Updates zu lokalen Sprachmodelle: MTP, APEX, Qwopus
Unser Buch Coding mit KI ist gerade erst erschienen, schon gibt es spannende Neuigkeiten rund um die Ausführung lokaler Modelle:
- Multi-Token Prediction (MTP) ist ein ganz neues Feature in llama.cpp. Seit ein paar Tagen steht es auch in LM Studio zur Verfügung. Durch einen »Trick« (Details folgen gleich) kann mit MTP die Output-Token-Geschwindigkeit deutlich vergrößert werden: laut diversen Benchmarktests im Internet bis auf das Doppelte, in meinen Tests immerhin um ca. 60 bis 70 Prozent.
-
Adaptive Precision for EXpert Models (APEX) ist ein neues Verfahren zur besonders platzsparenden Quantisierung von MoE-Modellen. Der Platzbedarf sinkt je nach Qualitätsstufe auf die Hälfte gegenüber der herkömmlichen 4-Bit-Darstellungen (Q4_x_x).
-
Qwopus ist eine neue Variante zu den Qwen-Modellen, bei denen das Fine Tuning mit Claude Opus verbessert wurde.
Von Speculative Decoding zur Multi-Token Prediction
In Coding mit KI gehe ich kurz auf das Vorgängerkonzept zu MTP ein, auf Speculative Decoding: Dabei führt die Engine (z.B. llama.cpp) zwei Sprachmodelle aus. Das kleinere (schnellere) dient als Draft Model. Während der Token-Generierung macht das Draft Model Vorschläge für die folgenden Token. Das größere, qualitativ bessere Modell überprüft anschließend eine Sequenz mehrerer vorgeschlagener Token auf einmal. Im Idealfall wird die ganze Sequenz akzeptiert. Der Geschwindigkeitsvorteil ergibt sich durch die parallele Verifizierung eines ganzen Token-Blocks. Dazu sind weniger Speicher-Transfers vom VRAM in die GPU notwendig, als wenn jedes Token für sich generiert wird. (Die Token-Generierung wird durch zwei Faktoren limitiert: die Rechenleistung der GPU und die Speicherbandbreite vom VRAM in die GPU-Cores. Speculative Decoding setzt beim zweiten Punkt ein, der oft der limitierende Faktor ist.)
In der Praxis funktioniert das nur mäßig gut: Zum einen ist es schwierig, ein geeignetes Draft Model zu finden. Es muss aus der gleichen »Familie« stammen, aber deutlich kleiner sein, idealerweise etwa um den Faktor zehn. Zum anderen funktioniert Speculative Decoding für Dense Models besser als für Mixture of Experts Models (MoE). Das Problem bei MoE besteht darin, dass bei jedem Token andere »Experten« zum Einsatz kommen können, was den Geschwindigkeitsvorteil von Speculative Decoding teilweise zunichtemacht. Kleinere MoE-Modelle für den Draft-Einsatz haben zudem oft eine andere Experten-Aufteilung, was die Acceptance Rate verringert.
Multi-Token Prediction (MTP) greift die Idee des Speculative Decoding auf. Der entscheidende Unterschied besteht darin, dass ein Modell ausreicht. Ein in das Modell integrierter Layer ist dafür zuständig, rasch ein paar Tokens (üblicherweise 2 bis 4) vorherzusagen. Das Gesamtmodell überprüft dann alle Token auf einmal, was nur unwesentlich mehr Zeit kostet, als ein Token zu berechnen. MTP erspart damit das umständliche Handling mit zwei Modellen.
Speculative Decoding und Multi-Token Prediction sind mit keinerlei Qualitätsverlust verbunden! Es werden exakt die gleichen Ergebnisse erzielt, weil jede Token-Sequenz vollständig kontrolliert und bei Abweichungen verworfen wird. Werfen Sie diesbezüglich einen Blick in das Video von Donata Capitella, das diesen Umstand anschaulich erklärt.
Für den erzielten Geschwindigkeitsgewinn ist der Prozentsatz der akzeptierten Draft Tokens entscheidend. Dieser variiert je Aufgabenstellung: Bei kreativem Text ist die Akzeptanzrate nur mittelmäßig, bei Code hingegen deutlich höher — ganz einfach deswegen, weil Code strengen Regeln folgt und weniger Spielraum als menschliche Sprachen bietet.
