Emacs als Markdown-Editor
Wer mein Linux-Buch gelesen hat weiß, dass ich nicht im Vi-Lager zuhause bin, sondern zu den Emacs-Fans zähle. Beim Programmieren verwende ich diverse Editoren und IDEs, von VSCode über IntelliJ bis hin zu Xcode. Aber längere Texte (sprich: Bücher) schreibe ich seit Jahrzehnten ausschließlich mit dem Emacs. Ich habe ein paar halbherzige Versuche mit anderen Editoren gemacht, aber ich bin immer wieder zurückgekommen.
Meine Emacs-Liebe hat weniger mit der Großartigkeit dieses Programms zu tun als viel mehr damit, dass ich mir im Laufe der Zeit ein eigenes Setup mit Tastenkürzeln und Zusatzfunktionen gebastelt habe. Davon bin ich jetzt abhängig, meine Finger wollen sich nicht mehr umgewöhnen.
Die Motivation für diesen Blogbeitrag ist die immer wiederkehrende Frage, womit ich meine Markdown-Texte verfasse. Vielleicht finden andere Emacs-Fans in der nachfolgenden .emacs-Datei Ideen, die sie noch nicht kennen; vielleicht schreibt mir auch jemand im Forum, welches Feature ich bisher übersehen habe.
Dieser Beitrag ist aber keinesfalls ein Versuch, Sie vom Emacs zu überzeugen. Ein Neustart heute bei Null — da würde ich höchstwahrscheinlich bei einem deutlich moderneren Programm landen (möglicherweise bei zed). Dieser Text will Ihnen auch nicht meine Tastenkürzel aufzwingen. Die sind im Laufe der Zeit eher zufällig entstanden. Aber dieser Teil von .emacs lässt sich ja am einfachsten anpassen.
Die Datei .emacs
Die Konfiguration des Emacs erfolgt in der Datei .emacs. Die Anweisungen dort müssen in der Programmiersprache Elisp formuliert werden. Das ist die Emacs-Variante der heute ansonsten kaum noch gebräuchlichen Sprache Lisp. Früher war Elisp eine Hürde für viele Emacs-Einsteiger, und in einigen frühen Auflagen meines Linux-Buchs hatte ich sogar ein kurzes Elisp-Kapitel untergebracht. Heute sagen Sie Claude oder einem anderen KI-Tool, was Sie erreichen wollen, schon bekommen Sie den erforderlichen Code. (Manchmal klappt es erst im zweiten oder dritten Versuch.) Dank KI ist die Elisp-Syntaxhürde also überwunden.
Der Emacs liest .emacs automatisch beim Start. Spätere Änderungen gelten daher erst mit dem nächsten Start oder indem Sie die geänderten Zeilen markieren und mit Alt+X eval-region Return ausführen.
Meine Konfiguration
Die ersten Zeilen im folgenden Listing aktivieren einige allgemeine Einstellungen. cua-mode erlaubt die vertrauten Tastenkürzel Strg+C, Strg+X und Strg+V für Kopieren, Ausschneiden und Einfügen. Im originalen Emacs gibt es dafür andere Kürzel, die parallel aktiv bleiben. save-place-mode bewirkt, dass der Emacs die letzte Cursor-Position in jeder geöffneten Datei dauerhaft speichert. Damit das Arbeitsverzeichnis nicht mit Backup-Dateien übersät wird, landen Emacs-Backups gesammelt in ~/.emacs.d/backups/.
Moderne Emacs-Konfigurationen laden Erweiterungspakete über package.el nach. Das Standard-Repository des Emacs enthält nur wenige Pakete; deshalb binde ich MELPA ein, das mit Abstand größte Community-Repository mit Tausenden von Erweiterungen. Beim ersten Start auf einem neuen Rechner aktualisiert der Emacs automatisch die Paketliste (package-refresh-contents), sodass alle benötigten Pakete sofort installiert werden können.
Das Makro use-package bündelt je ein Paket zusammen mit seiner Konfiguration, Hooks und Tastenkürzel-Bindungen in einem einzigen Block. Die Einstellung use-package-always-ensure t sorgt dafür, dass fehlende Pakete automatisch nachinstalliert werden, ohne manuelles Eingreifen.
