B0CWTPBKW2&revisionId=c1fbf2dd&format=1&depth=1
Linux Bücher für Einsteiger von mir (Ebook und Taschenbuch):
▶️ https://www.amazon.de/~/e/B001K73R84
Brandneu: Linux Mint 21 - Schnellanleitung für Einsteiger
▶️ https://www.amazon.de/dp/B0BB9LGMPG
Weitere Videos zu Linux Distributionen findet Ihr in dieser Playlist:
▶️ https://www.youtube.com/watch?v=sdYcdG4mn98&list=PLl0zRfPkQ7Xu86XQgKbUhVRSBbHpUzxxM
Andere Kanäle von mir:
Joe loves Linux ▶️ https://www.youtube.com/channel/UCdI8plWGpNHwN1oswHi3iWA
Raketenheftleser ▶️ https://www.youtube.com/channel/UCyPNZr7yK8278QXQDMFnQag
Joe's Musik Check ▶️ https://www.youtube.com/channel/UCuB7gdAs73msDRUnlRRKv5Q
JJ Fotoshow ▶️ https://www.youtube.com/c/JoeTravels
Mozilla hat Firefox 127 für Windows, Apple macOS und Linux veröffentlicht. Dieser Artikel fasst die wichtigsten Neuerungen zusammen – wie immer auf diesem Blog weit ausführlicher als auf anderen Websites.
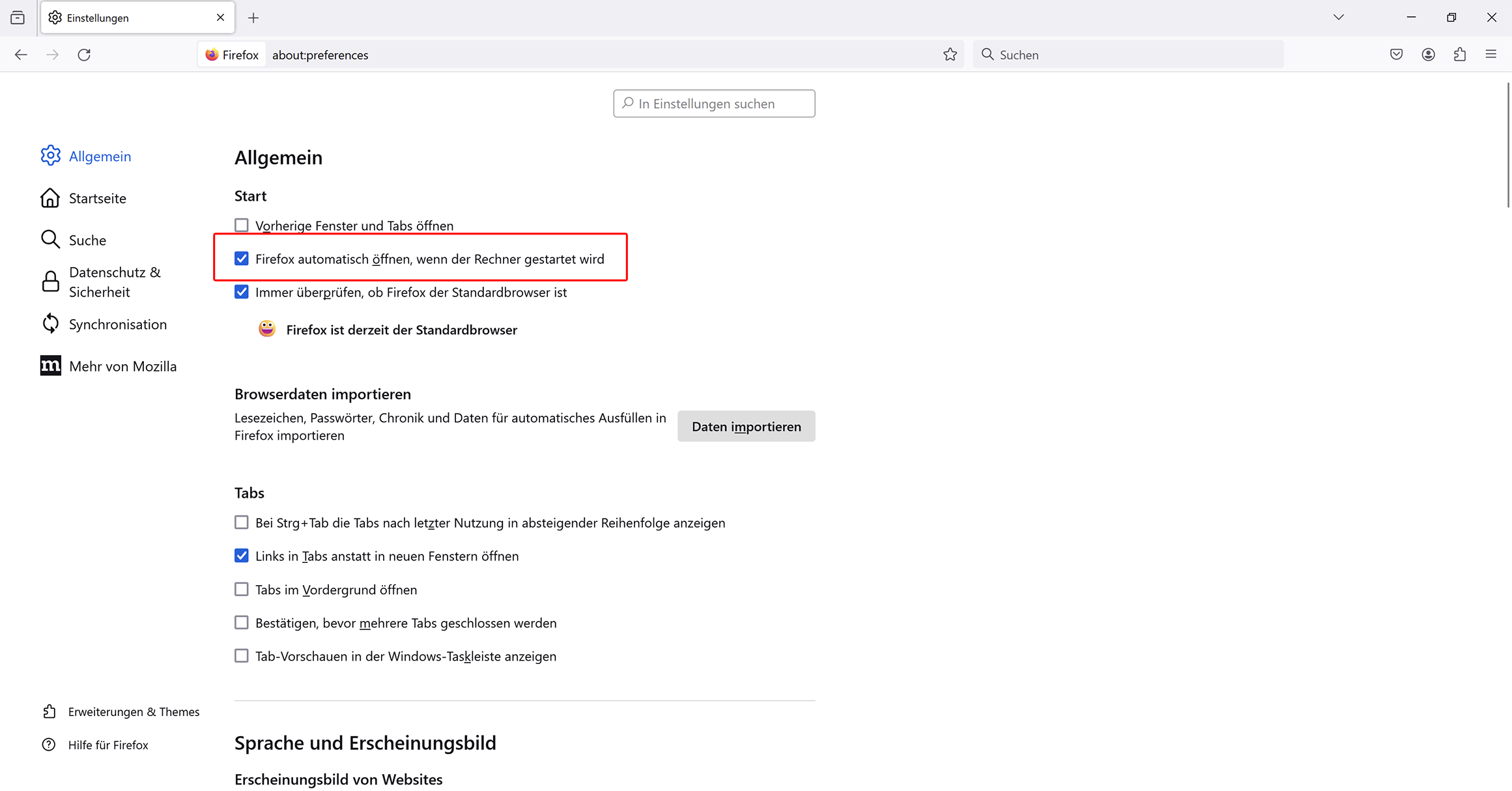
Firefox automatisch starten, wenn Windows gestartet wird
Bereits seit Firefox 120 wurde eine neue Option schrittweise ausgerollt, um den Browser automatisch zu starten, wenn Windows gestartet wird. Diese Option steht nun für alle Nutzer zur Verfügung (außer bei Verwendung von Firefox aus dem Microsoft Store).
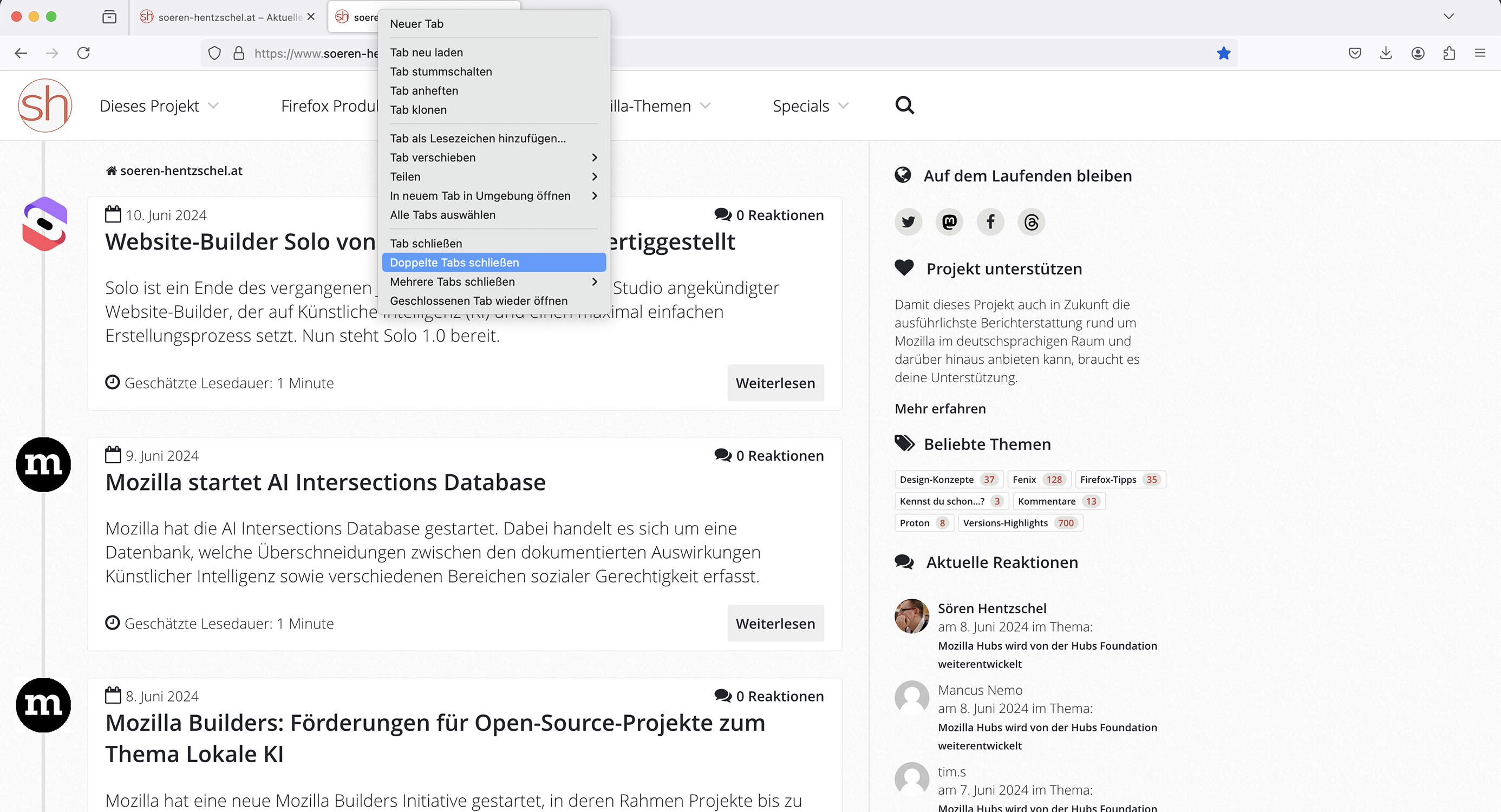
Schnelles Schließen identischer Tabs
Manchmal kommt es vor, dass man bestimmte Websites mehrfach geöffnet hat. Gerade mit einer größeren Anzahl offener Tabs kann dies sehr leicht passieren. Ein neuer Eintrag im Kontextmenü der Tabs erlaubt es, sämtliche Duplikate des ausgewählten Tabs zu schließen. Im „Alle Tabs auflisten“-Menü in der Tableiste gibt es einen neuen Menüeintrag, um alle doppelten Tabs zu schließen. So muss man nicht länger nach anderen Tabs mit gleicher URL suchen, um diese zu schließen.
