Die kürzlich veröffentlichte Beta-Version von SteamOS 3.8.6 bietet erstmals nativen HDMI-VRR-Support. Ist das ein Hinweis auf eine baldige VRR-Unterstützung der Steam Machine, sobald AMD HDMI-2.1 in ihren Grafikkartentreiber implementiert hat?
Der Linux Coffee Talk, das lockere Format rund um Linux, Open Source und Technik im Alltag. Ohne Hype, ohne Clickbait, dafür mit echten Einordnungen der Meldungen, Meinungen und einem Überblick über die wichtigsten FOSS-/Linux-News aus Mai 2026. Wir sprechen über Distributionen, Tools, Datenschutz, Nerd-Themen und alles, was uns Linux-User bewegt. Perfekt für alle, die stets […]
Der Linux Coffee Talk ist das entspannte Monatsformat bei fosstopia. Hier fassen wir die spannendsten Ereignisse und Entwicklungen der letzten Wochen für Euch zusammen und ordnen sie bestmöglich ein. Also schnappt euch einen Kaffee, Tee oder Euer Lieblingsgetränk, macht es euch gemütlich und lasst uns den Mai 2026 Revue passieren.
Mozilla hat Firefox 151 für Apple iOS veröffentlicht. Dieser Artikel beschreibt die Neuerungen von Firefox 151.
Die Neuerungen von Firefox 151 für iOS
Mozilla hat Firefox 151 für das iPhone, iPad sowie iPod touch veröffentlicht. Die neue Version steht im Apple App Store zum Download bereit.
„Kill Switch” für KI-Funktionen
Künstliche Intelligenz (KI) ist ein Thema, welches mittlerweile omnipräsent ist. Die einen lieben es, andere möchten am liebsten gar nichts damit zu tun haben. Um die Verwaltung von KI-Funktionen einfacher zu machen, hat Mozilla die Firefox-Einstellungen um einen zusätzlichen Bereich mit der Bezeichnung „KI-Einstellungen” erweitert. Dieser neue Bereich bietet einen Ort, um KI-Funktionen zentral zu steuern. Darüber hinaus bietet Firefox einen globalen Schalter zum Ein- und Ausschalten von KI-Funktionen an – welcher auch zukünftige KI-Features abschaltet.
Sonstige Neuerungen von Firefox 151 für iOS
Ansonsten bringt das Update auf Firefox 151 wie imme Detail-Verbesserungen, Fehlerbehebungen sowie Optimierungen unter der Haube. Auch Sicherheitslücken wurden behoben.
Flatpak könnte künftig stärker auf systemd Services setzen. Diese mögliche Richtung sorgt bei vielen Nutzern für Diskussionen. Besonders betroffen wären Distributionen ohne systemd Unterstützung. Die Entwickler arbeiten derzeit an einer neuen Architektur. Sie nennen das Konzept „Flatpak Next-Generation Sandboxing“ und prüfen grundlegende Änderungen. Ziel ist eine stabilere Verwaltung laufender Anwendungen. Auch die Integration moderner Desktop […]
Unser Buch Coding mit KI ist gerade erst erschienen, schon gibt es spannende Neuigkeiten rund um die Ausführung lokaler Modelle:
Multi-Token Prediction (MTP) ist ein ganz neues Feature in llama.cpp. Seit ein paar Tagen steht es auch in LM Studio zur Verfügung. Durch einen »Trick« (Details folgen gleich) kann mit MTP die Output-Token-Geschwindigkeit deutlich vergrößert werden: laut diversen Benchmarktests im Internet bis auf das Doppelte, in meinen Tests immerhin um ca. 60 bis 70 Prozent.
Adaptive Precision for EXpert Models (APEX) ist ein neues Verfahren zur besonders platzsparenden Quantisierung von MoE-Modellen. Der Platzbedarf sinkt je nach Qualitätsstufe auf die Hälfte gegenüber der herkömmlichen 4-Bit-Darstellungen (Q4_x_x).
Qwopus ist eine neue Variante zu den Qwen-Modellen, bei denen das Fine Tuning mit Claude Opus verbessert wurde.