Leider ist auch MTP mit Nachteilen verbunden:
- Das Modell muss für MTP konzipiert sein. MTP muss schon beim Training berücksichtigt werden. Das Modell benötigt einen zusätzlichen Layer für die Token Prediction. Aktuell gibt es nur eine einzige »freie« Modellfamilie mit MTP, nämlich Qwen 3.6 und dessen Variante Qwopus. Gemma-4-Modelle sollten demnächst folgen. In Zukunft wird MTP wohl zu einem Standard-Feature für freie Modelle.
-
Natürlich muss auch die Software MTP unterstützen. Weil viele Programme intern llama.cpp verwenden, wird MTP rasch weite Verbreitung finden.
-
Schließlich teilt sich MTP einen Nachteil mit Speculative Decoding: Es funktioniert bei herkömmlichen Dense-Modellen besser als bei MoE-Modellen (Mixture of Experts). Die ohnedies schon schnellen MoE-Modelle werden also nur geringfügig schneller oder, wie bei einigen meiner Tests, sogar langsamer. Bei den Dense-Modellen ist dagegen eine spürbare Verbesserung zu bemerken. Bei meinen Tests ca. +65%, bei einigen Benchmarks im Internet bis zu +100%, also eine Verdoppelung der Output-Token-Rate.
-
MTP ändert nichts an der Input-Verarbeitung (dem Prompt Processing, pp). Schneller wird nur der Output (die Token Generation, tg).
Dense versus Mixture of Experts (MoE): MoE ist schneller, kann aber qualitativ bei gleicher Modellgröße nicht ganz mithalten. Während bei Dense-Modellen immer alle Parameter aktiv sind, nutzen MoE-Modelle nur wenige, stets wechselnde »Experten«, also Subsets mit viel weniger Parametern. Das spart Zeit, aber kein »Experte« ist so gut wie das volle Modell. Dementsprechend sinkt die Qualität der Antworten, nicht massiv, aber spürbar.)
Praktische Erfahrungen