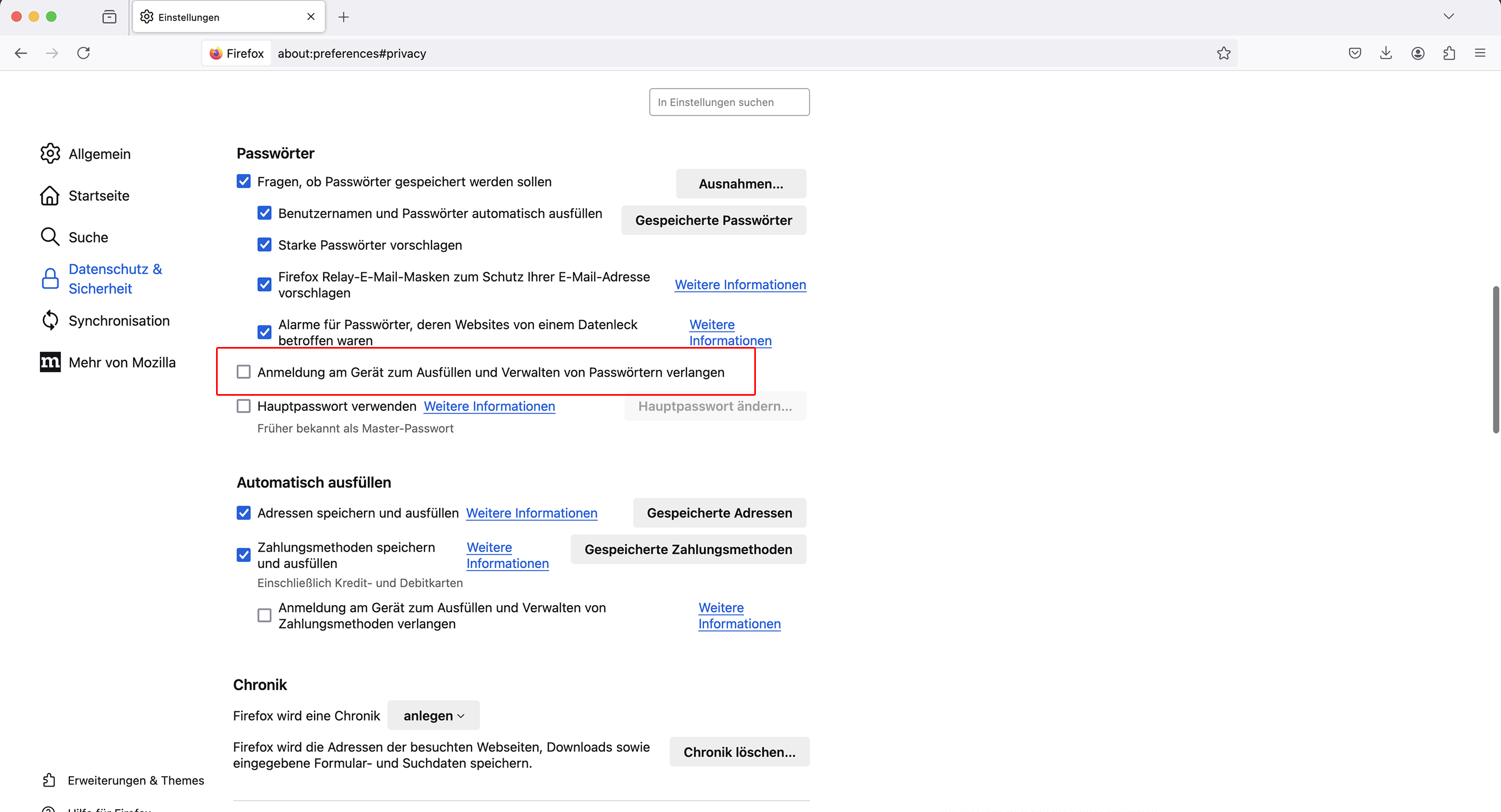
Schutz der gespeicherten Zugangsdaten
Auf Windows und Apple macOS kann der Zugriff auf gespeicherte Zugangsdaten sowie das Anlegen derer jetzt optional durch die Authentifizierung des Betriebssystems (Passwort, Fingerabdruck, Gesichts- oder Stimmerkennung) geschützt werden.
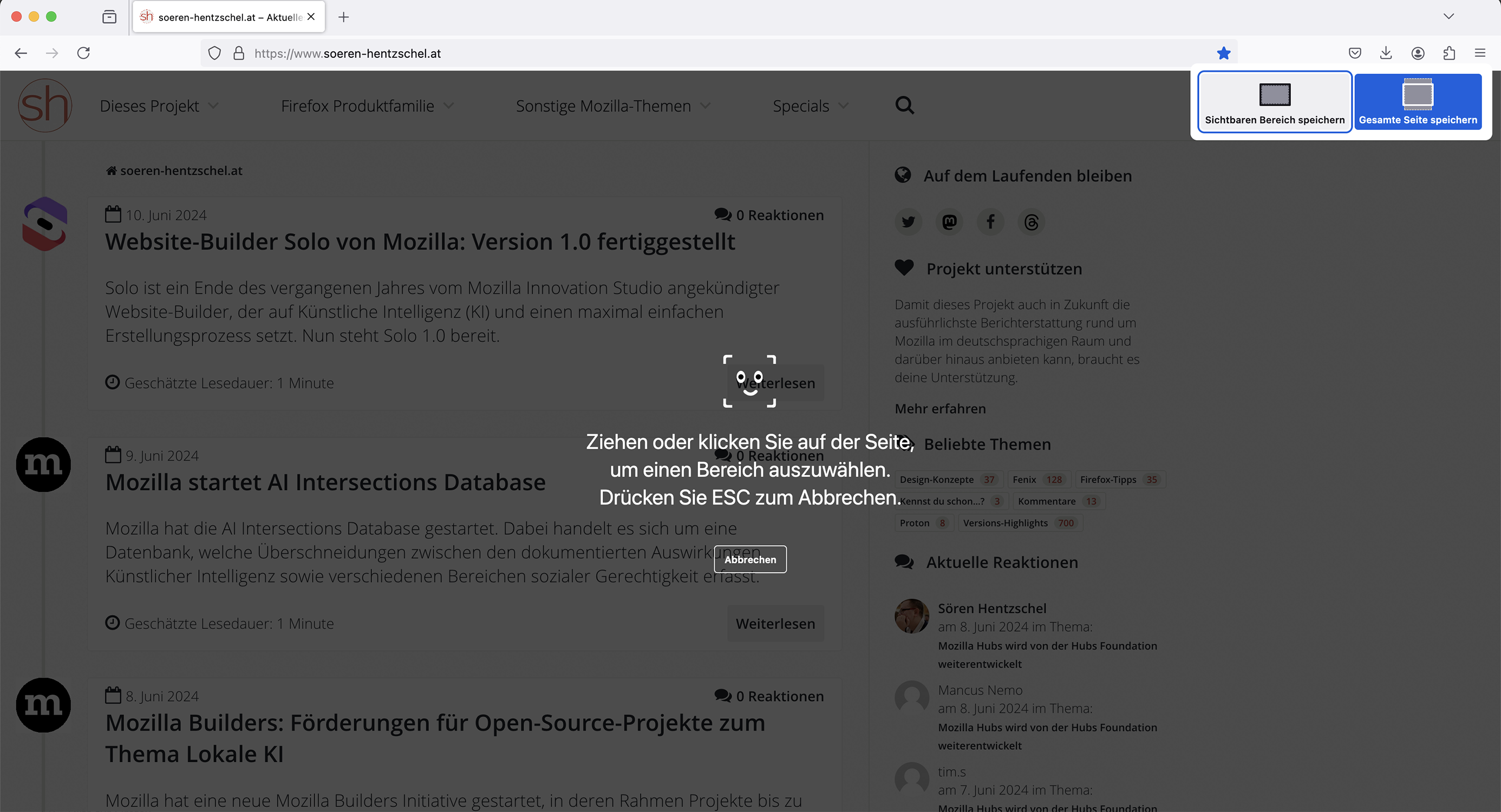
Verbesserte Screenshot-Funktion
Die Screenshot-Funktion von Firefox wurde neu implementiert, was diverse Vorteile bringt. So sind jetzt auch Screenshots von Dateitypen wie SVG und XML möglich, ebenso Screenshots von den internen about:-Seiten, was bislang nicht möglich war. Neue Tastatur-Kurzbefehle sowie Kompatibilität mit Hochkontrastthemen verbessern die Zugänglichkeit. Außerdem wurde die Performance beim Aufnehmen großer Screenshots verbessert. Auch steht der entsprechende Kontextmenü-Eintrag jetzt auch bei Rechtsklick auf Bilder und Videos zur Verfügung.