Von Speculative Decoding zur Multi-Token Prediction
In Coding mit KI gehe ich kurz auf das Vorgängerkonzept zu MTP ein, auf Speculative Decoding: Dabei führt die Engine (z.B. llama.cpp) zwei Sprachmodelle aus. Das kleinere (schnellere) dient als Draft Model. Während der Token-Generierung macht das Draft Model Vorschläge für die folgenden Token. Das größere, qualitativ bessere Modell überprüft anschließend eine Sequenz mehrerer vorgeschlagener Token auf einmal. Im Idealfall wird die ganze Sequenz akzeptiert. Der Geschwindigkeitsvorteil ergibt sich durch die parallele Verifizierung eines ganzen Token-Blocks. Dazu sind weniger Speicher-Transfers vom VRAM in die GPU notwendig, als wenn jedes Token für sich generiert wird. (Die Token-Generierung wird durch zwei Faktoren limitiert: die Rechenleistung der GPU und die Speicherbandbreite vom VRAM in die GPU-Cores. Speculative Decoding setzt beim zweiten Punkt ein, der oft der limitierende Faktor ist.)
In der Praxis funktioniert das nur mäßig gut: Zum einen ist es schwierig, ein geeignetes Draft Model zu finden. Es muss aus der gleichen »Familie« stammen, aber deutlich kleiner sein, idealerweise etwa um den Faktor zehn. Zum anderen funktioniert Speculative Decoding für Dense Models besser als für Mixture of Experts Models (MoE). Das Problem bei MoE besteht darin, dass bei jedem Token andere »Experten« zum Einsatz kommen können, was den Geschwindigkeitsvorteil von Speculative Decoding teilweise zunichtemacht. Kleinere MoE-Modelle für den Draft-Einsatz haben zudem oft eine andere Experten-Aufteilung, was die Acceptance Rate verringert.
Multi-Token Prediction (MTP) greift die Idee des Speculative Decoding auf. Der entscheidende Unterschied besteht darin, dass ein Modell ausreicht. Ein in das Modell integrierter Layer ist dafür zuständig, rasch ein paar Tokens (üblicherweise 2 bis 4) vorherzusagen. Das Gesamtmodell überprüft dann alle Token auf einmal, was nur unwesentlich mehr Zeit kostet, als ein Token zu berechnen. MTP erspart damit das umständliche Handling mit zwei Modellen.
Speculative Decoding und Multi-Token Prediction sind mit keinerlei Qualitätsverlust verbunden! Es werden exakt die gleichen Ergebnisse erzielt, weil jede Token-Sequenz vollständig kontrolliert und bei Abweichungen verworfen wird. Werfen Sie diesbezüglich einen Blick in das Video von Donata Capitella, das diesen Umstand anschaulich erklärt.
Für den erzielten Geschwindigkeitsgewinn ist der Prozentsatz der akzeptierten Draft Tokens entscheidend. Dieser variiert je Aufgabenstellung: Bei kreativem Text ist die Akzeptanzrate nur mittelmäßig, bei Code hingegen deutlich höher — ganz einfach deswegen, weil Code strengen Regeln folgt und weniger Spielraum als menschliche Sprachen bietet.
Leider ist auch MTP mit Nachteilen verbunden:
Das Modell muss für MTP konzipiert sein. MTP muss schon beim Training berücksichtigt werden. Das Modell benötigt einen zusätzlichen Layer für die Token Prediction. Aktuell gibt es nur eine einzige »freie« Modellfamilie mit MTP, nämlich Qwen 3.6 und dessen Variante Qwopus. Gemma-4-Modelle sollten demnächst folgen. In Zukunft wird MTP wohl zu einem Standard-Feature für freie Modelle.
Natürlich muss auch die Software MTP unterstützen. Weil viele Programme intern llama.cpp verwenden, wird MTP rasch weite Verbreitung finden.
Schließlich teilt sich MTP einen Nachteil mit Speculative Decoding: Es funktioniert bei herkömmlichen Dense-Modellen besser als bei MoE-Modellen (Mixture of Experts). Die ohnedies schon schnellen MoE-Modelle werden also nur geringfügig schneller oder, wie bei einigen meiner Tests, sogar langsamer. Bei den Dense-Modellen ist dagegen eine spürbare Verbesserung zu bemerken. Bei meinen Tests ca. +65%, bei einigen Benchmarks im Internet bis zu +100%, also eine Verdoppelung der Output-Token-Rate.
