Mozilla hat Firefox Klar 127 (internationaler Name: Firefox Focus 127) für Android veröffentlicht.
Die Neuerungen von Firefox Klar 127 für Android
Bei Firefox Klar 127 handelt es sich um ein Wartungs-Update, bei welchem der Fokus auf Fehlerbehebungen und Verbesserungen unter der Haube lag. Dazu kommen wie immer neue Plattform-Features der aktuellen GeckoView-Engine sowie geschlossene Sicherheitslücken.
Die Open Source Business Alliance und die Open Logistics Foundation werden in Zukunft enger zusammenarbeiten. Dazu haben die beiden Organisationen kürzlich ein Memorandum of Understanding unterzeichnet. Die Kooperation soll den Einsatz von Open Source in den Bereichen Wirtschaft und Industrie fördern.
Sonys PC-Ports zeigen nicht nur, wie man Konsolenspiele vernünftig auf den PC bringt, sondern präsentieren sich auch oft direkt ab Release mit guter Linux-Kompatibilität. Im Fall von Ghost of Tsushima versprach Sony selbst Steam-Deck-Unterstützung. Wie sich der Titel darauf und auf dem Linux-Desktop schlägt, klärt dieser Test.
Wer bist du, wie kommst du zur Stadt Dortmund und was tust du?
Ich bin Katharina Flisikowski und seit Kurzem im CIIO – Chief Information/Innovation Office der Stadt Dortmund für Digitale Souveränität und Open Source zuständig. Meinen Background habe ich in den Medien- und Sozialwissenschaften.
In der Vergangenheit habe ich im Projektmanagement gearbeitet sowie im Bereich Kommunikation und Transfer. Mehrere Jahre lang besetzte ich die Stabsstelle Qualität und Kommunikation eines interkulturellen Trägers der Sozialen Arbeit, wo ich viel über Organisationsstrukturen sowie die Optimierung von Prozessen gelernt habe.
Meine letzte Station war ein Leibniz-Projekt am Deutschen Bergbau-Museum Bochum. Dort entwickelte ich Konzepte für den Transfer von Wissen zwischen Forschung und Bürger*innen. Mit dem Ende des Projekts wollte ich mich weiterhin für einen offenen Zugang zu Wissen einsetzen. Passenderweise fiel das in die Zeit, in der die Stelle der Stadt Dortmund ausgeschrieben war – und hier bin ich nun!
Was begeistert dich am Thema Open Source?
Mich motiviert der Gedanke an eine starke, gleichberechtigte und selbstbestimmte Gesellschaft.
Aktuelle Entwicklungen, wie etwa Angriffe auf Infrastrukturen oder aber auch das Schüren von Ängsten durch Fake News und Verschwörungserzählungen, stellen dabei reale Gefährdungen dar, denen eine Demokratie wehrhaft begegnen muss.
Daher ist es für uns unerlässlich, die Fragen zu stellen: Wie wird Wissen hergestellt und verbreitet? Wie transparent sind Strukturen? Haben wir als Gesellschaft die Handlungsfähigkeit, die wir brauchen, um uns sicher und stark im physischen und digitalen Raum zu bewegen? Und wie schaffen wir es, uns technologisch und gesellschaftlich weiter- und nicht zurückzuentwickeln?
Als ein Teil Digitaler Souveränität bietet Open Source hierbei einen Ansatz, der in eben diese Richtung geht: Durch das Teilen von Wissen (über den Code hinaus) entsteht eine Transparenz, die Vertrauen schafft. Der multiple Blick auf Lösungen gibt einerseits Sicherheit, andererseits macht er Innovation und somit Fortschritt möglich. So werden wir als Gesellschaft zur selbstbestimmten Gestalterin unserer Zukunft – was will man mehr!
Einen weiteren Aspekt, den ich an Open Source sehr schätze, ist der Community-Gedanke: Ich finde es erstrebenswert, gemeinsam an Lösungen zu wirken, anstatt im Alleingang oder gar in Rivalität zu tüfteln und dann doch das Rad immer wieder neu zu erfinden. Kooperation und Kollaboration bringen uns hier viel weiter.
Was sind deine ersten Schritte als Koordinatorin für Digitale Souveränität und Open Source bei der Stadt Dortmund?
Da ich selbst nicht aus Dortmund komme, nutzte ich die erste Zeit dafür, die Stadt und die Menschen, die sie ausmachen, kennenzulernen. Dazu gehört auch, die Entwicklungen der Stadt Dortmund im Hinblick auf Digitale Souveränität zu betrachten, schließlich gibt es schon einige Ansätze und politische Beschlüsse in diese Richtung.
Als Nächstes geht es darum, aus dieser Bestandsaufnahme einen Fahrplan zu entwickeln. Hier freue ich mich darauf, in den Austausch mit einzelnen Akteur*innen zu treten, sowohl inner- als auch außerhalb der Dortmunder Stadtverwaltung. Die ersten Gespräche fanden bereits statt, nun gilt es, diese Kontakte zu vertiefen und weitere zu knüpfen.
Angesichts der ständigen Weiterentwicklung von Technologie und Gesetzgebung, wie hast du vor auf dem neuesten Stand zu bleiben und wie beeinflusst dies deine Herangehensweise an deine Projektplanung und -umsetzung im Bereich Digitaler Souveränität und Open Source?
Hier ist Netzwerk das Stichwort – Open Source lebt vom Community-Gedanken und genau hierin sehe ich auch die Stärke: Mit einem Pool an unterschiedlichen Expertisen, Erfahrungen und Blickwinkeln ist es möglich, verschiedene Aspekte zu durchleuchten und so zu neuen Erkenntnissen zu gelangen. Ich bin ein großer Fan des interdisziplinären Austauschs, weil man so voneinander lernen und sich weiterentwickeln kann. Wissen und Erfahrung sind wertvolle Ressourcen – diese zu teilen wiederum macht uns als Gesellschaft stark.
Was ist deine Hoffnung an deine neue Stelle für dich selbst, aber auch für die Aufgabe?
Ich hoffe, dass wir gemeinsam mit den vielen Beteiligten, Interessierten ebenso wie den noch nicht ganz Überzeugten einen Weg finden, das Thema Digitale Souveränität in unsere Alltagspraxis fest zu verankern. Für die Stadt Dortmund sind die ersten Weichen ja bereits gestellt, nun gilt es, das Triebwerk zu befeuern und Fahrt aufzunehmen.
Dabei geht es nicht darum, so schnell wie möglich und um jeden Preis sämtliche Strukturen abzulösen. Vielmehr geht es darum, Wahlmöglichkeiten und Handlungsspielräume zu erweitern, die Menschen mitzunehmen und ein Bewusstsein für Abhängigkeiten zu schaffen.
Persönlich erhoffe ich mir, dass wir mit unserer Arbeit einen Beitrag für eine sichere, wehrhafte und selbstbestimmte Gesellschaft leisten. Ich bin mir sicher, dass wir dem gemeinsam in einem großen Netzwerk, dem Ökosystem der Digitalen Souveränität, einen Schritt näherkommen.
Ich freue mich darauf, daran mitzuwirken!
Wir wünschen uns allen viel Erfolg bei der Umsetzung von Open-Source-first und freuen uns auf die konkrete Zusammenarbeit!
Soweit im gesetzlichen Rahmen möglich verzichtet der Autor auf alle Urheber- und damit verwandten Rechte an diesem Werk.
Es kann beliebig genutzt, kopiert, verändert und veröffentlicht werden.
Für weitere Informationen zur Lizenz, siehe hier.
Bilder sind eingefrorene persönliche Erinnerungen, die eigentlich auf Google Photos nicht zu suchen haben. Die Fotoverwaltung Immich ist angetreten, das zu ändern.
In den vergangengenen Wochen habe ich die erste »echte« Ubuntu-Server-Installation durchgeführt. Abgesehen von aktuelleren Versionsnummern (siehe auch meinen Artikel zu Ubuntu 24.04) sind mir nicht allzu viele Unterschiede im Vergleich zu Ubuntu Server 22.04 aufgefallen. Bis jetzt läuft alles stabil und unkompliziert. Erfreulich für den Server-Einsatz ist die Verlängerung des LTS-Supports auf 12 Jahre (erfordert aber Ubuntu Pro); eine derart lange Laufzeit wird aber wohl nur in Ausnahmefällen sinnvoll sein.