Host-Berechtigungen bei Installation von MV3-Erweiterungen
Sogenannte Host-Berechtigungen sind seit dem Manifest v3 für Firefox-Erweiterungen grundsätzlich optional. Ab Firefox 127 werden die Host-Berechtigungen automatisch bei Installation der Erweiterung gewährt. Details zu dieser Neuerung wurden in einem separaten Artikel ausführlich behandelt.
Sonstige Endnutzer-Neuerungen von Firefox 127
Die Untertitel-Option der Bild-im-Bild-Funktion für Videos unterstützt ab sofort noch mehr Websites.
Wenn Firefox so konfiguriert ist, dass keine Chronik gespeichert wird, wird für die Priorisierung von Vorschlägen in der Adressleiste jetzt die Anzahl der Lesezeichen für die jeweilige Domain als Kriterium herangezogen.
Links und andere fokussierbare Elemente sind unter Apple macOS standardmäßig über Tabs navigierbar, anstatt der macOS-Einstellung „Tastaturnavigation“ zu folgen. Dies ist ein besser zugänglicher Standard und entspricht außerdem dem Standard auf den anderen Desktop-Plattformen. Eine Option in den Einstellungen erlaubt es, das alte Verhalten wiederherzustellen.
Zwecks Reduzierung des digitalen Fingerabdrucks und Webkompatibilitätsproblemen wurde die CPU-Architektur im User-Agent unter Linux eingefroren und zeigt jetzt unabhängig von der tatsächlichen Hardware auch für 32-Bit-Systeme x86_64 an.
Über die Entwicklerwerkzeuge aufgenommene Screenshots landen zukünftig wie Screenshots, welche über die Screenshot-Funktion aufgenommen werden, im Downloads-Ordner statt im Ordner für Bilder.
Mehr Sicherheit für Firefox-Nutzer
Auch in Firefox 127 wurden wieder mehrere Sicherheitslücken geschlossen. Alleine aus Gründen der Sicherheit ist ein Update auf Firefox 127 daher für alle Nutzer dringend empfohlen.
Via http:// eingebettete <img>-, <audio>– sowie <video>-Elemente auf Seiten, welche via https:// geladen werden, werden jetzt automatisch auch via https:// geladen, sofern diese Elemente via https:// aufrufbar sind. Wenn dies nicht der Fall ist, werden die Elemente nicht länger geladen.
Alte Erweiterungen, welche nur mit dem SHA-1-Algorithmus signiert worden sind, lassen sich nicht länger installieren. Sämtliche Erweiterungen, welche auf addons.mozilla.org angeboten werden und zuletzt vor April 2019 aktualisiert worden und damit betroffen sind, wurden durch Mozilla automatisch neu signiert.
Verbesserungen der Webplattform
DNS-Prefetching für HTTPS-Dokumente via rel="dns-prefetch" wird jetzt unterstützt, um Domain-Namen für wichtige Assets anzugeben, die präventiv aufgelöst werden sollen.
Firefox 127 unterstützt die Clipboard API, welche die Möglichkeit bringt, auf Zwischenablagebefehle (Ausschneiden, Kopieren und Einfügen) zu reagieren sowie asynchron aus der Systemzwischenablage zu lesen und in diese zu schreiben. Beim Versuch, Inhalte aus der Zwischenablage zu lesen, die nicht von einer Seite gleichen Ursprungs stammen, wird ein Kontextmenü zum Einfügen angezeigt, das der Benutzer bestätigen muss.
Für Sets in JavaScript wurden mehrere neue Methoden wie unter anderem intersection(), union() und difference() implementiert.
Auch für Entwickler von Firefox-Erweiterungen gab es Neuerungen. Alle Neuerungen für Entwickler von Websites und Firefox-Erweiterungen lassen sich in den MDN Web Docs nachlesen.
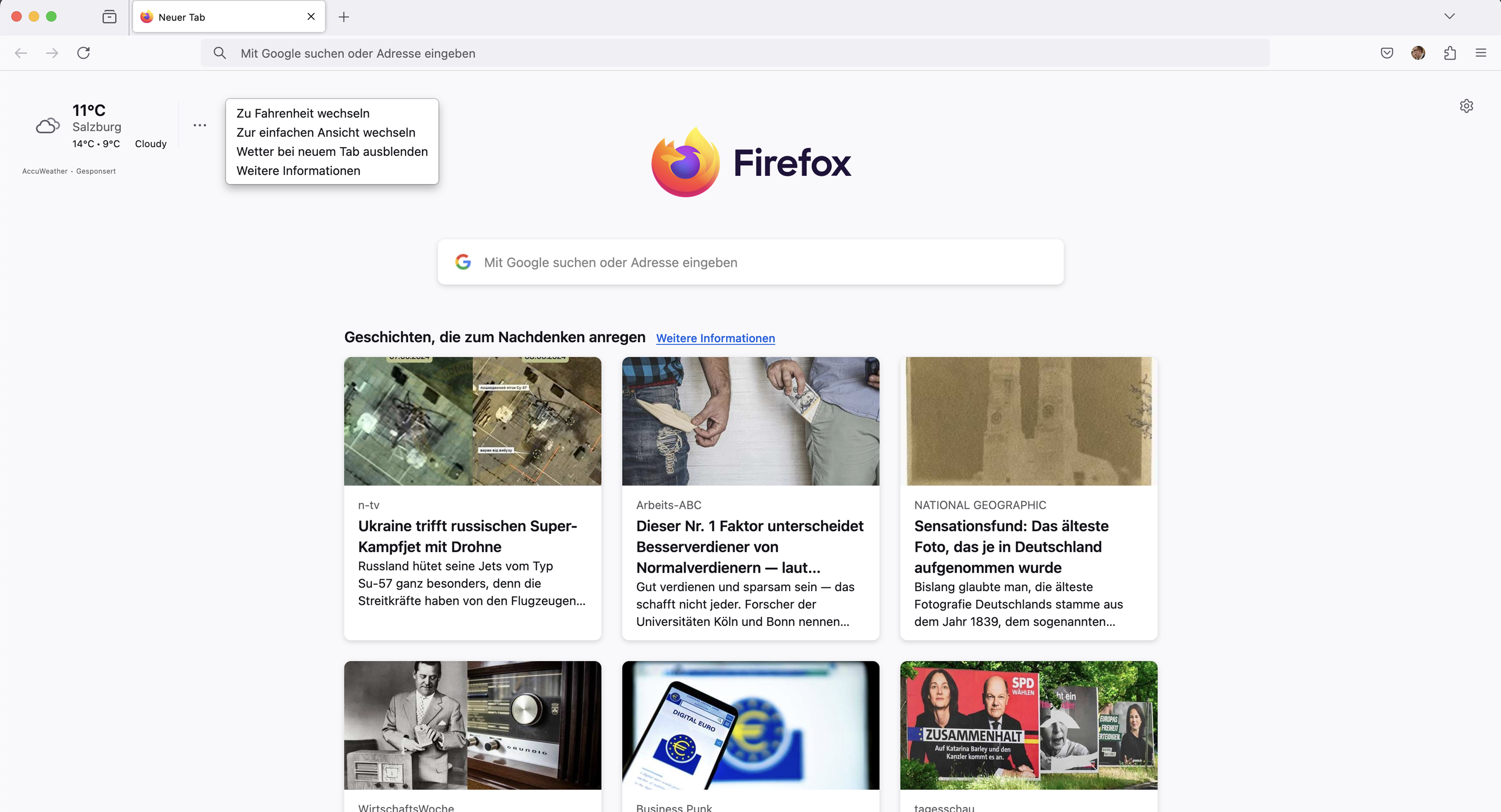
Vorschau: Wetter auf der Firefox-Startseite
Wird über about:config der Schalter browser.newtabpage.activity-stream.system.showWeather per Doppelklick auf true gestellt, kann das aktuelle Wetter auf der Firefox-Startseite angezeigt werden. Über das entsprechende Menü lassen sich Temperatur-Einheit sowie Darstellungs-Modus anpassen. Sollte der automatisch erkannte Ort nicht passen, müssen Nutzer auf Firefox 128 warten. Denn dann lässt sich der Ort auch manuell auswählen.
Solo ist ein Ende des vergangenen Jahres vom Mozilla Innovation Studio angekündigter Website-Builder, der auf Künstliche Intelligenz (KI) und einen maximal einfachen Erstellungsprozess setzt. Nun steht Solo 1.0 bereit.
Im Rahmen der Innovation Week im Dezember 2023 hatte das Mozilla Innovation Studio Solo angekündigt. Dabei handelt es sich um einen sogenannten Website-Builder mit Fokus auf Selbständige, der auf generative Künstliche Intelligenz für einen maximal einfachen Erstellungsprozess setzt.