MTP ändert nichts an der Input-Verarbeitung (dem Prompt Processing, pp). Schneller wird nur der Output (die Token Generation, tg).
Dense versus Mixture of Experts (MoE): MoE ist schneller, kann aber qualitativ bei gleicher Modellgröße nicht ganz mithalten. Während bei Dense-Modellen immer alle Parameter aktiv sind, nutzen MoE-Modelle nur wenige, stets wechselnde »Experten«, also Subsets mit viel weniger Parametern. Das spart Zeit, aber kein »Experte« ist so gut wie das volle Modell. Dementsprechend sinkt die Qualität der Antworten, nicht massiv, aber spürbar.)
Praktische Erfahrungen
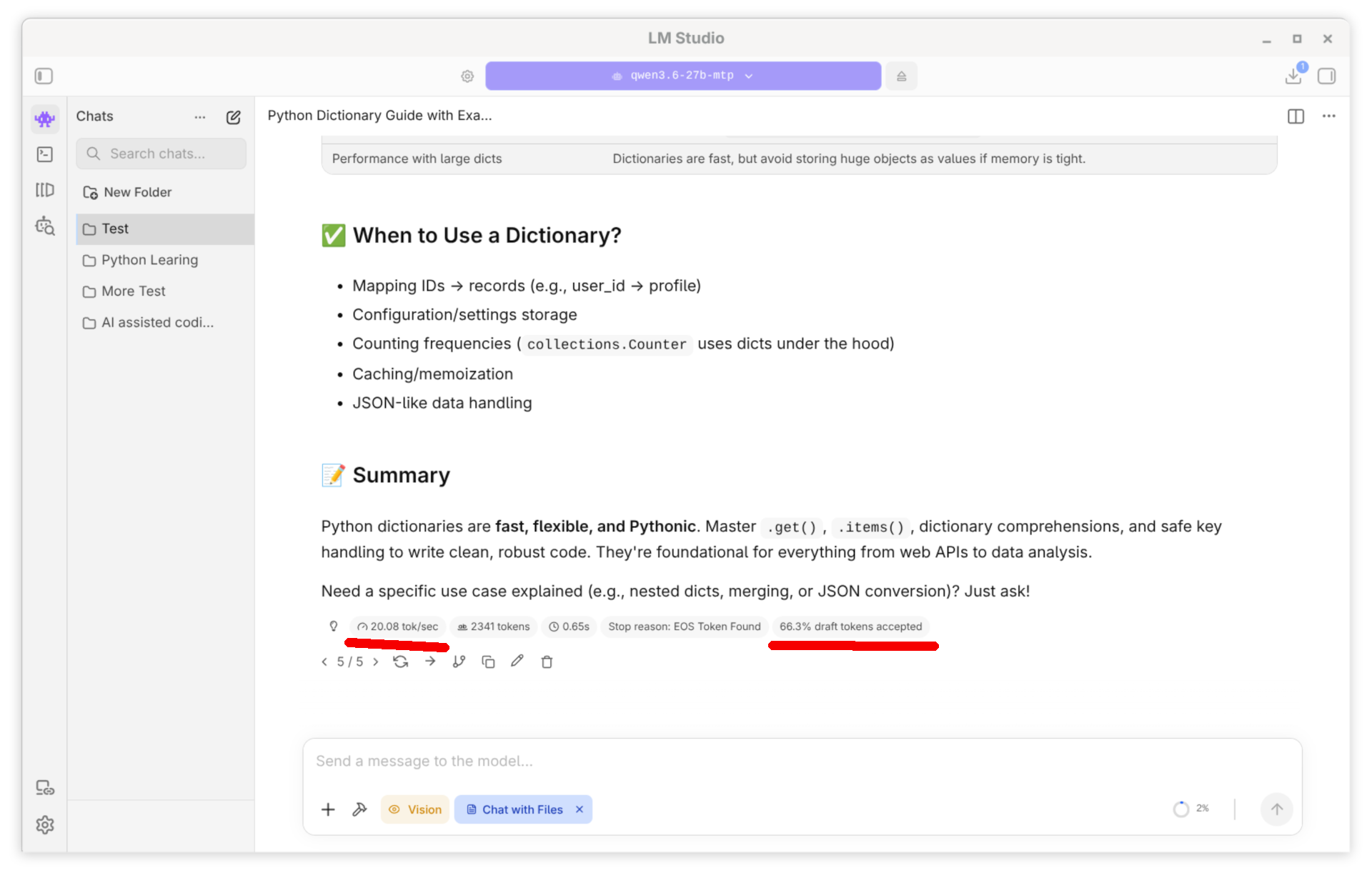
Ich habe MTP mit LM Studio 0.4.14 auf meinem Framework Desktop ausprobiert (AMD Ryzen Max 395 CPU/GPU). Mein Mini-Benchmarktests lautete: »Explain Python dictionaries«. Die getesteten Modelle denken über diese Frage eine Weile nach und produzieren dann einen mehrseitigen, qualitativ sehr hochwertigen Text mit eingebauten Code-Schnipseln.