Der markdown-mode aus dem gleichnamigen Paket steht im Zentrum des Setups. Der Modus hebt Markdown-Syntax farbig hervor und aktiviert über Hooks mehrere Begleitmodi: visual-line-mode sorgt für weiche Zeilenumbrüche ohne harte Zeilenenden in der Datei, display-line-numbers-mode blendet Zeilennummern ein, und visual-fill-column-mode begrenzt die Textbreite auf 100 Zeichen.
adaptive-wrap ist ein kleines, aber feines Detail: Wenn eine Zeile weich umgebrochen wird, rückt die Folgezeile so ein, dass Listenelemente (* oder -) korrekt untereinander ausgerichtet bleiben. unfill ergänzt den eingebauten Befehl fill-paragraph (bei mir F4): Statt einen Absatz auf mehrere kurze Zeilen zu verteilen, fasst unfill-paragraph alle Zeilen eines Absatzes wieder zu einer einzigen langen Zeile zusammen. Das ist hilfreich, wenn Markdown-Quellen von anderen Tools weiterverarbeitet werden.
Das Paket vertico erweitert den Emacs-Minibuffer um eine vertikale Auswahlliste (siehe den folgenden Screenshot). Beim Wechsel zwischen Buffern (F1) sehe ich alle offenen Dateien auf einen Blick inklusive Dateigröße, Modus und Pfad — letzteres dank marginalia, das die Listeneinträge um nützliche Zusatzinformationen ergänzt. orderless macht die Suche komfortabler: Ich kann mehrere Suchbegriffe mit Leerzeichen trennen und in beliebiger Reihenfolge eingeben.
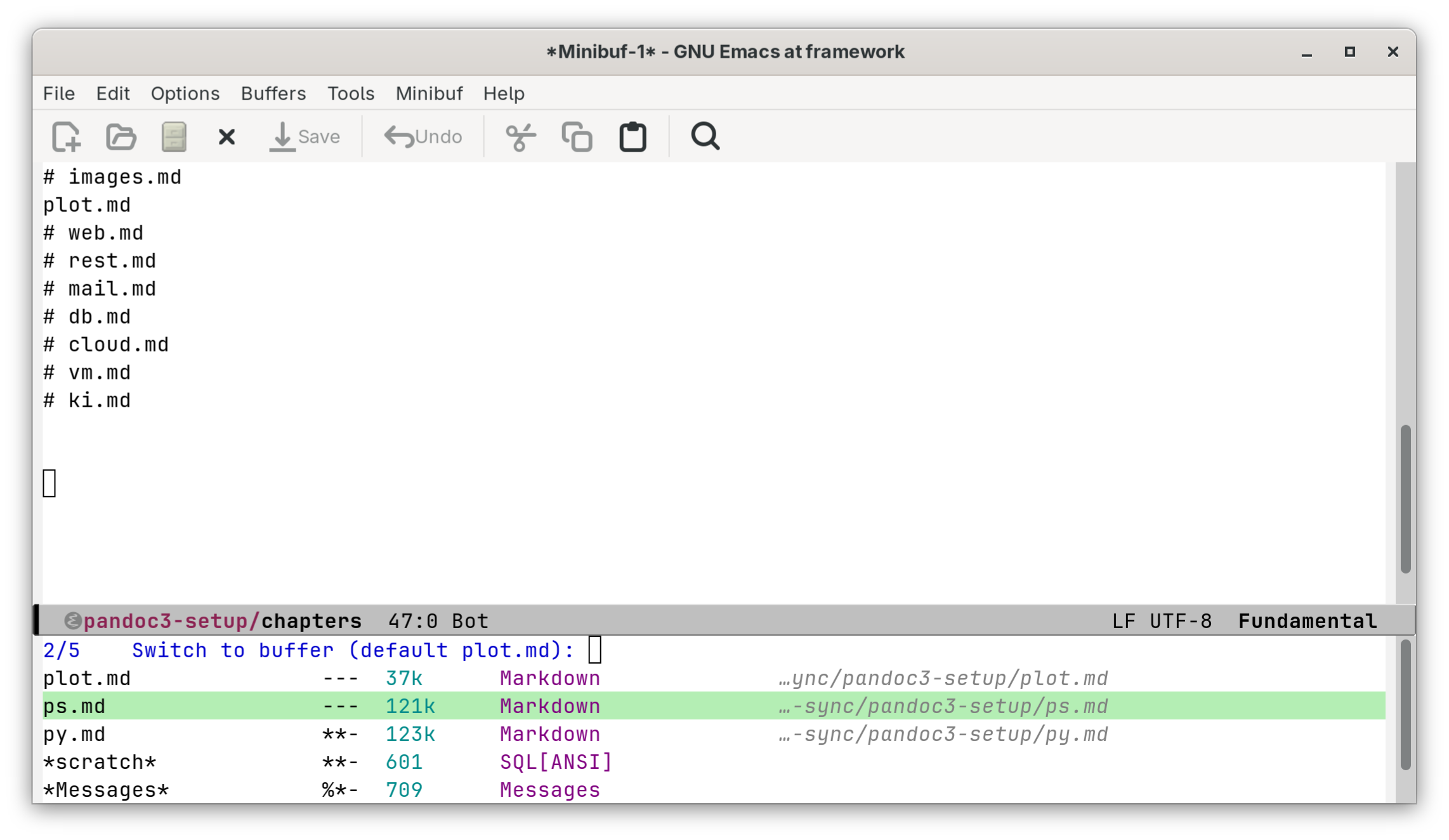
Die benutzerdefinierte vertico-sort-override-function ändert die Sortierreihenfolge im Buffer-Switcher: Statt alphabetischer Reihenfolge erscheinen die zuletzt verwendeten Buffer ganz oben in der Liste. Bei vielen Dateien finde ich die zuletzt verwendeten Datei schneller.