Seit dem Start hat Mozilla einige Funktionen ergänzt. Jetzt hat Mozilla Solo 1.0 fertiggestellt. Neu ist unter anderem eine Option zum Aktivieren eines ganz simplen Cookie-Banners. Außerdem gibt es eine Option für einen fixierten Header, Threads von Meta wurde als Option zu den Social-Media-Kanälen hinzugefügt und die Labels in Kontaktformular können jetzt auch auf Deutsch oder Italienisch eingestellt werden. Dies war nur eine kleine Auswahl der Neuerungen. Die vollständigen Release Notes:
Version 1.0
Added a new fixed header option so you can have the Navigation bar always show as you scroll
You can now add up to 3 Text Banner and Image Banner sections
Added Threads as a new social media type
Option to now add an image to your Text Banner sections
Improved custom domain connection handling
Multiple visual UI improvements
Squashed a lot of small bugs including a general site speed-up
Slowed down transition time for gallery photos in carousel
Added multiple new animations to published sites giving it a more polished feel
Increased custom image upload cap to 30
New “centered” layout option for Footer text and social media icons
Increased character limit for the Services section items
Added Italian and German as new language options for the Contact Form labels
Die Nutzung von Solo ist kostenlos. Geringe Kosten fallen höchstens bei Verwendung einer benutzerdefinierten Domain an. In Zukunft könnten gegen eine monatliche Gebühr aber auch zusätzliche Funktionen bereitgestellt werden. Als Nächstes stehen weitere Optionen zum Bearbeiten und Gestalten sowie benutzerdefinierte Favicons auf der Roadmap.
Das Training auf einer virtuellen Maschine mit Fedora 40 Server, 10 CPU-Threads und 32 GB RAM dauerte 180 Std. 44 Min. 7 Sek. Ich halte an dieser Stelle fest, ohne GPU-Beschleunigung fehlt es mir persönlich an Geduld. So macht das Training keinen Spaß.
Nach dem Training mit ilab train findet man ein brandneues LLM auf dem eigenen System:
(venv) tronde@instructlab:~/src/instructlab$ ls -ltrh models
total 18G
-rw-r--r--. 1 tronde tronde 4.1G May 28 20:34 merlinite-7b-lab-Q4_K_M.gguf
-rw-r--r--. 1 tronde tronde 14G Jun 6 12:07 ggml-model-f16.gguf
Test des neuen Modells
Den Chat mit dem LLM starte ich mit dem Befehl ilab chat -m models/ggml-model-f16.gguf. Das folgende Bild zeigt zwei Chats mit jeweils unterschiedlichem Ergebnis:
Zwei Chats mit dem frisch trainierten LLM. Beide Male erhalte ich nicht die erhoffte Antwort.
Fazit
Schade, das hat nicht so funktioniert, wie ich mir das vorgestellt habe. Es kommt weiterhin zu KI-Halluzinationen und nur gelegentlich gesteht das LLM seine Unkenntnis bzw. seine Unsicherheit ein.
Für mich sind damit 180 Stunden Rechenzeit verschwendet. Ich werde bis auf Weiteres keine Trainings ohne Beschleuniger-Karten mehr durchführen. Jedoch werde ich mir von Zeit zu Zeit aktualisierte Releases der verfügbaren Modelle herunterladen und diesen Fragen stellen, deren Antworten ich bereits kenne.
Wenn sich mir die Gelegenheit bietet, diesen Versuch auf einem Rechner mit entsprechender GPU-Hardware zu wiederholen, werde ich die Erkenntnisse hier im Blog teilen.
In diesem Video zeigt Jean, wie man auf seinem Linux-Betriebssystem am Besten mit PDF-Dateien umgeht. Du erfährst, wie man PDFs neu ordnen, bearbeiten oder zu Word-Dateien konvertieren kann und wie man Formulare einfach erstellen und ausfüllen kann.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
Erstes Video zu PDF: https://www.youtube.com/watch?v=ZmjcFj-8EUw
PDF zu Word konvertieren: https://www.adobe.com/de/acrobat/online/pdf-to-word.html
PDF-Beispiel: https://linuxmint.com/documentation/user-guide/Cinnamon/german_18.1.pdf
Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Offizielle Webseite: https://www.linuxguides.de
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Mastodon: https://mastodon.social/@LinuxGuides
X: https://twitter.com/LinuxGuides
Instagram: https://www.instagram.com/linuxguides/
Kontakt: https://www.linuxguides.de/kontakt/
Inhaltsverzeichnis:
-------------------------------------
0:00 Begrüßung
1:02 PDF-Seiten zusammenfügen und neu ordnen
5:35 PDF-Dateien bearbeiten
6:40 Zu Word konvertieren
8:23 PDF bearbeiten: Alternative zu LibreOffice Draw
10:41 Formulare erstellen
14:48 Formulare ausfüllen
16:28 Verabschiedung
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Wer bist du, wie kommst du zur Stadt Dortmund und was tust du?
Ich bin Katharina Flisikowski und seit Kurzem im CIIO – Chief Information/Innovation Office der Stadt Dortmund für Digitale Souveränität und Open Source zuständig. Meinen Background habe ich in den Medien- und Sozialwissenschaften.
In der Vergangenheit habe ich im Projektmanagement gearbeitet sowie im Bereich Kommunikation und Transfer. Mehrere Jahre lang besetzte ich die Stabsstelle Qualität und Kommunikation eines interkulturellen Trägers der Sozialen Arbeit, wo ich viel über Organisationsstrukturen sowie die Optimierung von Prozessen gelernt habe.
Meine letzte Station war ein Leibniz-Projekt am Deutschen Bergbau-Museum Bochum. Dort entwickelte ich Konzepte für den Transfer von Wissen zwischen Forschung und Bürger*innen. Mit dem Ende des Projekts wollte ich mich weiterhin für einen offenen Zugang zu Wissen einsetzen. Passenderweise fiel das in die Zeit, in der die Stelle der Stadt Dortmund ausgeschrieben war – und hier bin ich nun!
Was begeistert dich am Thema Open Source?
Mich motiviert der Gedanke an eine starke, gleichberechtigte und selbstbestimmte Gesellschaft.
Aktuelle Entwicklungen, wie etwa Angriffe auf Infrastrukturen oder aber auch das Schüren von Ängsten durch Fake News und Verschwörungserzählungen, stellen dabei reale Gefährdungen dar, denen eine Demokratie wehrhaft begegnen muss.
Daher ist es für uns unerlässlich, die Fragen zu stellen: Wie wird Wissen hergestellt und verbreitet? Wie transparent sind Strukturen? Haben wir als Gesellschaft die Handlungsfähigkeit, die wir brauchen, um uns sicher und stark im physischen und digitalen Raum zu bewegen? Und wie schaffen wir es, uns technologisch und gesellschaftlich weiter- und nicht zurückzuentwickeln?
Als ein Teil Digitaler Souveränität bietet Open Source hierbei einen Ansatz, der in eben diese Richtung geht: Durch das Teilen von Wissen (über den Code hinaus) entsteht eine Transparenz, die Vertrauen schafft. Der multiple Blick auf Lösungen gibt einerseits Sicherheit, andererseits macht er Innovation und somit Fortschritt möglich. So werden wir als Gesellschaft zur selbstbestimmten Gestalterin unserer Zukunft – was will man mehr!
Einen weiteren Aspekt, den ich an Open Source sehr schätze, ist der Community-Gedanke: Ich finde es erstrebenswert, gemeinsam an Lösungen zu wirken, anstatt im Alleingang oder gar in Rivalität zu tüfteln und dann doch das Rad immer wieder neu zu erfinden. Kooperation und Kollaboration bringen uns hier viel weiter.
Was sind deine ersten Schritte als Koordinatorin für Digitale Souveränität und Open Source bei der Stadt Dortmund?
Da ich selbst nicht aus Dortmund komme, nutzte ich die erste Zeit dafür, die Stadt und die Menschen, die sie ausmachen, kennenzulernen. Dazu gehört auch, die Entwicklungen der Stadt Dortmund im Hinblick auf Digitale Souveränität zu betrachten, schließlich gibt es schon einige Ansätze und politische Beschlüsse in diese Richtung.
Als Nächstes geht es darum, aus dieser Bestandsaufnahme einen Fahrplan zu entwickeln. Hier freue ich mich darauf, in den Austausch mit einzelnen Akteur*innen zu treten, sowohl inner- als auch außerhalb der Dortmunder Stadtverwaltung. Die ersten Gespräche fanden bereits statt, nun gilt es, diese Kontakte zu vertiefen und weitere zu knüpfen.
Angesichts der ständigen Weiterentwicklung von Technologie und Gesetzgebung, wie hast du vor auf dem neuesten Stand zu bleiben und wie beeinflusst dies deine Herangehensweise an deine Projektplanung und -umsetzung im Bereich Digitaler Souveränität und Open Source?
Hier ist Netzwerk das Stichwort – Open Source lebt vom Community-Gedanken und genau hierin sehe ich auch die Stärke: Mit einem Pool an unterschiedlichen Expertisen, Erfahrungen und Blickwinkeln ist es möglich, verschiedene Aspekte zu durchleuchten und so zu neuen Erkenntnissen zu gelangen. Ich bin ein großer Fan des interdisziplinären Austauschs, weil man so voneinander lernen und sich weiterentwickeln kann. Wissen und Erfahrung sind wertvolle Ressourcen – diese zu teilen wiederum macht uns als Gesellschaft stark.
Was ist deine Hoffnung an deine neue Stelle für dich selbst, aber auch für die Aufgabe?
Ich hoffe, dass wir gemeinsam mit den vielen Beteiligten, Interessierten ebenso wie den noch nicht ganz Überzeugten einen Weg finden, das Thema Digitale Souveränität in unsere Alltagspraxis fest zu verankern. Für die Stadt Dortmund sind die ersten Weichen ja bereits gestellt, nun gilt es, das Triebwerk zu befeuern und Fahrt aufzunehmen.
Dabei geht es nicht darum, so schnell wie möglich und um jeden Preis sämtliche Strukturen abzulösen. Vielmehr geht es darum, Wahlmöglichkeiten und Handlungsspielräume zu erweitern, die Menschen mitzunehmen und ein Bewusstsein für Abhängigkeiten zu schaffen.