LM Studio mit dem Modell Qwen 3.6 und Multi-Token Prediction (MTP)
Ich habe alle Tests mit einem Kontextfenster von 128.000 Token ausgeführt. Bei den MTP-Modellen habe ich die Einstellung MTP Max Tokens = 3 verwendet, also immer drei Tokens auf einmal erzeugt. Alle getesteten Modelle weisen eine 4-Bit-Quantisierung auf (Ausnahme: das APEX-Modell, siehe unten). Als Backend kommt llama.cpp mit Vulkan zum Einsatz.
Draft Token
Modell MoE APEX MTP Output (tg) Acceptance
----------------- ---- ---- ---- ------------ ------------------
qwen-3.6-27b nein nein nein 12,3 Token/s
qwen-3.6-27b-mtp nein nein ja 20,1 Token/s 66,3 %
qwopus-3.6-27b-v2-mtp nein nein ja 19,0 Token/s 63,7 %
qwen-3.6-35b-a3b ja nein nein 69,7 Token/s
qwen-3.6-35b-a3b-mtp ja nein ja 67,1 Token/s 66,6 %
qwen-3.6-35b-a3b-apex-mtp ja ja ja 71,5 Token/s 63,3 %
qwopus-3.6-35b-a3b-mtp ja nein ja 74,2 Token/s 68,2 %
Professionellere Benchmark-Tests hat Donata Capitella durchgeführt (siehe die ersten zwei Links in den Übersicht der Quellen am Ende des Artikels). Interessanterweise ist dort auch bei MoE-Modellen ein spürbarer Geschwindigkeitszuwachs von etwa 30% zu sehen, den ich bei meinen Tests aber nicht nachvollziehen kann.
Qwopus-Modelle
Die neuen Qwopus-Modelle basieren auf Qwen-Modellen, erhalten aber ein zusätzliches Fine-Tuning mit Claude Opus. Dieses soll den Nachdenkprozess beschleunigen und eine bessere Antwortqualität mit sich bringen. Die erste Versprechung trifft definitiv zu, aber ich bin nicht in der Lage, die Qualität des Modells im Detail zu beurteilen. Subjektiv hatte ich den Eindruck, dass die Unterschiede zu den Qwen-Originalen gering sind.
Zum Denkprozess: Beim Prompt »write a Sudoku solver in Python« denkt qwen-3.6-27b-mtp ca. 1:30 Minuten nach, qwopus-3.6-27b-v2-mtp aber ca. nur 1:00 Minuten. (Die Denkzeit hat eine relativ starke Varianz, weswegen hier genaue Angaben sinnlos sind.) Die resultierende Antwort samt Code ist mehr oder weniger gleichwertig (Backtracking-Algorithmus).
APEX Quantisierung
Die Verkleinerung von Modellen bei möglichst geringen Qualitätsverlust ist zu einer eigenen KI-Disziplin geworden. Die Grundidee besteht darin, Milliarden von Parametern (also eigentlich Fließkommazahlen) mit möglichst wenigen Bits darzustellen, ohne dass die Qualität der Ergebnisse allzu sehr leidet.
Der geringere Platzbedarf von Modellen ist insbesondere dann wichtig, wenn der Speicher (VRAM) limitiert ist. Mit einer geschickten Quantisierung läuft ein Modell vielleicht gerade noch auf einer GPU mit 16 GiB VRAM.