Ich habe MTP mit LM Studio 0.4.14 auf meinem Framework Desktop ausprobiert (AMD Ryzen Max 395 CPU/GPU). Mein Mini-Benchmarktests lautete: »Explain Python dictionaries«. Die getesteten Modelle denken über diese Frage eine Weile nach und produzieren dann einen mehrseitigen, qualitativ sehr hochwertigen Text mit eingebauten Code-Schnipseln.
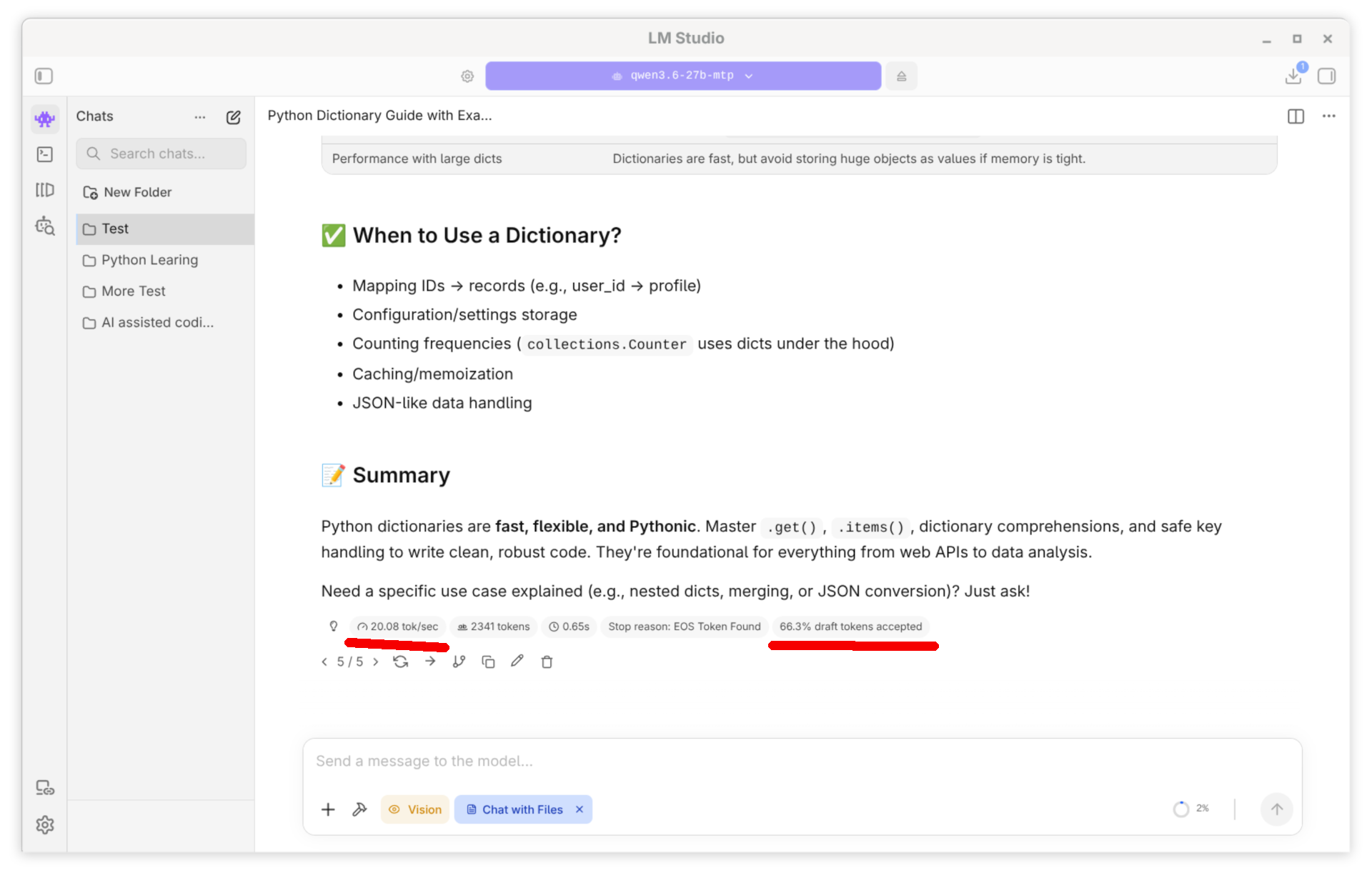
Ich habe alle Tests mit einem Kontextfenster von 128.000 Token ausgeführt. Bei den MTP-Modellen habe ich die Einstellung MTP Max Tokens = 3 verwendet, also immer drei Tokens auf einmal erzeugt. Alle getesteten Modelle weisen eine 4-Bit-Quantisierung auf (Ausnahme: das APEX-Modell, siehe unten). Als Backend kommt llama.cpp mit Vulkan zum Einsatz.
Draft Token
Modell MoE APEX MTP Output (tg) Acceptance
----------------- ---- ---- ---- ------------ ------------------
qwen-3.6-27b nein nein nein 12,3 Token/s
qwen-3.6-27b-mtp nein nein ja 20,1 Token/s 66,3 %
qwopus-3.6-27b-v2-mtp nein nein ja 19,0 Token/s 63,7 %
qwen-3.6-35b-a3b ja nein nein 69,7 Token/s
qwen-3.6-35b-a3b-mtp ja nein ja 67,1 Token/s 66,6 %
qwen-3.6-35b-a3b-apex-mtp ja ja ja 71,5 Token/s 63,3 %
qwopus-3.6-35b-a3b-mtp ja nein ja 74,2 Token/s 68,2 %
Professionellere Benchmark-Tests hat Donata Capitella durchgeführt (siehe die ersten zwei Links in den Übersicht der Quellen am Ende des Artikels). Interessanterweise ist dort auch bei MoE-Modellen ein spürbarer Geschwindigkeitszuwachs von etwa 30% zu sehen, den ich bei meinen Tests aber nicht nachvollziehen kann.
Qwopus-Modelle
Die neuen Qwopus-Modelle basieren auf Qwen-Modellen, erhalten aber ein zusätzliches Fine-Tuning mit Claude Opus. Dieses soll den Nachdenkprozess beschleunigen und eine bessere Antwortqualität mit sich bringen. Die erste Versprechung trifft definitiv zu, aber ich bin nicht in der Lage, die Qualität des Modells im Detail zu beurteilen. Subjektiv hatte ich den Eindruck, dass die Unterschiede zu den Qwen-Originalen gering sind.