Persönlich erhoffe ich mir, dass wir mit unserer Arbeit einen Beitrag für eine sichere, wehrhafte und selbstbestimmte Gesellschaft leisten. Ich bin mir sicher, dass wir dem gemeinsam in einem großen Netzwerk, dem Ökosystem der Digitalen Souveränität, einen Schritt näherkommen.
Ich freue mich darauf, daran mitzuwirken!
Wir wünschen uns allen viel Erfolg bei der Umsetzung von Open-Source-first und freuen uns auf die konkrete Zusammenarbeit!
Soweit im gesetzlichen Rahmen möglich verzichtet der Autor auf alle Urheber- und damit verwandten Rechte an diesem Werk.
Es kann beliebig genutzt, kopiert, verändert und veröffentlicht werden.
Für weitere Informationen zur Lizenz, siehe hier.
Heute Abend klären wieder Hauke und Jean Deine Fragen live!
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
--------------------
Links:
Frage stellen: https://ask.linuxguides.de
Forum: https://forum.linuxguides.de/
Haukes Webseite: https://goos-habermann.de/index.php
Nicht der Weisheit letzter Schluß: youtube.com/@nichtderweisheit
Linux Guides Admin: https://www.youtube.com/@LinuxGuidesAdmin
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Ubuntu Kurs für Anwender*: https://www.linuxguides.de/ubuntu-kurs-fuer-anwender/
Linux für Fortgeschrittene*: https://www.linuxguides.de/linux-kurs-fuer-fortgeschrittene/
Offizielle Webseite: https://www.linuxguides.de
Tux Tage: https://www.tux-tage.de/
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Twitter: https://twitter.com/LinuxGuides
Mastodon: https://mastodon.social/@LinuxGuides
Matrix: https://matrix.to/#/+linuxguides:matrix.org
Discord: https://www.linuxguides.de/discord/
Kontakt: https://www.linuxguides.de/kontakt/
BTC-Spende: 1Lg22tnM7j56cGEKB5AczR4V89sbSXqzwN
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
In den vergangengenen Wochen habe ich die erste »echte« Ubuntu-Server-Installation durchgeführt. Abgesehen von aktuelleren Versionsnummern (siehe auch meinen Artikel zu Ubuntu 24.04) sind mir nicht allzu viele Unterschiede im Vergleich zu Ubuntu Server 22.04 aufgefallen. Bis jetzt läuft alles stabil und unkompliziert. Erfreulich für den Server-Einsatz ist die Verlängerung des LTS-Supports auf 12 Jahre (erfordert aber Ubuntu Pro); eine derart lange Laufzeit wird aber wohl nur in Ausnahmefällen sinnvoll sein.
Update 1 am 25.6.2024: Es gibt immer noch keinen finalen Fix für fail2ban, aber immerhin einen guter Workaround (Installation des proposed-Fix).
Update 2 am 29.6.2024: Es gibt jetzt einen regulären Fix.
fail2ban-Ärger
Recht befremdlich ist, dass fail2ban sechs Wochen nach dem Release immer noch nicht funktioniert. Der Fehler ist bekannt und wird verursacht, weil das Python-Modul asynchat mit Python 3.12 nicht mehr ausgeliefert wird. Für die Testversion von Ubuntu 24.10 gibt es auch schon einen Fix, aber Ubuntu 24.04-Anwender stehen diesbezüglich im Regen.
Persönlich betrachte ich fail2ban als essentiell zur Absicherung des SSH-Servers, sofern dort Login per Passwort erlaubt ist.
Update 1:
Mittlerweile gibt es einen proposed-Fix, der wie folgt installiert werden kann (Quelle: [Launchpad](https://bugs.launchpad.net/ubuntu/+source/fail2ban/+bug/2055114)):
* In `/etc/apt/sources.list.d/ubuntu.sources` einen Eintrag für `noble-proposed` hinzufügen, z.B. so:
„`
# zusätzliche Zeilen in `/etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://archive.ubuntu.com/ubuntu/
Suites: noble-proposed
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
„`
Beachten Sie, dass sich Ort und Syntax für die Angabe der Paketquellen geändert haben.
* `apt update`
* `apt-get install -t noble-proposed fail2ban`
* in `/etc/apt/sources.list.d/ubuntu.sources` den Eintrag für `noble-proposed` wieder entfernen (damit es nicht weitere Updates aus dieser Quelle gibt)
* `apt update`
Update 2: Der Fix ist endlich offiziell freigegeben. apt update und apt full-upgrade, fertig.
/tmp mit tmpfs im RAM
Das Verzeichnis /tmp wird unter Ubuntu nach wie vor physikalisch auf dem Datenträger gespeichert. Auf einem Server mit viel RAM kann es eine Option sein, /tmp mit dem Dateisystemtyp tmpfs im RAM abzubilden. Der Hauptvorteil besteht darin, dass I/O-Operationen in /tmp dann viel effizienter ausgeführt werden. Dagegen spricht, dass die exzessive Nutzung von /tmp zu Speicherproblemen führen kann.
Auf meinem Server mit 64 GiB RAM habe ich beschlossen, max. 4 GiB für /tmp zu reservieren. Die Konfiguration ist einfach, weil der Umstieg auf tmpfs im systemd bereits vorgesehen ist:
systemctl enable /usr/share/systemd/tmp.mount
Mit systemctl edit tmp.mount bearbeiten Sie die neue Setup-Datei /etc/systemd/system/tmp.mount.d/override.conf, die nur Änderungen im Vergleich zur schon vorhandenen Datei /etc/systemd/system/tmp.mount bzw. /usr/share/systemd/tmp.mount enthält.
# wer keinen vi mag, zuerst: export EDITOR=/usr/bin/nano
systemctl edit tmp.mount
Wer ein GitHub Account hat, kann sich sehr einfach über neue Releases (Veröffentlichungen) von Projekten per E-Mail informieren lassen. Es benutzen aber nicht alle Projekte das „Releases“ Feature, sondern setzen stattdessen auf Git Tags....
Dies ist mein Erfahrungsbericht zu den ersten Schritten mit InstructLab. Ich gehe darauf ein, warum ich mich über die Existenz dieses Open Source-Projekts freue, was ich damit mache und was ich mir von Large Language Models (kurz: LLMs, zu Deutsch: große Sprachmodelle) erhoffe. Der Text enthält Links zu tiefergehenden Informationen, die euch mit Hintergrundwissen versorgen und einen Einstieg in das Thema ermöglichen.
Dieser Text ist keine Schritt-für-Schritt-Anleitung für:
Beim Bezug auf große Sprachmodelle bediene ich mich der englischen Abkürzung LLM oder bezeichne diese als KI-ChatBot bzw. nur ChatBot.
Was ist InstructLab?
InstructLab ist ein von IBM und Red Hat ins Leben gerufenes Open Source-Projekt, mit dem die Gemeinschaft zur Verbesserung von LLMs beitragen kann. Jeder
Hugging Face. The AI community building the future. The platform where the machine learning community collaborates on models, datasets, and applications. URL: https://huggingface.co/
Meine Einstellung gegenüber KI-ChatBots
Gegenüber KI-Produkten im Allgemeinen und KI-ChatBots im Speziellen bin ich stets kritisch, was nicht bedeutet, dass ich diese Technologien und auf ihnen basierende Produkte und Services ablehne. Ich versuche mir lediglich eine gesunde Skepsis zu bewahren.
Was Spielereien mit ChatBots betrifft, bin ich sicherlich spät dran. Ich habe schlicht keine Lust, mich irgendwo zu registrieren und unnötig Informationen über mich preiszugeben, nur um anschließend mit einer Büchse chatten und ihr Fragen stellen zu können, um den Wahrheitsgehalt der Antworten anschließend noch verifizieren zu müssen.
Mittlerweile gibt es LLMs, welche ohne spezielle Hardware auch lokal ausgeführt werden können. Diese sprechen meine Neugier und meinen Spieltrieb schon eher an, weswegen ich mich nun doch mit einem ChatBot unterhalten möchte.
Der lokale LLM-Server wird mit dem Befehl ilab serve gestartet. Mit dem Befehl ilab chat wird die Unterhaltung mit dem Modell eingeleitet.
Im folgenden Video sende ich zwei Anweisungen an das LLM merlinite-7b-lab-Q4_K_M. Den Chatverlauf seht ihr in der rechten Bildhälfte. In der linken Bildhälfte seht ihr die Ressourcenauslastung meines Laptops.
Screencast eines Chats mit merlinite-7b-lab-Q4_K_M
Wie ihr seht, sind die Antwortzeiten des LLM auf meinem Laptop nicht gerade schnell, aber auch nicht so langsam, dass ich währenddessen einschlafe oder das Interesse an der Antwort verliere. An der CPU-Auslastung im Cockpit auf der linken Seite lässt sich erkennen, dass das LLM durchaus Leistung abruft und die CPU fordert.
Mit den Antworten des LLM bin ich zufrieden. Sie decken sich mit meiner Erinnerung und ein kurzer Blick auf die Seite https://www.json.org/json-de.html bestätigt, dass die Aussagen des LLM korrekt sind.