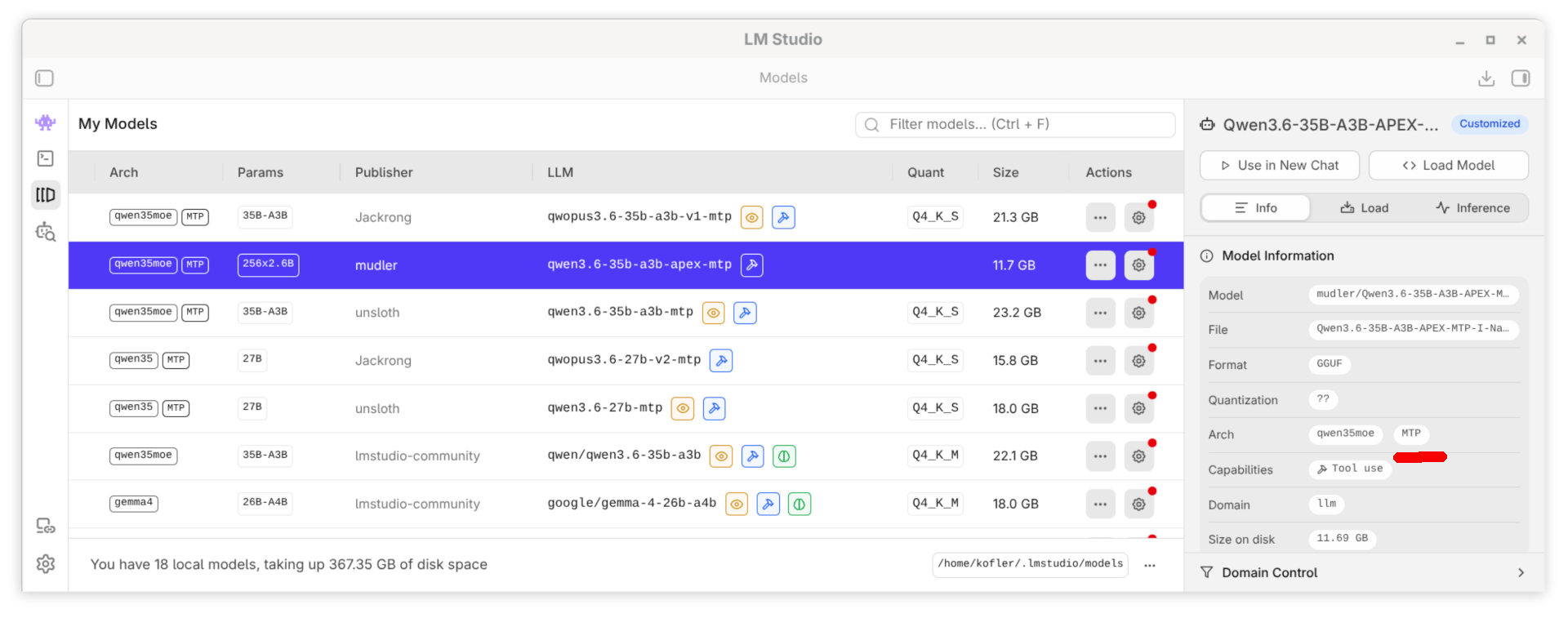
Vor ein paar Monaten machte Google mit dem neuen Turbo-Quant-Verfahren Furore. Bei der Recherche für diesen Artikel bin ich nun auf das neue Verfahren Adaptive Precision for EXpert Models (APEX) gestoßen. Das von Local AI entwickelte Verfahren ist speziell für MoE-Modelle optimiert und kompatibel zu aktuellen llama.cpp-Versionen. Die Grundidee besteht darin, dass für jede Parametergruppe eine andere, für den Wertebereich und die Wichtigkeit angepasste Quantisierung verwendet wird. Insofern ist eine klare Bit-Angabe (4 Bit pro Parameter) unmöglich. Technische Details und Benchmarks finden Sie auf der GitHub-Projektseite. Local AI arbeitet daran, Modelle lokal auf Smartphones auszuführen; da ist die möglichst platzsparende Darstellung natürlich wichtig.