Zum Denkprozess: Beim Prompt »write a Sudoku solver in Python« denkt qwen-3.6-27b-mtp ca. 1:30 Minuten nach, qwopus-3.6-27b-v2-mtp aber ca. nur 1:00 Minuten. (Die Denkzeit hat eine relativ starke Varianz, weswegen hier genaue Angaben sinnlos sind.) Die resultierende Antwort samt Code ist mehr oder weniger gleichwertig (Backtracking-Algorithmus).
APEX Quantisierung
Die Verkleinerung von Modellen bei möglichst geringen Qualitätsverlust ist zu einer eigenen KI-Disziplin geworden. Die Grundidee besteht darin, Milliarden von Parametern (also eigentlich Fließkommazahlen) mit möglichst wenigen Bits darzustellen, ohne dass die Qualität der Ergebnisse allzu sehr leidet.
Der geringere Platzbedarf von Modellen ist insbesondere dann wichtig, wenn der Speicher (VRAM) limitiert ist. Mit einer geschickten Quantisierung läuft ein Modell vielleicht gerade noch auf einer GPU mit 16 GiB VRAM.
Vor ein paar Monaten machte Google mit dem neuen Turbo-Quant-Verfahren Furore. Bei der Recherche für diesen Artikel bin ich nun auf das neue Verfahren Adaptive Precision for EXpert Models (APEX) gestoßen. Das von Local AI entwickelte Verfahren ist speziell für MoE-Modelle optimiert und kompatibel zu aktuellen llama.cpp-Versionen. Die Grundidee besteht darin, dass für jede Parametergruppe eine andere, für den Wertebereich und die Wichtigkeit angepasste Quantisierung verwendet wird. Insofern ist eine klare Bit-Angabe (4 Bit pro Parameter) unmöglich. Technische Details und Benchmarks finden Sie auf der GitHub-Projektseite. Local AI arbeitet daran, Modelle lokal auf Smartphones auszuführen; da ist die möglichst platzsparende Darstellung natürlich wichtig.
Konkret sind APEX-Modelle zum Teil wirklich erheblich kleiner als vergleichbare Modelle mit Q4-Quantisierung, wie sie bei der lokalen Ausführung von Modellen üblich ist. Die folgende Tabelle zeigt lauter Qwen-3.6-Modelle mit jeweils 35 Milliarden Parameter. Das APEX-MTP-Modell benötigt nur halb so viel Platz wie das MTP-Modell mit einer herkömmlichen Q4-Quantisierung.