Anmerkung: Der direkte Aufruf der Seite https://json.org, der mich mittels Redirect zu obiger URL führte, hat sicher deutlich weniger Energie verbraucht als das LLM oder eine Suchanfrage in irgendeiner Suchmaschine. Ich merke dies nur an, da ich den Eindruck habe, dass es aus der Mode zu geraten scheint, URLs einfach direkt in die Adresszeile eines Webbrowsers einzugeben, statt den Seitennamen in eine Suchmaske zu tippen.
Ich halte an dieser Stelle fest, der erste kleine Test wird zufriedenstellend absolviert.
KI-Halluzinationen
Da ich einige Zeit im Hochschulrechenzentrum der Universität Bielefeld gearbeitet habe, interessiert mich, was das LLM über meine ehemalige Dienststelle weiß. Im nächsten Video frage ich, wer der Kanzler der Universität Bielefeld ist.
Frage an das LLM: „Who is the chancellor of the Bielefeld University?“
Da ich bis März 2023 selbst an der Universität Bielefeld beschäftigt war, kann ich mit hinreichender Sicherheit sagen, dass diese Antwort falsch ist und das Amt des Kanzlers nicht von Prof. Dr. Karin Vollmerd bekleidet wird. Im Personen- und Einrichtungsverzeichnis (PEVZ) findet sich für Prof. Dr. Vollmerd keinerlei Eintrag. Für den aktuellen Kanzler Dr. Stephan Becker hingegen schon.
Da eine kurze Recherche in der Suchmaschine meines geringsten Misstrauens keine Treffer zu Frau Vollmerd brachte, bezweifle ich, dass diese Person überhaupt existiert. Es kann allerdings auch in meinen unzureichenden Fähigkeiten der Internetsuche begründet liegen.
Bei der vorliegenden Antwort handelt es sich um eine Halluzination der Künstlichen Intelligenz.
Im Bereich der Künstlichen Intelligenz (KI) ist eine Halluzination (alternativ auch Konfabulation genannt) ein überzeugend formuliertes Resultat einer KI, das nicht durch Trainingsdaten gerechtfertigt zu sein scheint und objektiv falsch sein kann.
Solche Phänomene werden in Analogie zum Phänomen der Halluzination in der menschlichen Psychologie als von Chatbots erzeugte KI-Halluzinationen bezeichnet. Ein wichtiger Unterschied ist, dass menschliche Halluzinationen meist auf falschen Wahrnehmungen der menschlichen Sinne beruhen, während eine KI-Halluzination ungerechtfertigte Resultate als Text oder Bild erzeugt. Prabhakar Raghavan, Leiter von Google Search, beschrieb Halluzinationen von Chatbots als überzeugend formulierte, aber weitgehend erfundene Resultate.
Oder wie ich es umschreiben möchte: „Der KI-ChatBot demonstriert sichereres Auftreten bei völliger Ahnungslosigkeit.“
Wenn ihr selbst schon mit ChatBots experimentiert habt, werdet ihr sicher selbst schon auf Halluzinationen gestoßen sein. Wenn ihr mögt, teilt doch eure Erfahrungen, besonders jene, die euch fast aufs Glatteis geführt haben, in den Kommentaren mit uns.
Welche Auswirkungen überzeugend vorgetragene Falschmeldungen auf Nutzer haben, welche nicht über das Wissen verfügen, diese Halluzinationen sofort als solche zu entlarven, möchte ich für den Moment eurer Fantasie überlassen.
Ich denke an Fahrplanauskünfte, medizinische Diagnosen, Rezepturen, Risikoeinschätzungen, etc. und bin plötzlich doch ganz froh, dass sich die EU-Staaten auf ein erstes KI-Gesetz einigen konnten, um KI zu regulieren. Es wird sicher nicht das letzte sein.
Um das Beispiel noch etwas auszuführen, frage ich das LLM erneut nach dem Kanzler der Universität und weise es auf seine Falschaussagen hin. Der Chatverlauf ist in diesem Video zu sehen:
ChatBot wird auf Falschaussage hingewiesen
Die Antworten des LLM enthalten folgende Fehler:
Professor Dr. Ulrich Heidt ist nicht der Kanzler der Universität Bielefeld
Die URL ‚https://www.uni-bielefeld.de/english/staff/‘ existiert nicht
Die URL ‚http://www.universitaet-bielefeld.de/en/‘ existiert ebenfalls nicht
Die Universität hieß niemals „Technische Universitaet Braunschweig“
Der Chatverlauf erweckt den Eindruck, dass der ChatBot sich zu rechtfertigen versucht und nach Erklärungen und Ausflüchten sucht. Hier wird nach meinem Eindruck menschliches Verhalten nachgeahmt. Dabei sollten wir Dinge nicht vermenschlichen. Denn unser Chatpartner ist kein Mensch. Er ist eine leblose Blechbüchse. Das LLM belügt uns auch nicht in böser Absicht, es ist schlicht nicht in der Lage, uns eine korrekte Antwort zu liefern, da ihm dazu das nötige Wissen bzw. der notwendige Datensatz fehlt. Daher versuche ich im nächsten Schritt, dem LLM mit InstructLab das notwendige Wissen zu vermitteln.
Wissen und Fähigkeiten hinzufügen und das Modell anlernen
Das README.md im Repository instructlab/taxonomy enthält die Beschreibung, wie man dem LLM Wissen (englisch: knowledge) hinzufügt. Weitere Hinweise finden sich in folgenden Dateien:
Diese Dateien befinden sich auch in dem lokalen Repository unterhalb von ~/instructlab/taxonomy/. Ich hangel mich an den Leitfäden entlang, um zu sehen, wie weit ich damit komme.
Wissen erschaffen
Die Überschrift ist natürlich maßlos übertrieben. Ich stelle lediglich existierende Informationen in erwarteten Dateiformaten bereit, um das LLM damit trainieren zu können.
Da aktuell nur Wissensbeiträge von Wikipedia-Artikeln akzeptiert werden, gehe ich wie folgt vor:
Konvertiere den Wikipedia-Artikel Bielefeld University ohne Bilder und Tabellen in eine Markdown-Datei und füge sie dem in Schritt 1 erstellten Repository unter dem Namen unibi.md hinzu
Füge dem lokalen Taxonomy-Repository neue Verzeichnisse hinzu: mkdir -p university/germany/bielefeld_university
Erstelle in dem neuen Verzeichnis eine qna.yaml und eine attribution.txt Datei
Führe ilab diff aus, um die Daten zu validieren
Der folgende Code-Block zeigt den Inhalt der Dateien qna.yaml und eine attribution.txt sowie die Ausgabe des Kommandos ilab diff:
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/qna.yaml
version: 2
task_description: 'Teach the model the who facts about Bielefeld University'
created_by: tronde
domain: university
seed_examples:
- question: Who is the chancellor of Bielefeld Universtiy?
answer: Dr. Stephan Becker is the chancellor of the Bielefeld University.
- question: When was the University founded?
answer: |
The Bielefeld Universtiy was founded in 1969.
- question: How many students study at Bielefeld University?
answer: |
In 2017 there were 24,255 students encrolled at Bielefeld Universtity?
- question: Do you know something about the Administrative staff?
answer: |
Yes, in 2017 the number for Administrative saff was published as 1,100.
- question: What is the number for Academic staff?
answer: |
In 2017 the number for Academic staff was 1,387.
document:
repo: https://github.com/Tronde/instructlab_knowledge_contributions_unibi.git
commit: c2d9117
patterns:
- unibi.md
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/attribution.txt
Title of work: Bielefeld University
Link to work: https://en.wikipedia.org/wiki/Bielefeld_University
License of the work: CC-BY-SA-4.0
Creator names: Wikipedia Authors
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ ilab diff
knowledge/university/germany/bielefeld_university/qna.yaml
Taxonomy in /taxonomy/ is valid :)
(venv) [tronde@t14s instructlab]$
Synthetische Daten generieren
Aus der im vorherigen Abschnitt erstellten Taxonomie generiere ich im nächsten Schritt synthetische Daten, welche in einem folgenden Schritt für das Training des LLM genutzt werden.
(venv) [tronde@t14s instructlab]$ ilab generate
[…]
INFO 2024-05-28 12:46:34,249 generate_data.py:565 101 instructions generated, 62 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log), 4 discarded due to rouge score
INFO 2024-05-28 12:46:34,249 generate_data.py:569 Generation took 12841.62s
(venv) [tronde@t14s instructlab]$ ls generated/
discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log
generated_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.json
test_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
train_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
Zur Laufzeit werden alle CPU-Threads voll ausgelastet. Auf meinem Laptop dauerte dieser Vorgang knapp 4 Stunden.
Das Training beginnt
Jetzt wird es Zeit, das LLM mit den synthetischen Daten anzulernen bzw. zu trainieren. Dieser Vorgang wird mehrere Stunden in Anspruch nehmen und ich verplane mein Laptop in dieser Zeit für keine weiteren Arbeiten.
Um möglichst viele Ressourcen freizugeben, beende ich das LLM (ilab serve und ilab chat). Das Training beginnt mit dem Befehl ilab train… und dauert wirklich lange.
Nach 2 von 101 Durchläufen wird die geschätzte Restlaufzeit mit 183 Stunden angegeben. Das Ergebnis spare ich mir dann wohl für einen Folgeartikel auf und gehe zum Fazit über.
Fazit
Mit dem InstructLab Getting Started Guide gelingt es in kurzer Zeit, das Projekt auf einem lokalen Linux-Rechner einzurichten, ein LLM auszuführen und mit diesem zu chatten.