Konkret sind APEX-Modelle zum Teil wirklich erheblich kleiner als vergleichbare Modelle mit Q4-Quantisierung, wie sie bei der lokalen Ausführung von Modellen üblich ist. Die folgende Tabelle zeigt lauter Qwen-3.6-Modelle mit jeweils 35 Milliarden Parameter. Das APEX-MTP-Modell benötigt nur halb so viel Platz wie das MTP-Modell mit einer herkömmlichen Q4-Quantisierung.
Überblick der heruntergeladenen Modelle in LM Studio
Leider verrät die Huggingface-Seite des Modells nicht, welche Variante der APEX-Quantisierung verwendet wurde. Es existieren verschiedene Qualitätsstufen, z.B. Quality, Balanced, Compact und Mini. Ich würde vermuten, das Modell ist eher bei Mini als bei Quality angesiedelt.
Bei der Ausführung des Modells waren für mich keine nennenswerten Unterschiede erkennbar, weder in der Geschwindigkeit noch qualitativ. Aber nochmals: Das sind subjektive Feststellungen anhand einiger Tests, keine objektiven Benchmark-Tests. Dazu fehlt mir ganz einfach die Zeit.
Die deutsch-französische „Taskforce für die Digitale Souveränität Europas", ins Leben gerufen beim Gipfel zur Europäischen Digitalen Souveränität am 18. November 2025 in Berlin, erarbeitet derzeit eine verbindliche Definition digitaler Souveränität. Diese soll künftig die Grundlage für deutsche und europäische Gesetzgebung sowie für Förder- und Beschaffungsprozesse bilden.
In dem vom Bundeskabinett beschlossenen Gesetzentwurf zur Stärkung der Cybersicherheit sieht der Digitalverband Bitkom zwar “eine Reihe guter Ansätze, mit denen die Cybersicherheit für…
Einer Umfrage der Beratungsfirma Mercer in den USA unter fast 1.000 CEOs diverser Unternehmen zufolge, wollen 99 Prozent in den nächsten zwei Jahren Mitarbeiter durch KI ersetzen.
Das bayerische Staatsministerium für Digitales will einen souveränen Arbeitsplatz mit “Alternativen zu proprietärer Arbeitsplatzsoftware” einführen, sprich ohne Microsoft Office.
Linux steht für Freiheit und Vielfalt an Linux Distributionen. Doch die wachsende Zahl an Distributionen wirft eine alte Frage neu auf. Hilft diese Auswahl wirklich jedem oder entsteht ein Effekt, der eher bremst als befreit. Viele Nutzer lieben die große Auswahl, doch andere fühlen sich schnell allein gelassen oder gar überfordert. Neue Distros erscheinen fast […]
Bayern startet ein neues Projekt für mehr digitale Unabhängigkeit. Das Digitalministerium entwickelt einen souveränen Arbeitsplatz, der langfristig proprietäre Lösungen ersetzen soll. Die Initiative folgt dem Beschluss der Ministerpräsidentenkonferenz, die bis 2027 sichere Alternativen fordert. Digitalminister Fabian Mehring betont die Bedeutung digitaler Souveränität für Staat und Verwaltung. Er sieht die öffentliche IT als kritische Infrastruktur, die […]
Google hat aus Versehen Exploit-Code veröffentlicht, der eine noch ungepatchte Schwachstelle in auf Chromium basierenden Browsern wie Googles Chrome, Microsofts Edge, Brave oder Opera ausnutzt.
AlmaLinux 10.2 erscheint als stabile Ausgabe und setzt auf Linux Kernel 6.12. Die neue Version basiert auf RHEL 10.2 erweitert den Funktionsumfang deutlich und stärkt die Unterstützung älterer Hardware. Besonders spannend ist die Rückkehr klassischer Treiber und die Einführung von i686 Paketen für 32 Bit Software. Die Distribution bietet nun Btrfs Boot Support. Damit lassen […]
Der neue COSMIC Desktop 1.0.14 zeigt, wie viel Feinschliff in einem kleinen Update stecken kann. System76 liefert eine Version, die viele Details verbessert und den Desktop im täglichen Einsatz spürbar angenehmer macht. Besonders Nutzer mit mehreren Monitoren dürfen sich über neue Möglichkeiten freuen. Eine der auffälligsten Neuerungen betrifft externe Displays. Der Desktop kann nun die […]
Die Diskussion um neue Altersprüfgesetze sorgt seit Monaten für Unruhe in der Open Source Welt. Nun bewegen sich Kalifornien und Colorado und schaffen klare Ausnahmen für freie Betriebssysteme und Community Software. Beide US Bundesstaaten reagieren damit auf deutliche Kritik aus der Linux Gemeinschaft. Kalifornien arbeitet derzeit an einer Anpassung des Digital Age Assurance Act. Der […]
Ein Problem unter macOS wurde behoben, bei dem Smartcards und Sicherheitsschlüssel Zertifikate nicht automatisch laden konnten.