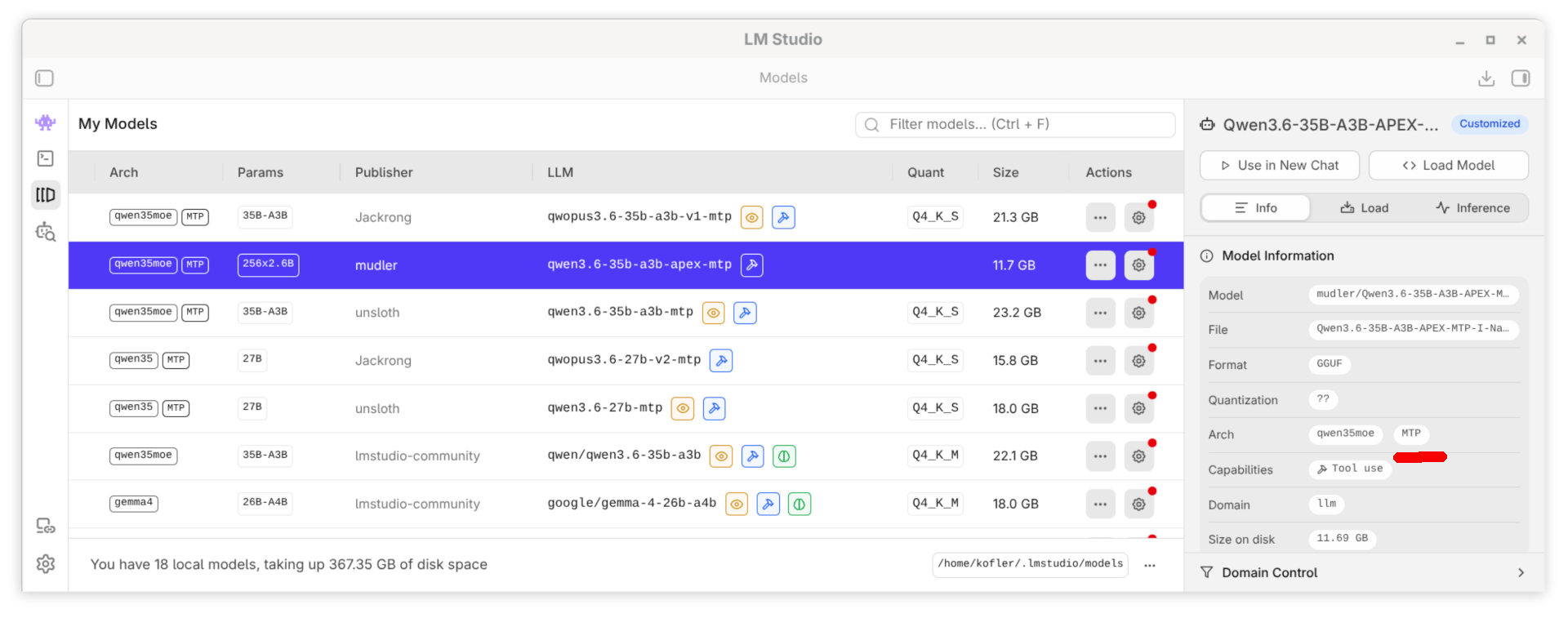
Leider verrät die Huggingface-Seite des Modells nicht, welche Variante der APEX-Quantisierung verwendet wurde. Es existieren verschiedene Qualitätsstufen, z.B. Quality, Balanced, Compact und Mini. Ich würde vermuten, das Modell ist eher bei Mini als bei Quality angesiedelt.
Modell Quantisierung Größe (Disk)
------------------------ ------------- ------------
qwen-3.6-35b-a3b Q4_K_M 22,0 GB
qwen-3.6-35b-a3b-mtp Q4_K_S 23,0 GB
qwen-3.6-35b-a3b-apex-mtp APEX 11,7 GB (!)
Bei der Ausführung des Modells waren für mich keine nennenswerten Unterschiede erkennbar, weder in der Geschwindigkeit noch qualitativ. Aber nochmals: Das sind subjektive Feststellungen anhand einiger Tests, keine objektiven Benchmark-Tests. Dazu fehlt mir ganz einfach die Zeit.
Quellen/Links
- https://www.youtube.com/watch?v=MI0Pm1d6YF4 (gutes Video von Donata Capitella)
- https://kyuz0.github.io/amd-strix-halo-toolboxes/mtp.html (Benchmarks von Donata Capitella)
- https://sebastianraschka.com/llm-architecture-gallery/mtp/
- https://github.com/ggml-org/llama.cpp/pull/22673 (MTP für llama.cpp)
- https://lmstudio.ai/changelog/lmstudio-v0.4.14 (LM Studio Changelog)
- https://github.com/localai-org/apex-quant
Ausgewählte Modelle mit MTP und/oder APEX
- https://huggingface.co/unsloth/Qwen3.6-35B-A3B-MTP-GGUF (Qwen MTP)
- https://huggingface.co/Jackrong/Qwopus3.6-27B-v2-MTP-GGUF (Qwopus MTP)
- https://huggingface.co/Jackrong/Qwopus3.6-35B-A3B-v1-MTP-GGUF (ebenso)
- https://huggingface.co/mudler/Qwen3.6-35B-A3B-APEX-MTP-GGUF (APEX)
Technisch/Wissenschaftliche Grundlagen
- https://arxiv.org/abs/2211.17192 (Speculative Decoding)
- https://arxiv.org/abs/2404.19737 (MTP)
- https://arxiv.org/abs/2509.18362v1 (FastMTP)
- https://arxiv.org/abs/2412.19437 (MTP in DeepSeek-Modellen)
- https://blog.google/innovation-and-ai/technology/developers-tools/multi-token-prediction-gemma-4/ (MTP in Gemma-Modellen)