Update 1 am 25.6.2024: Es gibt immer noch keinen finalen Fix für fail2ban, aber immerhin einen guter Workaround (Installation des proposed-Fix).
Update 2 am 29.6.2024: Es gibt jetzt einen regulären Fix.
fail2ban-Ärger
Recht befremdlich ist, dass fail2ban sechs Wochen nach dem Release immer noch nicht funktioniert. Der Fehler ist bekannt und wird verursacht, weil das Python-Modul asynchat mit Python 3.12 nicht mehr ausgeliefert wird. Für die Testversion von Ubuntu 24.10 gibt es auch schon einen Fix, aber Ubuntu 24.04-Anwender stehen diesbezüglich im Regen.
Persönlich betrachte ich fail2ban als essentiell zur Absicherung des SSH-Servers, sofern dort Login per Passwort erlaubt ist.
Update 1:
Mittlerweile gibt es einen proposed-Fix, der wie folgt installiert werden kann (Quelle: [Launchpad](https://bugs.launchpad.net/ubuntu/+source/fail2ban/+bug/2055114)):
* In `/etc/apt/sources.list.d/ubuntu.sources` einen Eintrag für `noble-proposed` hinzufügen, z.B. so:
„`
# zusätzliche Zeilen in `/etc/apt/sources.list.d/ubuntu.sources
Types: deb
URIs: http://archive.ubuntu.com/ubuntu/
Suites: noble-proposed
Components: main universe restricted multiverse
Signed-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
„`
Beachten Sie, dass sich Ort und Syntax für die Angabe der Paketquellen geändert haben.
* `apt update`
* `apt-get install -t noble-proposed fail2ban`
* in `/etc/apt/sources.list.d/ubuntu.sources` den Eintrag für `noble-proposed` wieder entfernen (damit es nicht weitere Updates aus dieser Quelle gibt)
* `apt update`
Update 2: Der Fix ist endlich offiziell freigegeben. apt update und apt full-upgrade, fertig.
/tmp mit tmpfs im RAM
Das Verzeichnis /tmp wird unter Ubuntu nach wie vor physikalisch auf dem Datenträger gespeichert. Auf einem Server mit viel RAM kann es eine Option sein, /tmp mit dem Dateisystemtyp tmpfs im RAM abzubilden. Der Hauptvorteil besteht darin, dass I/O-Operationen in /tmp dann viel effizienter ausgeführt werden. Dagegen spricht, dass die exzessive Nutzung von /tmp zu Speicherproblemen führen kann.
Auf meinem Server mit 64 GiB RAM habe ich beschlossen, max. 4 GiB für /tmp zu reservieren. Die Konfiguration ist einfach, weil der Umstieg auf tmpfs im systemd bereits vorgesehen ist:
systemctl enable /usr/share/systemd/tmp.mount
Mit systemctl edit tmp.mount bearbeiten Sie die neue Setup-Datei /etc/systemd/system/tmp.mount.d/override.conf, die nur Änderungen im Vergleich zur schon vorhandenen Datei /etc/systemd/system/tmp.mount bzw. /usr/share/systemd/tmp.mount enthält.
# wer keinen vi mag, zuerst: export EDITOR=/usr/bin/nano
systemctl edit tmp.mount
Dies ist mein Erfahrungsbericht zu den ersten Schritten mit InstructLab. Ich gehe darauf ein, warum ich mich über die Existenz dieses Open Source-Projekts freue, was ich damit mache und was ich mir von Large Language Models (kurz: LLMs, zu Deutsch: große Sprachmodelle) erhoffe. Der Text enthält Links zu tiefergehenden Informationen, die euch mit Hintergrundwissen versorgen und einen Einstieg in das Thema ermöglichen.
Dieser Text ist keine Schritt-für-Schritt-Anleitung für:
Beim Bezug auf große Sprachmodelle bediene ich mich der englischen Abkürzung LLM oder bezeichne diese als KI-ChatBot bzw. nur ChatBot.
Was ist InstructLab?
InstructLab ist ein von IBM und Red Hat ins Leben gerufenes Open Source-Projekt, mit dem die Gemeinschaft zur Verbesserung von LLMs beitragen kann. Jeder
Hugging Face. The AI community building the future. The platform where the machine learning community collaborates on models, datasets, and applications. URL: https://huggingface.co/
Meine Einstellung gegenüber KI-ChatBots
Gegenüber KI-Produkten im Allgemeinen und KI-ChatBots im Speziellen bin ich stets kritisch, was nicht bedeutet, dass ich diese Technologien und auf ihnen basierende Produkte und Services ablehne. Ich versuche mir lediglich eine gesunde Skepsis zu bewahren.
Was Spielereien mit ChatBots betrifft, bin ich sicherlich spät dran. Ich habe schlicht keine Lust, mich irgendwo zu registrieren und unnötig Informationen über mich preiszugeben, nur um anschließend mit einer Büchse chatten und ihr Fragen stellen zu können, um den Wahrheitsgehalt der Antworten anschließend noch verifizieren zu müssen.
Mittlerweile gibt es LLMs, welche ohne spezielle Hardware auch lokal ausgeführt werden können. Diese sprechen meine Neugier und meinen Spieltrieb schon eher an, weswegen ich mich nun doch mit einem ChatBot unterhalten möchte.
Der lokale LLM-Server wird mit dem Befehl ilab serve gestartet. Mit dem Befehl ilab chat wird die Unterhaltung mit dem Modell eingeleitet.
Im folgenden Video sende ich zwei Anweisungen an das LLM merlinite-7b-lab-Q4_K_M. Den Chatverlauf seht ihr in der rechten Bildhälfte. In der linken Bildhälfte seht ihr die Ressourcenauslastung meines Laptops.
Screencast eines Chats mit merlinite-7b-lab-Q4_K_M
Wie ihr seht, sind die Antwortzeiten des LLM auf meinem Laptop nicht gerade schnell, aber auch nicht so langsam, dass ich währenddessen einschlafe oder das Interesse an der Antwort verliere. An der CPU-Auslastung im Cockpit auf der linken Seite lässt sich erkennen, dass das LLM durchaus Leistung abruft und die CPU fordert.
Mit den Antworten des LLM bin ich zufrieden. Sie decken sich mit meiner Erinnerung und ein kurzer Blick auf die Seite https://www.json.org/json-de.html bestätigt, dass die Aussagen des LLM korrekt sind.
Anmerkung: Der direkte Aufruf der Seite https://json.org, der mich mittels Redirect zu obiger URL führte, hat sicher deutlich weniger Energie verbraucht als das LLM oder eine Suchanfrage in irgendeiner Suchmaschine. Ich merke dies nur an, da ich den Eindruck habe, dass es aus der Mode zu geraten scheint, URLs einfach direkt in die Adresszeile eines Webbrowsers einzugeben, statt den Seitennamen in eine Suchmaske zu tippen.
Ich halte an dieser Stelle fest, der erste kleine Test wird zufriedenstellend absolviert.
KI-Halluzinationen
Da ich einige Zeit im Hochschulrechenzentrum der Universität Bielefeld gearbeitet habe, interessiert mich, was das LLM über meine ehemalige Dienststelle weiß. Im nächsten Video frage ich, wer der Kanzler der Universität Bielefeld ist.
Frage an das LLM: „Who is the chancellor of the Bielefeld University?“
Da ich bis März 2023 selbst an der Universität Bielefeld beschäftigt war, kann ich mit hinreichender Sicherheit sagen, dass diese Antwort falsch ist und das Amt des Kanzlers nicht von Prof. Dr. Karin Vollmerd bekleidet wird. Im Personen- und Einrichtungsverzeichnis (PEVZ) findet sich für Prof. Dr. Vollmerd keinerlei Eintrag. Für den aktuellen Kanzler Dr. Stephan Becker hingegen schon.
Da eine kurze Recherche in der Suchmaschine meines geringsten Misstrauens keine Treffer zu Frau Vollmerd brachte, bezweifle ich, dass diese Person überhaupt existiert. Es kann allerdings auch in meinen unzureichenden Fähigkeiten der Internetsuche begründet liegen.
Bei der vorliegenden Antwort handelt es sich um eine Halluzination der Künstlichen Intelligenz.