Situationen, die bei Verwendung der geteilten Ansicht von Tabs zu einem unerwarteten Schließen von Tabs führen konnten, wurden korrigiert.
Es wurde ein Problem behoben, bei dem das Zwischenspeichern neuer Inhalte nicht mehr funktionierte, sobald der Festplatten-Cache voll war. Dies konnte dazu führen, dass Ressourcen bei jedem Besuch erneut aus dem Netzwerk heruntergeladen wurden.
Ein möglicher Absturz unter Windows wurde behoben, der bei Eingabe von vereinfachtem Chinesisch mit der Sogou-Eingabemethode auftrat. Außerdem wurde ein Absturz behoben, der Nutzer von macOS 26.5 betroffen hat.
Eine Reihe von Webkompatibilitätsproblemen wurden gelöst.
Auch in Zusammenhang mit dem KI-Feature Smart Window sowie der VPN-Integration wurden noch einmal Verbesserungen vorgenommen.
Leider hat das Update auf Firefox 151.0.2 eine Regression eingeführt, die dafür sorgt, dass die VPN-Schaltfläche in der Navigationssymbolleiste viel zu groß erscheint. Eine Korrektur hierfür befindet sich bereits in Arbeit.
Das neue adminForge-Frontend ist ab sofort live! Wir haben die gesamte Webseite grundlegend modernisiert, um Performance, Datenschutz und Benutzerfreundlichkeit auf das nächste Level zu heben.
Webseitenweite Suchfunktion mittels Lupe im Menü oder STRG+F nach Services
Wir hoffen, euch gefällt das neue, aufgeräumte Design. Feedback könnt ihr uns gerne im adminForge Chat hinterlassen!
Euer adminForge Team
Das Betreiben der Dienste, Webseite und Server machen wir gerne, kostet aber leider auch Geld.
Unterstütze unsere Arbeit mit einer Spende und diskutiere in unserem Chat mit.
MX Linux 25.2 erscheint als aktualisierte Ausgabe und setzt auf eine stabile Basis. Die neue Version der MX Linux 25 Serie nutzt Debian 13.5 und liefert aktuelle Pakete. Die AHS Variante setzt auf Linux 7.0 und richtet sich an Nutzer mit neuer Hardware. Die regulären Ausgaben verwenden den Debian Kernel 6.12. Die AHS Edition mit […]
Linux Mint gibt einen frühen Ausblick auf die kommenden Verbesserungen für die nächste Ausgabe. Die Entwickler arbeiten an spürbar schnellerer Dateiverwaltung und neuen Werkzeugen für den Alltag. Nemo reagiert nun flotter auf Eingaben. Der Dateimanager passt seine Darstellung dynamisch an und zeigt viele Ordner sofort. Die bisherige Verzögerung fällt damit in vielen Fällen weg. Auch […]
Mozilla hat Firefox Klar 151 (internationaler Name: Firefox Focus 151) für Android veröffentlicht.
Die Neuerungen von Firefox Klar 151 für Android
Bei Firefox Klar 151 handelt es sich um ein Wartungs-Update, bei welchem der Fokus auf Fehlerbehebungen und Verbesserungen unter der Haube lag. Dazu kommen wie immer neue Plattform-Features der aktuellen GeckoView-Engine sowie geschlossene Sicherheitslücken.
Mozilla hat Firefox 151 für Android veröffentlicht. Die neue Version bringt einige spannende Verbesserungen. Dieser Artikel beschreibt die Neuerungen von Firefox 151 für Android.