swap-char (F11) vertauscht die zwei Zeichen an der Cursor-Position. Tippfehler wie getsern statt gestern lassen sich damit sofort korrigieren: Cursor auf das erste falsche Zeichen, einmal F11, fertig.
change-case (F12) wechselt die Groß- bzw. Kleinschreibung des Zeichens unter dem Cursor. change-word-case (F9) tut dasselbe für den ersten Buchstaben des aktuellen Worts, unabhängig davon, wo im Wort der Cursor gerade steht.
point-to-register-1 (F5) / jump-to-register-1 (F6): Mit F5 speichere ich die aktuelle Position, mit F6 springe ich dorthin zurück. Beim Sprung wird gleichzeitig die neue Position gespeichert, sodass ich mit wiederholten F6-Drücken zwischen zwei weit entfernten Textstellen hin- und herspringen kann. Ich finde das praktisch, wenn ich parallel an zwei Stellen eines langen Dokuments arbeite.
expand-abbrev-or-dabbrev (F3) versucht zunächst, eine gespeicherte Abkürzung zu expandieren. In .abbrevs_defs habe ich einige solche Abkürzungen gespeichert, z.B. ms für »Microsoft« oder rhel für »Red Hat Enterprise Linux«. Falls keine passt, greift dabbrev-expand und vervollständigt das angefangene Wort anhand von Vorkommen im selben Buffer. Praktisch für lange Schlüsselwörter.
Beim Einlesen der .emacs-Datei lädt der Editor automatisch alle erforderlichen Pakete herunter. Wenn dabei Download-Fehler auftreten, müssen Sie eventuell den MELPA-Cache aktualisieren. Dazu führen Sie Alt+X package-refresh-contents Return aus und starten den Emacs dann neu.
;; Datei ~/.emacs
;; ======== Grundeinstellungen ====================================
(cua-mode 1) ;Cut&Paste mit Strg+C/X/V
(setq inhibit-startup-message t) ;kein Emacs-Startbildschirm
(setq screen-preserve-screen-position t) ;zurück zur letzten Zeile
(setq scroll-step 5) ;bei Scrollen Sprünge von 5 Zeilen
(column-number-mode 1) ; ... Spaltennummern in der Statusleiste
(abbrev-mode 0) ;kein automatisches expand-abbrev
(setq require-final-newline t) ;letzte Zeile automatisch mit Return abschließen
(save-place-mode) ;Cursor-Position innerhalb der Datei merken
;; automatische Backups nicht im lokalen Verzeichnis, sondern in ~/.emacs.d/backups/
(setq backup-directory-alist
`(("." . ,(concat user-emacs-directory "backups"))))
(setq auto-save-file-name-transforms
`((".*" ,(concat user-emacs-directory "backups/") t)))
;; Spaltenbreite für Zeilennummern (nur Markdown)
(setq-default display-line-numbers-width 4)
;; Abkürzungstabelle automatisch laden und speichern
;; Falls ~/.abbrev_defs nicht existiert, leere Datei anlegen (kein Fehler)
(let ((abbrev-file "~/.abbrev_defs"))
(unless (file-exists-p abbrev-file)
(write-region "" nil abbrev-file))
(read-abbrev-file abbrev-file))
(setq save-abbrevs t) ;automat. speichern
;; ======== Packages ================================================
;; package.el initialisieren und MELPA-Repo hinzufügen (falls erforderlich)
(require 'package)
(add-to-list 'package-archives '("melpa" . "https://melpa.org/packages/") t)
(package-initialize)
;; Paket-Repo aktualisieren (first run / new machine)
(when (not package-archive-contents)
(package-refresh-contents))
;; alle erforderlichen Pakete automatisch laden
(unless (package-installed-p 'use-package)
(package-install 'use-package))
(require 'use-package)
(setq use-package-always-ensure t)
;; scratch-Buffer automatisch speichern (https://github.com/Fanael/persistent-scratch)
(use-package persistent-scratch
:config
(persistent-scratch-setup-default))
;; weiche Zeilenumbrüche mit Einrückung bei Listen etc.