KI-Halluzinationen stellen in meinen Augen ein Problem dar. Da LLMs überzeugend argumentieren, kann es Nutzern schwerfallen oder gar misslingen, die Falschaussagen als solche zu erkennen. Im schlimmsten Fall lernen Nutzer somit dummen Unfug und verbreiten diesen ggf. weiter. Dies ist allerdings kein Problem bzw. Fehler des InstructLab-Projekts, da alle LLMs in unterschiedlicher Ausprägung von KI-Halluzinationen betroffen sind.
Wie Knowledge und Skills hinzugefügt werden können, musste ich mir aus drei Guides anlesen. Dies ist kein Problem, doch kann der Leitfaden evtl. noch etwas verbessert werden.
Knowledge Contributions werden aktuell nur nach vorheriger Genehmigung und nur von Wikipedia-Quellen akzeptiert. Der Grund wird nicht klar kommuniziert, doch ich vermute, dass dies etwas mit geistigem Eigentum und Lizenzen zu tun hat. Wikipedia-Artikel stehen unter einer Creative Commons Attribution-ShareAlike 4.0 International License und können daher unkompliziert als Quelle verwendet werden. Da sich das Projekt in einem frühen Stadium befindet, kann ich diese Limitierung nachvollziehen. Ich wünsche mir, dass grundsätzlich auch Primärquellen wie Herstellerwebseiten und Publikationen zugelassen werden, wenn Rechteinhaber dies autorisieren.
Der von mir herangezogene Wikipedia-Artikel ist leider nicht ganz aktuell. Nutze ich ihn als Quelle für das Training eines LLM, bringe ich dem LLM damit veraltetes und nicht mehr gültiges Wissen bei. Das ist für meinen ersten Test unerheblich, für Beiträge zum Projekt jedoch nicht sinnvoll.
Die Generierung synthetischer Daten dauert auf Alltagshardware schon entsprechend lange, das anschließende Training jedoch nochmals bedeutend länger. Dies ist meiner Ansicht nach nichts, was man nebenbei auf seinem Laptop ausführt. Daher habe ich den Test auf meinem Laptop abgebrochen und lasse das Training aktuell auf einem Fedora 40 Server mit 32 GB RAM und 10 CPU-Kernen ausführen. Über das Ergebnis und einen Test des verbesserten Modells werde ich in einem folgenden Artikel berichten.
Was ist mit euch? Kennt ihr das Projekt InstructLab und habt evtl. schon damit gearbeitet? Wie sind eure Erfahrungen?
Arbeitet ihr mit LLMs? Wenn ja, nutzt ihr diese nur oder trainiert ihr sie auch? Was nutzt ihr für Hardware?
Ich freue mich, wenn ihr eure Erfahrungen hier mit uns teilt.
Ich hatte es geahnt, aber dann ging es doch schneller als gedacht. Mit der Entscheidung des Europäischen Gerichtshofes Ende April wurde in einem Fall in Frankreich die Speicherung von IP-Adressen seitens des ISPs auf Vorrat nicht nur für den Bereich schwerer Straftaten, sondern auch für Urheberrechtsverstöße für zulässig erachtet. Damit ist eine Diskussion wieder auf dem Tisch, die seit 20 Jahren regelmäßig aufflammt, aber bisher durch Urteile gegen die erlassenen Gesetze eingefangen wurde.
Mit diesem Thema haben wir uns vergangene Woche mit Professor Dr. Stephan G. Humer in der 48. Episode des Risikozone-Podcasts beschäftigt, den ich euch wärmstens empfehlen kann.
Die klassische VDS in Deutschland wird momentan nicht praktiziert, da sie nach einem älteren Urteil des EuGH, das konkret das deutsche Gesetz betraf, als rechtswidrig eingestuft wurde. Nichtsdestotrotz ist die Diskussion wieder eröffnet und alle Möglichkeiten für Vorhaben zur Wiedereinführung werden wieder eingebracht. Das Thema wird uns also weiterhin noch eine ganze Weile verfolgen.
Klar, im Urteil des EuGH wird als Bedingung gestellt, dass Maßnahmen getroffen werden müssen, damit die Privatsphäre der einzelnen Nutzer gewahrt bleibt, aber das ändert nichts daran, dass die Daten grundsätzlich erstmal erhoben werden. Die "Neuerung" in diesem Urteil zu der Thematik ist, dass IP-Adressen und Identitäten getrennt gespeichert werden müssen. Mir ist allerdings noch nicht einleuchtend, was im Urteil mit der "Verknüpfung nur unter Verwendung eines leistungsfähigen technischen Verfahrens [...], das die Wirksamkeit der strikten Trennung dieser Datenkategorien nicht in Frage stellt" gemeint ist. Sollen die Datenbanken mit einem anschließend zu verwerfenden Schlüssel verschlüsselt werden, der bei der Verknüpfung erst geknackt werden muss? Am Ende kann ein technisches Verfahren doch gar nicht feststellen, ob ein Gesuch den formellen juristischen Anforderungen genügt oder nicht.
Technisch reden wir hier im Übrigen von zwei Teilaspekten: einerseits die Speicherung, welche Stationen (mit welchen IP-Adressen) miteinander kommunizieren und andererseits, wer hinter welcher IP-Adresse steckt. Diese ganze letzte Thematik haben wir allerdings nur, weil die ISPs einerseits ungern Privatkunden feste IP-Adressen vergeben und andererseits mitunter gar nicht so viele IP(v4)-Adressen wie Kunden haben und dann zu Tricks wie CG-NAT greifen müssen. Hämisch könnte man jetzt fragen, warum in dem Zusammenhang die Politik noch nicht alle zu IPv6 verpflichtet hat. Auf der anderen Seite wird deutlich, wie sehr sich das Internet verändert hat, nachdem es ein Massenmedium wurde.
Früher wurden feste IP-Adressen genutzt und die Zuordnung größtenteils öffentlich hinterlegt. Die Teilnehmer des Internets kannten sich mehr oder weniger sowieso alle untereinander. Als das Internet mehr und mehr ein Massenmedium wurde, ging es allerdings nicht mehr um den wissenschaftlichen oder beruflichen Austausch, sondern auch vorrangiger um das private Leben, wodurch auf einmal Grundrechte tangiert wurden und das Thema der Anonymität im Netz aufkam.
Gespeichert werden die Zuordnungen wohl auch weiterhin noch, aber sichtbar sind sie nur noch für Behörden und ähnliche Organisationen. Spätestens mit dem breiten Ausrollen der DSGVO wurde z. B. der whois-Dienst der DENIC für die Öffentlichkeit geschlossen. Wer einen Webseitenbetreiber ermitteln möchte, der kein Impressum auf der Seite stehen hat, schaut seitdem in die Röhre.
Vorratsdatenspeicherung ist und bleibt somit ein netzpolitisches Thema und lässt sich somit nicht auf der rein technischen Ebene erklären. Von da aus kann man sich oft an den Kopf fassen, was da alles von der Technik erwartet wird. Solche Themen sind auch ein Abbild der Gesellschaftspolitik, was daran deutlich wird, dass im Wesentlichen Deutschland eines der wenigen kritischen Länder diesbezüglich ist.
Die Never-ending-Story geht jetzt also in die nächste Runde. Weitere Probleme, Risiken und Lösungsansätze könnt ihr gerne euch in unserem Podcast anhören und in den Kommentaren mitdiskutieren.
In diesem Video zeigt Jean verschiedene Alternativen zu Anwendungen von Microsoft. Wahre deine digitale Souveränität und setze auf besseren Datenschutz mit diesen coolen Alternativen.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
Linux im Alltag, Erfahrungsbericht: https://www.youtube.com/watch?v=rhv1UlwCffU
Libre Workspace vorgestellt: https://www.youtube.com/watch?v=tzs9SdfeOMc
Website des Libre Workspace*: https://www.libre-workspace.org/
Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Die Linux-Kommandoreferenz ist erstmalig 1995 erschienen. Die Kommandoreferenz war damals aber nur ein 56 Seiten langes Kapitel in der ersten Auflage meines Linux-Buchs. Aufgrund von Platzproblemen musste ich das Kommandoreferenz-Kapitel 15 Jahre später aus dem Linux-Buch entfernen und in ein eigenes Buch auslagern. Die erste Auflage im Taschenbuchformat hatte noch schlanke 176 Seiten. In der gerade neu erschienen sechsten Auflage hat das Buch den dreifachen Umfang!
547 Seiten, Hard-Cover
ISBN: 978-3-367-10103-0
Preis: Euro 29,90 (in D inkl. MWSt.)
Vor 15 Jahren zweifelten der Verlag und ich, ob die Kommandoreferenz überhaupt ein sinnvolles Buch wäre. Natürlich lassen sich alle Kommandos im Internet recherchieren. Heute verrät auch ChatGPT die gerade relevanten Optionen von find oder grep.
Dessen ungeachtet geben die Verkaufszahlen eine klare Botschaft: Ja, es gibt ganz offensichtlich den Bedarf nach einer Linux-Kommandoreferenz, die das Wesentliche vom Unwesentlichen trennt, die anhand thematischer Übersichten einen Startpunkt in das riesige Universum der Linux-Kommandos bietet, die mit vielen Beispielen alltägliche »Linux-Praxis« vermittelt. Keines meiner Bücher öffne ich selbst so oft (natürlich als PDF-Datei), um irgendein Detail rasch nachzulesen!