Im Bereich der Künstlichen Intelligenz (KI) ist eine Halluzination (alternativ auch Konfabulation genannt) ein überzeugend formuliertes Resultat einer KI, das nicht durch Trainingsdaten gerechtfertigt zu sein scheint und objektiv falsch sein kann.
Solche Phänomene werden in Analogie zum Phänomen der Halluzination in der menschlichen Psychologie als von Chatbots erzeugte KI-Halluzinationen bezeichnet. Ein wichtiger Unterschied ist, dass menschliche Halluzinationen meist auf falschen Wahrnehmungen der menschlichen Sinne beruhen, während eine KI-Halluzination ungerechtfertigte Resultate als Text oder Bild erzeugt. Prabhakar Raghavan, Leiter von Google Search, beschrieb Halluzinationen von Chatbots als überzeugend formulierte, aber weitgehend erfundene Resultate.
Oder wie ich es umschreiben möchte: „Der KI-ChatBot demonstriert sichereres Auftreten bei völliger Ahnungslosigkeit.“
Wenn ihr selbst schon mit ChatBots experimentiert habt, werdet ihr sicher selbst schon auf Halluzinationen gestoßen sein. Wenn ihr mögt, teilt doch eure Erfahrungen, besonders jene, die euch fast aufs Glatteis geführt haben, in den Kommentaren mit uns.
Welche Auswirkungen überzeugend vorgetragene Falschmeldungen auf Nutzer haben, welche nicht über das Wissen verfügen, diese Halluzinationen sofort als solche zu entlarven, möchte ich für den Moment eurer Fantasie überlassen.
Ich denke an Fahrplanauskünfte, medizinische Diagnosen, Rezepturen, Risikoeinschätzungen, etc. und bin plötzlich doch ganz froh, dass sich die EU-Staaten auf ein erstes KI-Gesetz einigen konnten, um KI zu regulieren. Es wird sicher nicht das letzte sein.
Um das Beispiel noch etwas auszuführen, frage ich das LLM erneut nach dem Kanzler der Universität und weise es auf seine Falschaussagen hin. Der Chatverlauf ist in diesem Video zu sehen:
ChatBot wird auf Falschaussage hingewiesen
Die Antworten des LLM enthalten folgende Fehler:
Professor Dr. Ulrich Heidt ist nicht der Kanzler der Universität Bielefeld
Die URL ‚https://www.uni-bielefeld.de/english/staff/‘ existiert nicht
Die URL ‚http://www.universitaet-bielefeld.de/en/‘ existiert ebenfalls nicht
Die Universität hieß niemals „Technische Universitaet Braunschweig“
Der Chatverlauf erweckt den Eindruck, dass der ChatBot sich zu rechtfertigen versucht und nach Erklärungen und Ausflüchten sucht. Hier wird nach meinem Eindruck menschliches Verhalten nachgeahmt. Dabei sollten wir Dinge nicht vermenschlichen. Denn unser Chatpartner ist kein Mensch. Er ist eine leblose Blechbüchse. Das LLM belügt uns auch nicht in böser Absicht, es ist schlicht nicht in der Lage, uns eine korrekte Antwort zu liefern, da ihm dazu das nötige Wissen bzw. der notwendige Datensatz fehlt. Daher versuche ich im nächsten Schritt, dem LLM mit InstructLab das notwendige Wissen zu vermitteln.
Wissen und Fähigkeiten hinzufügen und das Modell anlernen
Das README.md im Repository instructlab/taxonomy enthält die Beschreibung, wie man dem LLM Wissen (englisch: knowledge) hinzufügt. Weitere Hinweise finden sich in folgenden Dateien:
Diese Dateien befinden sich auch in dem lokalen Repository unterhalb von ~/instructlab/taxonomy/. Ich hangel mich an den Leitfäden entlang, um zu sehen, wie weit ich damit komme.
Wissen erschaffen
Die Überschrift ist natürlich maßlos übertrieben. Ich stelle lediglich existierende Informationen in erwarteten Dateiformaten bereit, um das LLM damit trainieren zu können.
Da aktuell nur Wissensbeiträge von Wikipedia-Artikeln akzeptiert werden, gehe ich wie folgt vor:
Konvertiere den Wikipedia-Artikel Bielefeld University ohne Bilder und Tabellen in eine Markdown-Datei und füge sie dem in Schritt 1 erstellten Repository unter dem Namen unibi.md hinzu
Füge dem lokalen Taxonomy-Repository neue Verzeichnisse hinzu: mkdir -p university/germany/bielefeld_university
Erstelle in dem neuen Verzeichnis eine qna.yaml und eine attribution.txt Datei
Führe ilab diff aus, um die Daten zu validieren
Der folgende Code-Block zeigt den Inhalt der Dateien qna.yaml und eine attribution.txt sowie die Ausgabe des Kommandos ilab diff:
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/qna.yaml
version: 2
task_description: 'Teach the model the who facts about Bielefeld University'
created_by: tronde
domain: university
seed_examples:
- question: Who is the chancellor of Bielefeld Universtiy?
answer: Dr. Stephan Becker is the chancellor of the Bielefeld University.
- question: When was the University founded?
answer: |
The Bielefeld Universtiy was founded in 1969.
- question: How many students study at Bielefeld University?
answer: |
In 2017 there were 24,255 students encrolled at Bielefeld Universtity?
- question: Do you know something about the Administrative staff?
answer: |
Yes, in 2017 the number for Administrative saff was published as 1,100.
- question: What is the number for Academic staff?
answer: |
In 2017 the number for Academic staff was 1,387.
document:
repo: https://github.com/Tronde/instructlab_knowledge_contributions_unibi.git
commit: c2d9117
patterns:
- unibi.md
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ cat /home/tronde/src/instructlab/taxonomy/knowledge/university/germany/bielefeld_university/attribution.txt
Title of work: Bielefeld University
Link to work: https://en.wikipedia.org/wiki/Bielefeld_University
License of the work: CC-BY-SA-4.0
Creator names: Wikipedia Authors
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$
(venv) [tronde@t14s instructlab]$ ilab diff
knowledge/university/germany/bielefeld_university/qna.yaml
Taxonomy in /taxonomy/ is valid :)
(venv) [tronde@t14s instructlab]$
Synthetische Daten generieren
Aus der im vorherigen Abschnitt erstellten Taxonomie generiere ich im nächsten Schritt synthetische Daten, welche in einem folgenden Schritt für das Training des LLM genutzt werden.
(venv) [tronde@t14s instructlab]$ ilab generate
[…]
INFO 2024-05-28 12:46:34,249 generate_data.py:565 101 instructions generated, 62 discarded due to format (see generated/discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log), 4 discarded due to rouge score
INFO 2024-05-28 12:46:34,249 generate_data.py:569 Generation took 12841.62s
(venv) [tronde@t14s instructlab]$ ls generated/
discarded_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.log
generated_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.json
test_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
train_merlinite-7b-lab-Q4_K_M_2024-05-28T09_12_33.jsonl
Zur Laufzeit werden alle CPU-Threads voll ausgelastet. Auf meinem Laptop dauerte dieser Vorgang knapp 4 Stunden.
Das Training beginnt
Jetzt wird es Zeit, das LLM mit den synthetischen Daten anzulernen bzw. zu trainieren. Dieser Vorgang wird mehrere Stunden in Anspruch nehmen und ich verplane mein Laptop in dieser Zeit für keine weiteren Arbeiten.
Um möglichst viele Ressourcen freizugeben, beende ich das LLM (ilab serve und ilab chat). Das Training beginnt mit dem Befehl ilab train… und dauert wirklich lange.
Nach 2 von 101 Durchläufen wird die geschätzte Restlaufzeit mit 183 Stunden angegeben. Das Ergebnis spare ich mir dann wohl für einen Folgeartikel auf und gehe zum Fazit über.
Fazit
Mit dem InstructLab Getting Started Guide gelingt es in kurzer Zeit, das Projekt auf einem lokalen Linux-Rechner einzurichten, ein LLM auszuführen und mit diesem zu chatten.