(use-package adaptive-wrap
:hook (visual-line-mode . adaptive-wrap-prefix-mode))
;; Spalte mit Zeilennummern / zentrierter Text
(use-package visual-fill-column
:hook (markdown-mode . visual-fill-column-mode)
:config
(setq-default visual-fill-column-width 100)
(setq visual-fill-column-width 100))
;; Markdown-Modus
(use-package markdown-mode
:mode (("\\.text\\'" . markdown-mode)
("\\.md\\'" . markdown-mode))
:hook ((markdown-mode . visual-line-mode) ; soft-wrap long lines
(markdown-mode . display-line-numbers-mode) ; show line numbers
(markdown-mode . visual-fill-column-mode) ; center text within column width
(markdown-mode . (lambda () (setq fill-column 79))))) ; hard-wrap at 79 chars
;; Unfill: mehrzeilige Absätze zu einer langen Zeile verbinden (Shift+F4)
(use-package unfill)
;; mehr Komfort im Minibuffer
(use-package vertico
:config
(vertico-mode 1)
; sort buffer list by 'recently shown'
(setq vertico-sort-override-function
(lambda (candidates)
(if (eq minibuffer-history-variable 'buffer-name-history)
(let ((hist (symbol-value minibuffer-history-variable)))
(sort candidates
(lambda (a b)
(let ((pa (or (cl-position a hist :test #'equal) most-positive-fixnum))
(pb (or (cl-position b hist :test #'equal) most-positive-fixnum)))
(< pa pb)))))
candidates))))
(use-package orderless
:config
(setq completion-styles '(orderless basic)))
(use-package marginalia
:config
(marginalia-mode 1))
;; schönere Statuszeile (setzt voraus, dass die JetBrains Nerd Fonts
;; installiert und als Emacs-Font verwendet werden)
(use-package nerd-icons
:config
(setq nerd-icons-font-family "JetBrainsMono Nerd Font"))
(use-package doom-modeline
:after nerd-icons
:config
(doom-modeline-mode 1)
(setq doom-modeline-height 25)
(setq doom-modeline-icon t))
;; Ligaturen (setzt ebenfalls einen Nerd Font voraus)
(use-package ligature
:config
(ligature-set-ligatures 't '("!=" "!==" "->" "<-" "=>" "<=>" ">=" "<=" "//"))
(global-ligature-mode t))
;; ======== Farben ================================================
(set-face-attribute 'line-number nil
:height 0.8 :foreground "#ffffff" :background "#dddddd")
(set-face-attribute 'link nil
:foreground "RoyalBlue3" :underline nil)
;; für Markdown-Modus
(with-eval-after-load 'markdown-mode
(set-face-attribute 'markdown-italic-face nil
:inherit 'italic :foreground "dark magenta" :slant 'italic)
(set-face-attribute 'markdown-pre-face nil
:inherit 'font-lock-constant-face))
(with-eval-after-load 'doom-modeline
(set-face-attribute 'doom-modeline-buffer-modified nil
:foreground "firebrick" :weight 'bold))
;; ======== eigene Funktionen ===================================================
(defun expand-abbrev-or-dabbrev () ;Expansion von Abkürzung: F3
(interactive)
(unless (expand-abbrev) ;falls keine Abkürzung existiert
(dabbrev-expand nil))) ;dynamische Expansion
(defvar my-point-register 1
"Hilfsvariable für jump-to-register-1: merkt sich, welches Register aktiv ist.")