Künstliche Intelligenz (KI) ist ein Thema, welches mittlerweile omnipräsent ist. Die einen lieben es, andere möchten am liebsten gar nichts damit zu tun haben. Um die Verwaltung von KI-Funktionen einfacher zu machen, hat Mozilla die Firefox-Einstellungen um einen zusätzlichen Bereich mit der Bezeichnung „KI-Steuerung” erweitert. Dieser neue Bereich bietet einen Ort, um KI-Funktionen zentral zu steuern. Darüber hinaus bietet Firefox einen globalen Schalter zum Ein- und Ausschalten von KI-Funktionen an – welcher auch zukünftige KI-Features abschaltet.
Schütteln zum Zusammenfassen
Nutzer von Firefox für iOS kennen bereits die innovative Funktion „Schütteln zum Zusammenfassen”. Alternativ lassen sich die Inhalts-Zusammenfassungen aber auch über das Menü erreichen. Firefox 151 bringt diese Funktion auch auf Android, zunächst für englischsprachige Inhalte. Mit einem der kommenden Updates soll die Funktion dann auch in anderen Sprachen bereitstehen, darunter Deutsch. Diese Neuerung wird schrittweise in den kommenden Wochen ausgerollt.
Andere Suchmaschine für privaten Modus
Firefox hat bereits die Möglichkeit angeboten, eine beliebige Suchmaschine zu konfigurieren. Firefox 151 bringt zusätzlich die Möglichkeit, für den privaten Modus eine unterschiedliche Suchmaschine festzulegen.
Sonstige Neuerungen von Firefox 151 für Android
Über die Anpassen-Einstellungen lässt sich seit kurzem eine Schaltfläche neben der Adressleiste individuell belegen. Ab sofort besteht auch die Möglichkeit, auf eine zusätzliche Schaltfläche zu verzichten, womit mehr Platz für die Adressleiste bleibt.
Die Übersicht aller geöffneten Tabs lässt sich jetzt auch über eine Wischgeste von der Adressleiste aus öffnen. Außerdem hat die Tab-Übersicht eine Suchfunktion erhalten. Diese Neuerung wird schrittweise in den nächsten Wochen ausgerollt.
Die sogenannten „Secret Settings”, über welche sich vorab zukünftige Funktionen testen lassen, sind zwecks Übersichtlichkeit jetzt in verschiedene Kategorien unterteilt.
Dazu kommen weitere neue Plattform-Features der aktuellen GeckoView-Engine, diverse Fehlerbehebungen, geschlossene Sicherheitslücken sowie Verbesserungen unter der Haube.
Canonical hat die Arbeit an Ubuntu 26.10 aufgenommen und gibt damit den Startschuss für den nächsten Zwischenrelease. Die neue Version trägt den Namen Stonking Stingray und soll Mitte Oktober erscheinen. Ubuntu 26.10 folgt auf die aktuelle LTS Ausgabe Ubuntu 24.04 und setzt den Fokus auf frische Technik. Die Planung deutet auf GNOME 51 und einen […]
Fedora verabschiedet sich vom Deepin Desktop Environment (DDE). Die Entscheidung folgt einer langen Reihe technischer Warnsignale und fehlender Pflege durch das verbliebene Entwicklerteam. FESCo, das zentrale technische Gremium des Projekts, stimmte dem Vorschlag zu, nachdem wiederholte Hinweise auf ungeprüfte sicherheitsrelevante Komponenten aufkamen. Besonders betroffen waren der Dateimanager und mehrere Dienste, die sensible Schnittstellen nutzten. Fedora […]
Die MZLA Technologies Corporation hat mit Thunderbird 151 eine neue Version seines Open Source E-Mail-Clients für Windows, Apple macOS und Linux veröffentlicht.
Neuerungen von Thunderbird 151
Mit Thunderbird 151 hat die MZLA Technologies Corporation ein Update für seinen Open Source E-Mail-Client veröffentlicht.
Details des OAuth-Anbieters für EWS-Konten können überschrieben werden. Aufgaben können nach Erstellungs- oder Änderungsdatum sortiert werden. Verbesserungen gab es für die Anmeldung mit den kommenden Thundermail-Konten.
Ansonsten bringt die neue Version wie immer weitere kleinere Verbesserungen und eine ganze Reihe von Fehlerkorrekturen, welche sich wie immer in den Release Notes (engl.) nachlesen lassen. Auch Sicherheitslücken wurden im neuesten Update wieder behoben.