KI-Halluzinationen stellen in meinen Augen ein Problem dar. Da LLMs überzeugend argumentieren, kann es Nutzern schwerfallen oder gar misslingen, die Falschaussagen als solche zu erkennen. Im schlimmsten Fall lernen Nutzer somit dummen Unfug und verbreiten diesen ggf. weiter. Dies ist allerdings kein Problem bzw. Fehler des InstructLab-Projekts, da alle LLMs in unterschiedlicher Ausprägung von KI-Halluzinationen betroffen sind.
Wie Knowledge und Skills hinzugefügt werden können, musste ich mir aus drei Guides anlesen. Dies ist kein Problem, doch kann der Leitfaden evtl. noch etwas verbessert werden.
Knowledge Contributions werden aktuell nur nach vorheriger Genehmigung und nur von Wikipedia-Quellen akzeptiert. Der Grund wird nicht klar kommuniziert, doch ich vermute, dass dies etwas mit geistigem Eigentum und Lizenzen zu tun hat. Wikipedia-Artikel stehen unter einer Creative Commons Attribution-ShareAlike 4.0 International License und können daher unkompliziert als Quelle verwendet werden. Da sich das Projekt in einem frühen Stadium befindet, kann ich diese Limitierung nachvollziehen. Ich wünsche mir, dass grundsätzlich auch Primärquellen wie Herstellerwebseiten und Publikationen zugelassen werden, wenn Rechteinhaber dies autorisieren.
Der von mir herangezogene Wikipedia-Artikel ist leider nicht ganz aktuell. Nutze ich ihn als Quelle für das Training eines LLM, bringe ich dem LLM damit veraltetes und nicht mehr gültiges Wissen bei. Das ist für meinen ersten Test unerheblich, für Beiträge zum Projekt jedoch nicht sinnvoll.
Die Generierung synthetischer Daten dauert auf Alltagshardware schon entsprechend lange, das anschließende Training jedoch nochmals bedeutend länger. Dies ist meiner Ansicht nach nichts, was man nebenbei auf seinem Laptop ausführt. Daher habe ich den Test auf meinem Laptop abgebrochen und lasse das Training aktuell auf einem Fedora 40 Server mit 32 GB RAM und 10 CPU-Kernen ausführen. Über das Ergebnis und einen Test des verbesserten Modells werde ich in einem folgenden Artikel berichten.
Was ist mit euch? Kennt ihr das Projekt InstructLab und habt evtl. schon damit gearbeitet? Wie sind eure Erfahrungen?
Arbeitet ihr mit LLMs? Wenn ja, nutzt ihr diese nur oder trainiert ihr sie auch? Was nutzt ihr für Hardware?
Ich freue mich, wenn ihr eure Erfahrungen hier mit uns teilt.
Nicht immer lässt sich zeitnah über jede Neuigkeit berichten, manche Ereignisse sind es aber dennoch wert, Erwähnung zu finden. In dieser Zusammenfassung überblickt die Redaktion alle wichtigen Meldungen aus der Linux-Welt der vorangegangenen Woche.
Ich hatte es geahnt, aber dann ging es doch schneller als gedacht. Mit der Entscheidung des Europäischen Gerichtshofes Ende April wurde in einem Fall in Frankreich die Speicherung von IP-Adressen seitens des ISPs auf Vorrat nicht nur für den Bereich schwerer Straftaten, sondern auch für Urheberrechtsverstöße für zulässig erachtet. Damit ist eine Diskussion wieder auf dem Tisch, die seit 20 Jahren regelmäßig aufflammt, aber bisher durch Urteile gegen die erlassenen Gesetze eingefangen wurde.
Mit diesem Thema haben wir uns vergangene Woche mit Professor Dr. Stephan G. Humer in der 48. Episode des Risikozone-Podcasts beschäftigt, den ich euch wärmstens empfehlen kann.
Die klassische VDS in Deutschland wird momentan nicht praktiziert, da sie nach einem älteren Urteil des EuGH, das konkret das deutsche Gesetz betraf, als rechtswidrig eingestuft wurde. Nichtsdestotrotz ist die Diskussion wieder eröffnet und alle Möglichkeiten für Vorhaben zur Wiedereinführung werden wieder eingebracht. Das Thema wird uns also weiterhin noch eine ganze Weile verfolgen.
Klar, im Urteil des EuGH wird als Bedingung gestellt, dass Maßnahmen getroffen werden müssen, damit die Privatsphäre der einzelnen Nutzer gewahrt bleibt, aber das ändert nichts daran, dass die Daten grundsätzlich erstmal erhoben werden. Die "Neuerung" in diesem Urteil zu der Thematik ist, dass IP-Adressen und Identitäten getrennt gespeichert werden müssen. Mir ist allerdings noch nicht einleuchtend, was im Urteil mit der "Verknüpfung nur unter Verwendung eines leistungsfähigen technischen Verfahrens [...], das die Wirksamkeit der strikten Trennung dieser Datenkategorien nicht in Frage stellt" gemeint ist. Sollen die Datenbanken mit einem anschließend zu verwerfenden Schlüssel verschlüsselt werden, der bei der Verknüpfung erst geknackt werden muss? Am Ende kann ein technisches Verfahren doch gar nicht feststellen, ob ein Gesuch den formellen juristischen Anforderungen genügt oder nicht.
Technisch reden wir hier im Übrigen von zwei Teilaspekten: einerseits die Speicherung, welche Stationen (mit welchen IP-Adressen) miteinander kommunizieren und andererseits, wer hinter welcher IP-Adresse steckt. Diese ganze letzte Thematik haben wir allerdings nur, weil die ISPs einerseits ungern Privatkunden feste IP-Adressen vergeben und andererseits mitunter gar nicht so viele IP(v4)-Adressen wie Kunden haben und dann zu Tricks wie CG-NAT greifen müssen. Hämisch könnte man jetzt fragen, warum in dem Zusammenhang die Politik noch nicht alle zu IPv6 verpflichtet hat. Auf der anderen Seite wird deutlich, wie sehr sich das Internet verändert hat, nachdem es ein Massenmedium wurde.
Früher wurden feste IP-Adressen genutzt und die Zuordnung größtenteils öffentlich hinterlegt. Die Teilnehmer des Internets kannten sich mehr oder weniger sowieso alle untereinander. Als das Internet mehr und mehr ein Massenmedium wurde, ging es allerdings nicht mehr um den wissenschaftlichen oder beruflichen Austausch, sondern auch vorrangiger um das private Leben, wodurch auf einmal Grundrechte tangiert wurden und das Thema der Anonymität im Netz aufkam.
Gespeichert werden die Zuordnungen wohl auch weiterhin noch, aber sichtbar sind sie nur noch für Behörden und ähnliche Organisationen. Spätestens mit dem breiten Ausrollen der DSGVO wurde z. B. der whois-Dienst der DENIC für die Öffentlichkeit geschlossen. Wer einen Webseitenbetreiber ermitteln möchte, der kein Impressum auf der Seite stehen hat, schaut seitdem in die Röhre.
Vorratsdatenspeicherung ist und bleibt somit ein netzpolitisches Thema und lässt sich somit nicht auf der rein technischen Ebene erklären. Von da aus kann man sich oft an den Kopf fassen, was da alles von der Technik erwartet wird. Solche Themen sind auch ein Abbild der Gesellschaftspolitik, was daran deutlich wird, dass im Wesentlichen Deutschland eines der wenigen kritischen Länder diesbezüglich ist.
Die Never-ending-Story geht jetzt also in die nächste Runde. Weitere Probleme, Risiken und Lösungsansätze könnt ihr gerne euch in unserem Podcast anhören und in den Kommentaren mitdiskutieren.
Die Linux-Kommandoreferenz ist erstmalig 1995 erschienen. Die Kommandoreferenz war damals aber nur ein 56 Seiten langes Kapitel in der ersten Auflage meines Linux-Buchs. Aufgrund von Platzproblemen musste ich das Kommandoreferenz-Kapitel 15 Jahre später aus dem Linux-Buch entfernen und in ein eigenes Buch auslagern. Die erste Auflage im Taschenbuchformat hatte noch schlanke 176 Seiten. In der gerade neu erschienen sechsten Auflage hat das Buch den dreifachen Umfang!
547 Seiten, Hard-Cover
ISBN: 978-3-367-10103-0
Preis: Euro 29,90 (in D inkl. MWSt.)