(defun point-to-register-1 () ;Position in Reg. 1 speichern: F5
(interactive)
(setq my-point-register 1)
(point-to-register 1))
(defun jump-to-register-1 () ;Position wechseln: F6
(interactive) ;springt zur Position, die mit F5
(if (= my-point-register 1) ; gespeichert wurde ...
(progn
(setq my-point-register 2)
(point-to-register 2)
(jump-to-register 1))
(progn
(setq my-point-register 1)
(point-to-register 1)
(jump-to-register 2))))
(defun swap-char () ;zwei Buchstaben an der Cursor-Position
(interactive) ;vertauschen: F11
(save-excursion
(forward-char)
(transpose-chars 1)))
(defun change-case () ;Groß- und Kleinschreibung des Zeichens
(interactive) ;an der Cursorposition ändern: F12
(let ((zeichen (char-after (point))))
(if (> zeichen 64)
(progn
(setq zeichen (logxor zeichen 32))
(insert-char zeichen 1)
(delete-char 1))
(forward-char 1))))
(defun change-word-case () ;Groß- und Kleinschreibung des ersten
(interactive) ;Zeichens eines Worts verändern: F9
(point-to-register 2)
(backward-word 1)
(change-case)
(jump-to-register 2))
(defun unfill-paragraph-and-advance () ;Absatz zusammenfügen und zum nächsten springen: S-F4
(interactive)
(unfill-paragraph)
(forward-paragraph)
(skip-chars-forward "\n")
(recenter))
(defun toggle-fill-column-width () ;Zeilenumbruch zwischen 100 und 1000 Zeichen wechseln
(interactive)
(setq-local visual-fill-column-width
(if (eq visual-fill-column-width 100) 1000 100))
(visual-fill-column-mode 1))
;; ======== Tastenkürzel ======================================================
(global-set-key [f1] 'switch-to-buffer) ;F1 Buffer wechseln
(global-set-key [f2] 'other-window) ;F2 Fenster wechseln
(global-set-key [f3] 'expand-abbrev-or-dabbrev) ;F3 Abkürzung erweitern
(global-set-key [f4] 'fill-paragraph) ;F4 Absatz umbrechen
(global-set-key [S-f4] 'unfill-paragraph-and-advance) ;S-F4 Absatz zusammenfügen + nächster
(global-set-key [f5] 'point-to-register-1) ;F5 Position speichern
(global-set-key [f6] 'jump-to-register-1) ;F6 zu Position springen
(global-set-key [f7] 'goto-line) ;F7 goto line
(global-set-key [f8] 'toggle-fill-column-width) ;F8 kurze/lange Zeilen
(global-set-key [f9] 'change-word-case) ;F9 Groß/Klein Wort
(global-set-key [f10] 'undo) ;F10 Undo
(global-set-key [f11] 'swap-char) ;F11 Buchst. vertauschen
(global-set-key [f12] 'change-case) ;F12 Groß-/Klein ändern
;; Mac-Tastatur: fn+ctrl+cursor to start/end of buffer
(global-set-key [C-prior] 'beginning-of-buffer)
(global-set-key [C-next] 'end-of-buffer)
;; Guillemets-Eingabe mit Alt+Q / Shift+Alt+Q
(defun insert-guillemot1 ()
(interactive)
(insert "«"))
(defun insert-guillemot2 ()
(interactive)
(insert "»"))
(global-set-key [?\M-q] 'insert-guillemot1) ;Alt+Q: «
(global-set-key [?\M-Q] 'insert-guillemot2) ;Shift+Alt+Q: »
;; macOS: rechte Alt-Taste zur Eingabe von Sonderzeichen wie @ oder € verwenden
(when (eq system-type 'darwin)
(setq mac-right-option-modifier nil) ; LeftAlt + L -> @ etc.
)
Quellen / Links
Die oben abgedruckte Datei können Sie als dotemacs.txt herunterladen.
- https://www.gnu.org/software/emacs/
- https://www.gnu.org/software/emacs/documentation.html
- https://www.gnu.org/software/emacs/manual/html_node/eintr/
- https://www.emacswiki.org
- https://github.com/chrisdone-archive/elisp-guide (Elisp Guide)
- https://en.wikipedia.org/wiki/Lisp_(programming_language)
- https://melpa.org/ (Erweiterungspakete)
- https://github.com/doomemacs/doomemacs (Emacs-Statuszeile)
Andere .emacs-Beispiele