Für die 6. Auflage habe ich das Buch einmal mehr komplett aktualisiert. Die folgenden Kommandos habe ich neu aufgenommen:
Außerdem habe ich die Beschreibung vieler Kommandos aktualisiert oder mit zusätzlichen Beispielen versehen, unter anderem bei acme.sh, chmod, convert, curl, dd, find, firewall-cmd, mail, nmcli, pip und tcpdump.
In diesem Video zeigt Jean, wie er sein Produktivsystem flott und schlank hält. Der perfekte Frühjahrsputz um mal wieder alles aufzuräumen und seinem Linux wieder neues Leben einzuhauchen.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
Linux-Assistant: https://www.linux-assistant.org/
Backups unter Linux machen: https://youtu.be/kgaOQ3pLZaI?si=Q8L-iqWCoqJXl0Dw
Hintergrundbild: https://unsplash.com/de/fotos/gewasser-tagsuber-eXHeq48Z-Q4
Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Offizielle Webseite: https://www.linuxguides.de
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Mastodon: https://mastodon.social/@LinuxGuides
X: https://twitter.com/LinuxGuides
Instagram: https://www.instagram.com/linuxguides/
Kontakt: https://www.linuxguides.de/kontakt/
Elektronomia - Sky High [NCS Release]
Music provided by NoCopyrightSounds.
Video Link: https://youtu.be/TW9d8vYrVFQ
Download Link: https://NCS.lnk.to/SkyHigh
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Heute Abend klären wieder Hauke und Jean Deine Fragen live!
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
--------------------
Links:
Frage stellen: https://ask.linuxguides.de
Forum: https://forum.linuxguides.de/
Haukes Webseite: https://goos-habermann.de/index.php
Nicht der Weisheit letzter Schluß: youtube.com/@nichtderweisheit
Linux Guides Admin: https://www.youtube.com/@LinuxGuidesAdmin
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Ubuntu Kurs für Anwender*: https://www.linuxguides.de/ubuntu-kurs-fuer-anwender/
Linux für Fortgeschrittene*: https://www.linuxguides.de/linux-kurs-fuer-fortgeschrittene/
Offizielle Webseite: https://www.linuxguides.de
Tux Tage: https://www.tux-tage.de/
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Twitter: https://twitter.com/LinuxGuides
Mastodon: https://mastodon.social/@LinuxGuides
Matrix: https://matrix.to/#/+linuxguides:matrix.org
Discord: https://www.linuxguides.de/discord/
Kontakt: https://www.linuxguides.de/kontakt/
BTC-Spende: 1Lg22tnM7j56cGEKB5AczR4V89sbSXqzwN
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
Vor über vier Jahren hatte ich mich schon einmal mit dieser Thematik im Artikel „TURN-Server für Nextcloud Talk“ auseinandergesetzt. Über die Jahre hinweg hat sich jedoch einiges geändert und ich konnte mein Wissen ausbauen. Aus diesem Grund möchte ich nun meine aktuellsten Erkenntnisse noch einmal zusammenhängend präsentieren.
Installation
Ein TURN-Server wird von Nextcloud Talk benötigt, um Videokonferenzen zu ermöglichen. Der TURN-Server bringt die Teilnehmer, welche sich in verschiedenen Netzwerken befinden, zusammen. Nur so ist eine reibungslose Verbindung unter den Teilnehmern in Nextcloud Talk möglich.
Wer bisher meinen Anleitungen zur Installation von Nextcloud auf dem Raspberry Pi gefolgt ist, kann nun die eigene Cloud für Videokonferenzen fit machen. Zu bedenken gilt aber, dass ein eigener TURN-Server nur bis maximal 6 Teilnehmer Sinn macht. Wer Konferenzen mit mehr Teilnehmern plant, muss zusätzlich einen Signaling-Server integrieren.
Nun zur Installation des TURN-Servers. Zuerst installiert man den Server mit
sudo apt install coturn
und kommentiert folgende Zeile, wie nachfolgend zu sehen in /etc/default/coturn aus.
sudo nano /etc/default/coturn
Dabei wird der Server im System aktiviert.
#
# Uncomment it if you want to have the turnserver running as
# an automatic system service daemon
#
TURNSERVER_ENABLED=1
Nun legt man die Konfigurationsdatei zum TURN-Server mit folgendem Inhalt an.
Hier werden u.a. der Port und das Passwort des Servers sowie die Domain der Cloud eingetragen. Natürlich muss hier noch der Port im Router freigegeben werden. Ein starkes Passwort wird nach belieben vergeben.
Hierbei kann das Terminal hilfreich sein. Der folgende Befehl generiert z.B. ein Passwort mit 24 Zeichen.
gpg --gen-random --armor 1 24
Jetzt wird der Server in den Verwaltungseinstellungen als STUN- und TURN-Server inkl. Listening-Port sowie Passwort eingetragen.
Nextcloud – Verwaltungseinstellungen – TalkEintrag der Domain für STUN- und TURN-Server (sowie Passwort)
Bei meinen ersten Versuchen auf dem Raspberry Pi fiel auf, dass der Service des TURN-Servers schneller startet als das gesamte System, was einen Betrieb unmöglich machte. Diese Problematik konnte ich wie im Artikel „coTurn zeitverzögert auf Raspberry Pi starten“ beschrieben, lösen. Leider überstand aber dieser Eingriff kein Systemupgrade. Durch einen sehr hilfreichen Kommentar von Matthias, kann ich nun eine bessere Lösung aufzeigen.
Es wird mit
sudo systemctl edit coturn.service
der Service des Servers editiert. Folgender Eintrag wird zwischen die Kommentare gesetzt:
### Editing /etc/systemd/system/coturn.service.d/override.conf
### Anything between here and the comment below will become the new contents of the file
[Service]
ExecStartPre=/bin/sleep 30
### Lines below this comment will be discarded
### /lib/systemd/system/coturn.service
Dies ermöglicht den TURN-Server (auch nach einem Upgrade) mit einer Verzögerung von 30 Sekunden zu starten.
Zum Schluss wird der Service neu gestartet.
sudo service coturn restart
Ein Check zeigt, ob der TURN-Server funktioniert. Hierzu klickt man auf das Symbol neben dem Papierkorb in der Rubrik TURN-Server der Nextcloud. Wenn alles perfekt läuft ist, wird im Screenshot, ein grünes Häkchen sichtbar.
Einmal wollte ich faul sein und gleichzeitig einem FOSS-Projekt etwas Gutes tun. Anstelle mich immer selbst um ein Update von LibreOffice zu kümmern, wollte ich es aus dem Apple App Store installieren, via selbigen an das Projekt spenden und die Downloadzahlen im Store um eine Wertigkeit erhöhen. Automatische Updates im Hintergrund sollten hier die Wahl ... Weiterlesen
In diesem Video reagiere ich auf den Erfahrungsbericht von PrivacyTutor, der Linux ein Jahr lang ausprobiert hat bevor er zum MacBook gewechselt ist. Ich sage dir meine Meinung zum Vorteil von Mac und warum ich trotzdem bei Linux bleibe.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
-------------------------------------
Originalvideo: https://youtu.be/6dTwkXcQIQM?si=GloYYGK9OvRI2hd5
Linux Mint Crashkurs: https://www.youtube.com/watch?v=eyUbzKY8ZaE
Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Offizielle Webseite: https://www.linuxguides.de
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Mastodon: https://mastodon.social/@LinuxGuides
X: https://twitter.com/LinuxGuides
Instagram: https://www.instagram.com/linuxguides/
Kontakt: https://www.linuxguides.de/kontakt/
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.
In diesem Video zeigt Jean, wie man in NocoDB eine Kundendatenbank zum Beispiel im Rahmen eines ERP aufbaut. Dabei wird gezeigt, wie man Felder in NocoDB zusammenfassen und mit anderen Tabellen verknüpfen kann.
Wenn Du das Video unterstützen willst, dann gib bitte eine Bewertung ab, und schreibe einen Kommentar. Vielen Dank!
Links:
Playlist zu NocoDB: https://www.youtube.com/playlist?list=PLhvaM7uJr1PDEw7I24kZYXwxV5tfybmjm
Formeln in NocoDB: https://docs.nocodb.com/0.109.7/setup-and-usages/formulas/
Linux-Guides Merch*: https://linux-guides.myspreadshop.de/
Professioneller Linux Support*: https://www.linuxguides.de/linux-support/
Linux-Arbeitsplatz für KMU & Einzelpersonen*: https://www.linuxguides.de/linux-arbeitsplatz/
Linux Mint Kurs für Anwender*: https://www.linuxguides.de/kurs-linux-mint-fur-anwender/
Offizielle Webseite: https://www.linuxguides.de
Forum: https://forum.linuxguides.de/
Unterstützen: http://unterstuetzen.linuxguides.de
Mastodon: https://mastodon.social/@LinuxGuides
X: https://twitter.com/LinuxGuides
Instagram: https://www.instagram.com/linuxguides/
Kontakt: https://www.linuxguides.de/kontakt/
0:00 Begrüßung
1:13 Kunden erstellen
10:08 Verknüpfung zwischen Tabellen
14:27 Felder zusammenfassen
31:00 Tabelle duplizieren
34:43 Zusammenfassung und Ausblick
Haftungsausschluss:
-------------------------------------
Das Video dient lediglich zu Informationszwecken. Wir übernehmen keinerlei Haftung für in diesem Video gezeigte und / oder erklärte Handlungen. Es entsteht in keinem Moment Anspruch auf Schadensersatz oder ähnliches.