Vor 15 Jahren zweifelten der Verlag und ich, ob die Kommandoreferenz überhaupt ein sinnvolles Buch wäre. Natürlich lassen sich alle Kommandos im Internet recherchieren. Heute verrät auch ChatGPT die gerade relevanten Optionen von find oder grep.
Dessen ungeachtet geben die Verkaufszahlen eine klare Botschaft: Ja, es gibt ganz offensichtlich den Bedarf nach einer Linux-Kommandoreferenz, die das Wesentliche vom Unwesentlichen trennt, die anhand thematischer Übersichten einen Startpunkt in das riesige Universum der Linux-Kommandos bietet, die mit vielen Beispielen alltägliche »Linux-Praxis« vermittelt. Keines meiner Bücher öffne ich selbst so oft (natürlich als PDF-Datei), um irgendein Detail rasch nachzulesen!
Für die 6. Auflage habe ich das Buch einmal mehr komplett aktualisiert. Die folgenden Kommandos habe ich neu aufgenommen:
Außerdem habe ich die Beschreibung vieler Kommandos aktualisiert oder mit zusätzlichen Beispielen versehen, unter anderem bei acme.sh, chmod, convert, curl, dd, find, firewall-cmd, mail, nmcli, pip und tcpdump.
Am 14. Mai 2024 war es wieder soweit: Der 2. Sovereign Cloud Stack Summit fand in der Villa Elisabeth in Berlin statt. Das denkmalgeschützte Gebäude mit seinem historischen Charme und dem angrenzenden Park bot für die rund 200 Teilnehmenden die perfekte Kulisse für das jährliche Get-together der SCS Community, von Entscheiderinnen und Entscheidern und Open-Source-Enthusiasten aus Wirtschaft, Politik und Zivilgesellschaft.
Am 9. Juni 2024 findet in Deutschland die Europawahl statt. Die Open Source Business Alliance hat im Vorfeld Wahlprüfsteine an die Parteien verschickt, um ihre politischen Ziele rund um die Themen digitale Souveränität und Open Source für die nächste Wahlperiode im Europaparlament zu erfragen. Mit den Antworten können sich die Wahlberechtigten einen Überblick über die Positionen der Parteien verschaffen.
Vor über vier Jahren hatte ich mich schon einmal mit dieser Thematik im Artikel „TURN-Server für Nextcloud Talk“ auseinandergesetzt. Über die Jahre hinweg hat sich jedoch einiges geändert und ich konnte mein Wissen ausbauen. Aus diesem Grund möchte ich nun meine aktuellsten Erkenntnisse noch einmal zusammenhängend präsentieren.
Installation
Ein TURN-Server wird von Nextcloud Talk benötigt, um Videokonferenzen zu ermöglichen. Der TURN-Server bringt die Teilnehmer, welche sich in verschiedenen Netzwerken befinden, zusammen. Nur so ist eine reibungslose Verbindung unter den Teilnehmern in Nextcloud Talk möglich.
Wer bisher meinen Anleitungen zur Installation von Nextcloud auf dem Raspberry Pi gefolgt ist, kann nun die eigene Cloud für Videokonferenzen fit machen. Zu bedenken gilt aber, dass ein eigener TURN-Server nur bis maximal 6 Teilnehmer Sinn macht. Wer Konferenzen mit mehr Teilnehmern plant, muss zusätzlich einen Signaling-Server integrieren.
Nun zur Installation des TURN-Servers. Zuerst installiert man den Server mit
sudo apt install coturn
und kommentiert folgende Zeile, wie nachfolgend zu sehen in /etc/default/coturn aus.
sudo nano /etc/default/coturn
Dabei wird der Server im System aktiviert.
#
# Uncomment it if you want to have the turnserver running as
# an automatic system service daemon
#
TURNSERVER_ENABLED=1
Nun legt man die Konfigurationsdatei zum TURN-Server mit folgendem Inhalt an.
Hier werden u.a. der Port und das Passwort des Servers sowie die Domain der Cloud eingetragen. Natürlich muss hier noch der Port im Router freigegeben werden. Ein starkes Passwort wird nach belieben vergeben.
Hierbei kann das Terminal hilfreich sein. Der folgende Befehl generiert z.B. ein Passwort mit 24 Zeichen.
gpg --gen-random --armor 1 24
Jetzt wird der Server in den Verwaltungseinstellungen als STUN- und TURN-Server inkl. Listening-Port sowie Passwort eingetragen.
Nextcloud – Verwaltungseinstellungen – TalkEintrag der Domain für STUN- und TURN-Server (sowie Passwort)
Bei meinen ersten Versuchen auf dem Raspberry Pi fiel auf, dass der Service des TURN-Servers schneller startet als das gesamte System, was einen Betrieb unmöglich machte. Diese Problematik konnte ich wie im Artikel „coTurn zeitverzögert auf Raspberry Pi starten“ beschrieben, lösen. Leider überstand aber dieser Eingriff kein Systemupgrade. Durch einen sehr hilfreichen Kommentar von Matthias, kann ich nun eine bessere Lösung aufzeigen.
Es wird mit
sudo systemctl edit coturn.service
der Service des Servers editiert. Folgender Eintrag wird zwischen die Kommentare gesetzt:
### Editing /etc/systemd/system/coturn.service.d/override.conf
### Anything between here and the comment below will become the new contents of the file
[Service]
ExecStartPre=/bin/sleep 30
### Lines below this comment will be discarded
### /lib/systemd/system/coturn.service
Dies ermöglicht den TURN-Server (auch nach einem Upgrade) mit einer Verzögerung von 30 Sekunden zu starten.
Zum Schluss wird der Service neu gestartet.
sudo service coturn restart
Ein Check zeigt, ob der TURN-Server funktioniert. Hierzu klickt man auf das Symbol neben dem Papierkorb in der Rubrik TURN-Server der Nextcloud. Wenn alles perfekt läuft ist, wird im Screenshot, ein grünes Häkchen sichtbar.
Einmal wollte ich faul sein und gleichzeitig einem FOSS-Projekt etwas Gutes tun. Anstelle mich immer selbst um ein Update von LibreOffice zu kümmern, wollte ich es aus dem Apple App Store installieren, via selbigen an das Projekt spenden und die Downloadzahlen im Store um eine Wertigkeit erhöhen. Automatische Updates im Hintergrund sollten hier die Wahl ... Weiterlesen
Broadcom bietet ab sofort VMware Workstation Pro und Fusion Player für die private Nutzung kostenlos an. Wer das Angebot nutzen möchte, sollte Geduld und gute Nerven mitbringen.
Die auf Arch Linux basierende Distribution CachyOS bietet gleich drei interessante Neuerungen: Der Installationsassistent kann mit dem Bcachefs-Dateisystem umgehen, es gibt ein SDK für…
Screen Sharing mit dem Raspberry Pi war schon immer ein fehleranfälliges Vergnügen. In der Vergangenheit hat die Raspberry Pi Foundation auf die proprietäre RealVNC-Software gesetzt. Zuletzt war RealVNC aber nicht Wayland-kompatibel. Die Alternative ist wayvnc, ein Wayland-kompatible VNC-Variante: Wie ich unter Remote Desktop und Raspberry Pi OS Bookworm schon berichtet habe, ist wayvnc aber nicht mit allen Remote-Clients kompatibel, insbesondere nicht mit Remotedesktopverbindung von Microsoft.
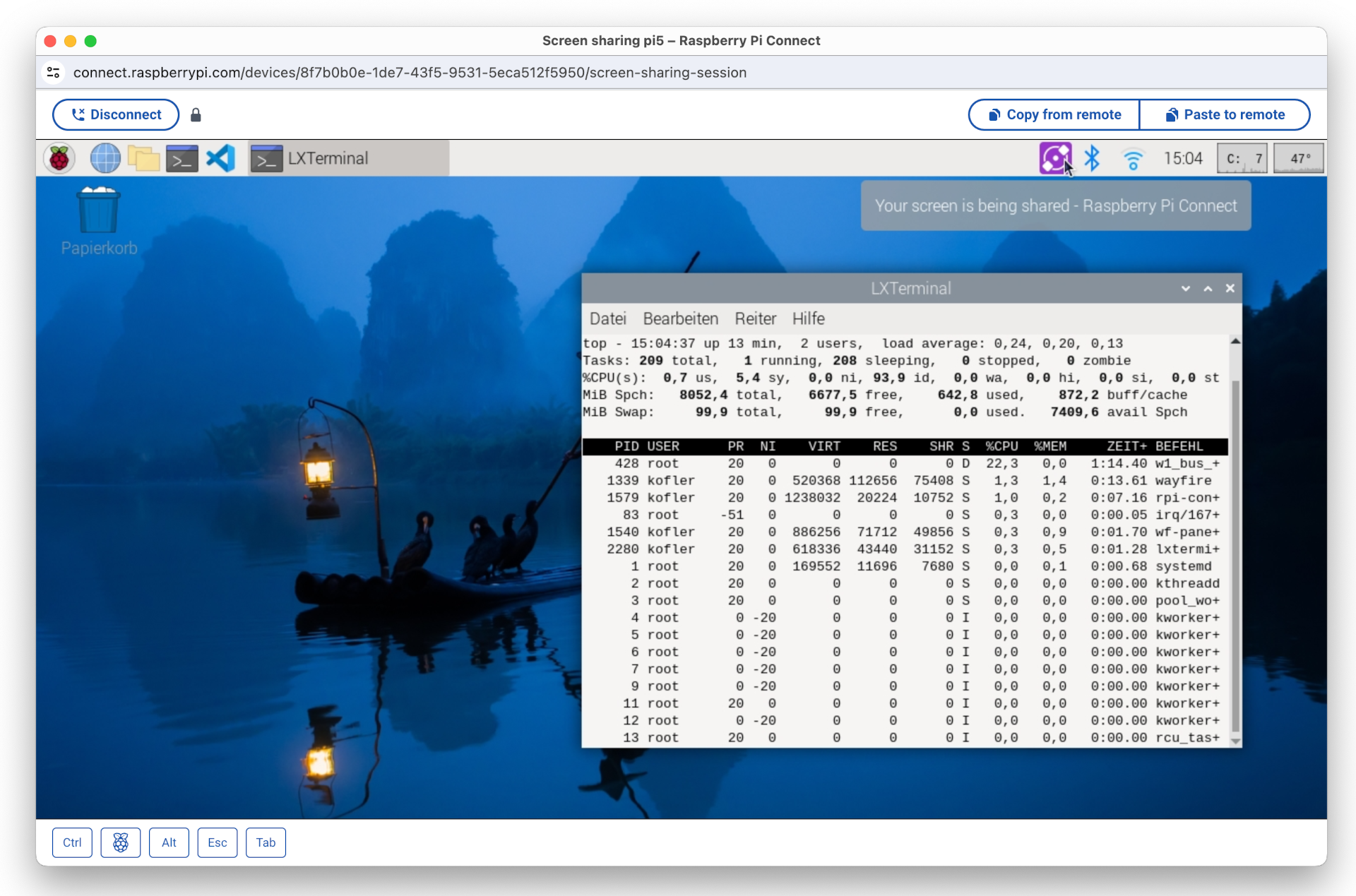
Anfang Mai 2024 hat die Raspberry Pi Foundation mit Raspberry Pi Connect eine eigene Lösung präsentiert. Ich habe das System ausprobiert. Um das Ergebnis gleich vorwegzunehmen: Bei meinen Tests hat alles bestens funktioniert, selbst dann, wenn auf beiden Seiten private Netzwerke mit Network Address Translation (NAT) im Spiel sind. Das Setup ist sehr einfach, als Client reicht ein Webbrowser. Geschwindigkeitswunder sind aber nicht zu erwarten, selbst im lokalen Netzwerk treten spürbare Verzögerungen auf.
Der Zugriff auf den Raspberry-Pi-Client erfolgt hier in einem Fenster des Webbrowsers Google Chrome unter macOS
Voraussetzungen
Raspberry Pi Connect setzt voraus, dass Sie die aktuelle Raspberry-Pi-Version »Bookworm« verwenden und dass der PIXEL Desktop in einer Wayland-Session läuft. Das schränkt die Modellauswahl auf 4B, 400 und 5 ein. Ob Ihr Desktop Wayland nutzt, überprüfen Sie am einfachsten im Terminal:
echo $XDG_SESSION_TYPE
wayland
Gegebenenfalls können Sie mit raspi-config zwischen Xorg und Wayland umschalten (Menüpunkt Advanced Options / Wayland).
Installation
Die Software-Installation verläuft denkbar einfach:
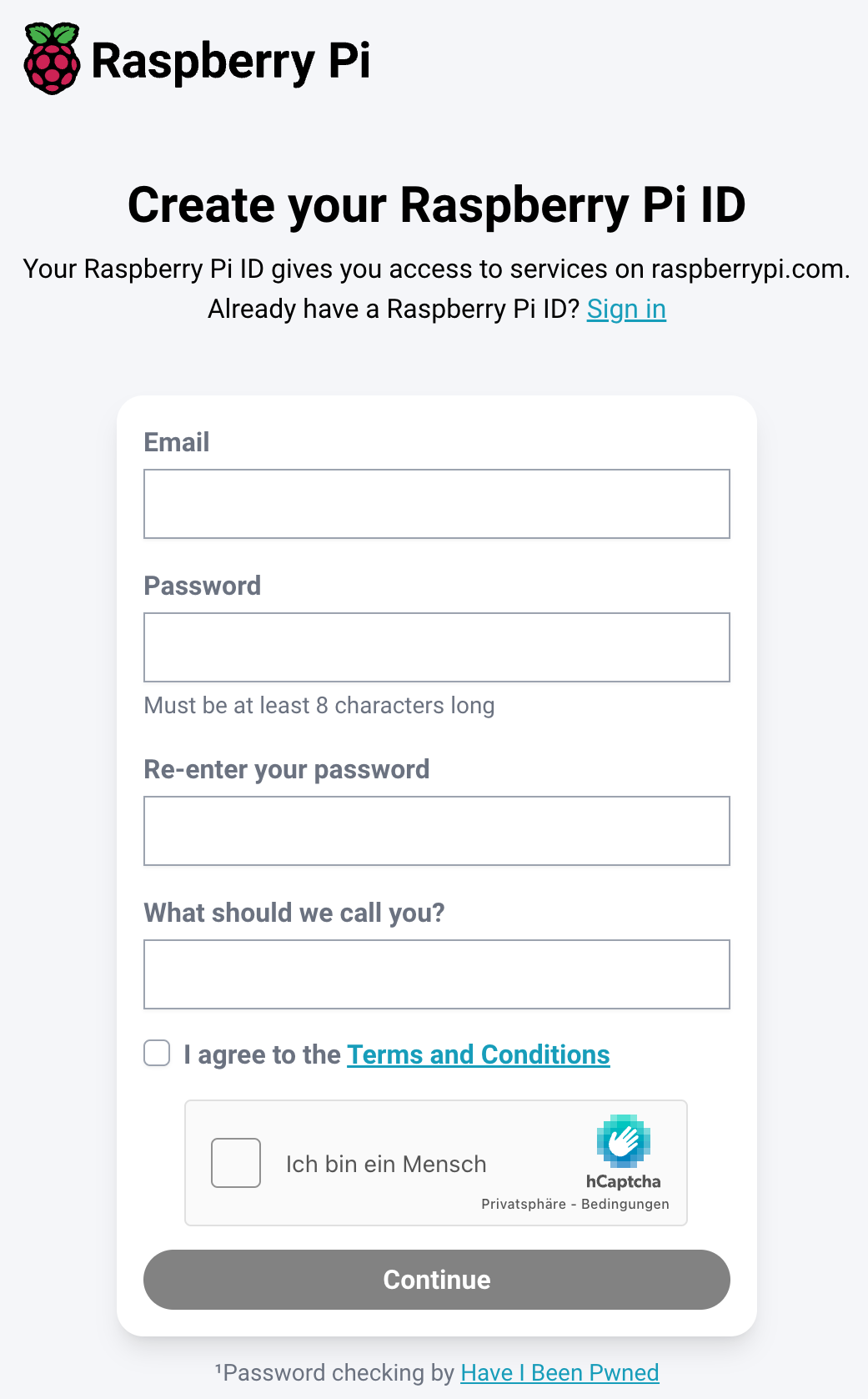
Nach der Installation erscheint ein neues Icon im Panel des PIXEL Desktops. Über dessen Menüeintrag Sign in gelangen Sie auf die Website https://connect.raspberrypi.com/sign-in. Dort müssen Sie eine Raspberry-Pi-ID einrichten. Die Eingabefelder sind auf ein Minimum beschränkt: E-Mail-Adresse, Passwort (2x) und Name. Fertig!
Bevor Sie Raspberry Pi Connect nutzen können, müssen Sie eine Raspberry Pi ID einrichten.
Fernzugriff
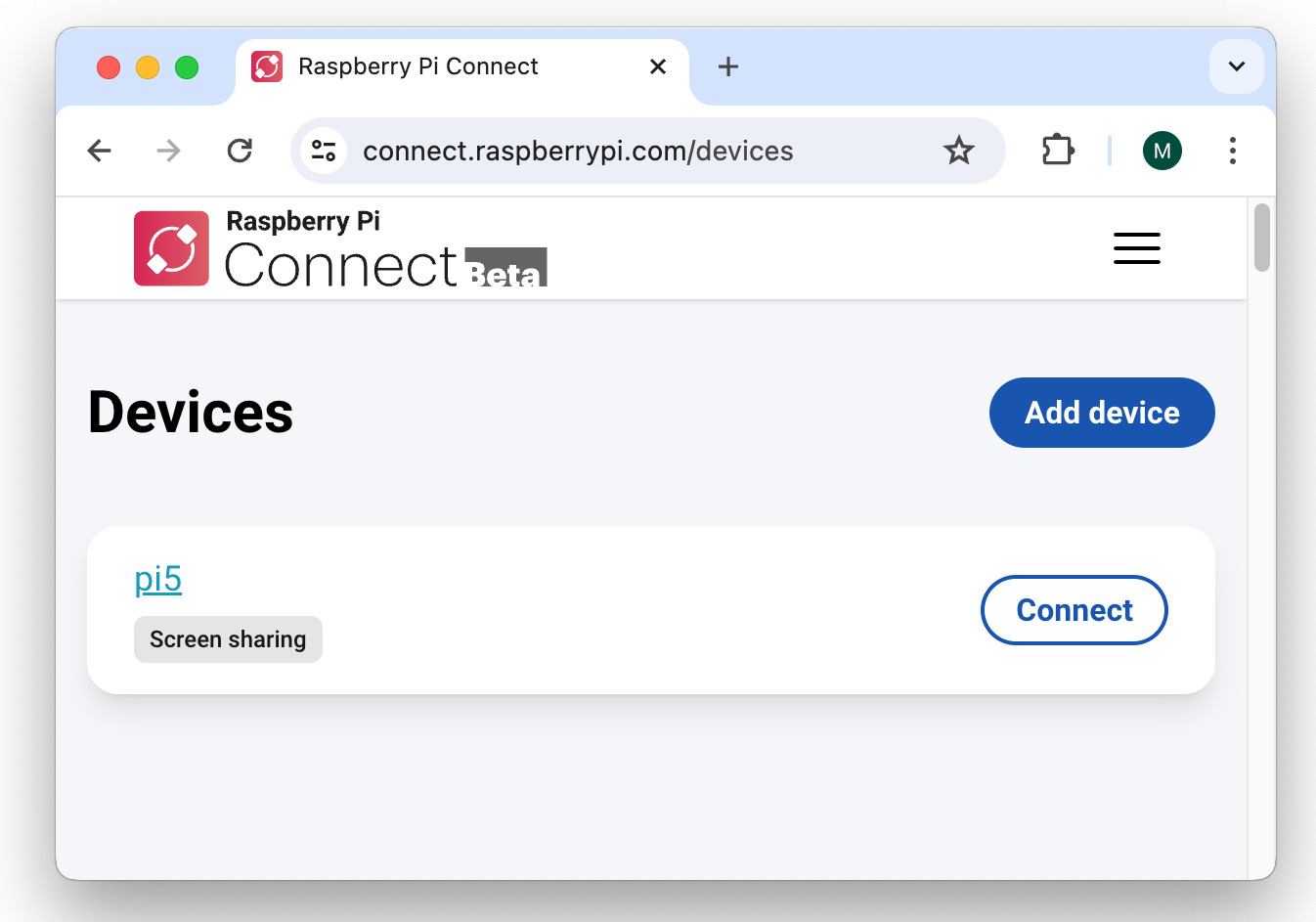
Um nun von einem anderen Rechner auf den PIXEL Desktop Ihres Raspberry Pis zuzugreifen, melden Sie sich dort ebenfalls auf der Website https://connect.raspberrypi.com/sign-in an. Dort werden alle registrierten Geräte aufgelistet. (Mit einer Raspberry-Pi-ID können als mehrere Raspberry Pis verknüpft werden.)
Remote-Verbindungsaufbau im Webbrowser
Praktische Erfahrungen
Bei meinen Tests hat Raspberry Pi Connect ausgezeichnet funktioniert. Der Verbindungsaufbau war problemlos. Der Desktop-Inhalt erscheint in einem neuen Browser-Fenster. Der Desktop-Inhalt wird automatisch auf die Fenstergröße skaliert. Die Bedienung ist denkbar simpel. Über zwei Buttons können Texte über die Zwischenablage kopiert bzw. eingefügt werden.
Raspberry Pi Connect testet beim Verbindungsaufbau, ob sich der Raspberry Pi und Ihr Client-Rechner (z.B. Ihr Notebook) im gleichen Netzwerk befinden. Wenn das der Fall ist, stellt der Client eine direkte Peer-to-Peer-Verbindung zum Raspberry Pi her. Nach dem Verbindungsaufbau fließen keine Daten mehr über den Raspberry-Pi-Connect-Server. Die Verbindungsgeschwindigkeit ist dann spürbar höher. Dennoch ist es empfehlenswert, die Bildschirmauflösung auf dem Raspberry Pi nicht höher einzustellen als notwendig.
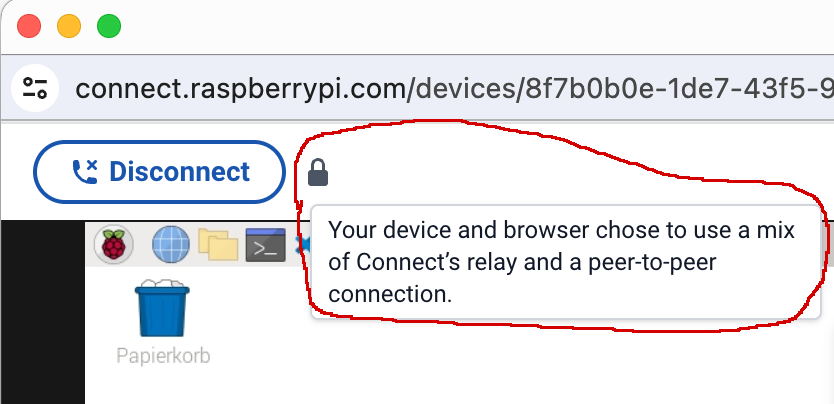
Wenn sich Ihr Pi und Ihr Client-Rechner dagegen in unterschiedlichen (privaten) Netzwerken befinden, agiert ein Server der Raspberry Pi Foundation als Relay. Sowohl der Bildschirminhalt als auch alle Eingaben werden verschlüsselt nach Großbritannien und wieder zurück übertragen. Selbst wenn alle Geräte eine gute Internetverbindung haben, ist ein gewisser Lag unvermeidlich.
Details über die Art der Verbindung erfahren Sie, wenn Sie den Mauszeiger auf das Schloss-Icon im Screen-Sharing-Fenster bewegen.
Wenn Sie den Mauszeiger über das Schloss-Icon bewegen, erscheint ein Info-Text zum Status der Verbindung
Wenn die Remote-Desktop-Verbindung nicht im lokalen Netzwerk stattfindet, fließt der ganze Netzwerkverkehr über einen Relay-Server in Großbritannien. Dabei kommt das Protokoll Traversal Using Relays around NAT (kurz TURN) zum Einsatz. Die Daten werden TLS-verschlüsselt.
Der entscheidende Schwachpunkt des Systems besteht darin, dass es aktuell nur einen einzigen TURN-Server gibt. Je mehr gleichzeitige Remote-Desktop-Verbindungen aktiv sind, desto langsamer wird das Vergnügen … (Und besonders schnell ist es schon im Idealfall nicht.)
Fazit
Raspberry Pi Connect punktet vor allem durch seine Einfachheit.
Am Raspberry Pi reicht es aus, rpi-connect zu installieren.
Die Raspberry-Pi-ID kann rasch und unkompliziert eingerichtet werden.
Die Anwendung im Webbrowser funktioniert plattformübergreifend und einfach.
Allzu hohe Performance-Anforderungen sollten Sie nicht haben. Die Nachlaufzeiten bei Mausbewegungen und gar beim Verschieben eines Fensters sind beachtlich. Für administrative Arbeiten reicht die Geschwindigkeit aber absolut aus.
Schließlich bleibt abzuwarten, wie gut die Software skaliert. Aktuell befindet sich Raspberry Pi Connect noch in einem Probebetrieb. Soweit sich der Raspberry Pi und der Client-Rechner nicht im gleichen lokalen Netzwerk befinden, werden die Bildschirmdaten über einen Relay in Großbritannien geleitet. Aktuell gibt es genau einen derartigen Relay. Je mehr Anwender Raspberry Pi Connect gleichzeitig nutzen, desto langsamer wird es. Die Raspberry Pi Foundation lässt sich aktuell überhaupt offen, ob es den Relay-Betrieb dauerhaft kostenlos anbieten kann.
Seit Nextcloud Hub 8 (29.0.0) ist ChatGPT nicht mehr über den Picker der Nextcloud zu erreichen. Dieser Umstand kann Nerven kosten, wenn OpenAI’s KI-Dienst hin und wieder genutzt wird und man plötzlich feststellt, dass dieser nicht mehr funktioniert. So ging es mir, als ich den in die Nextcloud integrierten KI-Assistenten einem kleinen Publikum vorstellen wollte. Da das neueste Release 29.0.0 noch recht frisch ist, findet man derzeit wenig Hinweise, wie man ChatGPT weiter nutzen kann.
Einrichtung
Dies hat mich nun dazu bewogen einen kleinen Artikel hierzu zu schreiben. Grundvoraussetzung ist jedoch ein Account beim US-amerikanischen Softwareunternehmen OpenAI bei dem ein API-Key erstellt wird.
Des weiteren müssen in der Nextcloud die Apps OpenAI and LocalAI integration und Nextcloud Assistant hinzugefügt und aktiviert werden.
Nextcloud – OpenAI and LocalAI integration und Nextcloud Assistant
Im Anschluss wird der API-Key, wie im Screenshot zu sehen ist, in der App OpenAI and LocalAI integration hinterlegt.
Nextcloud – OpenAI and LocalAI integration (API Key)
Nun kann man über den neuen Nextcloud-Assistent das KI-Tool nutzen.
Da ich einiges an Zeit in meine auf dem Raspberry Pi 4 laufende Nextcloud investiert habe, wäre es schade, für das aktuelle Raspberry Pi OS 12, alles noch einmal aufsetzen und konfigurieren zu müssen. Obwohl die Entwickler des Betriebssystems von einem Upgrade generell abraten, habe ich mich auf die Suche nach einer guten und funktionierenden Anleitung gemacht und bin auf den vielversprechenden Artikel „Raspberry Pi OS – Update von Bullseye (11) auf Bookworm (12)“ von Sascha Syring gestoßen.
Um das Ganze ausgiebig zu testen, habe ich das Upgrade zuerst auf einem Raspberry Pi 4 durchgeführt, auf dem ein Mumble-Server läuft, den unsere Community produktiv zum Erfahrungsaustausch nutzt. Nachdem dies alles problemlos funktioniert hat, habe ich mich an meinen Nextcloud-RasPi gewagt. Was es weiter zu beachten gab, darauf gehe ich am Ende des Artikels noch ein.
Systemupgrade
Bevor es los geht muss das System auf den aktuellsten Stand unter Raspberry Pi OS 11 Bullseye gebracht werden. Hierzu führt man Folgendes aus:
Danach werden die Paketquellen auf das neue System Bookworm angepasst. Hierzu öffnet man die /etc/apt/sources.list
sudo nano /etc/apt/sources.list
und kommentiert alle aktiven Quellen, indem man vor jede aktive Zeile eine Raute „#“ setzt. Danach fügt man die drei Zeilen
deb http://deb.debian.org/debian bookworm main contrib non-free non-free-firmware
deb http://security.debian.org/debian-security bookworm-security main contrib non-free non-free-firmware
deb http://deb.debian.org/debian bookworm-updates main contrib non-free non-free-firmware
am Anfang ein und speichert die Datei mit Ctr + o ab und verlässt dann den Editor mit Ctr + x.
Paketquellen
Das Gleiche Spiel wiederholt man mit den zusätzlichen Paketquellen.
sudo nano /etc/apt/sources.list.d/raspi.list
Hier wird nun folgende Zeile an den Anfang gesetzt:
deb http://archive.raspberrypi.org/debian/ bookworm main
Die Datei wird mit Ctr + o gespeichert und der Editor mit Ctr + x verlassen. Ist dies geschehen, können die Paketquellen neu eingelesen werden.
Zusätzliche Paketquellen
sudo apt update
Bootpartition
Nun kommt der kniffligste Teil. Die Bootpartition muss an die neuen Gegebenheiten angepasst werden. Dazu wird die alte Boot-Partition ausgehängt.
sudo umount /boot
Dann wird das neue Verzeichnis /boot/firmware erstellt.
sudo mkdir /boot/firmware
Jetzt bearbeitet man die Partitionstabelle:
sudo nano /etc/fstab
Hier wird der Eintrag der Bootpartition entsprechend eingetragen. Bei mir sieht das so aus:
Datei zum Einbinden der Datenträger
Die Datei wird wieder mit Ctr + o gespeichert und der Editor mit Ctr + x verlassen. Damit die Änderungen wirksam werden, wird systemd neu geladen
sudo systemctl daemon-reload
und die neue Boot-Partition gemountet.
sudo mount /boot/firmware
Bootloader und Kernel
Im Nachgang werden die aktuelle Firmware und der aktuelle Kernel für das Raspberry Pi OS 12 (Bookworm) installiert
Ist dies geschehen, müssen die Paketquellen nochmalig mit
sudo apt update
eingelesen werden.
Upgrade
Nun kann das eigentlich Upgrade durchgeführt werden. Hierbei stoppt der Vorgang bei den wichtigsten Konfigurationsdateien. Diese werden in der Regel alle beibehalten.
sudo apt full-upgrade
System aufräumen
Nun wird das System noch aufgeräumt.
sudo apt autoremove
sudo apt clean
Neustart
Nach dem Neustart
sudo reboot now
sollte nun das aktuelle Raspberry Pi OS 12 laufen. Das installierte Betriebssystem lässt man sich mit
Abschließend sei darauf hingewiesen, dass das Upgrade einige Gefahren in sich birgt. Bitte vorher unbedingt an ein Backup denken, was im Bedarfsfall wieder eingespielt werden kann!
Noch zu erwähnen
Eingangs des Artikels hatte ich erwähnt, dass es Weiteres zu beachten gibt. Durch das Upgrade wurden die Einstellungen des Dienstes zu meinem Turn-Server zurück gesetzt. Ein funktionierender Turn-Server ist wichtig, um reibungslosen Verlauf in Videokonferenzen zu ermöglichen.
Wer also wie ich eine Nextcloud auf dem Raspberry Pi installiert hat und bisher meinen Anleitungen gefolgt ist, muss den zeitverzögerten Start des Turnservers, wie im Artikel „coTurn zeitverzögert auf Raspberry Pi starten“ beschrieben, wieder neu konfigurieren. Dazu editiert man die Datei /lib/systemd/system/coturn.service:
sudo nano /lib/systemd/system/coturn.service
Nun fügt man den folgenden Eintrag unter [Service] ein und speichert die Änderung mit Ctlr + o.
ExecStartPre=/bin/sleep 30
Den Editor verlässt man dann wieder mit Ctrl + x. Durch den Eintrag wird nun eine Verzögerung von 30 Sekunden erzwungen. Mit
sudo service coturn restart
wird der Turnserver zeitverzögert neu gestartet. jetzt arbeitet coTURN nach dem nächsten Reboot des Raspberry Pi wie gewünscht.